
[프로젝트] Scene graph to Video generation with diffusion model - (2)구현
Inha univ. Scene Graph를 Condition으로 받는 video generation diffusion model 개발
요약
기존 SGDiff 논문의 경우 Visual genome(Image-SceneGraph pair dataset)을 가지고 image diffusion generation 모델을 제안하였다. 따라서 이를 Video로 확장하여 모델을 제안하고자 한다.
- Video-SG pair dataset을 가지고 Graph embedding model 학습
- Graph condition 을 DIffusion model에 대입하여 video 생성
- Long video generation을 위한 Autoregrassive 방법 사용
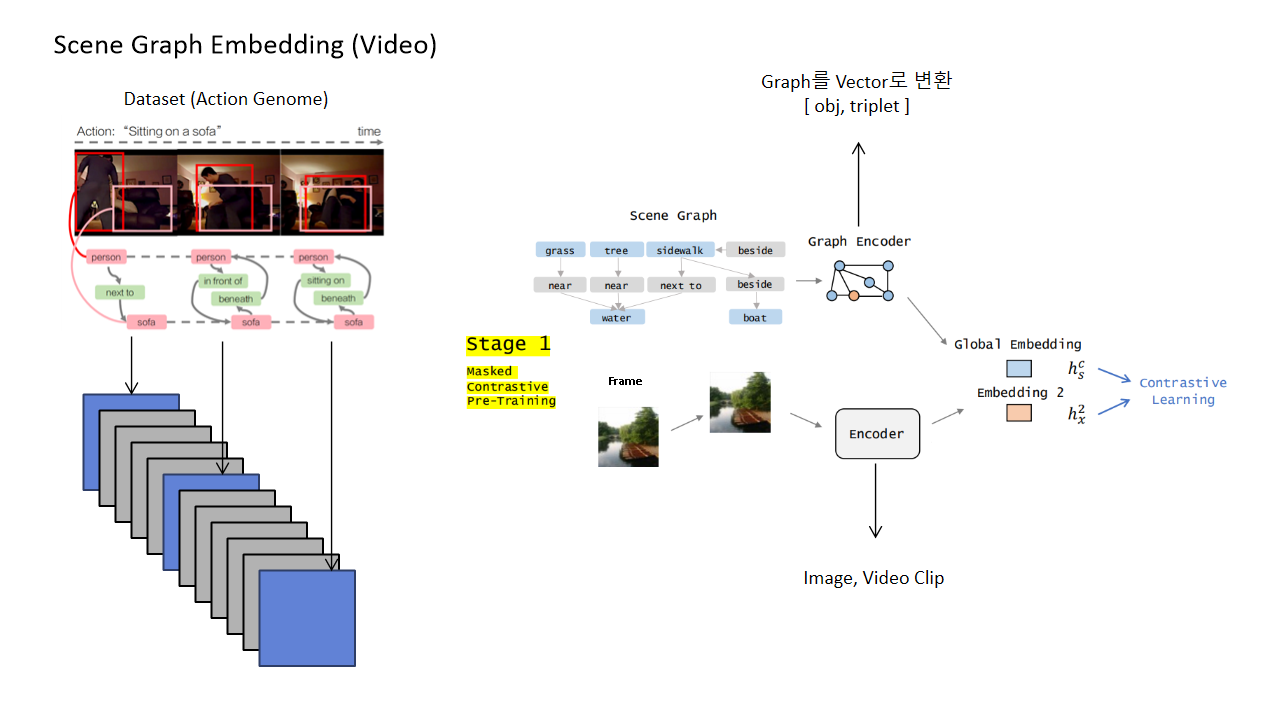
SG Encoding model
