
[코드분석] video diffusion model 코드 분석
Inha univ. VDM 코드 분석 및 예제 학습 돌리기
video diffusion model 코드 분석
https://github.com/lucidrains/video-diffusion-pytorch 의 코드를 참고
1. Dataset
class Dataset(data.Dataset):
def __init__(
self,
folder,
image_size,
channels = 3,
num_frames = 16,
horizontal_flip = False,
force_num_frames = True,
exts = ['gif']
):
super().__init__()
self.folder = folder
self.image_size = image_size
self.channels = channels
self.paths = [p for ext in exts for p in Path(f'{folder}').glob(f'**/*.{ext}')]
self.cast_num_frames_fn = partial(cast_num_frames, frames = num_frames) if force_num_frames else identity
self.transform = T.Compose([
T.Resize(image_size),
T.RandomHorizontalFlip() if horizontal_flip else T.Lambda(identity),
T.CenterCrop(image_size),
T.ToTensor()
])
def __len__(self):
return len(self.paths)
def __getitem__(self, index):
path = self.paths[index]
tensor = gif_to_tensor(path, self.channels, transform = self.transform)
return self.cast_num_frames_fn(tensor)
torch.utils에서 제공하는 dataset class를 상속 받아 사용
getitem을 통해 하나씩 dataset을 불러옴
2. GaussianDiffusion
2.1 Training part
forward
모델의 Foward pass 계산을 정의
- 주어진 입력 이미지에 대해 랜덤 타임스텝
t를 선택 - normalize
- loss 계산
한번에 모든 step을 학습하는 것이 아니라, 각 미니 배치에서 하나의 랜덤 step을 선택하여 학습
p_losses
- 현재 타임스텝에서 노이즈를 추가
- denoise 함수로 예측된 노이즈와 실제 노이즈 간의 차이를 기반으로 손실(loss)을 계산
noise = default(noise, lambda: torch.randn_like(x_start))
다음 코드를 통해 랜덤한 노이즈를 생성 (Noise == None)
x_noisy = self.q_sample(x_start=x_start, t=t, noise=noise)
노이즈가 섞인 데이터 x_noisy를 생성
x_recon = self.denoise_fn(x_noisy, t, cond = cond, **kwargs)
노이즈가 섞인 데이터 노이즈 제거 함수를 사용하여 이미지를 예측하는 과정
denoise_fn 는 Unet3D을 기본적으로 사용
q_sample
주어진 x_start에 노이즈를 추가하여 t 타임스텝의 이미지를 생성
입력:
x_start: 원본 이미지.t: 타임스텝.noise: 노이즈.
alphas_cumprod = torch.cumprod(alphas, axis=0)
alphas_cumprod_prev = F.pad(alphas_cumprod[:-1], (1, 0), value = 1.)
register_buffer('sqrt_alphas_cumprod', torch.sqrt(alphas_cumprod))
register_buffer('sqrt_one_minus_alphas_cumprod', torch.sqrt(1. - alphas_cumprod))
확산 모델(DDPM)에서 사용되는 베타 스케줄(beta schedule)과 관련된 alphas 값을 누적곱한 결과를 저장
alphas는 1 - betas로 계산
alphas는 각 타임스텝에서 원본 데이터의 기여도를 결정하는 값betas는 노이즈의 비율을 의미하고,alphas는 원본 데이터의 비율을 의미
각 타임스텝에서 원본 데이터의 기여도가 누적되어 계산된 값
\[\mathrm{alphas\_cumprod\_prev}=[1,a_1,a_1⋅a_2,a_1⋅a_2⋅a_3,…]\]마지막 값을 제외한 모든 값 + 타임스텝이 하나 씩 뒤로 밀림
diffusion model에서 posterior 분포를 계산할 때 사용
def extract(a, t, x_shape):
b, *_ = t.shape
out = a.gather(-1, t) # 배치 내의 각 샘플에 대해 개별적인 타임스텝 값을 추출
return out.reshape(b, *((1,) * (len(x_shape) - 1))) # out을 입력 데이터 x_shape에 맞춰 모양을 변형하는 부분
주어진 타임스텝 t에 해당하는 a의 값을 추출하고, 이를 입력 데이터 x_start와 곱할 수 있도록 모양을 변형
다음 함수를 통해 출력 되는 값은 특정 타임스텝 t에서 원본 데이터 x_start에 노이즈를 추가한 데이터
즉, q_sample 함수는 원본 데이터 x_start에서 시작하여 노이즈로 완전히 변환되기까지의 확산 과정에서, 특정 타임스텝 t를 지정하고 그 사이의 중간 단계들을 생성하는 함수
2.2 Sampling
sample
sampling과정에서 가장 먼저 호출되는 함수
입력:
cond: 조건부 입력.cond_scale: 조건부 스케일링.batch_size: 배치 크기.
