[논문분석] HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
GAN을 활용해 압축된 표현에서 오디오로 변환, one generator and two discriminators [Code, Paper]
1. Abstract
Several recent work on speech synthesis have employed generative adversarial networks (GANs) to produce raw waveforms. Although such methods improve the sampling efficiency and memory usage, their sample quality has not yet reached that of autoregressive and flow-based generative models. In this work, we propose HiFi-GAN, which achieves both efficient and high-fidelity speech synthesis. As speech audio consists of sinusoidal signals with various periods, we demonstrate that modeling periodic patterns of an audio is crucial for enhancing sample quality. A subjective human evaluation (mean opinion score, MOS) of a single speaker dataset indicates that our proposed method demonstrates similarity to human quality while generating 22.05 kHz high-fidelity audio 167.9 times faster than real-time on a single V100 GPU. We further show the generality of HiFi-GAN to the mel- spectrogram inversion of unseen speakers and end-to-end speech synthesis. Finally, a small footprint version of HiFi-GAN generates samples 13.4 times faster than real-time on CPU with comparable quality to an autoregressive counterpart.
2. Introduction
Most neural speech synthesis models use a two-stage pipeline:
1) predicting a low resolution intermediate representation such as mel-spectrograms or linguistic features from text → latent 표현으로 압축
