
[프로젝트] Korean Audio, Multilingual Hubert translate Training Guideline
Inha univ. | 기존 Unit based audio Multilingual translate으로 제안된 논문에 Korean을 추가
ECE Capston design
🎈 SG2Video challenge 정리한 페이지 바로가기 🎈
최근 Audio2Audio multilingual translate에서 hubert를 활용한 direct translation이 제안되었다.
Textless Unit-to-Unit training for Many-to-Many Multilingual Speech-to-Speech Translation
AV2AV: Direct Audio-Visual Speech to Audio-Visual Speech Translation with Unified Audio-Visual Speech Representation
논문에서는 다양한 언어를 지원하지만, 한국어를 지원하지는 않는다.
그래서 한글도 같이 지원하도록 모델을 학습하는 것이 목표이다.
현재 Training code가 제공되지 않기 때문에, 자세한 가이드라인도 같이 제공하고자 한다.
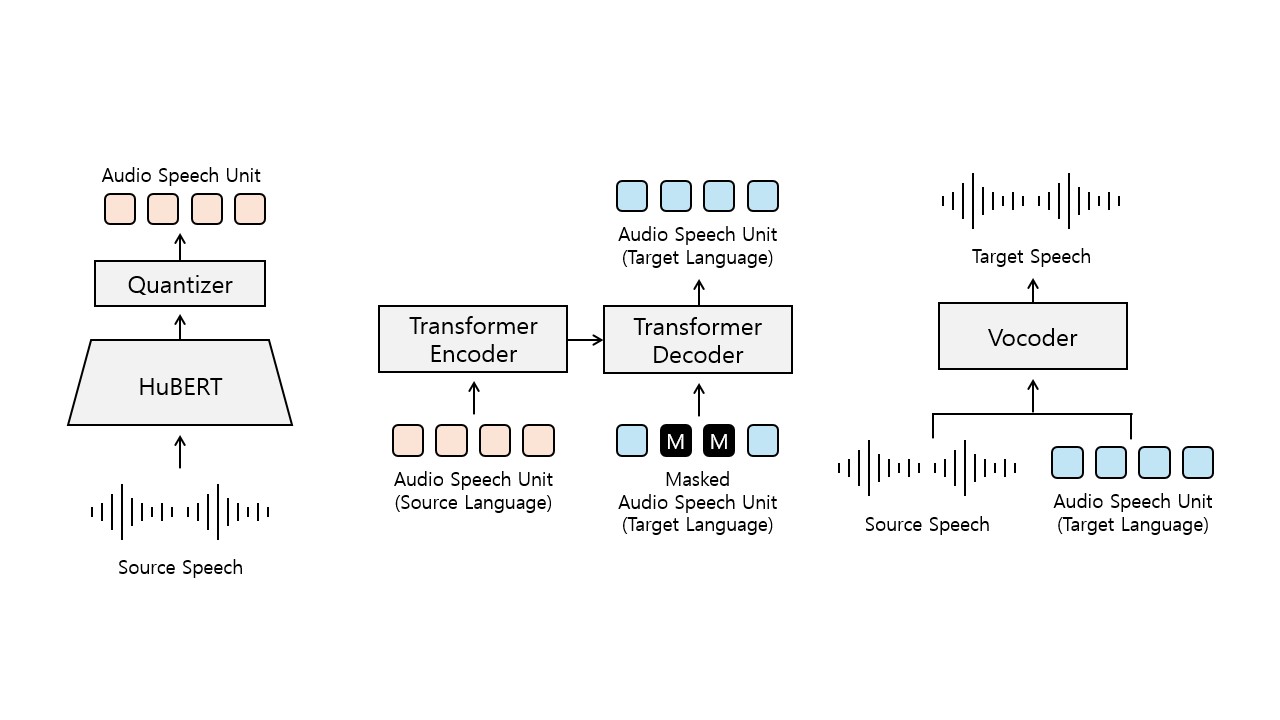
fairseq를 기반으로 코드 작성
관련 논문 분석
목차
Hubert preprocessing
wave2vec manifest → mmfc → sample kmean
출처
https://github.com/facebookresearch/fairseq/blob/main/examples/wav2vec/README.md
https://github.com/facebookresearch/fairseq/blob/main/examples/hubert/simple_kmeans/README.md
-
manifest 생성
역할 : 오디오 파일의 경로와 해당 길이를 명시하여 데이터셋을 체계적으로 관리
학습(training)과 검증(validation) 데이터 분할
파일 형식 :
.tsv(Tab-Separated Values) 형식으로 저장- 첫 번째 줄: 헤더 (경로, 파일 길이)
- 이후 각 줄: 개별 오디오 파일의 경로와 길이(초 단위)
논문에서 10~30초 길이의 오디오 파일을 사용
Python의
soundfile라이브러리 설치 (pip install soundfile)python examples/wav2vec/wav2vec_manifest.py /path/to/waves --dest /manifest/path --ext $ext --valid-percent $valid/path/to/waves: 오디오 파일이 있는 디렉토리.-dest /manifest/path: 생성된 manifest 파일을 저장할 경로.-ext $ext: 오디오 파일의 확장자 (예: wav, flac 등).-valid-percent $valid: 학습 데이터에서 검증 데이터로 사용할 비율 (예: 0.01 = 1%).
-
mmfc 생성
