
[보고서분석] report : An image deblurring method using improved U‐Net model based on multilayer fusion and attention mechanism
U-Net을 기반으로 하는 image deblurring, low cost [Page]
Zuozheng Lian & Haizhen Wang
such methods often suffer from limited inherent interconnections across various hierarchical levels, resulting in inadequate receptive fields and suboptimal deblurring outcomes
이런 상황에서 U-net은 효율적, 파라미터 수 줄임, 정확도 상승
Firstly, the model structure was designed, incorporating two key components: the MLFF (multilayer feature fusion) module and the DMRFAB (dense multi‐receptive field attention block).
Abstract
The investigation of image deblurring techniques in dynamic scenes represents a prominent area of research. Recently, deep learning technology has gained extensive traction within the field of image deblurring methodologies. However, such methods often suffer from limited inherent interconnections across various hierarchical levels, resulting in inadequate receptive fields and suboptimal deblurring outcomes. In U‐Net, a more adaptable approach is employed, integrating diverse levels of features effectively. Such design not only significantly reduces the number of parameters but also maintains an acceptable accuracy range. Based on such advantages, an improved U‐Net model for enhancing the image deblurring effect was proposed in the present study. Firstly, the model structure was designed, incorporating two key components: the MLFF (multilayer feature fusion) module and the DMRFAB (dense multi‐receptive field attention block). The aim of these modules is to improve the feature extraction ability. The MLFF module facilitates the integration of feature information across various layers, while the DMRFAB module, enriched with an attention mechanism, extracts crucial and intricate image details, thereby enhancing the overall information extraction process. Finally, in combination with fast Fourier transform, the FRLF (Frequency Reconstruction Loss Function) was proposed. The FRLF obtains the frequency value of the image by reducing the frequency difference. The present experiment results reveal that the proposed method exhibited higher‐quality visual effects. Specifically, for the GoPro dataset, the PSNR (peak signal‐ to‐noise ratio) reached 31.53, while the SSIM (structural similarity index) attained a value of 0.948. Additionally, for the Real Blur dataset, the PSNR achieved 31.32, accompanied by an SSIM score of 0.934.
동적 장면에서 이미지 블러링 기법을 연구하는 것은 주목할 만한 연구 분야입니다. 최근 딥러닝 기술은 이미지 디블러링 방법론 분야에서 광범위한 주목을 받고 있습니다. 그러나 이러한 방법은 다양한 계층적 수준에서 고유한 상호 연결이 제한되어 있어 수용 영역이 부적절하고 디블러링 결과가 최선이 아닌 경우가 많습니다. U-Net에서는 다양한 수준의 기능을 효과적으로 통합하는 보다 적응력 있는 접근 방식이 사용됩니다. 이러한 설계는 파라미터의 수를 크게 줄일 뿐만 아니라 허용 가능한 정확도 범위를 유지합니다. 이러한 장점을 바탕으로 본 연구에서는 이미지 디블러링 효과를 향상시키기 위한 개선된 U-Net 모델을 제안했습니다. 먼저 MLFF(다층 특징 융합) 모듈과 DMRFAB(고밀도 다중 수용 필드 주의 블록)이라는 두 가지 핵심 구성 요소를 통합한 모델 구조를 설계했습니다. 이 모듈의 목적은 특징 추출 능력을 향상시키는 것입니다. MLFF 모듈은 다양한 레이어에 걸쳐 특징 정보를 통합하는 것을 용이하게 하고, 주의 메커니즘이 강화된 DMRFAB 모듈은 중요하고 복잡한 이미지 세부 사항을 추출하여 전반적인 정보 추출 프로세스를 향상시킵니다. 마지막으로 고속 푸리에 변환과 함께 주파수 재구성 손실 함수(FRLF)가 제안되었습니다. FRLF는 주파수 차이를 줄임으로써 이미지의 주파수 값을 얻습니다. 실험 결과 제안한 방법이 더 높은 품질의 시각 효과를 나타냈습니다. 구체적으로 GoPro 데이터 세트의 경우 PSNR(피크 신호 대 잡음비)은 31.53에 달했고, SSIM(구조적 유사성 지수)은 0.948의 값을 얻었습니다. 또한 리얼 블러 데이터 세트의 경우 PSNR은 31.32를 기록했으며 SSIM 점수는 0.934를 기록했습니다.