action genome으로 위 코드 동일하게 돌렸을 때 accuracy가 10% 정도 밖에 안나옴
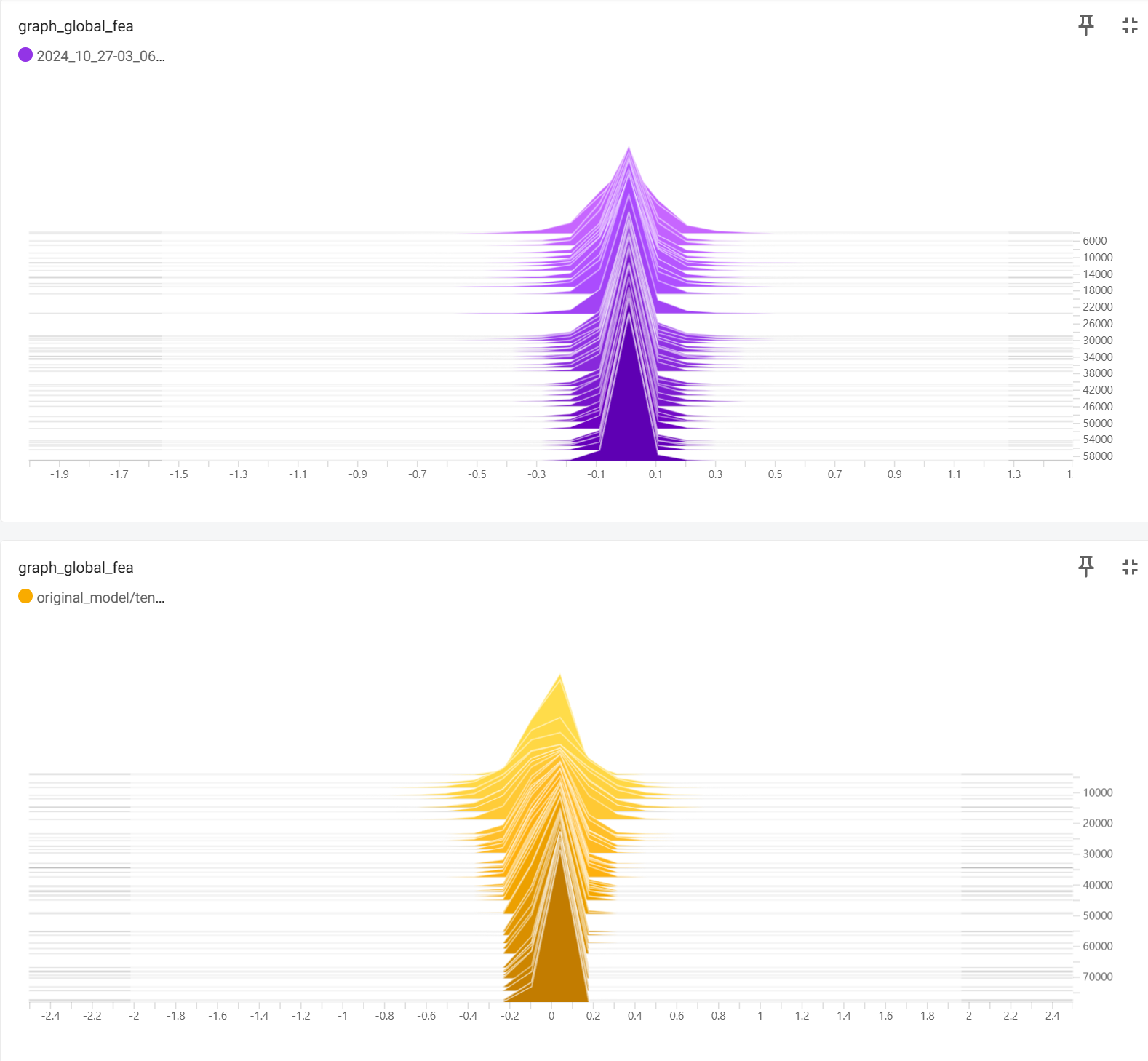
학습 기록
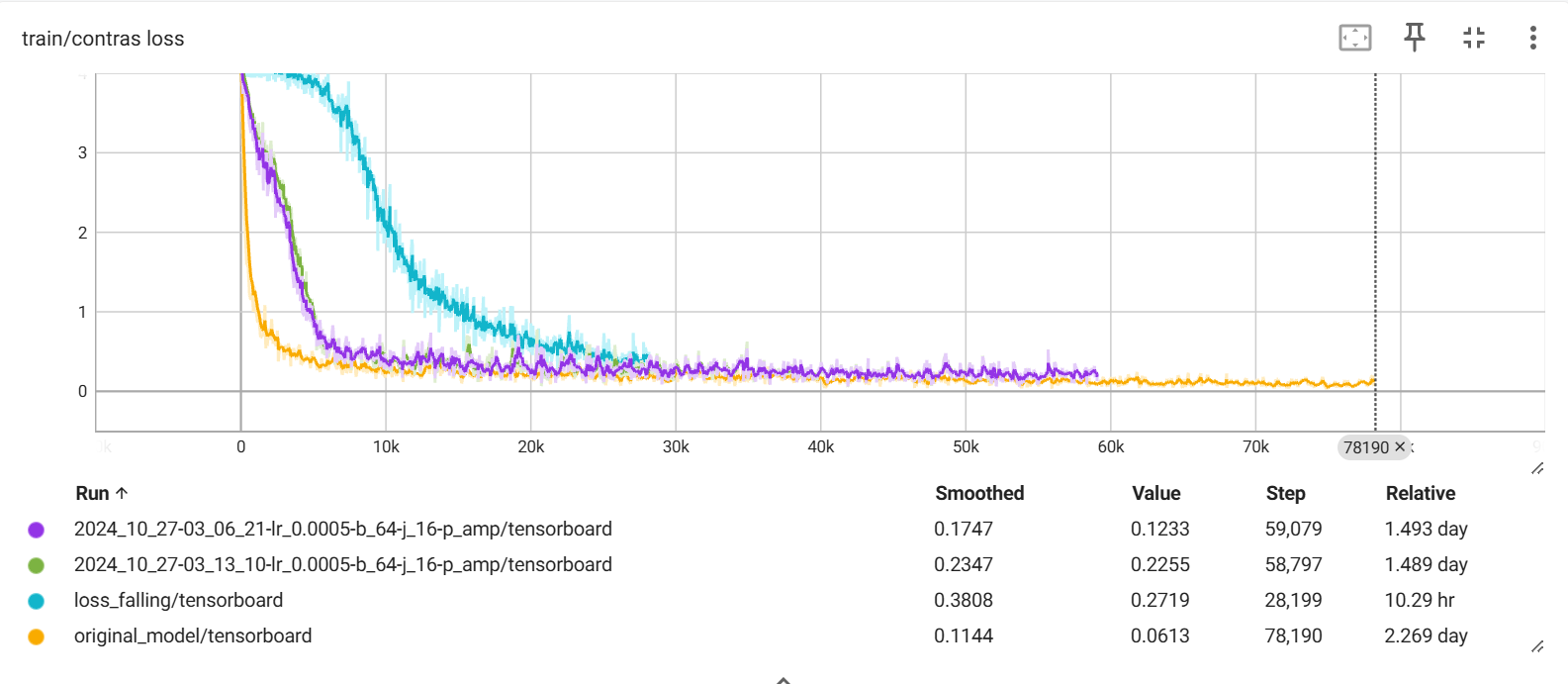
노란색이 원본 나머지가 Action genome으로 시도한 Loss(contrastive loss)
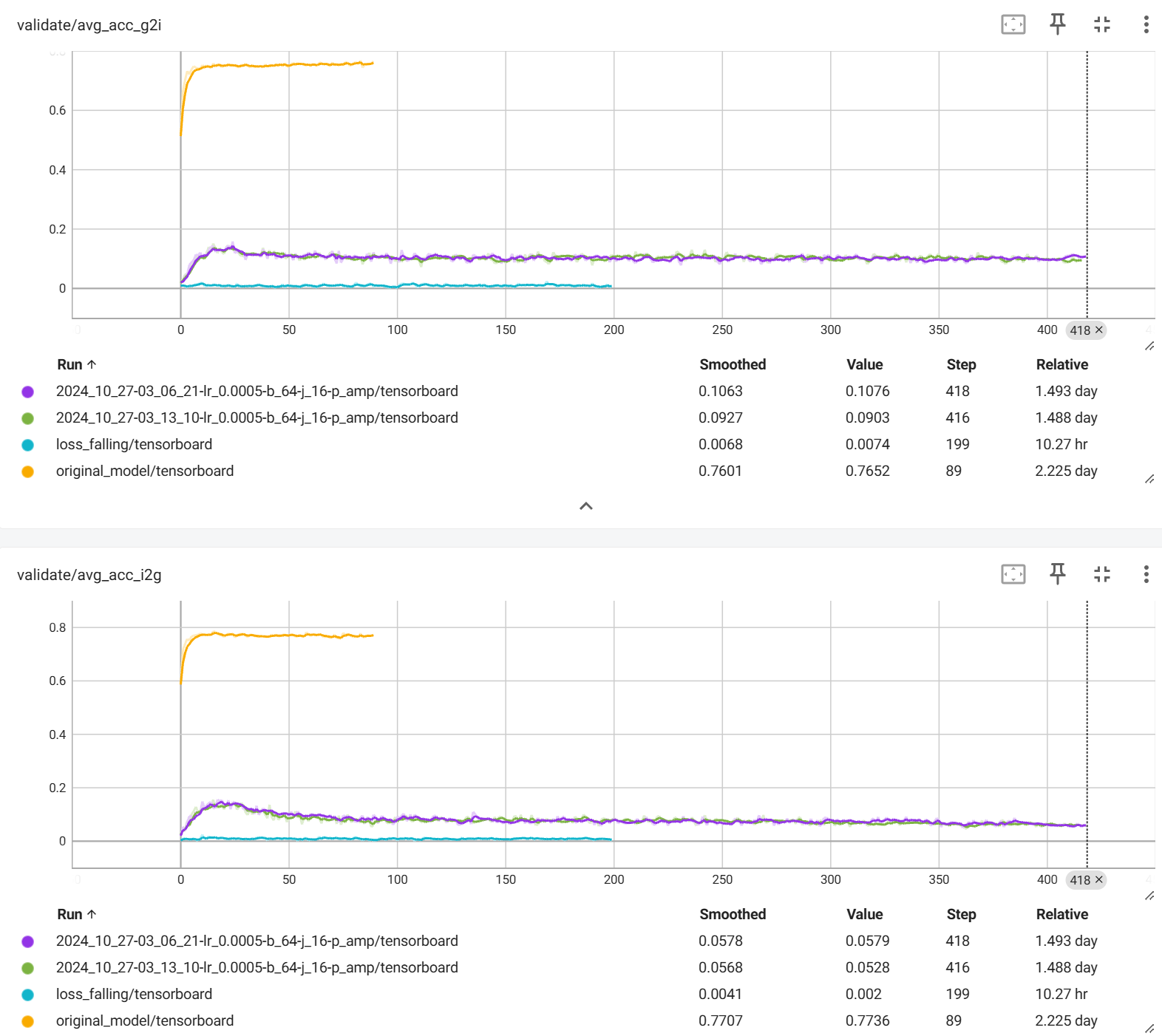
그에 따른 image/video to graph or graph to image/video accuracy
예상되는 문제점
- 데이터셋 자체가 적음 (action genome : 약 1만개, Visual Genome : 약 20만개)
- clip 모델과 유사하게 이미지 혹은 비디오 벡터를 graph 벡터와 유사하게 만드는 과정인데 이 과정에 많은 데이터가 필요
- image 혹은 video와 graph와의 연결성을 찾기 어려움
- 모델 구조 문제
- 모델 구조가 데이터 분포에 비해 깊은 경우
