
[프로젝트] Inha Dacon LLM - QA task
Inha univ. Inha Dacon LLM - QA task
요약
- 이미 기존 kr - LLM의 성능이 뛰어남
- LoRA를 통해서 다양한 시도를 해봤지만, 기존 align이 너무 잘 되어있어서 오히려 성능하락
- 최대한 기존 모델 성능을 살리며, fine-tuning 하고자 함
- polar model에 input format이 제공되지 않음. 어떤 방식으로 학습이 진행되었는지 모름
Environment
Linux
python : 3.10
gpu : a100 or rtx6000
cuda : 12.1
Dacon 홈페이지
https://dacon.io/competitions/official/236291/overview/rules
Action
성적 20등 : 0.806
POLAR-14B_qlora
POLAR-14B_zero-QLoRA
LLaMA3-openko finetune
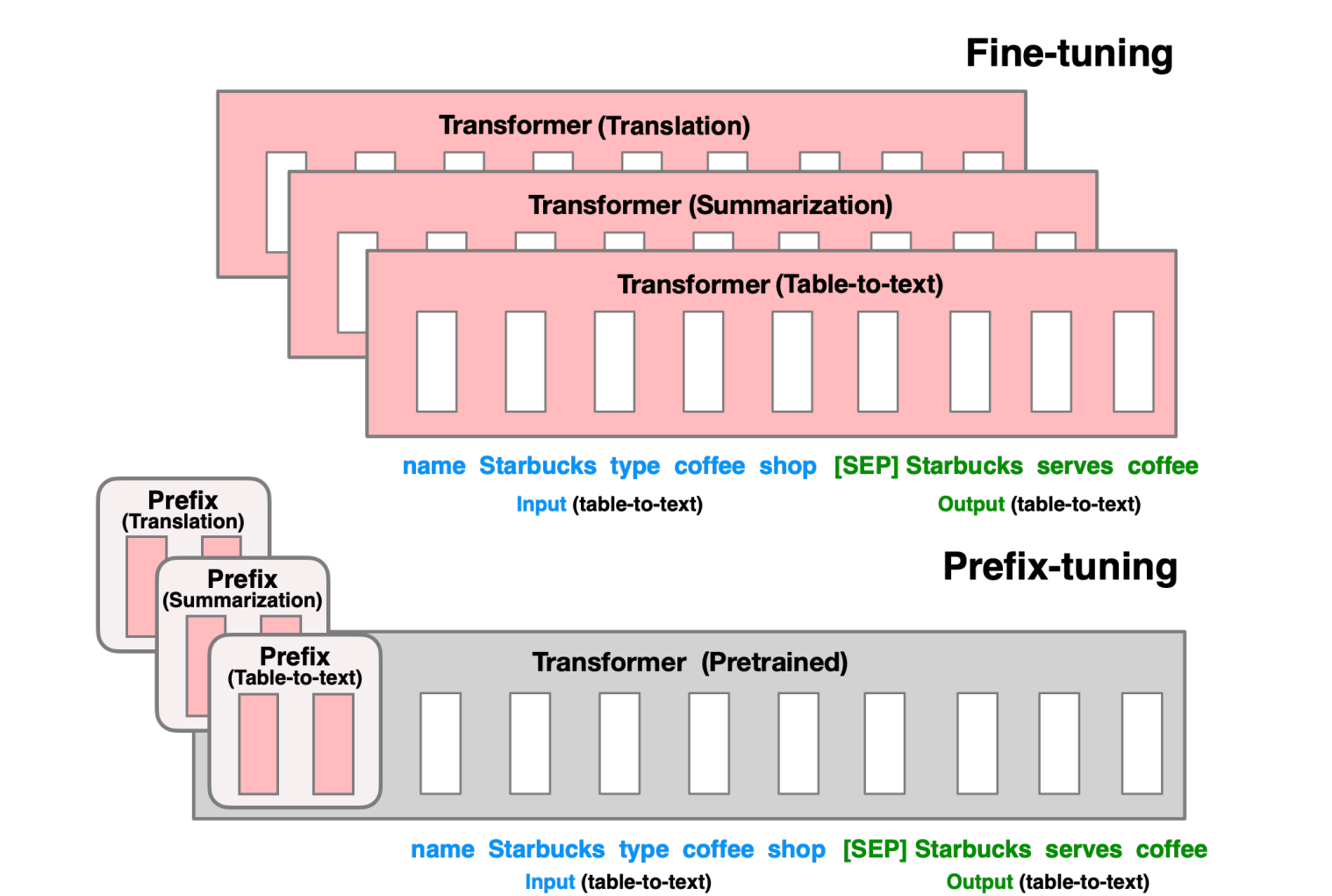
prefix finetuning
등등 다양한 시도
프로젝트 페이지
LLM 학습에 대한 고찰 - 입력과 출력이 어떻게 이루어지는지
1bit LLM BitNet 사용 가능 여부
결론적으로는 힘들 것 같음
기존 모델들 에서 사용하는 quantization은 Post Quantization으로 학습된 모델에다가 quantization 적용
⇒ FP32를 FP16, FP8 심지어 4bit까지 줄어듬. 우리가 지금 사용하는 모델들에서 4bit option이 있는 이유가 다 post quantization 적용임.
1bit LLM 저자들은 이러한 Post Quantization은 suboptimal하고 모델을 학습하는 과정에서 quantization을 고려하여 학습하는 방식인 QAT(Quantization Aware Training)을 제안함.
nn.Linear가 computation cost를 너무 차지하므로 BitLinear로 대체하는 등 모델 아키텍처에 변화를 넣어서 quantization을 고려하여 학습.
Pretrained 모델에 finetuning을 할 우리에게는 안맞는 부분일 것이라고 생각.
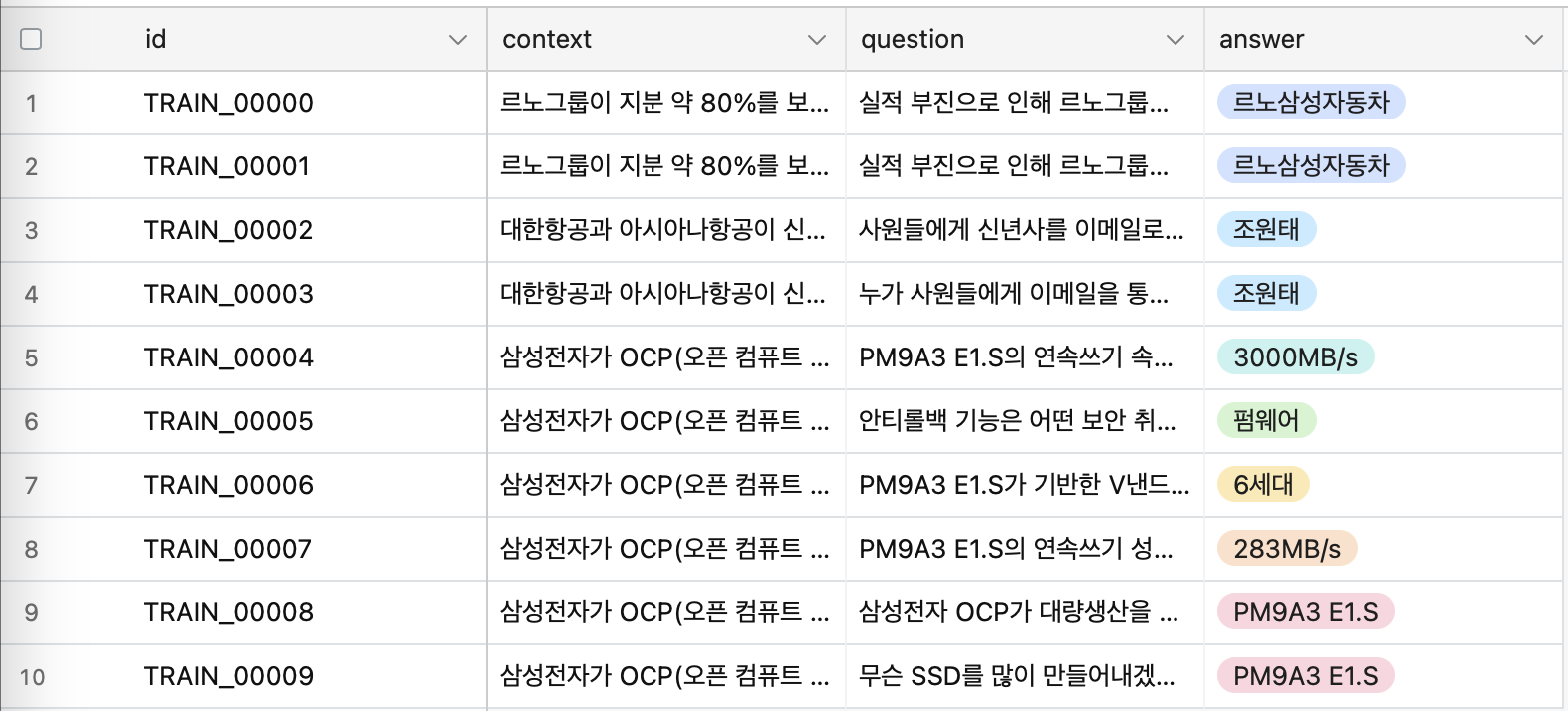
Dataset 문제점
동의어 정답 처리, 특수 문자
Datapreprocessing
최대 토큰 수: 2368
최대 문장 수: 30
최소 문장 수: 1
특수기호 빈도수:'/': 56
'.': 1369
'%': 1613
',': 2438
'~': 261
'-': 285
'+': 25
'(': 378
...
정답단어개수
Word Count Frequency:
Word Count: 1, Frequency: 20819
Word Count: 2, Frequency: 6729
Word Count: 3, Frequency: 2971
Word Count: 4, Frequency: 1530
Word Count: 5, Frequency: 758
Word Count: 6, Frequency: 425
Word Count: 7, Frequency: 220
Word Count: 8, Frequency: 111
Word Count: 9, Frequency: 79
Word Count: 10, Frequency: 46
Word Count: 11, Frequency: 12
Word Count: 12, Frequency: 10
Word Count: 14, Frequency: 4
Word Count: 16, Frequency: 2
context안에 answer가 몇개 들어있는지
context 최대 토큰
answer 최대 토큰수 확인
Prefix tuning [ training code ]
https://arxiv.org/abs/2101.00190
https://huggingface.co/docs/peft/package_reference/prefix_tuning