MLFF(다층 특징 융합) 모듈
DMRFAB(고밀도 다중 수용 필드 주의 블록)
고속 푸리에 변환과 함께 주파수 재구성 손실 함수(FRLF)
Introduction
(1) 이미지 디블러링 목적에 맞는 개선된 U-Net 아키텍처를 조사 및 개발하고, (2) 다양한 레이어에서 이미지 디테일과 중요 정보를 추출할 수 있는 핵심 모듈을 조사 및 식별하여 이미지 특징 추출 기능을 향상시키고 시각적 결과물을 개선
(1) 하나의 인코더와 4개의 블록을 가진 하나의 디코더를 포함한 U-Net 기반 4 계층 네트워크를 제안했습니다.
(2) U-Net 네트워크의 여러 계층에 특징 정보를 통합하고 기존 U-Net 네트워크의 고유 한 정보 흐름 모드를 변경하며 다양한 규모의 특징 정보를 통합하는 MLFF 모듈을 추가하여 네트워크가 더 많은 특징 정보를 추출 할 수 있도록했습니다;
(3) 심층 특징에서 중요한 정보를 추출하고 그에 따라 영상 디블러링 효과를 개선하기 위해 CAM(채널 주의 메커니즘)과 SAM(공간 주의 메커니즘)을 모두 도입한 DMRFAB 모듈을 통합하고,
(4) 손실 함수에 FFT를 도입하고 영상의 주파수 차이를 줄여 영상의 주파수 값을 구할 수 있는 FRLF를 제안하여 디블러링 효과를 개선했습니다.
제안한 모델은 GoPro 및 실제 블러 데이터 세트를 사용하여 정량적, 정성적 분석을 거쳤습니다. 그 결과 제안한 모델을 통해 이미지 디블러링 품질이 크게 향상되었음을 확인
Method
요약
-
인코더는 4개의 블록을 사용하여 2-2-2-2의 컨볼루션 구조로 각 레이어에서 특징을 추출
ChatGPT
그림에서 E1, E2, E3, E4 각각이 2개의 컨볼루션 연산을 거친다는 의미는 다음과 같습니다:
- E1: 첫 번째 인코더 블록으로, 2개의 컨볼루션 레이어를 거쳐 특징을 추출합니다.
- E2: 두 번째 인코더 블록으로, 마찬가지로 2개의 컨볼루션 레이어를 거쳐 특징을 추출합니다.
- E3: 세 번째 인코더 블록으로, 2개의 컨볼루션 레이어를 거쳐 특징을 추출합니다.
- E4: 네 번째 인코더 블록으로, 2개의 컨볼루션 레이어를 거쳐 특징을 추출합니다.
각 블록은 아래와 같은 순서로 작동합니다:
- 첫 번째 컨볼루션 연산
- 두 번째 컨볼루션 연산
따라서, “2-2-2-2” 구조는 각 인코더 블록에서 2개의 컨볼루션 레이어를 사용하여 입력 특징을 점진적으로 추출하는 것을 의미합니다. 이러한 방식은 입력 이미지의 특징을 효율적으로 추출하고 다음 단계로 전달합니다.
반면, 디코더 블록인 D1, D2, D3, D4는 “2-3-3-2” 구조를 따릅니다. 이는 다음과 같습니다:
- D1: 2개의 컨볼루션 레이어
- D2: 3개의 컨볼루션 레이어
- D3: 3개의 컨볼루션 레이어
- D4: 2개의 컨볼루션 레이어
디코더는 이 구조를 통해 복잡한 특징을 복원하고 이미지를 점차적으로 선명하게 만듭니다.
따라서, E1, E2, E3, E4는 각각 2개의 컨볼루션 연산을 거친다는 의미가 맞습니다. 이는 인코더에서 입력 이미지를 효과적으로 처리하고 중요한 특징을 추출하기 위한 구조입니다.