- 현재 512크기의 벡터로 압축하는데, 데이터가 가진 정보양 대비 이 벡터의 크기가 너무 커 실제로 압축이 안되고 그대로 출력되는 경우
- 초기 align 문제
Action genome dataset 분포
어떤 방식으로 데이터를 쪼개던지 비슷한 분포를 보임
.png)
실제 학습에서 vector 분포
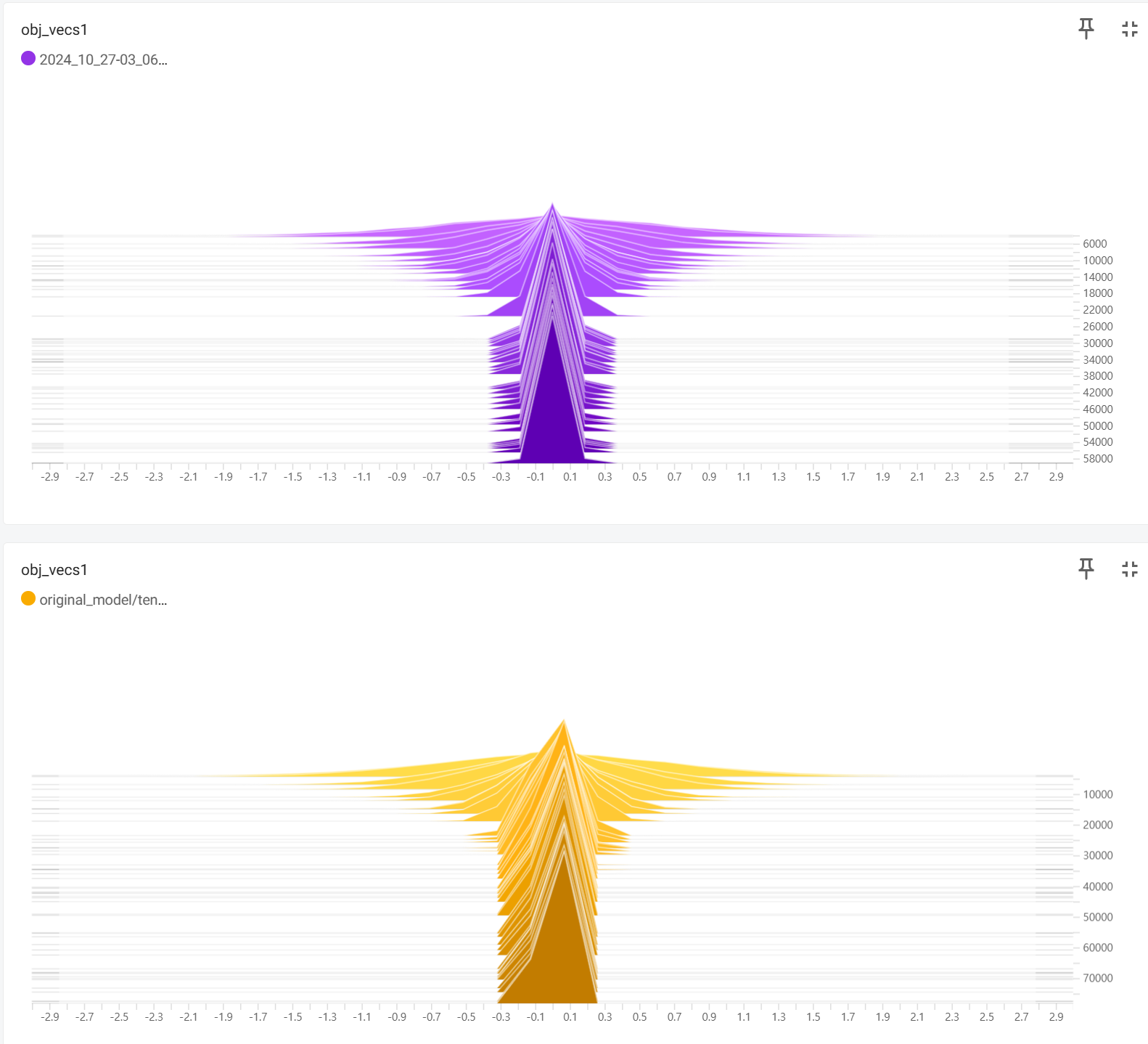
vocab label 변경
PCA를 통해 vector 분포 확인 [test dataset]
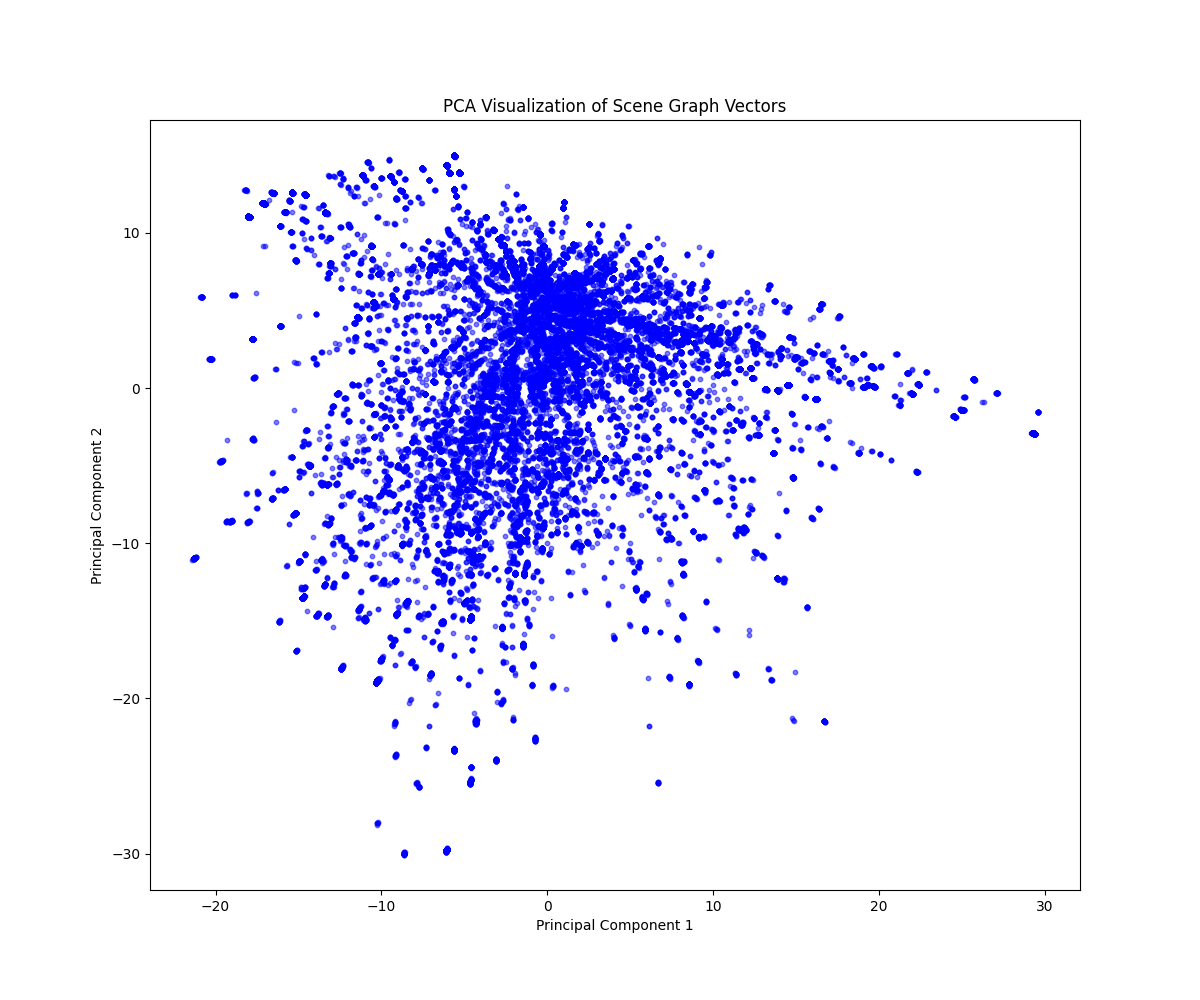
Action genome [52455개]
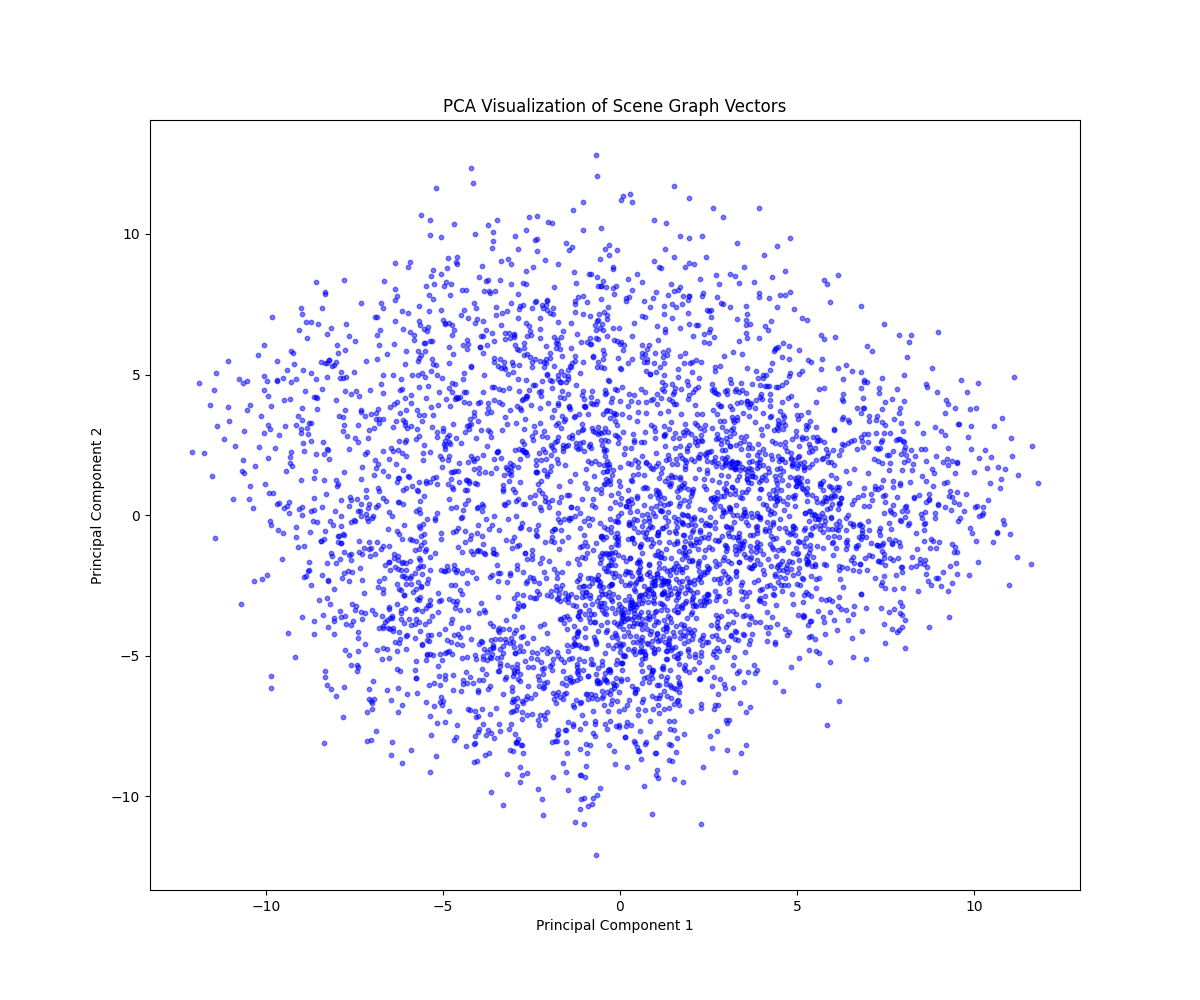
visual genome [4123개]
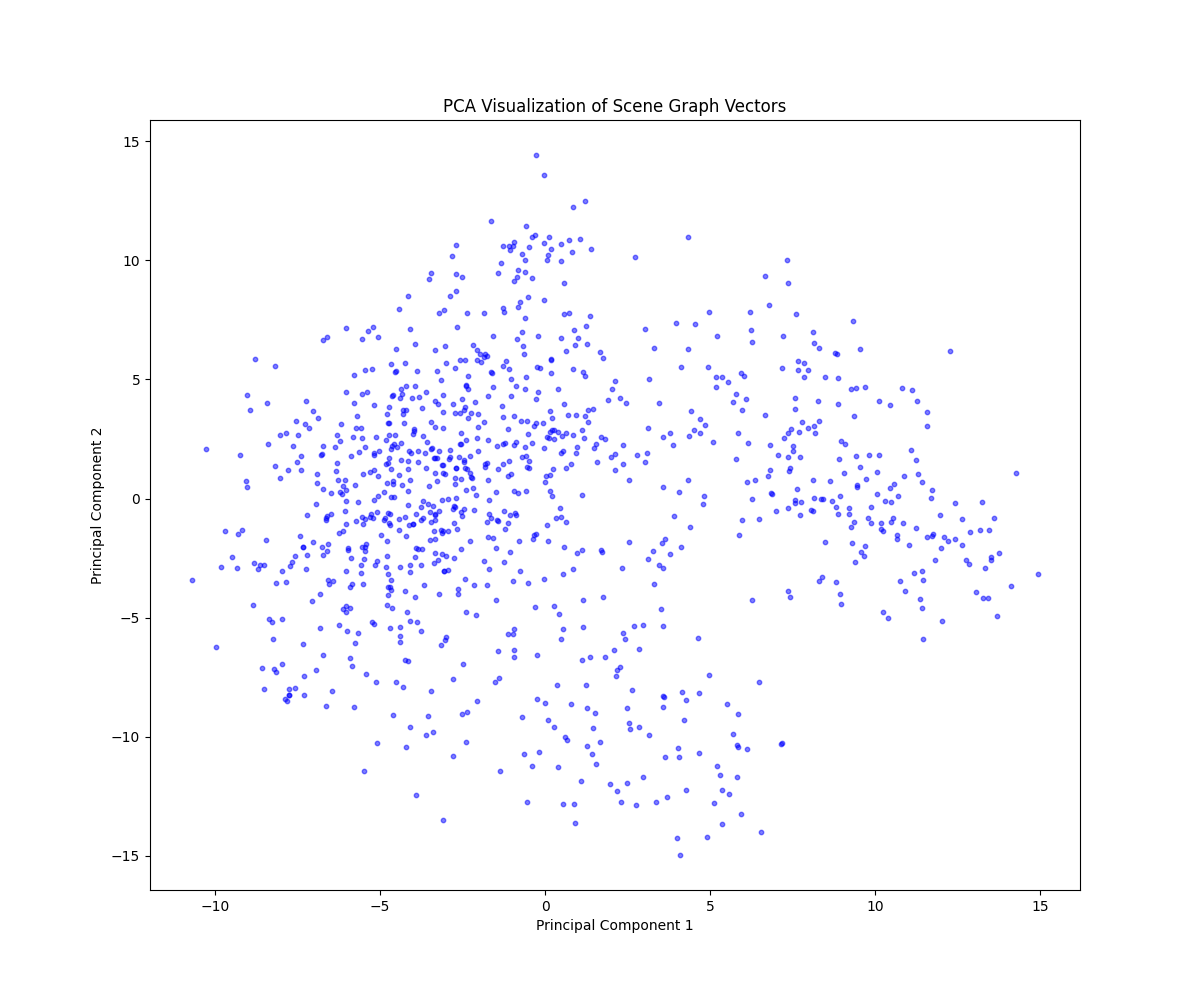
coco [1024개]
| Action Genome | Visual Genome | Coco Stuff | |
|---|---|---|---|
| Total nodes | 219336 | 36753 | 6771 |