device = next(self.denoise_fn.parameters()).device : 파라미터가 존재하는 디바이스(GPU 또는 CPU)
condition 뽑는 과정 : 여기서는 bert 사용
self.p_sample_loop 에서 실제 연산 진행
p_sample_loop
sampling step을 거치면서 이미지 생성 [Reverse process]
img = torch.randn(shape, device=device)
랜덤 값에서 시작
for i in tqdm(reversed(range(0, self.num_timesteps)), desc='sampling loop time step', total=self.num_timesteps):
img = self.p_sample(img, torch.full((b,), i, device=device, dtype=torch.long), cond = cond, cond_scale = cond_scale)
self.p_sample을 반복
p_sample
모델을 사용해 타임스텝 t에서 샘플링
model_mean, _, model_log_variance = self.p_mean_variance(x = x, t = t, clip_denoised = clip_denoised, cond = cond, cond_scale = cond_scale)
해당 step에 예측된 분포의 평균과 분산을 가져옴 → **노이즈 제거 과정에 사용
(Diffusion Model)은 정확한 값을 예측하는 것보다는, 데이터의 분포를 추정하는 모델
\[x_{t−1}=μ_θ(x_t,t)+σ_t⋅z\]q_mean_variance
샘플링 과정에서, 주어진 타임스텝 t에서 데이터의 평균과 분산을 계산하는 함수
x_recon = self.predict_start_from_noise(x, t=t, noise=self.denoise_fn.forward_with_cond_scale(x, t, cond=cond, cond_scale=cond_scale))
모델을 활용해 데이터 예측
디노이징된 결과를 일정 범위로 클리핑 → 선택 (안정적 결과)
model_mean, posterior_variance, posterior_log_variance = self.q_posterior(x_start=x_recon, x_t=x, t=t)
주어진 타임스텝 t에서 포스터리어 분포를 계산
predict_start_from_noise
각 타임스텝에서 노이즈를 추정하여 원본 데이터를 복원
def predict_start_from_noise(self, x_t, t, noise):
return (
extract(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t -
extract(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape) * noise
)
q_posterior
포스터리어 분포(posterior distribution)를 계산
def q_posterior(self, x_start, x_t, t):
posterior_mean = (
extract(self.posterior_mean_coef1, t, x_t.shape) * x_start +
extract(self.posterior_mean_coef2, t, x_t.shape) * x_t
)
posterior_variance = extract(self.posterior_variance, t, x_t.shape)
posterior_log_variance_clipped = extract(self.posterior_log_variance_clipped, t, x_t.shape)
return posterior_mean, posterior_variance, posterior_log_variance_clipped
-
\[\mu_{t-1} = \frac{\sqrt{\bar{\alpha}_{t-1}} \beta_t}{1 - \bar{\alpha}_t} \cdot x_0 + \frac{\sqrt{\bar{\alpha}_t} (1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t} \cdot x_t\]posterior_mean: 이전 타임스텝 t−1에서의 데이터의 평균값. -
\[\sigma_{t-1}^2 = \frac{\beta_t (1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t}\]posterior_variance: 이전 타임스텝 t−1에서의 데이터의 분산값. -
\[\log \sigma_{t-1}^2 = \log\left(\frac{\beta_t (1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t}\right)\]posterior_log_variance_clipped: 로그 스케일에서 클리핑된 분산값.
