
[논문분석] Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Stable diffusion의 video generation version
[Page, Paper]
Stability AI
Abstract
We present Stable Video Diffusion — a latent video diffusion model for high-resolution, state-of-the-art text-to-video and image-to-video generation. Recently, latent diffusion models trained for 2D image synthesis have been turned into generative video models by inserting temporal layers and finetuning them on small, high-quality video datasets. However, training methods in the literature vary widely, and the field has yet to agree on a unified strategy for curating video data. In this paper, we identify and evalu- ate three different stages for successful training of video LDMs: text-to-image pretraining, video pretraining, and high-quality video finetuning. Furthermore, we demon- strate the necessity of a well-curated pretraining dataset for generating high-quality videos and present a system- atic curation process to train a strong base model, includ- ing captioning and filtering strategies. We then explore the impact of finetuning our base model on high-quality data and train a text-to-video model that is competitive with closed-source video generation. We also show that our base model provides a powerful motion representation for down- stream tasks such as image-to-video generation and adapt- ability to camera motion-specific LoRA modules. Finally, we demonstrate that our model provides a strong multi-view 3D-prior and can serve as a base to finetune a multi-view diffusion model that jointly generates multiple views of ob- jects in a feedforward fashion, outperforming image-based methods at a fraction of their compute budget. We release code and model weights at https://github.com/ Stability-AI/generative-models.
기존의 접근 방법은 2D 생성을 위한 LDM(Latent Diffusion Model)에 대해서 시간축 레이어를 추가 후 작은 비디오 세트에 대해서 파인튜닝하는 방식을 통해 Video Generation Model을 생성
하지만, 큐레이션 및 학습 방법에 대한 통일화 된 방법을 얻지 못하는 문제를 가짐