import json
import torch
import os
from torch.utils.data import DataLoader, Dataset
from transformers import AutoTokenizer, AutoModelForCausalLM
from tqdm import tqdm
from torch.optim import AdamW
from accelerate import Accelerator
import torch.optim as optim
import torch.nn.functional as F
os.environ["TOKENIZERS_PARALLELISM"] = "true"
torch.set_printoptions(profile="full")
# 사전 훈련된 모델과 토크나이저 로드
model_name = 'beomi/Llama-3-Open-Ko-8B'
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.model_max_length = 3500
# Padding token 설정
if tokenizer.pad_token is None:
tokenizer.add_special_tokens({'pad_token': tokenizer.eos_token})
# 디바이스 설정
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 모델을 float16으로 로드
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16).to(device)
model.resize_token_embeddings(len(tokenizer)) # Tokenizer 길이가 변경되었으므로 모델의 토큰 임베딩 크기 조정
# Prefix 벡터를 초기화
prefix_length = 32
prefix_dim = model.config.hidden_size
prefix_vectors = torch.nn.Parameter(torch.zeros(prefix_length, prefix_dim, dtype=torch.float16).to(device)) # Initialize with zeros
prefix_vectors.data.uniform_(-0.1, 0.1) # Add small random values
# 모델의 파라미터를 학습 대상에서 제외
for param in model.parameters():
param.requires_grad = False
# 옵티마이저에 prefix_vectors 추가 (epsilon 값 증가)
optimizer = torch.optim.AdamW([prefix_vectors], lr=1e-5, eps=1e-6)
# Accelerator 설정
accelerator = Accelerator()
model, optimizer = accelerator.prepare(model, optimizer)
class QADataset(Dataset):
def __init__(self, data, tokenizer):
self.data = data
self.tokenizer = tokenizer
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
item = self.data[idx]
question = item['question']
context = item['context']
answer = item['answer']
input_text = f"### 질문: {question}\n\n### 맥락: {context}\n\n### 답변:"
target_text = f"### 질문: {question}\n\n### 맥락: {context}\n\n### 답변: {answer}"