2.3 Sampling flow
x_recon = self.predict_start_from_noise(x, t=t, noise = self.denoise_fn.forward_with_cond_scale(x, t, cond = cond, cond_scale = cond_scale))
다음 코드를 통해 단일 시간 단계에서의 예측을 가져옴
model_mean, posterior_variance, posterior_log_variance = self.q_posterior(x_start=x_recon, x_t=x, t=t)
예측한 값을 가지고 평균과 분산을 가져옴
평균과 분산을 사용하여 다음 시간 단계의 이미지를 생성
for i in tqdm(reversed(range(0, self.num_timesteps)), desc='sampling loop time step', total=self.num_timesteps):
img = self.p_sample(img, torch.full((b,), i, device=device, dtype=torch.long), cond = cond, cond_scale = cond_scale)
step의 반복을 통해 점진적으로 노이즈 제거
확률적 샘플링: diffusion model은 각 시간 단계에서 데이터 분포를 모델링하기 위해 확률 분포(보통 Gaussian 분포)를 사용
따라서 평균과 분산을 사용하여 이미지를 생성 가능
3. 3d U-Net
3.1 init
class Unet3D(nn.Module):
def __init__(
self,
dim,
cond_dim = None,
out_dim = None,
dim_mults=(1, 2, 4, 8),
channels = 3,
attn_heads = 8,
attn_dim_head = 32,
use_bert_text_cond = False,
init_dim = None,
init_kernel_size = 7,
use_sparse_linear_attn = True,
block_type = 'resnet'
):
super().__init__()
self.channels = channels
# temporal attention and its relative positional encoding
rotary_emb = RotaryEmbedding(min(32, attn_dim_head))
temporal_attn = lambda dim: EinopsToAndFrom('b c f h w', 'b (h w) f c', Attention(dim, heads = attn_heads, dim_head = attn_dim_head, rotary_emb = rotary_emb))
self.time_rel_pos_bias = RelativePositionBias(heads = attn_heads, max_distance = 32) # realistically will not be able to generate that many frames of video... yet
-
RotaryEmbedding로터리 임베딩은 어텐션 메커니즘에서 시간적 순서를 표현하는 데 사용
-
temporal_attn3D 데이터에서 시간적 어텐션을 적용하는 함수데이터 shape을 변형 → Attention에 대입
-
RelativePositionBias어텐션 메커니즘에서 상대적인 위치 정보를 학습하기 위해 사용
class RelativePositionBias(nn.Module): def __init__( self, heads = 8, num_buckets = 32, max_distance = 128 ): super().__init__() self.num_buckets = num_buckets self.max_distance = max_distance self.relative_attention_bias = nn.Embedding(num_buckets, heads) @staticmethod def _relative_position_bucket(relative_position, num_buckets = 32, max_distance = 128): ret = 0 n = -relative_position num_buckets //= 2 ret += (n < 0).long() * num_buckets n = torch.abs(n) max_exact = num_buckets // 2 is_small = n < max_exact val_if_large = max_exact + ( torch.log(n.float() / max_exact) / math.log(max_distance / max_exact) * (num_buckets - max_exact) ).long() val_if_large = torch.min(val_if_large, torch.full_like(val_if_large, num_buckets - 1)) ret += torch.where(is_small, n, val_if_large) return ret def forward(self, n, device): q_pos = torch.arange(n, dtype = torch.long, device = device) k_pos = torch.arange(n, dtype = torch.long, device = device) rel_pos = rearrange(k_pos, 'j -> 1 j') - rearrange(q_pos, 'i -> i 1') rp_bucket = self._relative_position_bucket(rel_pos, num_buckets = self.num_buckets, max_distance = self.max_distance) values = self.relative_attention_bias(rp_bucket) return rearrange(values, 'i j h -> h i j')
