
[프로젝트] 개인 : IP-Adaptor + Scene Graph
Inha univ. Scene Graph를 Condition으로 받는 image generation diffusion model finetuning
최종적으로 Scene Graph를 가지고 Video generation을 하기 위해서 먼저 image generation을 테스트 해보고자 한다.
기존에 SGDiff 논문에서 기본 diffusion model에 SG embedding을 condition으로 넣어 pretraining 시켰을 때 SG로 Image을 control 할 수 있음을 증명했다.
하지만, 생성되는 이미지의 퀄리티가 충분하지 못했다.
따라서 기존 Stable diffusion model에 Finetuning을 하여 이미지의 퀄리티와 Graph control 두 가지를 IP-Adaptor 를 이용해 잡아보려 한다.
기존에 Image Encoder 부분을 SGDiff에 SG encoder로 대체하여 테스트 하였다.
아래 부분은 테스트 기록이다.
24-09-03
visual genome Dataset + Image Captioning model → image - text - scene graph dataset
image 먼저 해보기
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image…
https://github.com/tencent-ailab/IP-Adapter
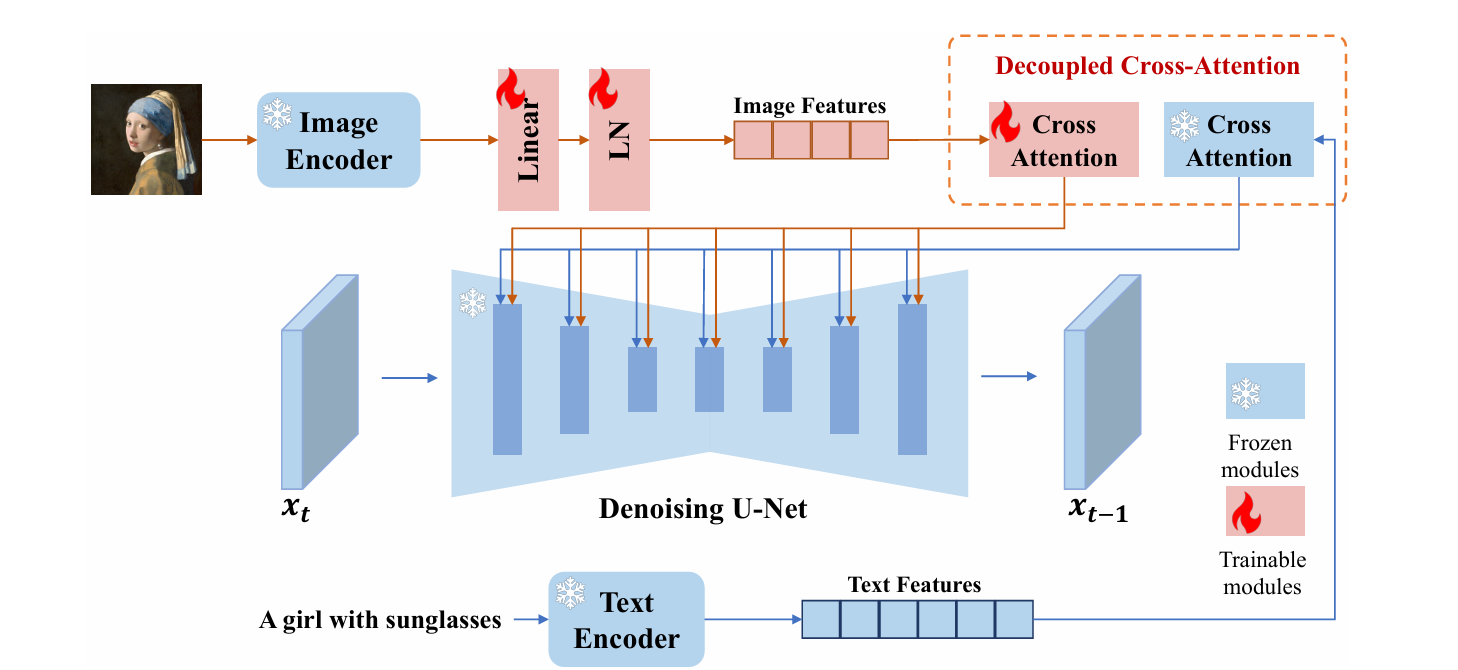
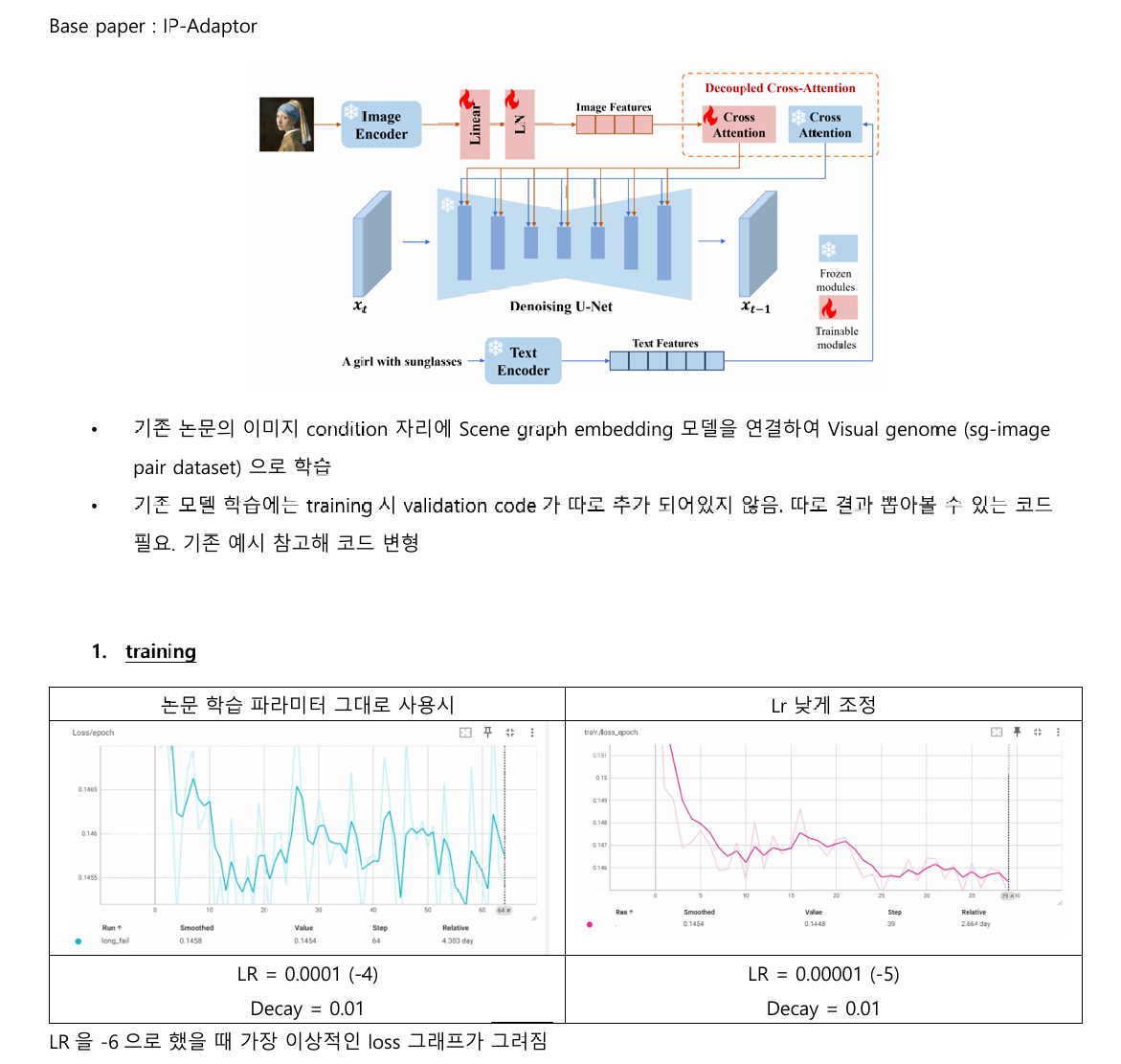
IP-Adaptor를 이용해서 sg embedding 연결 → 이미지 자리에 SG 연결
-
Dataset
# Dataset class MyDataset(torch.utils.data.Dataset): def __init__(self, tokenizer, vocab, h5_path, image_dir, image_size=256, max_objects=10, max_samples=None, include_relationships=True, use_orphaned_objects=True, size=512, t_drop_rate=0.05, i_drop_rate=0.05, ti_drop_rate=0.05): super().__init__() self.tokenizer = tokenizer self.size = size self.i_drop_rate = i_drop_rate self.t_drop_rate = t_drop_rate self.ti_drop_rate = ti_drop_rate with open(vocab, 'r') as f: vocab = json.load(f) self.image_dir = image_dir self.image_size = (image_size, image_size) self.vocab = vocab self.num_objects = len(vocab['object_idx_to_name']) self.use_orphaned_objects = use_orphaned_objects self.max_objects = max_objects self.max_samples = max_samples self.include_relationships = include_relationships self.captions = json.load(open('/home/jskim/T2I/IP-Adapter/image_captions.json')) # list of dict: [{"image_file": "1.png", "text": "A dog"}] self.data = {} with h5py.File(h5_path, 'r') as f: for k, v in f.items(): if k == 'image_paths': self.image_paths = list(v) else: self.data[k] = torch.IntTensor(np.asarray(v)) self.transform = transforms.Compose([ transforms.Resize(self.size, interpolation=transforms.InterpolationMode.BILINEAR), transforms.CenterCrop(self.size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5]), ]) self.clip_image_processor = CLIPImageProcessor() def __getitem__(self, idx): item = self.set_sg(idx) image_id = self.image_paths[idx].decode('utf-8') text = self.captions[image_id] # read image image = item[0] sg = item # clip_image = self.clip_image_processor(images=raw_image, return_tensors="pt").pixel_values # drop drop_image_embed = 0 rand_num = random.random() if rand_num < self.i_drop_rate: drop_image_embed = 1 elif rand_num < (self.i_drop_rate + self.t_drop_rate): text = "" elif rand_num < (self.i_drop_rate + self.t_drop_rate + self.ti_drop_rate): text = "" drop_image_embed = 1 # get text and tokenize text_input_ids = self.tokenizer( text, max_length=self.tokenizer.model_max_length, padding="max_length", truncation=True, return_tensors="pt" ).input_ids return { "image": image, "text_input_ids": text_input_ids, "clip_image": sg, "drop_image_embed": drop_image_embed } def __len__(self): num = self.data['object_names'].size(0) if self.max_samples is not None: return min(self.max_samples, num) return num def set_sg(self, index): img_path = os.path.join(self.image_dir, str(self.image_paths[index], encoding="utf-8")) with open(img_path, 'rb') as f: with PIL.Image.open(f) as image: WW, HH = image.size image = self.transform(image.convert('RGB')) image = image * 2 - 1 obj_idxs_with_rels = set() obj_idxs_without_rels = set(range(self.data['objects_per_image'][index].item())) for r_idx in range(self.data['relationships_per_image'][index]): s = self.data['relationship_subjects'][index, r_idx].item() o = self.data['relationship_objects'][index, r_idx].item() obj_idxs_with_rels.add(s) obj_idxs_with_rels.add(o) obj_idxs_without_rels.discard(s) obj_idxs_without_rels.discard(o) obj_idxs = list(obj_idxs_with_rels) obj_idxs_without_rels = list(obj_idxs_without_rels) if len(obj_idxs) > self.max_objects - 1: obj_idxs = random.sample(obj_idxs, self.max_objects) if len(obj_idxs) < self.max_objects - 1 and self.use_orphaned_objects: num_to_add = self.max_objects - 1 - len(obj_idxs) num_to_add = min(num_to_add, len(obj_idxs_without_rels)) obj_idxs += random.sample(obj_idxs_without_rels, num_to_add) O = len(obj_idxs) + 1 objs = torch.LongTensor(O).fill_(-1) boxes = torch.FloatTensor([[0, 0, 1, 1]]).repeat(O, 1) obj_idx_mapping = {} for i, obj_idx in