초기 블록을 제외한 모든 블록은 이산 웨이블릿 변환(DWT)을 사용한 다운샘플링 작업 한 번과 컨볼루션 작업 두 번을 포함하는 특정 프로세스를 거침
각 레이어에서 추출된 특징은 MLFF 모듈을 통해 융합
디코더는 2-3-3-2의 컨볼루션 구조로 4개의 블록을 채택
마지막 블록을 제외한 각 블록은 두 번의 컨볼루션과 한 번의 역 웨이블릿 변환(IWT)을 거침
컨볼루션 파라미터와 계산 복잡성을 줄이고 딥 네트워크의 성능 저하 문제를 해결하기 위해 컨볼루션 블록은 DSC(깊이별 분리 가능 컨볼루션) 및 RDSC(잔여 깊이별 분리 가능 컨볼루션)로 대체
인코더와 디코더는 DMRFAB을 통해 연결되어 더 풍부하고 세밀한 특징 추출
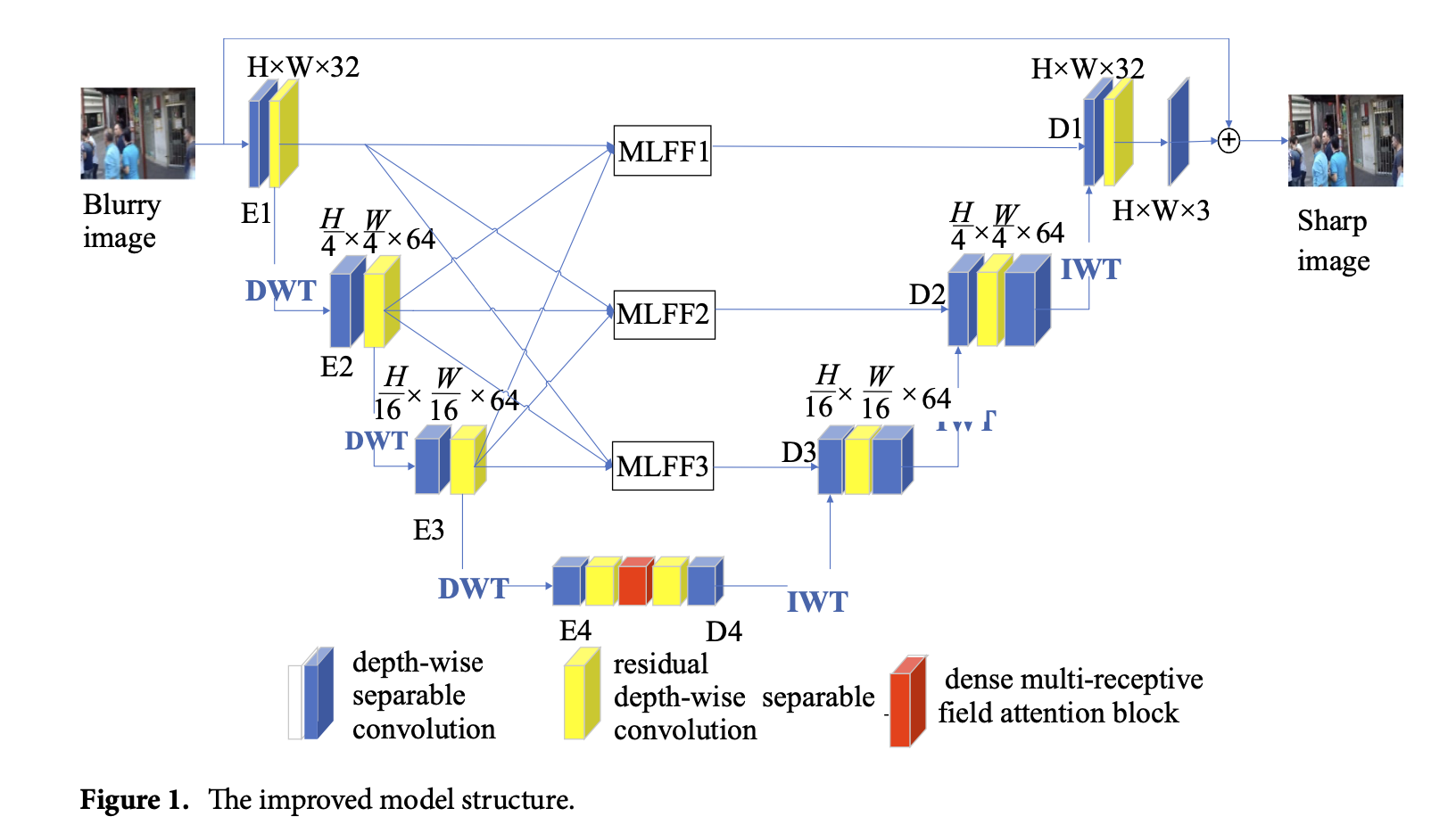
이 모델은 주로 DSC, 3개의 RDSC를 포함한 RDSC 그룹, DWT, IWT, MLFF 모듈, DMRFAB 모듈로 구성됩니다. 모델은 왼쪽에 인코더가 있고 오른쪽에 디코더가 있는 U-Net 기반의 4계층 네트워크입니다. 입력 이미지는 H × W × 3으로 표현되며, 여기서 H는 이미지의 높이, W는 이미지의 너비, 3은 이미지의 채널 수를 나타냅니다. 모델 처리에는 다음 세 단계가 포함됩니다:
인코딩 단계
- 첫 번째 레이어는 32채널 DSC와 하나의 RDSC 그룹으로 구성되며, 입력 이미지를 H×W×32로 변환하여 E1로 표현됩니다.
- 두 번째 레이어는 첫 번째 레벨 DWT를 통해 첫 번째 레이어에서 추출된 정보를 처리하여, 64채널 DSC와 하나의 RDSC 그룹을 사용하여 입력 특징 정보를 H/4 × W/4 × 64로 변환하여 E2로 표현합니다.