2) synthesizing raw waveform audio from the intermediate representation. → latent 표현에서 오디오로 변환
-
Mel-spectrogram
소리를 분석하거나 딥러닝 모델에 입력으로 사용하기 위해 주파수 대역을 인간 청각에 맞춰 변환한 spectrogram
인간의 청각은 낮은 주파수에서는 높은 해상도를, 높은 주파수에서는 낮은 해상도를 가지므로, 이를 반영해 주파수 축을 변환
프레임 분할 → STFS 적용 → Mel 스케일로 변환 → 로그 압축(log-compression)
일반 스펙트로그램은 선형 주파수 스케일로 주파수를 분석하며, 주파수 축의 단위는 Hz
HiFi GAN은 2번째 step 집중
기존 시도들
autoregressive
WaveNet : an autoregressive (AR) convolutional neural network
단점 : AR이라 느림
Flow-based generative models
Parallel WaveNet : WaveNet을 teacher 모델로 사용 , Kullback-Leibler divergence를 min 하는 방향으로 학습 (inverse autoregressive flow (IAF))
1000배 스피드 향상
WaveGlow : distilling a teacher model 필요 없음 하지만, 파라미터 양 많음
GAN
MelGAN : 멀티 스케일 아키텍처를 제안, 서로 다른 스케일의 원시 파형(raw waveform)에 대해 작동하는 여러 discriminators 도입
Parallel wavegan : 멀티 해상도 STFT 손실 함수를 제안
GAN-TTS : 여러 크기의 윈도우를 가진 discriminators 사용 , mel-spectrogram이 아닌 언어적 특징으로부터 직접 고품질의 원시 오디오 파형을 생성, 연산량 감소
HiFi GAN
음성 신호는 다양한 주기의 사인 신호(sinusoidal signal)로 구성 → 주기적인 패턴을 모델링하는 것이 현실감 있는 음성을 생성하는 데 중요
so, 특정 주기적인 부분만을 추출하여 학습하는 여러 small sub-discriminators 로 구성된 discriminators 제안
성능 및 결과
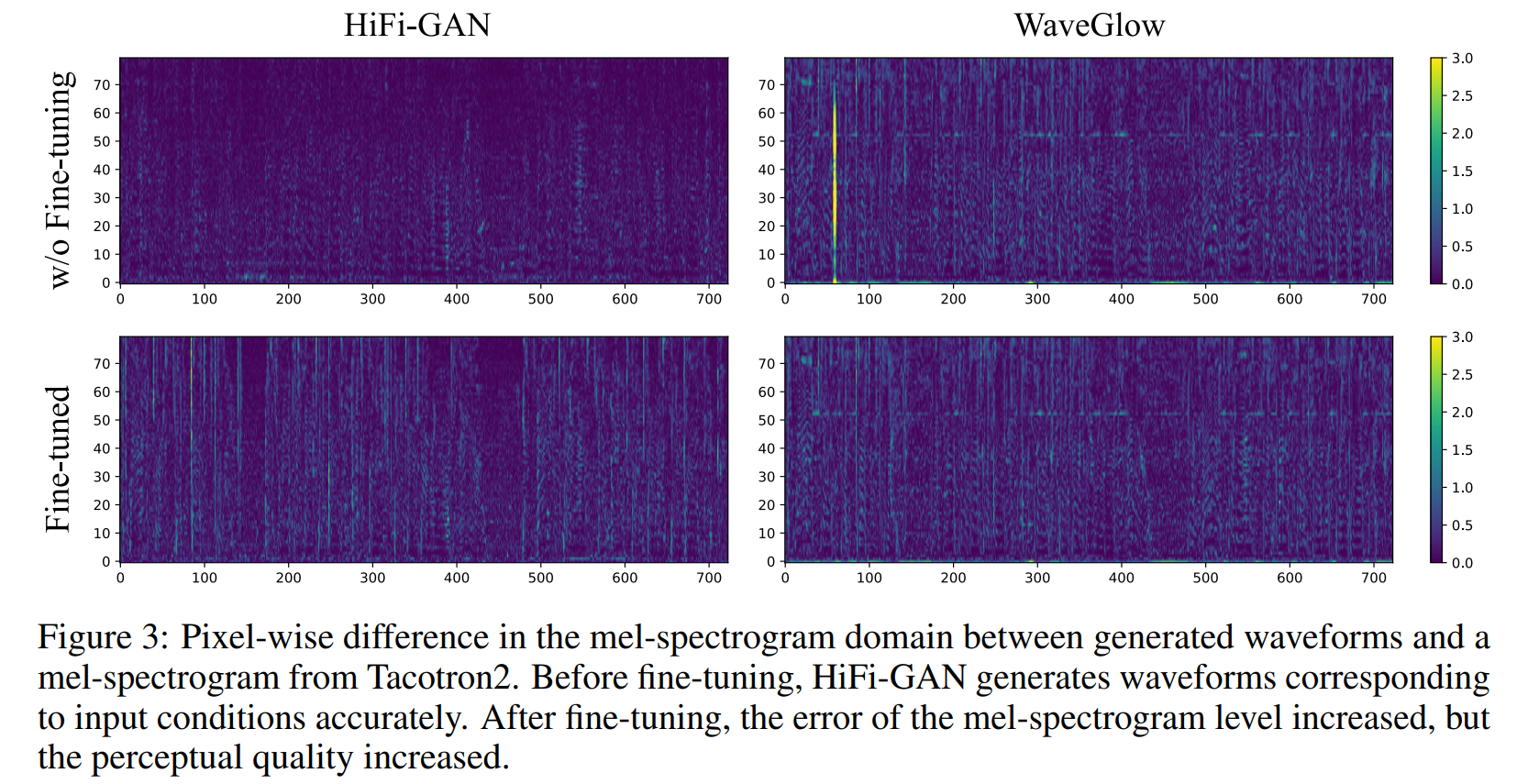
- MOS(Mean Opinion Score) 점수: HiFi-GAN은 기존의 공개된 최고의 모델들인 WaveNet과 WaveGlow보다 높은 MOS 점수를 기록했습니다. MOS 점수는 음성의 품질을 평가하는 척도로, 높은 점수는 높은 음질을 의미합니다.
- 합성 속도:
- V100 GPU에서 HiFi-GAN은 3.7 MHz의 속도로 사람 수준의 음성을 생성할 수 있습니다.
- 일반화 성능:
- HiFi-GAN은 새로운 화자에 대한 mel-spectrogram 인버전과 종단 간(end-to-end) 음성 합성에서도 좋은 성능을 보였습니다.
- 경량 모델:
- HiFi-GAN의 작은 버전은 0.92M 파라미터만을 사용하며, 기존 최고의 모델보다도 뛰어난 성능을 보였습니다.