enumerate(obj_idxs): objs[i] = self.data['object_names'][index, obj_idx].item() x, y, w, h = self.data['object_boxes'][index, obj_idx].tolist() x0 = float(x) / WW y0 = float(y) / HH x1 = float(x + w) / WW y1 = float(y + h) / HH boxes[i] = torch.FloatTensor([x0, y0, x1, y1]) obj_idx_mapping[obj_idx] = i objs[O - 1] = self.vocab['object_name_to_idx']['__image__'] triples = [] for r_idx in range(self.data['relationships_per_image'][index].item()): if not self.include_relationships: break s = self.data['relationship_subjects'][index, r_idx].item() p = self.data['relationship_predicates'][index, r_idx].item() o = self.data['relationship_objects'][index, r_idx].item() s = obj_idx_mapping.get(s, None) o = obj_idx_mapping.get(o, None) if s is not None and o is not None: triples.append([s, p, o]) in_image = self.vocab['pred_name_to_idx']['__in_image__'] for i in range(O - 1): triples.append([i, in_image, O - 1]) triples = torch.LongTensor(triples) return image, objs, boxes, triples def collate_fn(data): images = torch.stack([example["image"] for example in data]) text_input_ids = torch.cat([example["text_input_ids"] for example in data], dim=0) drop_image_embeds = [example["drop_image_embed"] for example in data] temp = [] for example in data: temp.append(example["clip_image"]) clip_images = vg_collate_fn(temp) return { "images": images, "text_input_ids": text_input_ids, "clip_images": clip_images, "drop_image_embeds": drop_image_embeds } def vg_collate_fn(batch): all_imgs, all_objs, all_boxes, all_triples = [], [], [], [] all_obj_to_img, all_triple_to_img = [], [] obj_offset = 0 for i, (img, objs, boxes, triples) in enumerate(batch): all_imgs.append(img[None]) O, T = objs.size(0), triples.size(0) all_objs.append(objs) all_boxes.append(boxes) triples = triples.clone() triples[:, 0] += obj_offset triples[:, 2] += obj_offset all_triples.append(triples) all_obj_to_img.append(torch.LongTensor(O).fill_(i)) all_triple_to_img.append(torch.LongTensor(T).fill_(i)) obj_offset += O all_imgs = torch.cat(all_imgs) all_objs = torch.cat(all_objs) all_boxes = torch.cat(all_boxes) all_triples = torch.cat(all_triples) all_obj_to_img = torch.cat(all_obj_to_img) all_triple_to_img = torch.cat(all_triple_to_img) out = (all_imgs, all_objs, all_boxes, all_triples, all_obj_to_img, all_triple_to_img) return out class Resize(object): def __init__(self, size, interp=PIL.Image.BILINEAR): if isinstance(size, tuple): H, W = size self.size = (W, H) else: self.size = (size, size) self.interp = interp def __call__(self, img): return img.resize(self.size, self.interp) -
SgProjModel → SG Embedding 이후에 concat을 위해 global, local 각각 linear layer 거침
class SgProjModel(torch.nn.Module): """Projection Model""" def __init__(self, cross_attention_dim=768, local_clip_embeddings_dim=1536, global_clip_embeddings_dim=512): super().__init__() self.generator = None self.cross_attention_dim = cross_attention_dim self.context_local_mlp = torch.nn.Linear(local_clip_embeddings_dim, cross_attention_dim) self.context_global_mlp = torch.nn.Linear(global_clip_embeddings_dim, cross_attention_dim) def forward(self, x): c_local, c_global = x context_local = self.context_local_mlp(c_local) context_global = self.context_global_mlp(c_global) context = torch.cat([context_local, context_global.unsqueeze(1)], dim=1) return context
나머지는 그대로
/home/jskim/anaconda3/envs/ip-adaptor/bin/python /home/jskim/T2I/IP-Adapter/tutorial_train_sg.py \
--pretrained_model_name_or_path /home/jskim/T2V/AnimateDiff/models/stable-diffusion-v1-5 \
--data_json_file path/to/your/data.json --data_root_path path/to/your/data \
--image_encoder_path "" --output_dir output_directory_name --logging_dir logs \
--resolution 512 --learning_rate 0.0001 --weight_decay 0.01 --num_train_epochs 100 \
--train_batch_size 24 --dataloader_num_workers 32 --save_steps 500 --mixed_precision no \
--report_to tensorboard --local_rank -1
24-09-04
- 최종적으로 학습 코드 마침
def main():
args = parse_args()
result_dir = os.path.abspath(os.path.join(args.output_dir, f"{datetime.datetime.now().strftime('%Y%m%d-%H%M%S')}"))
logging_dir = Path(result_dir, args.logging_dir)
accelerator_project_config = ProjectConfiguration(project_dir=result_dir, logging_dir=logging_dir)
accelerator = Accelerator(
mixed_precision=args.mixed_precision,
log_with=args.report_to,
project_config=accelerator_project_config,
)
writer = SummaryWriter(log_dir=args.logging_dir)
if accelerator.is_main_process:
if result_dir is not None:
os.makedirs(result_dir, exist_ok=True)