| Total edges | 541383 | 44694 | 11494 |
| Average degree | 2.5650782361308675 | 2.2669169863684595 | 3.2089794712745534 |
| Number of isolated nodes | 0 | 0 | 0 |
| Number of objects with missing attributes | 52455 | 4123 | 0 |
| Number of outlier nodes based on degree | 13100 | 3365 | 544 |
확실히 Action genome이 안좋음
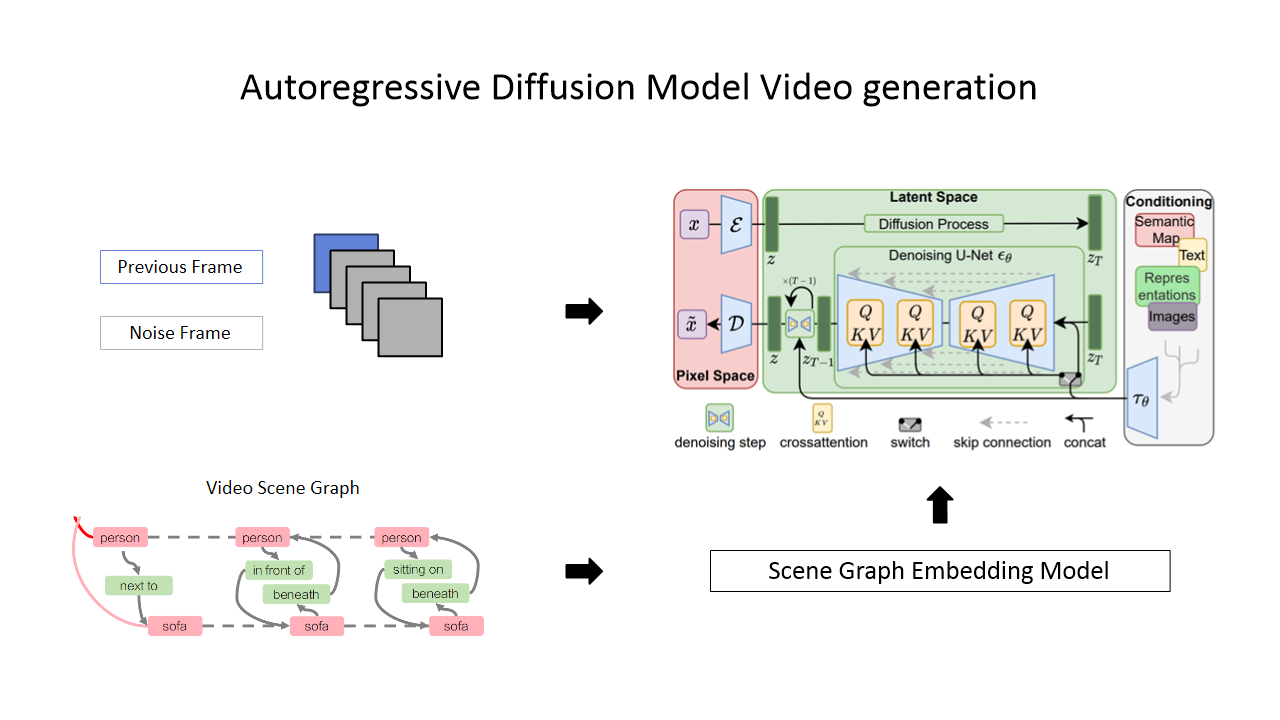
Diffusion model
이전 frame을 conditioning 하는 방법은 여러가지가 있지만, 가장 먼저 구현한 방법은 input의 일부를 이전 frame으로 넣는 것이다. 이후 이전 프레임은 denoising에서 제거하고 생성할 프레임만 backward pass를 진행한다.