- HiFi-GAN의 가장 빠른 버전은 CPU에서 실시간보다 13.44배 빠르게, V100 GPU에서 실시간보다 1,186배 빠르게 샘플링을 진행합니다. 성능은 AR 기반 모델과 비슷한 수준을 유지합니다.
3. HiFi-GAN
one generator and two discriminators
Generator
The generator is a fully convolutional neural network
mel-spectrogram을 입력으로 사용
출력 시퀀스의 길이가 raw waveforms의 temporal resolution과 일치할 때까지 transposed convolutions을 통해 업샘플링
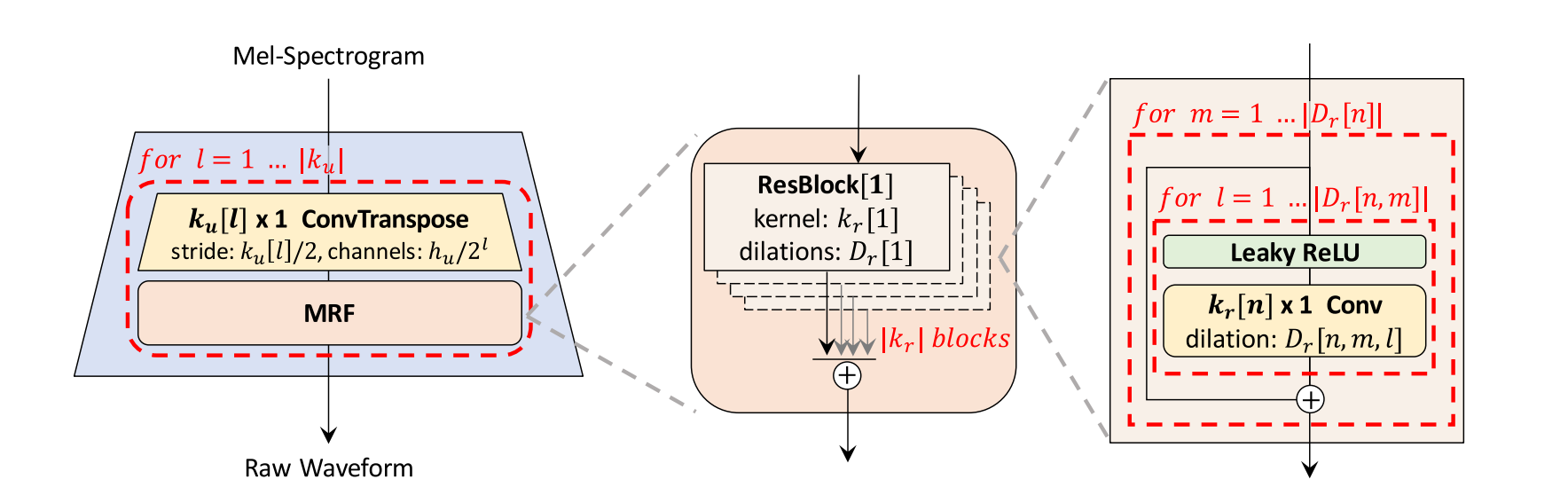
| Figure 1: The generator upsamples mel-spectrograms up to | ku | times to match the temporal resolution of raw waveforms. A MRF module adds features from | kr | residual blocks of different kernel sizes and dilation rates. Lastly, the n-th residual block with kernel size kr[n] and dilation rates Dr[n] in a MRF module is depicted. |
모든 transposed convolutions 뒤, multi-receptive field fusion (MRF) module가 이어짐
Multi-Receptive Field Fusion
제너레이터를 위해 다양한 길이의 패턴을 병렬로 관찰하는 모듈을 설계