# Load scheduler, tokenizer and models.
noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
tokenizer = CLIPTokenizer.from_pretrained(args.pretrained_model_name_or_path, subfolder="tokenizer")
text_encoder = CLIPTextModel.from_pretrained(args.pretrained_model_name_or_path, subfolder="text_encoder")
vae = AutoencoderKL.from_pretrained(args.pretrained_model_name_or_path, subfolder="vae")
unet = UNet2DConditionModel.from_pretrained(args.pretrained_model_name_or_path, subfolder="unet")
# image_encoder = CLIPVisionModelWithProjection.from_pretrained(args.image_encoder_path)
sg_encoder = CGIPModel(num_objs= 179, num_preds= 46, layers = 5, width = 512, embed_dim = 512, ckpt_path = '/home/jskim/T2I/IP-Adapter/pretrained/sip_vg.pt')
# freeze parameters of models to save more memory
unet.requires_grad_(False)
vae.requires_grad_(False)
text_encoder.requires_grad_(False)
# image_encoder.requires_grad_(False)
#ip-adapter
image_proj_model = SgProjModel()
# init adapter modules
attn_procs = {}
unet_sd = unet.state_dict()
for name in unet.attn_processors.keys():
cross_attention_dim = None if name.endswith("attn1.processor") else unet.config.cross_attention_dim
if name.startswith("mid_block"):
hidden_size = unet.config.block_out_channels[-1]
elif name.startswith("up_blocks"):
block_id = int(name[len("up_blocks.")])
hidden_size = list(reversed(unet.config.block_out_channels))[block_id]
elif name.startswith("down_blocks"):
block_id = int(name[len("down_blocks.")])
hidden_size = unet.config.block_out_channels[block_id]
if cross_attention_dim is None:
attn_procs[name] = AttnProcessor()
else:
layer_name = name.split(".processor")[0]
weights = {
"to_k_ip.weight": unet_sd[layer_name + ".to_k.weight"],
"to_v_ip.weight": unet_sd[layer_name + ".to_v.weight"],
}
attn_procs[name] = IPAttnProcessor(hidden_size=hidden_size, cross_attention_dim=cross_attention_dim)
attn_procs[name].load_state_dict(weights)
unet.set_attn_processor(attn_procs)
adapter_modules = torch.nn.ModuleList(unet.attn_processors.values())
ip_adapter = IPAdapter(unet, image_proj_model, adapter_modules, args.pretrained_ip_adapter_path)
weight_dtype = torch.float32
if accelerator.mixed_precision == "fp16":
weight_dtype = torch.float16
elif accelerator.mixed_precision == "bf16":
weight_dtype = torch.bfloat16
vae.to(accelerator.device, dtype=weight_dtype)
text_encoder.to(accelerator.device, dtype=weight_dtype)
sg_encoder.to(accelerator.device, dtype=weight_dtype)
unet.to(accelerator.device, dtype=weight_dtype)
# optimizer
params_to_opt = itertools.chain(ip_adapter.image_proj_model.parameters(), ip_adapter.adapter_modules.parameters())
optimizer = torch.optim.AdamW(params_to_opt, lr=args.learning_rate, weight_decay=args.weight_decay)
# dataloader
train_dataset = MyDataset(tokenizer=tokenizer,
vocab='/home/jskim/Graph_VIdeo_generation/dataset/vg/vocab.json',
h5_path='/home/jskim/Graph_VIdeo_generation/dataset/vg/train.h5',
image_dir='/home/jskim/Graph_VIdeo_generation/dataset/vg/frames',
size=args.resolution,
)
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
shuffle=True,
collate_fn=collate_fn,
batch_size=args.train_batch_size,
num_workers=args.dataloader_num_workers,
)
# Prepare everything with our `accelerator`.
ip_adapter, optimizer, train_dataloader = accelerator.prepare(ip_adapter, optimizer, train_dataloader)
global_step = 0
for epoch in range(0, args.num_train_epochs):
epoch_loss = 0.0
num_batches = 0
begin = time.perf_counter()
for step, batch in enumerate(train_dataloader):
load_data_time = time.perf_counter() - begin
with accelerator.accumulate(ip_adapter):
# Convert images to latent space
with torch.no_grad():
latents = vae.encode(batch["images"].to(accelerator.device, dtype=weight_dtype)).latent_dist.sample()
latents = latents * vae.config.scaling_factor
# Sample noise that we'll add to the latents
noise = torch.randn_like(latents)
bsz = latents.shape[0]
# Sample a random timestep for each image
timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device)
timesteps = timesteps.long()
# Add noise to the latents according to the noise magnitude at each timestep
# (this is the forward diffusion process)
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
with torch.no_grad():
all_imgs, all_objs, all_boxes, all_triples, all_obj_to_img, all_triple_to_img = [x.to(accelerator.device) for x in batch["clip_images"]]
graph_info = [all_imgs, all_objs, all_boxes, all_triples, all_obj_to_img, all_triple_to_img]
c_globals, c_locals = sg_encoder(graph_info)
c_local_ = []
c_global_ = []
for c_global, c_local, drop_image_embed in zip(c_globals, c_locals, batch["drop_image_embeds"]):
if drop_image_embed == 1:
c_local_.append(torch.zeros_like(c_local))
c_global_.append(torch.zeros_like(c_global))
else:
c_local_.append(c_local)
c_global_.append(c_global)
image_embeds = (torch.stack(c_global_), torch.stack(c_local_))
with torch.no_grad():
encoder_hidden_states = text_encoder(batch["text_input_ids"].to(accelerator.device))[0]
noise_pred = ip_adapter(noisy_latents, timesteps, encoder_hidden_states, image_embeds)
loss = F.mse_loss(noise_pred.float(), noise.float(), reduction="mean")
epoch_loss += loss.item()