역할 : MFCC는 사람의 청각 감각과 유사한 방식으로 음성 신호를 분석해, 중요한 특징을 저차원적으로 요약
주파수 정보를 효율적으로 표현, 음성의 타이밍, 음조, 음질과 같은 중요한 정보를 포함
- Pre-emphasis: 신호의 고주파 성분을 강화, 잡음을 줄이고 신호의 정보 균등
- 신호의 고주파 성분을 강화하면, 잡음이 늘어나는거 아닌가?
- 고주파 신호와 잡음을 동일한 비율로 증가
- 고주파 성분에는 발음 구별에 중요한 정보(자음 등)가 포함
- 음성 신호는 일반적으로 4~8kHz의 대역폭, 노이즈는 이것보다 더 큼
- 신호의 고주파 성분을 강화하면, 잡음이 늘어나는거 아닌가?
- Framing: 신호 분할, 일반적으로 프레임 크기는 20-40ms
- Windowing: 각 프레임에 윈도우 함수를 적용 → 신호의 경계를 soft하게 만듬(주로 Hamming 윈도우 사용)
- Fourier Transform: 각 프레임에 대해 FFT(Fast Fourier Transform)를 수행, 주파수 스펙트럼을 계산
- Mel Filter Bank: 인간의 청각 감각에 기반하여 Mel scale로 fliter를 적용
- 저주파는 자세히, 고주파는 덜 자세히 표현.
- Logarithm: Mel 필터 출력에 로그를 취하여 음성 신호의 크기 차이를 줄임
- Discrete Cosine Transform (DCT): 로그 스펙트럼을 시간 영역으로 변환 → MFCC 벡터를 생성 , 보통 상위 12~13개의 계수를 사용하며, 이로부터 delta(속도 정보)와 delta-delta(가속도 정보) 계수를 추가로 계산
.npy또는.len형식으로 저장python dump_mfcc_feature.py ${tsv_dir} ${split} ${nshard} ${rank} ${feat_dir}${tsv_dir}: 데이터셋 manifest 파일의 디렉토리.${split}: 데이터를 분리한 종류(e.g., train, valid).${nshard}: 전체 데이터를 몇 개의 샤드(shard)로 나눌지 설정.${rank}: 처리할 샤드 번호 (0부터 시작).
- Pre-emphasis: 신호의 고주파 성분을 강화, 잡음을 줄이고 신호의 정보 균등
-
K-means clustering
feature를 데이터를 기반으로 K-means 클러스터링을 실행
python learn_kmeans.py ${feat_dir} ${split} ${nshard} ${km_path} ${n_clusters} --percent 0.1### 파라미터 설명
${feat_dir}: 추출된 특징(feature)이 저장된 디렉토리.${split}: 데이터 분할 이름 (e.g., train, valid).${nshard}: 데이터셋을 나누는 샤드 개수.${km_path}: 학습된 K-means 모델이 저장될 경로.${n_clusters}: K-means 클러스터 개수 (e.g., 100, 500, 1000).-percent:- 사용할 데이터의 비율. 10% 데이터를 사용할 경우
0.1. 1로 설정하면 전체 데이터를 사용.