이에 따라 이 논문에서는 Video LDM 모델을 생성하기 위해 크게 Text-to-Image, Video Pretraining, High-Quality Video Finetuning 단계로 실험을 진행
Introduction
최근 연구들은 spatial and temporal layers를 통한 video modeling 개선에만 초첨을 맞춰왔다. → 훈련 데이터 분포가 생성 모델에 미치는 중요한 영향이 잘 알려지지 않았다.
데이터 선택의 중요성
핵심 포인트 3가지
- a systematic data curation workflow → 데이터 셋 정리
- 위 데이터 셋으로 training
- strong prior of motion and 3D understanding in our models 증명 → strong multi-view generators를 통해 3d 영역에서 발생하는 데이터 부족 문제 해결
Curating Data for HQ Video Synthesis
HQ Video Synthesis는 고화질 비디오 합성을 의미하며, 이는 인공지능 기술을 사용하여 고해상도 비디오를 생성하거나 편집하는 과정을 말합니다. 이 기술은 다양한 응용 분야에서 사용될 수 있으며, 주로 딥러닝 모델과 최신 컴퓨터 비전 기술을 활용하여 구현됩니다.
1. Data Processing and Annotation
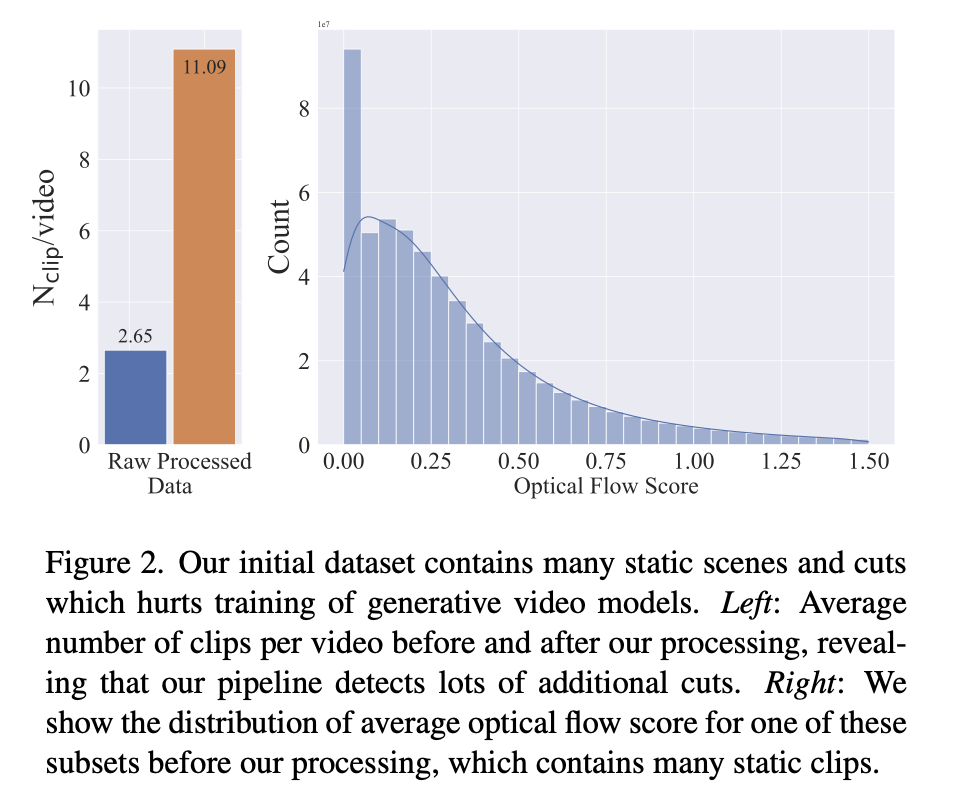
합성된 동영상에서 cuts and fades가 누출되는 것을 방지하기 위해 세 가지 다른 FPS 수준에서 계단식 방식으로 컷 감지 파이프라인을 적용
clip 수가 processing 후에 4배 증가
optical flow 역시 낮은 쪽에 분포가 높다 → 비디오에 동작(motion)이 적다
각 클립에 세 가지 다른 동기화 캡션 방법을 사용하여 주석을 적용
- 이미지 캡션 프로그램인 CoCa [108]를 사용하여 각 클립의 중간 프레임에 주석
- V-BLIP [109]을 사용하여 비디오 기반 캡션
- 처음 두 캡션의 LLM 기반 요약을 통해 클립에 대한 세 번째 설명을 생성
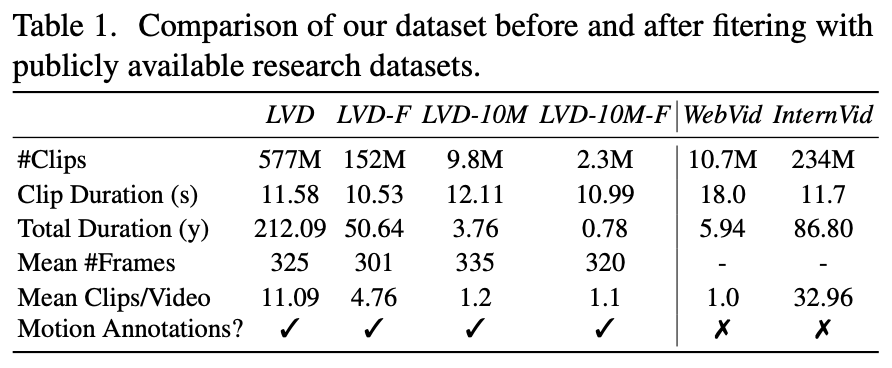
→ 이렇게 생성된 초기 데이터 세트는 5억 8천만 개의 주석이 달린 비디오 클립 쌍으로 구성, Large Video Dataset (LVD)
하지만 위에 방법으로 움직임이 적거나 텍스트가 과도하게 존재하거나 일반적으로 에스테틱 값이 낮은 클립 등 최종 비디오 모델의 성능을 저하시킬 수 있는 예시가 포함되어 있었음.
- optical flow를 통해 추가적으로 주석을 처리 2 FPS 에서 특정 임계값 이하의 optical flow는 제거
- 광학 문자 인식을 적용하여 대량의 텍스트가 포함된 클립을 걸러냄
- 각 클립의 첫 번째, 중간, 마지막 프레임에 클립[66] 임베딩을 통해 주석을 달아 미학 점수와 텍스트-이미지 유사성을 계산
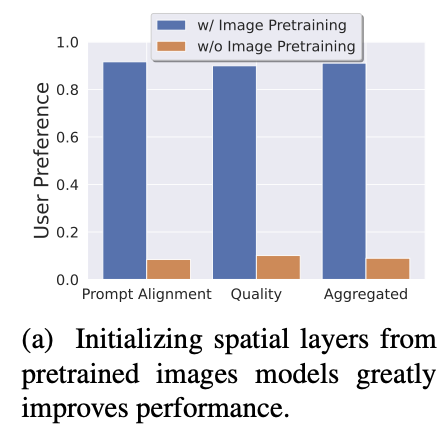
Stage I: Image Pretraining
이미지로 먼저 학습 → 퀄리티 업
Stage II: Curating a Video Pretraining Dataset
A systematic approach to video data curation : 인간에 선호도에 따른 분류를 진행
- LVD 데이터셋에서 무작위로 추출된 9.8M 개의 예제를 포함한 하위 집합(LVD-10M)을 사용
- 무작위로 샘플링된 9.8M 예제 중 하위 12.5%, 25%, 50%의 데이터를 순차적으로 제거
- CLIP scores: 이미지와 텍스트 간의 유사성을 측정하는 점수.
- Aesthetic scores: 이미지의 미적 품질을 평가하는 점수.
- OCR detection rates: 이미지에서 텍스트가 얼마나 잘 감지되는지를 평가하는 비율.
- Synthetic captions: 이미지에 대한 인공지능 생성 캡션.
- Optical flow scores: 동영상 프레임 간의 움직임을 측정하는 점수.