num_batches += 1
# Gather the losses across all processes for logging (if we use distributed training).
avg_loss = accelerator.gather(loss.repeat(args.train_batch_size)).mean().item()
# Backpropagate
accelerator.backward(loss)
optimizer.step()
optimizer.zero_grad()
if accelerator.is_main_process:
print("Epoch {}, step {}, data_time: {}, time: {}, step_loss: {}".format(
epoch, step, load_data_time, time.perf_counter() - begin, avg_loss))
writer.add_scalar("Training Loss", loss.item(), global_step)
global_step += 1
if accelerator.is_main_process and global_step % args.save_steps == 0:
save_path = os.path.abspath(os.path.join(result_dir, f"checkpoint-{global_step}.pt"))
print(f"Saving model at step {global_step}, {save_path}")
save_specific_parameters(ip_adapter, optimizer, save_path, accelerator)
begin = time.perf_counter()
if accelerator.is_main_process:
average_epoch_loss = epoch_loss / num_batches
writer.add_scalar("Loss/epoch", average_epoch_loss, epoch)
print(f"Epoch {epoch} average loss: {average_epoch_loss}")
writer.close()
image caption
"VG_100K_2/1.jpg": "a tree with no leaves",
"VG_100K/2.jpg": "a man walking down the street",
"VG_100K/3.jpg": "a white desk",
"VG_100K/4.jpg": "a living room with a couch and a table",
"VG_100K/5.jpg": "a desk with a computer and a chair",
"VG_100K/6.jpg": "a table with a bowl of apples and a bottle of water",
"VG_100K/7.jpg": "a whiteboard on the wall",
"VG_100K/8.jpg": "a man sitting at a desk with a computer",
"VG_100K/11.jpg": "a white desk",
24-09-14
학습코드는 문제가 없었고, Inference 에 문제가 있었음
StableDiffusionPipeline.from_pretrained() : 이 코드를 통해서 돌려야함


Visual genonme text caption
-
기존 BERT image captioning
-
bilp2를 활용한 image captioning
import os import numpy as np from PIL import Image import torch import h5py import json from transformers import Blip2Processor, Blip2ForConditionalGeneration from tqdm import tqdm # GPU 가용성 확인 및 디바이스 설정 device = torch.device("cuda" if torch.cuda.is_available() else "cpu") print(f"Using device: {device}") # 사전 학습된 이미지 캡셔닝 모델 로드 및 GPU로 이동 processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b") model = Blip2ForConditionalGeneration.from_pretrained( "Salesforce/blip2-opt-2.7b", load_in_8bit=False, device_map={"": 0}, torch_dtype=torch.float32 ) data = {} captions_dict = {} # HDF5 파일에서 데이터 읽기 with h5py.File("/home/jskim/Graph_VIdeo_generation/dataset/vg/train.h5", 'r') as f: for k, v in f.items(): if k == 'image_paths': image_paths = list(v) else: data[k] = torch.IntTensor(np.asarray(v)) # 각 이미지에 대해 캡션 생성 for index in tqdm(image_paths, desc="Generating captions"): img_path = os.path.join('/home/jskim/Graph_VIdeo_generation/dataset/vg/frames', str(index, encoding="utf-8")) # 이미지 파일이 존재하는지 확인 if not os.path.exists(img_path): print(f"Image not found: {img_path}") continue try: with open(img_path, 'rb') as f: with Image.open(f) as image: WW, HH = image.size image = image.convert('RGB') # Prepare the image for the captioning model inputs = processor(image, return_tensors="pt").to(device) # Remove 'max_length' from inputs to prevent the warning if 'max_length' in inputs: del inputs['max_length'] # Generate the caption out = model.generate( pixel_values=inputs['pixel_values'], num_beams=5, # Apply beam search temperature=1.2, # Increase creativity with temperature top_p=0.9, # Use nucleus sampling for more diverse results top_k=50, # Add diversity with top-k sampling length_penalty=2.0 # Set length_penalty to favor longer captions ) # Decode the generated caption caption = processor.decode(out[0], skip_special_tokens=True) # 캡션을 딕셔너리에 저장 captions_dict[str(index)] = caption # encoding="utf-8" 제거 except Exception as e: print(f"Error processing image {img_path}: {e}") # GPU 메모리 관리 (필요시) torch.cuda.empty_cache() # 캡션을 JSON 파일로 저장 with open('image_captions.json', 'w', encoding='utf-8') as json_file: json.dump(captions_dict, json_file, ensure_ascii=False, indent=4) print("Image captions have been successfully saved to 'image_captions.json'.") # 이미지 캡션 예시 10개 출력 print("\nExample Captions:") for i, (img_index, caption) in enumerate(list(captions_dict.items())[:10]): print(f"{i+1}. Image Path: {img_index}, Caption: {caption}") -
Scene Graph triplet to text convert
Example Captions:
- Image Path: [‘VG_100K/2322973.jpg’], Caption: girl has shirt. girl has shirt. girl . girl . shirt . shirt . girl . tree . girl . sock . girl .
- Image Path: [‘VG_100K/2348155.jpg’], Caption: brick on side of building. brick . building . clock . picture .
- Image Path: [‘VG_100K_2/2398699.jpg’], Caption: face of clock. clock . face . roof . sky . tree . wire .
- Image Path: [‘VG_100K/2343824.jpg’], Caption: water behind umbrella. umbrella has pole. umbrella near water. water behind umbrella. umbrella has pole. pole . umbrella . water . sky .
- Image Path: [‘VG_100K_2/2399651.jpg’], Caption: train on track. track on ground. ground . track . train . wood . fence . sky . building . grass . train .
- Image Path: [‘VG_100K/2323416.jpg’], Caption: light in sky. stripe on street. pole on sidewalk. pole on sidewalk. light . pole . pole . sidewalk . sky . street . stripe . vehicle . street .
- Image Path: [‘VG_100K_2/2388894.jpg’], Caption: bowl has edge. towel has edge. man wears jean. man wears towel. bowl has edge. picture on wall. man wears towel. bowl on counter. picture on wall. bowl . counter . edge . edge . jean . man . picture . towel . wall .
- Image Path: [‘VG_100K_2/2404431.jpg’], Caption: man has bike. man eating pizza. man has pizza. bike behind man. logo on shirt. window on building. bike . building . logo . man . pizza . shirt . window . wall . table .
- Image Path: [‘VG_100K/2354967.jpg’], Caption: rock behind bear. bear on leg. bear . leg . rock . leaf . bird . dirt . leaf . branch . leaf .
- Image Path: [‘VG_100K_2/2409239.jpg’], Caption: flower next to wall. man wearing shirt. man wearing shirt. flower . man . shirt . wall . short . shirt . line . shoe .