multi-receptive field fusion (MRF) 모듈은 multiple residual blocks의 출력 합계를 반환
Different kernel sizes and dilation rates은 each residual block to form diverse receptive field patterns를 통해 선택
hidden dimension \(h_u\), 전치된 컨볼루션의 kernel sizes \(k_u\), kernel sizes \(k_r\), MRF 모듈의 dilation \(D_r\) 을 합성 효율과 샘플 품질 간의 균형을 고려하여 자신의 요구 사항에 맞게 조절 가능
Discriminator
Identifying long-term dependencies는 realistic한 audio modeling에 핵심
장기 의존성 문제 : increasing receptive fields 로 해결
다양한 주기적 패턴의 중요성 : Multi-Period Discriminator, MPD 제안, 여러 서브-판별기로 구성되며, 각 서브-판별기가 입력 오디오의 특정 주기 신호를 담당
Multi-Scale Discriminator, MSD : MSD는 오디오 샘플을 여러 레벨에서 연속적으로 평가함으로써 연속적인 패턴과 장기적인 의존성을 포착
Multi-Period Discriminator
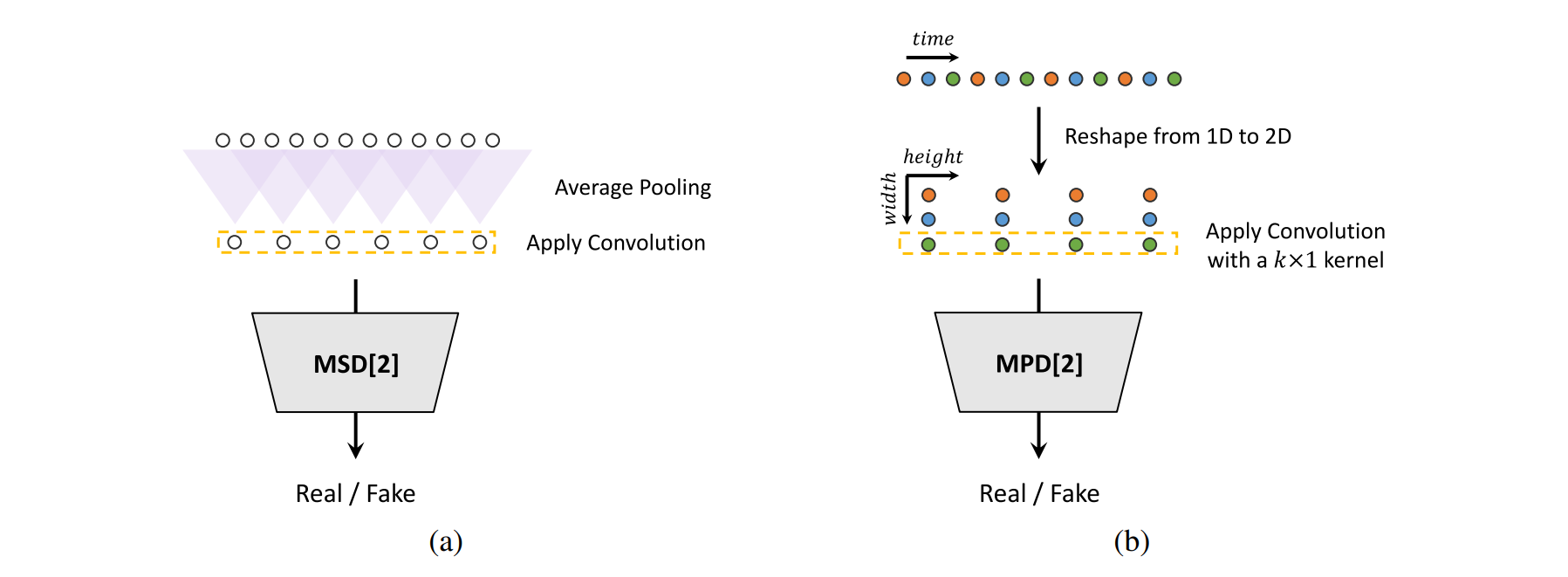
Figure 2: (a) The second sub-discriminator of MSD. (b) The second sub-discriminator of MPD with period 3.