answers = self.tokenizer(answer, return_tensors='pt', padding='longest', truncation=True, max_length=self.tokenizer.model_max_length)
inputs = self.tokenizer(input_text, return_tensors='pt', padding='longest', truncation=True, max_length=self.tokenizer.model_max_length)
targets = self.tokenizer(target_text, return_tensors='pt', padding='longest', truncation=True, max_length=self.tokenizer.model_max_length)
inputs = {key: val.squeeze(0) for key, val in inputs.items()}
targets = {key: val.squeeze(0) for key, val in targets.items()}
return inputs, targets, answers
# collate_fn 정의
def collate_fn(batch):
input_ids = [item[0]['input_ids'] for item in batch]
attention_mask = [item[0]['attention_mask'] for item in batch]
target_ids = [item[1]['input_ids'] for item in batch]
answers = [item[2] for item in batch]
input_ids = torch.nn.utils.rnn.pad_sequence(input_ids, batch_first=True, padding_value=tokenizer.pad_token_id)
attention_mask = torch.nn.utils.rnn.pad_sequence(attention_mask, batch_first=True, padding_value=0)
target_ids = torch.nn.utils.rnn.pad_sequence(target_ids, batch_first=True, padding_value=tokenizer.pad_token_id)
return {'input_ids': input_ids, 'attention_mask': attention_mask}, {'input_ids': target_ids}, answers
# 데이터 로드
with open('all_data.json', 'r', encoding='utf-8') as f:
qa_data = json.load(f)
print(f"Loaded {len(qa_data)} QA pairs")
dataset = QADataset(qa_data, tokenizer)
dataloader = DataLoader(dataset, batch_size=2, shuffle=True, collate_fn=collate_fn)
# GPU 메모리 관리 함수
def free_memory():
torch.cuda.empty_cache()
from torch.nn import CrossEntropyLoss
loss_fn = CrossEntropyLoss(ignore_index=tokenizer.pad_token_id) # 패딩 토큰을 무시하도록 설정
# 학습 루프
num_epochs = 10
answer_weight = 0.5
# 스케줄러 설정
scheduler = optim.lr_scheduler.LinearLR(optimizer, start_factor=0.1, end_factor=1.0, total_iters=len(dataloader) * num_epochs)
# '### 답변:'의 토큰화
answer_prompt = "### 답변:"
answer_prompt_tokens = tokenizer.encode(answer_prompt, add_special_tokens=False)