import datetime import os import random import argparse from pathlib import Path import json import itertools import time import random import h5py import numpy as np import PIL from PIL import Image import tempfile import torch import torch.nn.functional as F from PIL import Image from transformers import CLIPImageProcessor from torchvision import transforms from accelerate import Accelerator from accelerate.logging import get_logger from accelerate.utils import ProjectConfiguration from diffusers import AutoencoderKL, DDPMScheduler, UNet2DConditionModel from transformers import CLIPTextModel, CLIPTokenizer, CLIPVisionModelWithProjection from cgip.cgip import CGIPModel from torch.utils.tensorboard import SummaryWriter from torchvision import transforms # Dataset class MyDataset(torch.utils.data.Dataset): def __init__(self,vocab, h5_path, image_dir, image_size=256, max_objects=10, max_samples=None, include_relationships=True, use_orphaned_objects=True, size=512, t_drop_rate=0.05, i_drop_rate=0.05, ti_drop_rate=0.05): super().__init__() self.size = size self.i_drop_rate = i_drop_rate self.t_drop_rate = t_drop_rate self.ti_drop_rate = ti_drop_rate with open(vocab, 'r') as f: vocab = json.load(f) self.image_dir = image_dir self.image_size = (image_size, image_size) self.vocab = vocab self.num_objects = len(vocab['object_idx_to_name']) self.use_orphaned_objects = use_orphaned_objects self.max_objects = max_objects self.max_samples = max_samples self.include_relationships = include_relationships self.transform = transforms.Compose([ transforms.Resize(self.size, interpolation=transforms.InterpolationMode.BILINEAR), transforms.CenterCrop(self.size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5]), ]) self.data = {} with h5py.File(h5_path, 'r') as f: for k, v in f.items(): if k == 'image_paths': self.image_paths = list(v) else: self.data[k] = torch.IntTensor(np.asarray(v)) def __getitem__(self, idx): item = self.set_sg(idx) image_id = self.image_paths[idx].decode('utf-8') # read image image = item[0] sg = item return { "image": image, "text_input_ids": image_id, "clip_image": sg, "idx" : str(self.image_paths[idx], encoding="utf-8") } def __len__(self): num = self.data['object_names'].size(0) if self.max_samples is not None: return min(self.max_samples, num) return num def set_sg(self, index): img_path = os.path.join(self.image_dir, str(self.image_paths[index], encoding="utf-8")) with open(img_path, 'rb') as f: with PIL.Image.open(f) as image: WW, HH = image.size image = self.transform(image.convert('RGB')) image = image * 2 - 1 obj_idxs_with_rels = set() obj_idxs_without_rels = set(range(self.data['objects_per_image'][index].item())) for r_idx in range(self.data['relationships_per_image'][index]): s = self.data['relationship_subjects'][index, r_idx].item() o = self.data['relationship_objects'][index, r_idx].item() obj_idxs_with_rels.add(s) obj_idxs_with_rels.add(o) obj_idxs_without_rels.discard(s) obj_idxs_without_rels.discard(o) obj_idxs = list(obj_idxs_with_rels) obj_idxs_without_rels = list(obj_idxs_without_rels) if len(obj_idxs) > self.max_objects - 1: obj_idxs = random.sample(obj_idxs, self.max_objects) if len(obj_idxs) < self.max_objects - 1 and self.use_orphaned_objects: num_to_add = self.max_objects - 1 - len(obj_idxs) num_to_add = min(num_to_add, len(obj_idxs_without_rels)) obj_idxs += random.sample(obj_idxs_without_rels, num_to_add) O = len(obj_idxs) + 1 objs = torch.LongTensor(O).fill_(-1) boxes = torch.FloatTensor([[0, 0, 1, 1]]).repeat(O, 1) obj_idx_mapping = {} for i, obj_idx in enumerate(obj_idxs): objs[i] = self.data['object_names'][index, obj_idx].item() x, y, w, h = self.data['object_boxes'][index, obj_idx].tolist() x0 = float(x) / WW y0 = float(y) / HH x1 = float(x + w) / WW y1 = float(y + h) / HH boxes[i] = torch.FloatTensor([x0, y0, x1, y1]) obj_idx_mapping[obj_idx] = i objs[O - 1] = self.vocab['object_name_to_idx']['__image__'] triples = [] for r_idx in range(self.data['relationships_per_image'][index].item()): if not self.include_relationships: break s = self.data['relationship_subjects'][index, r_idx].item() p = self.data['relationship_predicates'][index, r_idx].item() o = self.data['relationship_objects'][index, r_idx].item() s = obj_idx_mapping.get(s, None) o = obj_idx_mapping.get(o, None) if s is not None and o is not None: triples.append([s, p, o]) in_image = self.vocab['pred_name_to_idx']['__in_image__'] for i in range(O - 1): triples.append([i, in_image, O - 1]) triples = torch.LongTensor(triples) return image, objs, boxes, triples def collate_fn(data): images = torch.stack([example["image"] for example in data]) text_input_ids = [example["text_input_ids"] for example in data] idx = [example["idx"] for example in data] temp = [] for example in data: temp.append(example["clip_image"]) clip_images = vg_collate_fn(temp) return { "images": images, "text_input_ids": text_input_ids, "Scene Graph": clip_images, "idx" : idx } def vg_collate_fn(batch): all_imgs, all_objs, all_boxes, all_triples = [], [], [], [] all_obj_to_img, all_triple_to_img = [], [] obj_offset = 0 for i, (img, objs, boxes, triples) in enumerate(batch): all_imgs.append(img[None]) O, T = objs.size(0), triples.size(0) all_objs.append(objs) all_boxes.append(boxes) triples = triples.clone() triples[:, 0] += obj_offset triples[:, 2] += obj_offset all_triples.append(triples) all_obj_to_img.append(torch.LongTensor(O).fill_(i)) all_triple_to_img.append(torch.LongTensor(T).fill_(i)) obj_offset += O all_imgs = torch.cat(all_imgs) all_objs = torch.cat(all_objs) all_boxes = torch.cat(all_boxes) all_triples = torch.cat(all_triples) all_obj_to_img = torch.cat(all_obj_to_img) all_triple_to_img = torch.cat(all_triple_to_img) out = (all_imgs, all_objs, all_boxes, all_triples, all_obj_to_img, all_triple_to_img) return out class Resize(object): def __init__(self, size, interp=PIL.Image.BILINEAR): if isinstance(size, tuple): H, W = size self.size = (W, H) else: self.size = (size, size) self.interp = interp def __call__(self, img): return img.resize(self.size, self.interp) def save_graph_info(vocab, objs, triples, path): f = open(path, 'w') data = f''' objs : {objs} triples : {triples} ### vocab ### {vocab['object_name_to_idx']} {vocab["attribute_name_to_idx"]} {vocab["pred_name_to_idx"]} ''' f.write(data) f.close() def draw_scene_graph(objs, triples, vocab=None, **kwargs): output_filename = kwargs.pop('output_filename', 'graph.png') orientation = kwargs.pop('orientation', 'V') edge_width = kwargs.pop('edge_width', 6) arrow_size = kwargs.pop('arrow_size', 1.5) binary_edge_weight = kwargs.pop('binary_edge_weight', 1.2) ignore_dummies = kwargs.pop('ignore_dummies', True) if orientation not in ['V', 'H']: raise ValueError('Invalid orientation "%s"' % orientation) rankdir = {'H': 'LR', 'V': 'TD'}[orientation] if vocab is not None: assert torch.is_tensor(objs) assert torch.is_tensor(triples) objs_list, triples_list = [], [] for i in range(objs.size(0)): objs_list.append(vocab['object_idx_to_name'][objs[i].item()]) for i in range(triples.size(0)): s = triples[i, 0].item() # p = vocab['pred_name_to_idx'][triples[i, 1].item()] p = triples[i, 1].item() o = triples[i, 2].item() triples_list.append([s, p, o]) objs, triples = objs_list, triples_list lines = [ 'digraph{', 'graph [size="5,3",ratio="compress",dpi="300",bgcolor="transparent"]', 'rankdir=%s' % rankdir, 'nodesep="0.5"', 'ranksep="0.5"', 'node [shape="box",style="rounded,filled",fontsize="48",color="none"]', 'node [fillcolor="lightpink1"]', ] for i, obj in enumerate(objs): if ignore_dummies and obj == '__image__': continue lines.append('%d [label="%s"]' % (i, obj)) next_node_id = len(objs) lines.append('node [fillcolor="lightblue1"]') for s, p, o in triples: p = vocab['pred_idx_to_name'][p] if ignore_dummies and p == '__in_image__': continue lines += [ '%d [label="%s"]' % (next_node_id, p), '%d->%d [penwidth=%f,arrowsize=%f,weight=%f]' % ( s, next_node_id, edge_width, arrow_size, binary_edge_weight), '%d->%d [penwidth=%f,arrowsize=%f,weight=%f]' % ( next_node_id, o, edge_width, arrow_size, binary_edge_weight) ] next_node_id += 1 lines.append('}') ff, dot_filename = tempfile.mkstemp() with open(dot_filename, 'w') as f: for line in lines: f.write('%s\n' % line) os.close(ff) output_format = os.path.splitext(output_filename)[1][1:] os.system('dot -T%s %s > %s' % (output_format, dot_filename, output_filename)) return None def convert(objs, triples, vocab): obj_vocab = {v: k for k, v in vocab['object_name_to_idx'].items()} rel_vocab = {v: k for k, v in vocab["pred_name_to_idx"].items()} objs_En = [] for obj_idx in objs: obj_name = obj_vocab.get(obj_idx.item(), "unknown") objs_En.append(obj_name) sentences = [] for subj_idx, pred_idx, obj_idx in triples: subj_name = objs_En[subj_idx] obj_name = objs_En[obj_idx] pred_name = rel_vocab.get(pred_idx.item(), "related to") sentence = f"{subj_name} {pred_name} {obj_name}" sentences.append(sentence) text = ". ".join(sentences) + "." text = text.replace("__in_image__", "").replace("__image__", "").strip() text = ' '.join(text.split()) return text # ----------------------------------------------------------------------------------------- with open("/home/jskim/Graph_VIdeo_generation/dataset/vg/vocab.json", 'r') as f: vocab = json.load(f) # dataloader train_dataset = MyDataset(vocab='/home/jskim/Graph_VIdeo_generation/dataset/vg/vocab.json', h5_path='/home/jskim/Graph_VIdeo_generation/dataset/vg/test.h5', image_dir='/home/jskim/Graph_VIdeo_generation/dataset/vg/frames', ) train_dataloader = torch.utils.data.DataLoader( train_dataset, shuffle=True, collate_fn=collate_fn, batch_size=1, num_workers=1, ) captions_dict = {} from tqdm import tqdm for step, batch in enumerate(tqdm(train_dataloader, desc="Captioning Progress", unit="batch")): # print("\n") # print(f"{batch['idx']}") # print(f"images\t: {batch['images'].shape}") # print(f"text\t: {batch['text_input_ids']}") # print(f"SG") # print(f"|-- objs\t: {batch['Scene Graph'][1]}") # print(f"|-- triples\t: {batch['Scene Graph'][3]}") # save_graph_info(vocab, batch['Scene Graph'][1], batch['Scene Graph'][3], "/home/jskim/T2I/IP-Adapter/make_sg/graph_info.txt") # draw_scene_graph(batch['Scene Graph'][1], batch['Scene Graph'][3], vocab, output_filename="/home/jskim/T2I/IP-Adapter/make_sg/graph.png") caption = convert(batch['Scene Graph'][1], batch['Scene Graph'][3], vocab) captions_dict[str(batch['text_input_ids'])] = caption pass with open('image_captions_sg.json', 'w', encoding='utf-8') as json_file: json.dump(captions_dict, json_file, ensure_ascii=False, indent=4) print("Image captions have been successfully saved to 'image_captions.json'.") print("\nExample Captions:") for i, (img_index, caption) in enumerate(list(captions_dict.items())[:10]): print(f"{i+1}. Image Path: {img_index}, Caption: {caption}")
IP-adaptor : SG 최종 code
-
train
import datetime import os import random import argparse from pathlib import Path import json import itertools import time import random import h5py import numpy as np import PIL from PIL import Image import tempfile import torch import torch.nn.functional as F from PIL import Image from transformers import CLIPImageProcessor from torchvision import transforms from accelerate import Accelerator from accelerate.logging import get_logger from accelerate.utils import ProjectConfiguration from diffusers import AutoencoderKL, DDPMScheduler, UNet2DConditionModel from transformers import CLIPTextModel, CLIPTokenizer, CLIPVisionModelWithProjection from cgip.cgip import CGIPModel from torch.utils.tensorboard import SummaryWriter from torchvision import transforms # Dataset class MyDataset(torch.utils.data.Dataset): def __init__(self,vocab, h5_path, image_dir, image_size=256, max_objects=10, max_samples=None, include_relationships=True, use_orphaned_objects=True, size=512, t_drop_rate=0.05, i_drop_rate=0.05, ti_drop_rate=0.05): super().