- 사용할 데이터의 비율. 10% 데이터를 사용할 경우
-
K-means application
학습된 K-means 모델을 사용해 특징 데이터에 클러스터 레이블 할당
python dump_km_label.py ${feat_dir} ${split} ${km_path} ${nshard} ${rank} ${lab_dir}${feat_dir}: 특징(feature)이 저장된 디렉토리.${split}: 데이터 분할 이름 (e.g., train, valid).${km_path}: 학습된 K-means 모델 경로.${nshard}: 샤드 개수.${rank}: 처리할 샤드의 순번 (0부터 시작).${lab_dir}: 레이블이 저장될 디렉토리
${lab_dir}/${split}_${rank}_${shard}.km형식으로 저장샤드별로 저장된 레이블 파일을 하나로 병합.
for rank in $(seq 0 $((nshard - 1))); do cat $lab_dir/${split}_${rank}_${nshard}.km done > $lab_dir/${split}.km${lab_dir}/${split}.km -
Create a dummy dict
레이블과 가중치를 HuBERT 훈련에 사용할 수 있도록 사전 형식으로 저장
for x in $(seq 0 $((n_clusters - 1))); do echo "$x 1" done >> $lab_dir/dict.km.txt더미 사전 파일
${lab_dir}/dict.km.txt
Hubert training
학습을 위해 필요한 데이터 목록
{train, valid}.tsv : manifest 파일
{train, valid}.km : K-means application 파일
dict.km.txt: dummy dict 파일
hubert pre-train
$ python fairseq_cli/hydra_train.py \
--config-dir /path/to/fairseq-py/examples/hubert/config/pretrain \
--config-name hubert_base_librispeech \
task.data=/path/to/data task.label_dir=/path/to/labels task.labels='["km"]' model.label_rate=100
hubert fine-tuning
$ python fairseq_cli/hydra_train.py \
--config-dir /path/to/fairseq-py/examples/hubert/config/finetune \
--config-name base_10h \
task.data=/path/to/data task.label_dir=/path/to/trans \
model.w2v_path=/path/to/checkpoint
Transformer 학습을 위한 Data preprocessing
- Hubert inference 돌리기
이전에 학습된 Hubert 모델을 가지고 Multilingual dataset을 Unit으로 변경
위 2개 파일 fairseq 폴더에 넣기
cd fairseq
python inference.py \
--in-wav-path <wav파일경로> \
--out-unit-path <unit출력저장경로> \
--mhubert-path <모델파라미터경로> \
--kmeans-path <k-means파일경로>
- 데이터 파일 안에 내용 txt 파일로 저장
파일이 해당 Unit 데이터를 쉽게 찾을 수 있도록 함
find /home/jskim/audio/dataset/units/en/ -maxdepth 1 -name '*.unit' | sort > en_files.txt
find /home/jskim/audio/dataset/units/es/ -maxdepth 1 -name '*.unit' | sort > es_files.txt
find /home/jskim/audio/dataset/units/fr/ -maxdepth 1 -name '*.unit' | sort > fr_files.txt
- TR 학습 데이터 준비
각 언어 쌍에 대해 학습 및 검증 데이터를 생성, Fairseq에서 요구하는 형식으로 준비
dataset/
└── units/
├── en/
├── es/
└── fr/
다음과 같이 파일 구조를 만들기
각 언어의 파일 수가 동일한지 확인 → parallel corpus 맞추기
학습과 검증 데이터로 데이터를 분할. 일반적으로 90%를 학습용으로, 10%를 검증용으로 사용
# 명령행 인자 파서 설정
parser = argparse.ArgumentParser(description='다국어 데이터 준비 스크립트')
parser.add_argument('--base_dir', type=str, default='/home/jskim/audio/dataset/units',
help='입력 데이터의 기본 디렉토리 경로')
parser.add_argument('--output_base_dir', type=str, default='/home/jskim/audio/dataset/units',
help='출력 데이터가 저장될 기본 디렉토리 경로')
parser.add_argument('--languages', type=str, nargs='+', default=['en', 'es', 'fr'],
help='처리할 언어 목록 (예: en es fr)')
parser.add_argument('--train_ratio', type=float, default=0.9,