model.train()
for epoch in range(num_epochs):
epoch_loss = 0
progress_bar = tqdm(dataloader, desc=f"Epoch {epoch + 1}/{num_epochs}")
for batch in progress_bar:
optimizer.zero_grad() # 옵티마이저 초기화
inputs, targets, answers = batch
input_ids = inputs['input_ids'].to(device)
attention_mask = inputs['attention_mask'].to(device)
target_ids = targets['input_ids'].to(device)
# 프리픽스 벡터를 입력에 결합
batch_size = input_ids.size(0)
expanded_prefix_vectors = prefix_vectors.unsqueeze(0).expand(batch_size, -1, -1)
inputs_embeds = model.get_input_embeddings()(input_ids)
inputs_embeds = torch.cat((expanded_prefix_vectors, inputs_embeds), dim=1)
# attention_mask 확장
attention_mask = torch.cat((torch.ones(batch_size, prefix_length).to(device), attention_mask), dim=1)
# target_ids를 inputs_embeds의 길이에 맞게 패딩
target_ids = torch.nn.functional.pad(target_ids, (0, inputs_embeds.size(1) - target_ids.size(1)), value=tokenizer.pad_token_id)
outputs = model(inputs_embeds=inputs_embeds, attention_mask=attention_mask, labels=target_ids)
logits = outputs.logits
# 손실 계산
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = target_ids[..., 1:].contiguous()
loss = loss_fn(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
loss_answer = 0
# 답변 부분의 Loss 계산
# for i in range(batch_size):
# input_id = input_ids[i]
# try:
# # '### 답변:'의 토큰 시작 위치 찾기
# for j in range(len(input_id) - len(answer_prompt_tokens) + 1):
# if torch.equal(input_id[j:j+len(answer_prompt_tokens)], torch.tensor(answer_prompt_tokens).to(device)):
# answer_start_idx = j + len(answer_prompt_tokens)
# break
# # 답변 부분의 토큰 추출 및 손실 계산
# answer_end_idx = shift_logits.size(1) # 답변 끝까지
# shift_logits_answer = shift_logits[i, answer_start_idx:answer_end_idx, :].contiguous()
# shift_labels_answer = shift_labels[i, answer_start_idx:answer_end_idx].contiguous()
# # 가중치 적용된 손실 계산
# answer_loss = loss_fn(shift_logits_answer.view(-1, shift_logits_answer.size(-1)), shift_labels_answer.view(-1))
# answer_loss = answer_loss * answer_weight # 가중치 적용
# loss_answer += answer_loss.mean()
# except IndexError:
# pass
# loss_answer = loss_answer / len(answers)
total_loss = loss + loss_answer