- 세 번째 레이어는 두 번째 레벨 DWT를 거친 후, 하나의 DSC와 하나의 RDSC 그룹을 사용하여 변환된 특징 정보를 H/16 × W/16 × 128로 변환하여 E3로 표현합니다.
- 네 번째 레이어는 세 번째 레벨 DWT를 거친 후, 들어오는 정보를 하나의 DSC, 하나의 RDSC 그룹, 하나의 DMRFAB를 사용하여 H/32 × W/32 × 256로 변환합니다. 그 후 DSC를 통해 채널 수를 512로 줄입니다.
(2) 인코더의 E1, E2, E3의 특징 정보는 다양한 레이어의 특징 정보를 융합하기 위해 MLFFI(i=1,2,3)에 입력됩니다.
디코딩 단계
- IWT는 출력 정보를 D4에서 네 번째 레이어를 통해 수행되며, 세 번째 레이어에서 D3와 함께 H/16 × W/16 × 128로 변환된 후, 하나의 DSC 그룹과 하나의 RDSC 그룹으로 들어가 채널 수를 256으로 늘립니다.
- 두 번째 레이어는 D2와 함께 하나의 DSC 그룹과 하나의 RDSC 그룹으로 들어가 H/4 × W/4 × 64로 변환합니다. 그 후, IWT 출력을 위해 두 번째 DSC 작업이 수행되어 채널 수를 128로 늘립니다.
- 첫 번째 레이어는 D1과 함께 하나의 DSC 그룹과 하나의 RDSC 그룹으로 들어가 H×W×32로 변환합니다. 분리된 컨볼루션 특징 정보는 H×W×3이 되도록 추가되고 초기 입력 모델의 이미지 정보와 융합되어 흐릿한 이미지를 복원한 결과를 얻습니다.