인공지능 생성 캡션(synthetic captions)에 대해서는 이 방식으로 필터링할 수 없기 때문에 Elo 순위를 사용
- 필터링된 데이터셋으로 모델을 훈련시킨 후, 인간 평가자의 선호도에 따라 모델 성능을 Elo 순위로 평가
- 이 필터링 접근 방식을 적용하여 최종적으로 152M 개의 예제를 포함하는 데이터셋을 구성
→ 이 데이터셋이 LVD-F
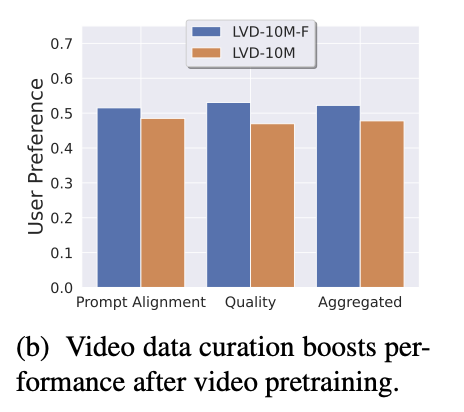
사람들은 F를 더 선호함
Stage III: High-Quality Finetuning
i) 비디오 사전 학습과 비디오 미세 조정에서 비디오 모델 학습을 분리하는 것이 미세 조정 후 최종 모델 성능에 유리하며
ii) 사전 학습 후 성능 차이가 미세 조정 후에도 지속되므로 비디오 사전 학습은 대규모의 선별된 데이터 세트에서 수행하는 것이 이상적이라는 결론
Appendix C.
We start from a large collection of raw video data which is not useful for generative text-video (pre)training
Cascaded Cut Detection
we use PySceneDetect 2 to detect cuts in our base video clips.
https://github.com/Breakthrough/PySceneDetect
Keyframe-Aware Clipping
We clip the videos using FFMPEG to quickly extract clips without cuts via seeking
Optical Flow
dense optical flow maps at 2fps using the OpenCV [48] implementation of the Farneba ̈ck algorithm
스토리지 크기를 더 작게 유지하기 위해 가장 짧은 면이 16픽셀 해상도가 되도록 플로우 맵을 공간적으로 다운스케일링
이러한 맵을 시간과 공간 좌표에 걸쳐 평균화하여 각 클립에 대한 글로벌 모션 점수를 얻은 다음, 필요한 최소 모션에 대한 임계값을 사용하여 정적 장면을 필터링하는 데 사용
이렇게 하면 대략적인 결과만 얻을 수 있으므로 최종 3단계 미세 조정을 위해 800 × 450 해상도에서 RAFT[89]를 사용하여 보다 정확한 고밀도 광학 흐름 맵을 계산합니다. 그런 다음 모션 스코어도 비슷하게 계산
Model training
Pretrained Base Model
Stable Diffusion 2.1 기반으로 학습
- 256 × 384 크기의 이미지에 대해 Karras 등[51]에서 제안한 네트워크 전제 조건을 사용하여 이미지 모델의 고정 이산 노이즈 스케줄을 연속 노이즈[87]로 미세 조정
- 템포럴 레이어를 삽입한 다음, 256 × 384 해상도의 14개 프레임에서 LVD-F로 모델을 훈련
- 150,000회 반복과 배치 크기 1536에 대해 표준 EDM 노이즈 스케줄[51]을 사용
- 배치 크기 768을 사용하여 100,000회 반복에 대해 14개의 320 × 576 프레임을 생성하도록 모델을 미세 조정 → 이 훈련 단계에서 노이즈 스케줄을 더 많은 노이즈로 이동하는 것이 중요하다는 것을 발견했으며, 이는 이미지 모델에 대한 Hoogeboom 등[44]의 결과를 확인
이 기본 모델을 가지고 미세조정 가능
text to video
약 1백만 개의 샘플로 구성된 고품질 비디오 데이터 세트에서 기본 텍스트-비디오 모델을 세밀하게 조정합니다.
데이터 세트의 샘플은 일반적으로 많은 물체 움직임, 안정적인 카메라 움직임, 잘 정렬된 캡션이 포함되어 있으며 전체적으로 시각적 품질이 높습니다.
배치 크기 768을 사용하여 해상도 576 × 1024에서 50,000회의 반복을 위해 기본 모델을 미세 조정합니다(다시 노이즈 스케줄을 더 많은 노이즈로 이동).

High Resolution Image-to-Video Model
기본 모델에 공급되는 텍스트 임베딩을 컨디셔닝의 클립 이미지 임베딩과 함께 다시 배치
노이즈가 증강된 버전의 컨디셔닝 프레임을 채널별로 UNet 의 입력에 연결
마스킹 기법을 사용하지 않고 단순히 시간 축에 걸쳐 프레임을 복사
이외 디테일 논문 확인
Camera Motion LoRA
줌 인아웃 같은 카메라 기법들 사용