# initial conv
init_dim = default(init_dim, dim)
assert is_odd(init_kernel_size)
init_padding = init_kernel_size // 2
self.init_conv = nn.Conv3d(channels, init_dim, (1, init_kernel_size, init_kernel_size), padding = (0, init_padding, init_padding))
self.init_temporal_attn = Residual(PreNorm(init_dim, temporal_attn(init_dim)))
# dimensions
dims = [init_dim, *map(lambda m: dim * m, dim_mults)]
in_out = list(zip(dims[:-1], dims[1:]))
# time conditioning
time_dim = dim * 4
self.time_mlp = nn.Sequential(
SinusoidalPosEmb(dim),
nn.Linear(dim, time_dim),
nn.GELU(),
nn.Linear(time_dim, time_dim)
)
-
init_conv처음 입력되는 3D 데이터를 처리하는 Convolution 레이어로, 시간 축에 대해서는 변화가 없고, 공간적인 차원만 커널을 적용
-
init_temporal_attn시간 축에 대한 어텐션 메커니즘을 적용하여, 시계열 데이터나 비디오 데이터에서 시간적인 관계를 학습
-
time_mlp시간 정보(예: timestep) 처리를 위한 다층 퍼셉트론(MLP)으로, Sinusoidal 임베딩을 통해 시간 정보를 주기적인 함수로 변환
# text conditioning
self.has_cond = exists(cond_dim) or use_bert_text_cond
cond_dim = BERT_MODEL_DIM if use_bert_text_cond else cond_dim
self.null_cond_emb = nn.Parameter(torch.randn(1, cond_dim)) if self.has_cond else None
cond_dim = time_dim + int(cond_dim or 0)
# layers
self.downs = nn.ModuleList([])
self.ups = nn.ModuleList([])
num_resolutions = len(in_out)
# block type
block_klass = ResnetBlock
block_klass_cond = partial(block_klass, time_emb_dim = cond_dim)
- text conditioning
# modules for all layers
for ind, (dim_in, dim_out) in enumerate(in_out):
is_last = ind >= (num_resolutions - 1)
self.downs.append(nn.ModuleList([
block_klass_cond(dim_in, dim_out),
block_klass_cond(dim_out, dim_out),
Residual(PreNorm(dim_out, SpatialLinearAttention(dim_out, heads = attn_heads))) if use_sparse_linear_attn else nn.Identity(),
Residual(PreNorm(dim_out, temporal_attn(dim_out))),
Downsample(dim_out) if not is_last else nn.Identity()
]))
mid_dim = dims[-1]
self.mid_block1 = block_klass_cond(mid_dim, mid_dim)
spatial_attn = EinopsToAndFrom('b c f h w', 'b f (h w) c', Attention(mid_dim, heads = attn_heads))
self.mid_spatial_attn = Residual(PreNorm(mid_dim, spatial_attn))
self.mid_temporal_attn = Residual(PreNorm(mid_dim, temporal_attn(mid_dim)))
self.mid_block2 = block_klass_cond(mid_dim, mid_dim)
for ind, (dim_in, dim_out) in enumerate(reversed(in_out)):
is_last = ind >= (num_resolutions - 1)
self.ups.append(nn.ModuleList([
block_klass_cond(dim_out * 2, dim_in),
block_klass_cond(dim_in, dim_in),
Residual(PreNorm(dim_in, SpatialLinearAttention(dim_in, heads = attn_heads))) if use_sparse_linear_attn else nn.Identity(),
Residual(PreNorm(dim_in, temporal_attn(dim_in))),
Upsample(dim_in) if not is_last else nn.Identity()
]))
out_dim = default(out_dim, channels)