# NaN 값 체크
if torch.isnan(prefix_vectors).any():
print("NaN detected in prefix_vectors. Stopping training.")
exit()
# Backward pass
total_loss.backward()
# 수동으로 옵티마이저 스텝 수행
for group in optimizer.param_groups:
for p in group['params']:
if p.grad is not None:
lr = group['lr']
state = optimizer.state[p]
if 'exp_avg' not in state:
state['exp_avg'] = torch.zeros_like(p.data)
if 'exp_avg_sq' not in state:
state['exp_avg_sq'] = torch.zeros_like(p.data)
beta1, beta2 = 0.9, 0.999
state['exp_avg'].mul_(beta1).add_(p.grad, alpha=1 - beta1)
state['exp_avg_sq'].mul_(beta2).addcmul_(p.grad, p.grad, value=1 - beta2)
bias_correction1 = 1 - beta1 ** (epoch + 1)
bias_correction2 = 1 - beta2 ** (epoch + 1)
step_size = lr / bias_correction1
denom = (state['exp_avg_sq'].sqrt() / torch.sqrt(torch.tensor(bias_correction2, device=p.data.device, dtype=p.data.dtype))).add_(1e-6)
p.data.addcdiv_(state['exp_avg'], denom, value=-step_size)
scheduler.step()
epoch_loss += total_loss.item()
progress_bar.set_postfix({
'average loss' : epoch_loss / (progress_bar.n + 1),
'current loss' : total_loss.item(),
'loss' : loss.item()
# 'answer loss' : loss_answer.item()
})
free_memory() # GPU 메모리 관리
print(f"Epoch {epoch + 1} completed with loss: {epoch_loss / len(dataloader)}")
print("Prefix Tuning 완료!")
# 최종적으로 모든 파라미터에 대해 업데이트된 값을 출력
print("\nFinal updated prefix_vectors:")
print(prefix_vectors.data)
# 모델 config와 프리픽스 벡터 파라미터 저장
output_dir = './model_output'
model.save_pretrained(output_dir)
tokenizer.save_pretrained(output_dir)
torch.save(prefix_vectors.cpu(), f'{output_dir}/prefix_vectors.pt')
print(f"Model config and prefix vectors saved to {output_dir}")