[프로젝트] Deep Learning Project - Model Ensemble
Inha univ. | Deep Learning lecture
report like paper
VIT-SSD [code]
Review
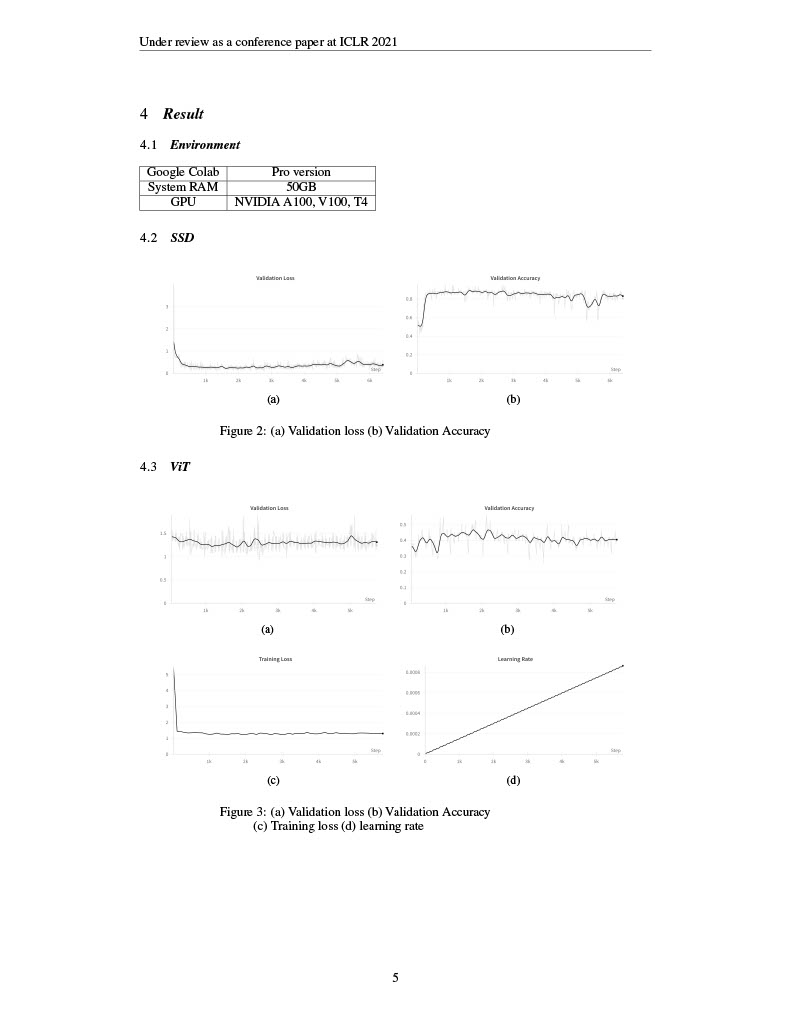
이번 프로젝트는 Deep Learning 분야에서 Vision Transformer (ViT)와 Single Shot MultiBox Detector (SSD)를 활용한 작업을 통해 이미지 분류 및 물체 탐지를 수행하는 실험을 진행했습니다. 프로젝트의 목표는 ViT를 사용하여 이미지의 feature를 추출하고, 이를 SSD에 적용하여 객체의 경계 상자를 출력하면서 동시에 분류 작업을 수행하는 것이었습니다.
데이터셋은 직접 구글 크롤링을 통해 구성하였으며, 약 3명의 여자 아이돌 이미지를 수집하여 500개의 학습용 데이터셋과 100개의 검증용 데이터셋을 구축했습니다. 각 이미지는 수동으로 bounding box를 설정하였고, 해당 객체에 대한 분류 작업도 수동으로 진행하였습니다.
비록 본 프로젝트에서 기대했던 성능이나 결과를 얻지는 못했지만, Deep Learning 프로젝트의 전 과정을 직접 경험하는 귀중한 기회였습니다. 특히, 이론적으로만 이해했던 ViT와 SSD 모델을 실제 코드로 구현하고, 이를 통해 얻은 결과를 분석하며 이론을 한층 깊이 이해할 수 있었습니다.
프로젝트 과정에서 얻은 주요 인사이트는 다음과 같습니다:
-
데이터셋 품질의 중요성: 수집된 데이터셋의 품질이 성능에 큰 영향을 미친다는 것을 깨달았습니다. 특히, 얼굴의 경계를 설정하는 기준이 일관되지 않았던 점이 결과에 부정적인 영향을 미쳤을 가능성이 있습니다.
-
모델 학습에 필요한 데이터 양: ViT와 같은 대형 모델은 성능을 극대화하기 위해 더 많은 양의 학습 데이터가 필요하다는 것을 실감했습니다. 500개의 이미지로는 충분하지 않았으며, 데이터 확장을 위해 Augmentation을 시도했지만 그마저도 제한적이었습니다.
-
사전 학습된 모델의 필요성: 제한된 시간 내에 더 나은 결과를 도출하기 위해서는 사전 학습된 모델을 사용하는 것이 필수적임을 깨달았습니다. 본 프로젝트에서는 사전 학습된 모델을 사용하지 못한 점이 성능 저하의 한 원인이었습니다.
-
자원 부족: ViT 모델을 학습하는 데 소요되는 자원이 매우 크기 때문에 코랩에서 제공되는 GPU로는 실험을 반복하고 결과를 확인하는 것이 쉽지 않았습니다. 약 30시간에 달하는 학습 시간이 요구되었으며, 이로 인해 실험을 효과적으로 수행하는 데 어려움이 있었습니다.