self.final_conv = nn.Sequential(
block_klass(dim * 2, dim),
nn.Conv3d(dim, out_dim, 1)
)
U-Net에 맞게 block 쌓기
3.2 Foward
- 초기 layer
focus_present_mask = default(focus_present_mask, lambda: prob_mask_like((batch,), prob_focus_present, device = device))
time_rel_pos_bias = self.time_rel_pos_bias(x.shape[2], device = x.device)
x = self.init_conv(x)
x = self.init_temporal_attn(x, pos_bias = time_rel_pos_bias)
r = x.clone()
t = self.time_mlp(time) if exists(self.time_mlp) else None
positional embedding + 초기 init_conv
- condition
if self.has_cond:
batch, device = x.shape[0], x.device
mask = prob_mask_like((batch,), null_cond_prob, device = device)
cond = torch.where(rearrange(mask, 'b -> b 1'), self.null_cond_emb, cond)
t = torch.cat((t, cond), dim = -1)
condition을 input x에 concat 해서 대입
- U-net
# classifier free guidance
if self.has_cond:
batch, device = x.shape[0], x.device
mask = prob_mask_like((batch,), null_cond_prob, device = device)
cond = torch.where(rearrange(mask, 'b -> b 1'), self.null_cond_emb, cond)
t = torch.cat((t, cond), dim = -1)
h = []
for block1, block2, spatial_attn, temporal_attn, downsample in self.downs:
x = block1(x, t)
x = block2(x, t)
x = spatial_attn(x)
x = temporal_attn(x, pos_bias = time_rel_pos_bias, focus_present_mask = focus_present_mask)
h.append(x)
x = downsample(x)
x = self.mid_block1(x, t)
x = self.mid_spatial_attn(x)
x = self.mid_temporal_attn(x, pos_bias = time_rel_pos_bias, focus_present_mask = focus_present_mask)
x = self.mid_block2(x, t)
for block1, block2, spatial_attn, temporal_attn, upsample in self.ups:
x = torch.cat((x, h.pop()), dim = 1)
x = block1(x, t)
x = block2(x, t)
x = spatial_attn(x)
x = temporal_attn(x, pos_bias = time_rel_pos_bias, focus_present_mask = focus_present_mask)
x = upsample(x)
x = torch.cat((x, r), dim = 1)
return self.final_conv(x)
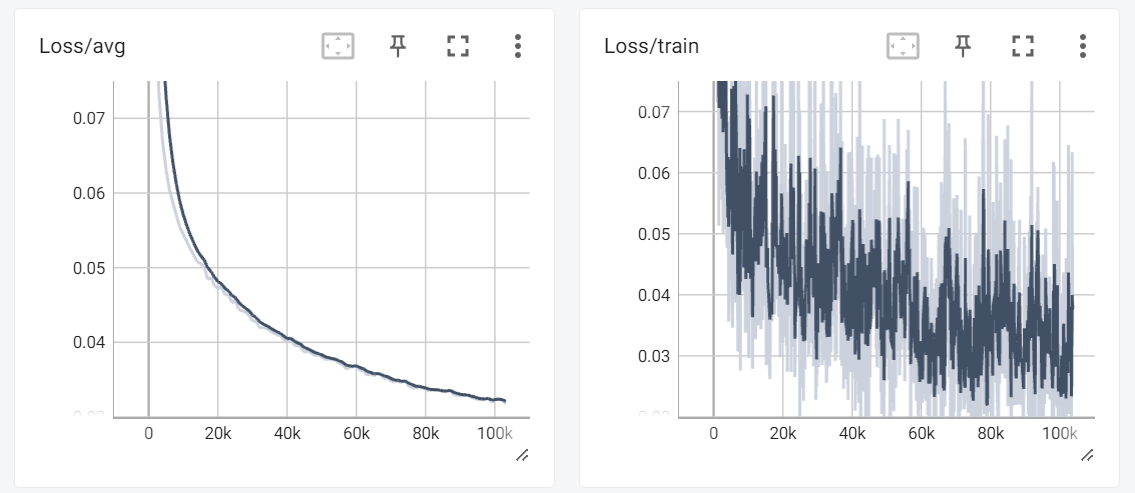
4. Run code
dataset : fireworks
step : 약 100000
gpu : a6000
import torch
from video_diffusion_pytorch import Unet3D, GaussianDiffusion, Trainer
model = Unet3D(
dim = 64,
dim_mults = (1, 2, 4, 8),
)
diffusion = GaussianDiffusion(
model,
image_size = 64,
num_frames = 10,
timesteps = 1000, # number of steps
loss_type = 'l1' # L1 or L2
).cuda()
trainer = Trainer(
diffusion,
'./dataset', # this folder path needs to contain all your training data, as .gif files, of correct image size and number of frames
train_batch_size = 16,
train_lr = 1e-4,
save_and_sample_every = 1000,
train_num_steps = 700000, # total training steps
gradient_accumulate_every = 2, # gradient accumulation steps
ema_decay = 0.995, # exponential moving average decay
amp = True # turn on mixed precision
)
trainer.train()



참고자료
https://github.com/lucidrains/denoising-diffusion-pytorch
http://dmqm.korea.ac.kr/activity/seminar/411