help='학습 데이터 비율 (0과 1 사이의 실수)')
parser.add_argument('--random_seed', type=int, default=42,
help='랜덤 시드 값')
args = parser.parse_args()
다음 코드로 동일한 parallel corpus 를 찾을 수 있도록 해야함
filename_pattern = re.compile(r'(.+)_([a-z]{2})_(\d+)\.unit$')
위 파일 실행 했을 때 4개 txt 파일이 나와야함
train.src, train.tgt, valid.src, valid.tgt
- fairseq Data Preprocessing
fairseq-preprocess \
--source-lang src \
--target-lang tgt \
--trainpref "/path/to/train" \
--validpref "/path/to/valid" \
--destdir "/path/to/data-bin" \
--workers 4 \
--joined-dictionary \
--dataset-impl 'mmap'
위 코드를 통해 실제 TR에 들어가는 data 구조 완성
dict 파일도 같이 들어감
여기에서는 하나의 multilingual Hubert가 들어가기 때문에 1개의 dict만 필요함
Trasformer Training code
fairseq-train '/shared/home/milab/users/jskim/multilingual' \
--arch transformer \
--share-decoder-input-output-embed \
--encoder-layers 12 \
--decoder-layers 12 \
--encoder-embed-dim 512 \
--decoder-embed-dim 512 \
--encoder-attention-heads 8 \
--decoder-attention-heads 8 \
--encoder-ffn-embed-dim 2048 \
--decoder-ffn-embed-dim 2048 \
--max-tokens 24000 \
--update-freq 2 \
--optimizer adam \
--adam-betas '(0.9, 0.98)' \
--lr 5e-4 \
--lr-scheduler inverse_sqrt \
--warmup-updates 4000 \
--dropout 0.3 \
--weight-decay 0.0001 \
--criterion label_smoothed_cross_entropy \
--label-smoothing 0.1 \
--max-epoch 50 \
--save-dir '/shared/home/milab/users/jskim/results' \
--patience 10 \
--tensorboard-logdir '/shared/home/milab/users/jskim/tensorboard_logs' \
--max-source-positions 3000 \
--max-target-positions 3000 \
--amp
Vocoder
https://github.com/facebookresearch/speech-resynthesis/tree/main/examples/speech_to_speech_translation
학습을 위해 필요한 데이터 목록
HuBERT 단위 파일 (e.g., .txt )
오디오 파일 .wav 또는 .flac
메타데이터 파일(.tsv)
JSON 파일 예제
json
코드 복사
{
"data": {
"train_wav": "/path/to/train/audio/",
"train_units": "/path/to/train/units/",
"train_durations": "/path/to/train/durations/",
"valid_wav": "/path/to/valid/audio/",
"valid_units": "/path/to/valid/units/",
"valid_durations": "/path/to/valid/durations/"
},
"training": {
"batch_size": 32,
"num_epochs": 100,
"learning_rate": 0.0002
},
"model": {
"n_units": 1000,
"hop_length": 256,
"sampling_rate": 16000
}
}
Training code
python -m torch.distributed.launch --nproc_per_node <NUM_GPUS> \
-m examples.speech_to_speech_translation.train \
--checkpoint_path checkpoints/lj_hubert100_dur1.0 \
--config examples/speech_to_speech_translation/configs/hubert100_dw1.0.json
Inference
python -m examples.speech_to_speech_translation.inference \
--checkpoint_file checkpoints/lj_hubert100_dur1.0 \
-n 10 \
--output_dir generations \
--num-gpu <NUM_GPUS> \
--input_code_file ./datasets/LJSpeech/hubert100/val.txt \
--dur-prediction