별첨
Action genome preprocessing 하는 코드
(model에 input으로 넣을 수 있게 indexing하는 과정)
dataset class with action genome
Autoregrassive diffusion model
이전 Frame은 input에 넣는 conditioning 방법 코드
def p_losses(self, x_start, cond, t, noise=None, x_noisy=None, cond_mask=None, **kwargs,):
"""
x_start: [N x C x VideoLength x H x W] tensor, where the first part is the previous frames
and the second part is the frames to generate.
t: timesteps
"""
video_length = x_start.shape[2] // 2
previous_frames = x_start[:, :, :video_length, :, :]
frames_to_generate = x_start[:, :, video_length:, :, :]
noise = default(noise, lambda: torch.randn_like(frames_to_generate))
frames_to_generate_noisy = self.q_sample(x_start=frames_to_generate, t=t, noise=noise)
x_noisy = torch.cat([previous_frames, frames_to_generate_noisy], dim=2)
model_out = self.model(x_noisy, t)
loss_dict = {}
prefix = 'train' if self.training else 'val'
if self.parameterization == "eps":
target = noise
elif self.parameterization == "x0":
target = frames_to_generate
else:
raise NotImplementedError(f"Paramterization {self.parameterization} not yet supported")
loss_simple = self.get_loss(model_out[:, :, video_length:, :, :], target, mean=False).mean(dim=[1, 2, 3, 4])
loss_dict.update({f'{prefix}/loss_simple': loss_simple.mean()})
if self.logvar.device != self.device:
self.logvar = self.logvar.to(self.device)
logvar_t = self.logvar[t]
loss = loss_simple / torch.exp(logvar_t) + logvar_t
if self.learn_logvar:
loss_dict.update({f'{prefix}/loss_gamma': loss.mean()})
loss_dict.update({'logvar': self.logvar.data.mean()})
loss = self.l_simple_weight * loss.mean()
loss_vlb = self.get_loss(model_out[:, :, video_length:, :, :], target, mean=False).mean(dim=(1, 2, 3, 4))
loss_vlb = (self.lvlb_weights[t] * loss_vlb).mean()
loss_dict.update({f'{prefix}/loss_vlb': loss_vlb})
loss += (self.original_elbo_weight * loss_vlb)
loss_dict.update({f'{prefix}/loss': loss})
return loss, loss_dict
- input으로 이전 프레임 및 이후 프레임 모두 제공
- 이전 Frame은 noise 를 추가하는 q_sample에서 제외
- noise를 추가한 이미지와 안 한 이전 프레임을 합쳐서 모델에 제공
- loss는 noise scheduling 부분만