여러 서브-판별기로 구성된 구조로, 각 서브-판별기는 일정한 간격(period p)으로 샘플링된 오디오 데이터를 입력
서브-판별기들은 서로 다른 p 값을 사용하여 오디오의 다른 부분을 분석 → 서로 다른 구조를 학습하도록 설계
겹치지 않도록 하기 위해 p 값은 [2, 3, 5, 7, 11]로 설정
MPD는 길이 T인 1D 오디오 데이터를 T / p 높이와 p 너비를 가진 2D 데이터로 변환 → 2D 컨볼루션을 적용
모든 컨볼루션 층에서 너비 축의 커널 크기를 1로 제한하여 주기적인 샘플들을 독립적으로 처리
각 서브-판별기는 스트라이드 컨볼루션 층과 leaky ReLU 활성화 함수로 구성, 가중치 정규화가 적용
이러한 2D 변환 방식 덕분에 MPD의 기울기 정보가 입력 오디오의 모든 시간 단계에 전달
Multi-Scale Discriminator
Multi-Period Discriminator (MPD)에서 각 서브-판별기가 불연속적인 샘플만 처리
연속적인 오디오 시퀀스를 평가하기 위해 Multi-Scale Discriminator (MSD)가 추가
MSD는 MelGAN에서 도입된 구조로, 세 가지 스케일(원시 오디오, ×2 평균 풀링 오디오, ×4 평균 풀링 오디오)에서 작동하는 서브-판별기로 구성
각 서브-판별기는 스트라이드와 그룹화된 컨볼루션 층 및 leaky ReLU 활성화를 사용하며, 크기는 스트라이드를 줄이고 층을 추가해 확장
가중치 정규화는 첫 번째 서브-판별기를 제외한 모든 서브-판별기에 적용되며, 첫 번째 서브-판별기에는 스펙트럼 정규화가 적용되어 안정적인 학습을 지원
MPD는 원시 파형에서 불연속 샘플을 처리하는 반면, MSD는 스무딩된 파형을 처리
Training Loss Terms
GAN Loss
\[\mathcal{L}_{\text{Adv}}(D; G) = \mathbb{E}_{(x, s)} \left[ \left( D(x) - 1 \right)^2 + \left( D(G(s)) \right)^2 \right]\] \[\mathcal{L}_{\text{Adv}}(G; D) = \mathbb{E}_s \left[ \left( D(G(s)) - 1 \right)^2 \right]\]- 생성기(G)와 판별기(D)는 LSGAN(Least Squares GAN) 방식으로 학습
- 판별기는 실제 오디오 샘플을 1로, 생성된 샘플을 0으로 분류하도록 학습
- 생성기는 판별기가 생성된 샘플을 진짜로 분류하도록 오디오 품질을 높이는 방향으로 학습
Mel-Spectrogram Loss
\[\mathcal{L}_{\text{Mel}}(G) = \mathbb{E}_{(x, s)} \left[ \left\| \phi(x) - \phi(G(s)) \right\|_1 \right]\]- 생성된 오디오가 입력 조건에 맞는 실제 오디오와 유사한 스펙트로그램을 가지도록 학습