__init__() self.size = size self.i_drop_rate = i_drop_rate self.t_drop_rate = t_drop_rate self.ti_drop_rate = ti_drop_rate with open(vocab, 'r') as f: vocab = json.load(f) self.image_dir = image_dir self.image_size = (image_size, image_size) self.vocab = vocab self.num_objects = len(vocab['object_idx_to_name']) self.use_orphaned_objects = use_orphaned_objects self.max_objects = max_objects self.max_samples = max_samples self.include_relationships = include_relationships self.transform = transforms.Compose([ transforms.Resize(self.size, interpolation=transforms.InterpolationMode.BILINEAR), transforms.CenterCrop(self.size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5]), ]) self.data = {} with h5py.File(h5_path, 'r') as f: for k, v in f.items(): if k == 'image_paths': self.image_paths = list(v) else: self.data[k] = torch.IntTensor(np.asarray(v)) def __getitem__(self, idx): item = self.set_sg(idx) image_id = self.image_paths[idx].decode('utf-8') # read image image = item[0] sg = item return { "image": image, "text_input_ids": image_id, "clip_image": sg, "idx" : str(self.image_paths[idx], encoding="utf-8") } def __len__(self): num = self.data['object_names'].size(0) if self.max_samples is not None: return min(self.max_samples, num) return num def set_sg(self, index): img_path = os.path.join(self.image_dir, str(self.image_paths[index], encoding="utf-8")) with open(img_path, 'rb') as f: with PIL.Image.open(f) as image: WW, HH = image.size image = self.transform(image.convert('RGB')) image = image * 2 - 1 obj_idxs_with_rels = set() obj_idxs_without_rels = set(range(self.data['objects_per_image'][index].item())) for r_idx in range(self.data['relationships_per_image'][index]): s = self.data['relationship_subjects'][index, r_idx].item() o = self.data['relationship_objects'][index, r_idx].item() obj_idxs_with_rels.add(s) obj_idxs_with_rels.add(o) obj_idxs_without_rels.discard(s) obj_idxs_without_rels.discard(o) obj_idxs = list(obj_idxs_with_rels) obj_idxs_without_rels = list(obj_idxs_without_rels) if len(obj_idxs) > self.max_objects - 1: obj_idxs = random.sample(obj_idxs, self.max_objects) if len(obj_idxs) < self.max_objects - 1 and self.use_orphaned_objects: num_to_add = self.max_objects - 1 - len(obj_idxs) num_to_add = min(num_to_add, len(obj_idxs_without_rels)) obj_idxs += random.sample(obj_idxs_without_rels, num_to_add) O = len(obj_idxs) + 1 objs = torch.LongTensor(O).fill_(-1) boxes = torch.FloatTensor([[0, 0, 1, 1]]).repeat(O, 1) obj_idx_mapping = {} for i, obj_idx in enumerate(obj_idxs): objs[i] = self.data['object_names'][index, obj_idx].item() x, y, w, h = self.data['object_boxes'][index, obj_idx].tolist() x0 = float(x) / WW y0 = float(y) / HH x1 = float(x + w) / WW y1 = float(y + h) / HH boxes[i] = torch.FloatTensor([x0, y0, x1, y1]) obj_idx_mapping[obj_idx] = i objs[O - 1] = self.vocab['object_name_to_idx']['__image__'] triples = [] for r_idx in range(self.data['relationships_per_image'][index].item()): if not self.include_relationships: break s = self.data['relationship_subjects'][index, r_idx].item() p = self.data['relationship_predicates'][index, r_idx].item() o = self.data['relationship_objects'][index, r_idx].item() s = obj_idx_mapping.get(s, None) o = obj_idx_mapping.get(o, None) if s is not None and o is not None: triples.append([s, p, o]) in_image = self.vocab['pred_name_to_idx']['__in_image__'] for i in range(O - 1): triples.append([i, in_image, O - 1]) triples = torch.LongTensor(triples) return image, objs, boxes, triples def collate_fn(data): images = torch.stack([example["image"] for example in data]) text_input_ids = [example["text_input_ids"] for example in data] idx = [example["idx"] for example in data] temp = [] for example in data: temp.append(example["clip_image"]) clip_images = vg_collate_fn(temp) return { "images": images, "text_input_ids": text_input_ids, "Scene Graph": clip_images, "idx" : idx } def vg_collate_fn(batch): all_imgs, all_objs, all_boxes, all_triples = [], [], [], [] all_obj_to_img, all_triple_to_img = [], [] obj_offset = 0 for i, (img, objs, boxes, triples) in enumerate(batch): all_imgs.append(img[None]) O, T = objs.size(0), triples.size(0) all_objs.append(objs) all_boxes.append(boxes) triples = triples.clone() triples[:, 0] += obj_offset triples[:, 2] += obj_offset all_triples.append(triples) all_obj_to_img.append(torch.LongTensor(O).fill_(i)) all_triple_to_img.append(torch.LongTensor(T).fill_(i)) obj_offset += O all_imgs = torch.cat(all_imgs) all_objs = torch.cat(all_objs) all_boxes = torch.cat(all_boxes) all_triples = torch.cat(all_triples) all_obj_to_img = torch.cat(all_obj_to_img) all_triple_to_img = torch.cat(all_triple_to_img) out = (all_imgs, all_objs, all_boxes, all_triples, all_obj_to_img, all_triple_to_img) return out class Resize(object): def __init__(self, size, interp=PIL.Image.BILINEAR): if isinstance(size, tuple): H, W = size self.size = (W, H) else: self.size = (size, size) self.interp = interp def __call__(self, img): return img.resize(self.size, self.interp) def save_graph_info(vocab, objs, triples, path): f = open(path, 'w') data = f''' objs : {objs} triples : {triples} ### vocab ### {vocab['object_name_to_idx']} {vocab["attribute_name_to_idx"]} {vocab["pred_name_to_idx"]} ''' f.write(data) f.close() def draw_scene_graph(objs, triples, vocab=None, **kwargs): output_filename = kwargs.pop('output_filename', 'graph.png') orientation = kwargs.pop('orientation', 'V') edge_width = kwargs.pop('edge_width', 6) arrow_size = kwargs.pop('arrow_size', 1.5) binary_edge_weight = kwargs.pop('binary_edge_weight', 1.2) ignore_dummies = kwargs.pop('ignore_dummies', True) if orientation not in ['V', 'H']: raise ValueError('Invalid orientation "%s"' % orientation) rankdir = {'H': 'LR', 'V': 'TD'}[orientation] if vocab is not None: assert torch.is_tensor(objs) assert torch.is_tensor(triples) objs_list, triples_list = [], [] for i in range(objs.size(0)): objs_list.append(vocab['object_idx_to_name'][objs[i].item()]) for i in range(triples.size(0)): s = triples[i, 0].item() # p = vocab['pred_name_to_idx'][triples[i, 1].item()] p = triples[i, 1].item() o = triples[i, 2].item() triples_list.append([s, p, o]) objs, triples = objs_list, triples_list lines = [ 'digraph{', 'graph [size="5,3",ratio="compress",dpi="300",bgcolor="transparent"]', 'rankdir=%s' % rankdir, 'nodesep="0.5"', 'ranksep="0.5"', 'node [shape="box",style="rounded,filled",fontsize="48",color="none"]', 'node [fillcolor="lightpink1"]', ] for i, obj in enumerate(objs): if ignore_dummies and obj == '__image__': continue lines.append('%d [label="%s"]' % (i, obj)) next_node_id = len(objs) lines.append('node [fillcolor="lightblue1"]') for s, p, o in triples: p = vocab['pred_idx_to_name'][p] if ignore_dummies and p == '__in_image__': continue lines += [ '%d [label="%s"]' % (next_node_id, p), '%d->%d [penwidth=%f,arrowsize=%f,weight=%f]' % ( s, next_node_id, edge_width, arrow_size, binary_edge_weight), '%d->%d [penwidth=%f,arrowsize=%f,weight=%f]' % ( next_node_id, o, edge_width, arrow_size, binary_edge_weight) ] next_node_id += 1 lines.append('}') ff, dot_filename = tempfile.mkstemp() with open(dot_filename, 'w') as f: for line in lines: f.write('%s\n' % line) os.close(ff) output_format = os.path.splitext(output_filename)[1][1:] os.system('dot -T%s %s > %s' % (output_format, dot_filename, output_filename)) return None def convert(objs, triples, vocab): obj_vocab = {v: k for k, v in vocab['object_name_to_idx'].items()} rel_vocab = {v: k for k, v in vocab["pred_name_to_idx"].items()} objs_En = [] for obj_idx in objs: obj_name = obj_vocab.get(obj_idx.item(), "unknown") objs_En.append(obj_name) sentences = [] for subj_idx, pred_idx, obj_idx in triples: subj_name = objs_En[subj_idx] obj_name = objs_En[obj_idx] pred_name = rel_vocab.get(pred_idx.item(), "related to") sentence = f"{subj_name} {pred_name} {obj_name}" sentences.append(sentence) text = ". ".join(sentences) + "." text = text.replace("__in_image__", "").replace("__image__", "").strip() text = ' '.join(text.split()) return text # ----------------------------------------------------------------------------------------- with open("/home/jskim/Graph_VIdeo_generation/dataset/vg/vocab.json", 'r') as f: vocab = json.load(f) # dataloader train_dataset = MyDataset(vocab='/home/jskim/Graph_VIdeo_generation/dataset/vg/vocab.json', h5_path='/home/jskim/Graph_VIdeo_generation/dataset/vg/test.h5', image_dir='/home/jskim/Graph_VIdeo_generation/dataset/vg/frames', ) train_dataloader = torch.utils.data.DataLoader( train_dataset, shuffle=True, collate_fn=collate_fn, batch_size=1, num_workers=1, ) captions_dict = {} from tqdm import tqdm for step, batch in enumerate(tqdm(train_dataloader, desc="Captioning Progress", unit="batch")): # print("\n") # print(f"{batch['idx']}") # print(f"images\t: {batch['images'].shape}") # print(f"text\t: {batch['text_input_ids']}") # print(f"SG") # print(f"|-- objs\t: {batch['Scene Graph'][1]}") # print(f"|-- triples\t: {batch['Scene Graph'][3]}") # save_graph_info(vocab, batch['Scene Graph'][1], batch['Scene Graph'][3], "/home/jskim/T2I/IP-Adapter/make_sg/graph_info.txt") # draw_scene_graph(batch['Scene Graph'][1], batch['Scene Graph'][3], vocab, output_filename="/home/jskim/T2I/IP-Adapter/make_sg/graph.png") caption = convert(batch['Scene Graph'][1], batch['Scene Graph'][3], vocab) captions_dict[str(batch['text_input_ids'])] = caption pass with open('image_captions_sg.json', 'w', encoding='utf-8') as json_file: json.dump(captions_dict, json_file, ensure_ascii=False, indent=4) print("Image captions have been successfully saved to 'image_captions.json'.") print("\nExample Captions:") for i, (img_index, caption) in enumerate(list(captions_dict.items())[:10]): print(f"{i+1}. Image Path: {img_index}, Caption: {caption}") -
inference
import torch from diffusers import StableDiffusionPipeline, StableDiffusionImg2ImgPipeline, StableDiffusionInpaintPipelineLegacy, DDIMScheduler, AutoencoderKL from PIL import Image from ip_adapter import IPAdapter from cgip.cgip import CGIPModel # /home/jskim/T2I/IP-Adapter/stable-diffusion-2-1-model # /home/jskim/T2V/AnimateDiff/models/stable-diffusion-v1-5/ base_model_path = "/home/jskim/T2V/AnimateDiff/models/stable-diffusion-v1-5/" vae_model_path = "/home/jskim/T2V/AnimateDiff/models/stable-diffusion-v1-5/vae" image_encoder_path = "/home/jskim/T2I/IP-Adapter/pretrained/sip_vg.pt" ip_ckpt = "/home/jskim/T2I/IP-Adapter/result/20240918-214447/checkpoint-226000.pt" device = "cuda" if torch.cuda.is_available() else "cpu" # load SD pipeline pipe = StableDiffusionPipeline.from_pretrained( base_model_path, torch_dtype=torch.float32, feature_extractor=None, safety_checker=None ).to(device) image = torch.zeros(3, 256, 256) objs = torch.tensor([167, 58, 6, 49, 8, 26, 27, 28]) boxes = torch.zeros(8, 4) triples = torch.tensor([ [0, 33, 3], # player standing on road [1, 31, 2], # boy holding person [2, 0, 5], # person in shoe [6, 3, 4], # people have ground [7, 15, 0], # door at player ]) text = '''two men on a baseball field running to first base man on the left is running man in the middle is walking man behind the man on the right is holding a baseball two baseball players running towards first base after a''' # "player wearing glove. player wearing shoe. player wearing helmet. player wearing cap. cap . glove . helmet . player . player . shoe . sock . pant . ground ." def vg_collate_fn(img, objs, boxes, triples): device = torch.device("cuda" if torch.cuda.is_available() else "cpu") img = img[None].to(device) objs = objs.to(device) boxes = boxes.to(device) triples = triples.clone().to(device) O, T = objs.size(0), triples.size(0) obj_to_img = torch.zeros(O, dtype=torch.long, device=device) triple_to_img = torch.zeros(T, dtype=torch.long, device=device) out = (img, objs, boxes, triples, obj_to_img, triple_to_img) return out graph_info = vg_collate_fn(image, objs, boxes, triples) sg_encoder = CGIPModel(num_objs=179, num_preds=46, layers=5, width=512, embed_dim=512, ckpt_path='/home/jskim/T2I/IP-Adapter/pretrained/sip_vg.pt').to(device) sg_encoder.eval() # Encode the scene graph with torch.no_grad(): c_globals, c_locals = sg_encoder(graph_info) c_globals = torch.zeros_like(c_globals) c_locals = torch.zeros_like(c_locals) image_embeds = (c_globals, c_locals) # load ip-adapter ip_model = IPAdapter(pipe, image_encoder_path, ip_ckpt, device) # generate image variations seed = 40 num_inference_steps = 50 guidance_scale = 8.0 clip_sample = False # 이미지 생성 호출 예시 images = ip_model.generate( pil_image=image_embeds, prompt=text, num_samples=1, num_inference_steps=num_inference_steps, guidance_scale=guidance_scale, seed=seed ) from PIL import Image # Assuming 'images' contains a list of generated images for idx, img in enumerate(images): img_path = f"generated_image_{text}.png" img.save(img_path) print(f"Image saved as {img_path}")
Test list
| try list | 위치 | LR | Weight decay | scale | text | 기타 (특이사항) |
|---|---|---|---|---|---|---|
| 0 | 인지융 0 | 0.00001 | 0.01 | 1 | ||
| 1 | 인지융 0 | 0.000001 | 0 | 2 | SG | 기본 |
| 2 | 인지융 1 | 0.000001 | 0 | 2 | SG | linear normalization |
| 랩실서버1 | 0.000001 | 0.01 | 2 | bilp2 | 기본 |
log
events.out.tfevents.1725944730.a100-n2.3376883 (2).0
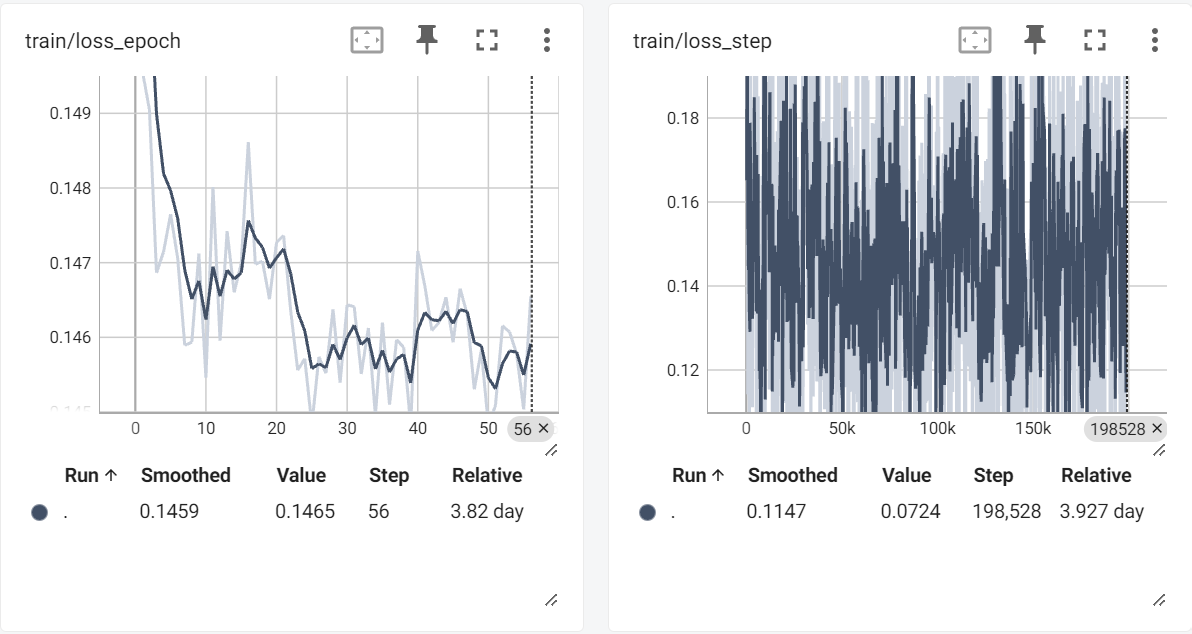
graph

image

code
-
2
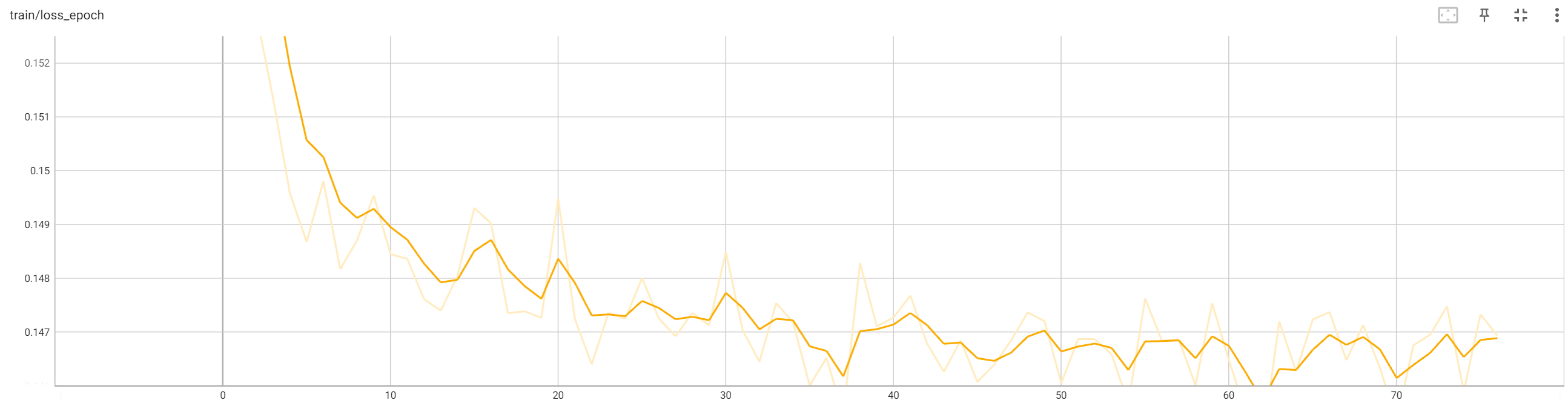
전반적으로 text에 alignment가 강하다.
graph에 대한 제어가 전혀 안됨
실패 요인 분석
Stable diffusion model에 Text alignment가 상당히 강했다.
몇가지 원인을 추론해 볼 수 있는데
- Scene Graph 정보와 이미지 생성 조건 간의 연결 방식이 부적절, 일관성이 부족한 경우
- 코드 상에 에러가 있는 경우
- 학습 시간, 데이터 부족
Inference code를 작성함에 있어 Training에서 사용했던 모델을 개별로 불러와서 조합하는 방식이 재대로 동작하지 않음 → 단순한 연결 이외에 최적화가 필요함