- 멜 스펙트로그램 손실은 실제 오디오와 생성된 오디오의 스펙트로그램 사이의 L1 거리로 정의
Feature Matching Loss
\[\mathcal{L}_{\text{FM}}(G; D) = \mathbb{E}_{(x, s)} \left[ \frac{1}{T} \sum_{i=1}^{T} \frac{1}{N_i} \left\| D^i(x) - D^i(G(s)) \right\|_1 \right]\]- 판별기의 중간 특징 차이를 이용하여 학습 안정성을 높이고, 생성기가 더 높은 품질의 오디오를 생성하도록 돕는 loss
- 실제 샘플과 생성된 샘플 사이의 중간 특징의 L1 거리를 계산하여 정의
Final Loss
\[\mathcal{L}_G = \mathcal{L}_{\text{Adv}}(G; D) + \lambda_{\text{fm}} \mathcal{L}_{\text{FM}}(G; D) + \lambda_{\text{mel}} \mathcal{L}_{\text{Mel}}(G)\] \[\mathcal{L}_D = \mathcal{L}_{\text{Adv}}(D; G)\]- 최종 생성기 손실은 GAN 손실, 특징 매칭 손실, 멜 스펙트로그램 손실의 가중치 합으로 정의
- 최종 판별기 손실은 GAN 손실로 정의되며, MPD와 MSD의 각 서브-판별기에 대해 개별적으로 계산
Loss with Sub-Discriminators
\[\mathcal{L}_G = \sum_{k=1}^{K} \left[ \mathcal{L}_{\text{Adv}}(G; D_k) + \lambda_{\text{fm}} \mathcal{L}_{\text{FM}}(G; D_k) \right] + \lambda_{\text{mel}} \mathcal{L}_{\text{Mel}}(G)\] \[\mathcal{L}_D = \sum_{k=1}^{K} \mathcal{L}_{\text{Adv}}(D_k; G)\]Experiments
LJSpeech, VCTK 데이터셋 사용
2.5M 스텝까지 학습
음량 차이에 따른 평가에 영향을 방지하기 위해 모든 음성 클립을 정규화
훈련 설정:
- 입력 조건으로 80 밴드의 멜-스펙트로그램을 사용
- FFT, window, hop size는 각각 1024, 1024, 256으로 설정
- AdamW 옵티마이저(β1=0.8, β2=0.99, weight decay λ=0.01)를 사용했고, 초기 학습률은 2 × 10^−4로 설정하여 매 에포크마다 0.999 배수로 감소
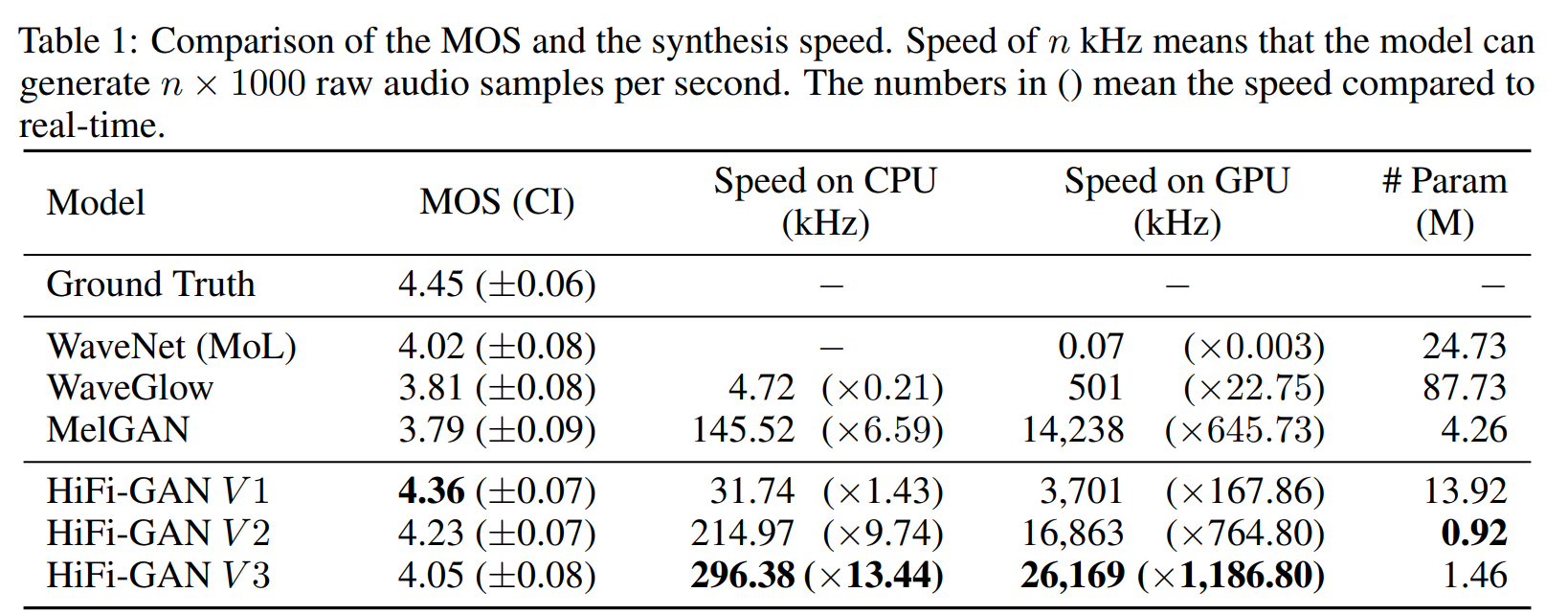
비교