모델의 모듈 상세 소개
DSC
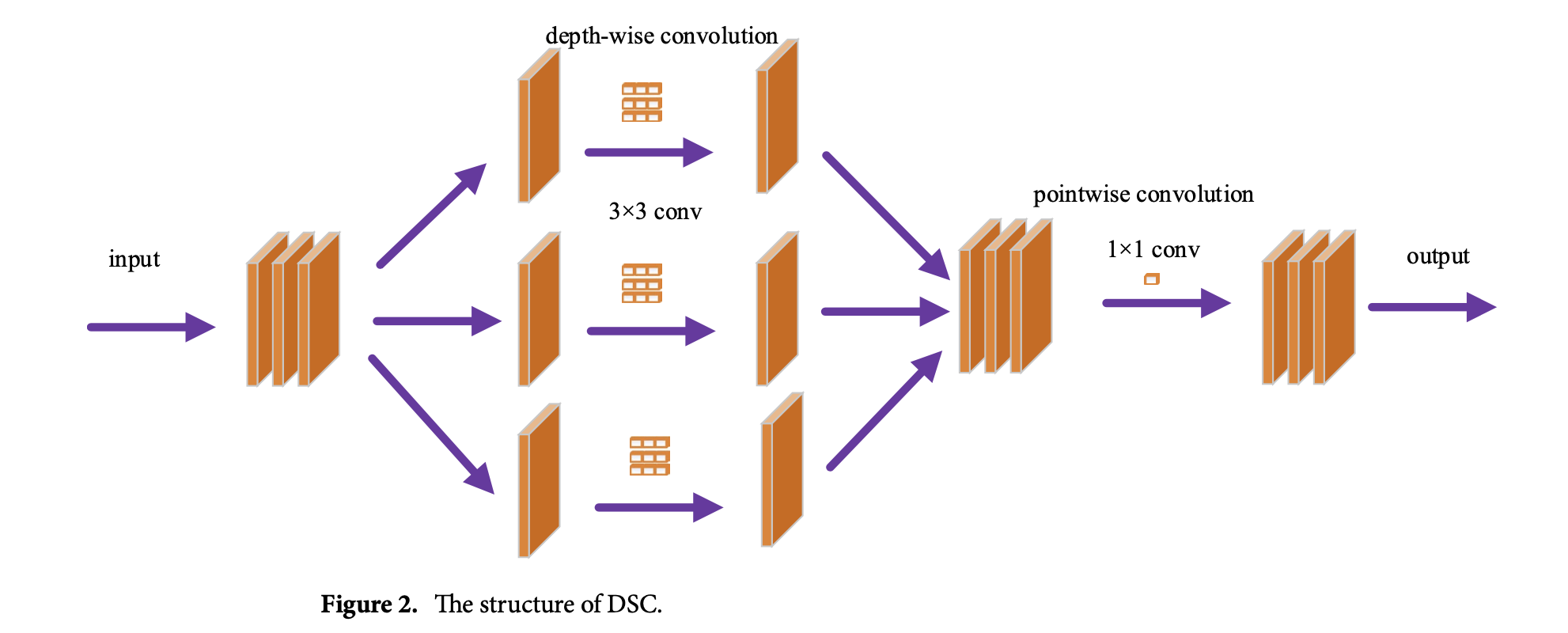
개선된 모델은 모델 파라미터 수를 줄이고 네트워크를 경량화하는 DSC를 도입합니다. DSC는 DWC(깊이별 분리 컨볼루션)와 PWC(포인트 와이즈 컨볼루션)로 구성됩니다. DWC는 이전 레이어의 다채널 특징을 단일 채널의 특징 맵으로 나누고, 3×3 컨볼루션 커널을 사용하여 컨볼루션을 수행합니다. 그 후, DWC는 동일한 채널 수를 유지하면서 이전 레이어의 특징 맵 크기를 조정하여 특징을 다시 결합합니다. DWC로 얻은 특징 이미지는 PWC를 사용하여 컨볼루션됩니다. PWC는 1×1 컨볼루션 커널을 사용하여 DWC의 컨볼루션 결과를 혼합하면서 필요한 출력 채널 수로 유연하게 변경할 수 있습니다.
RDSC
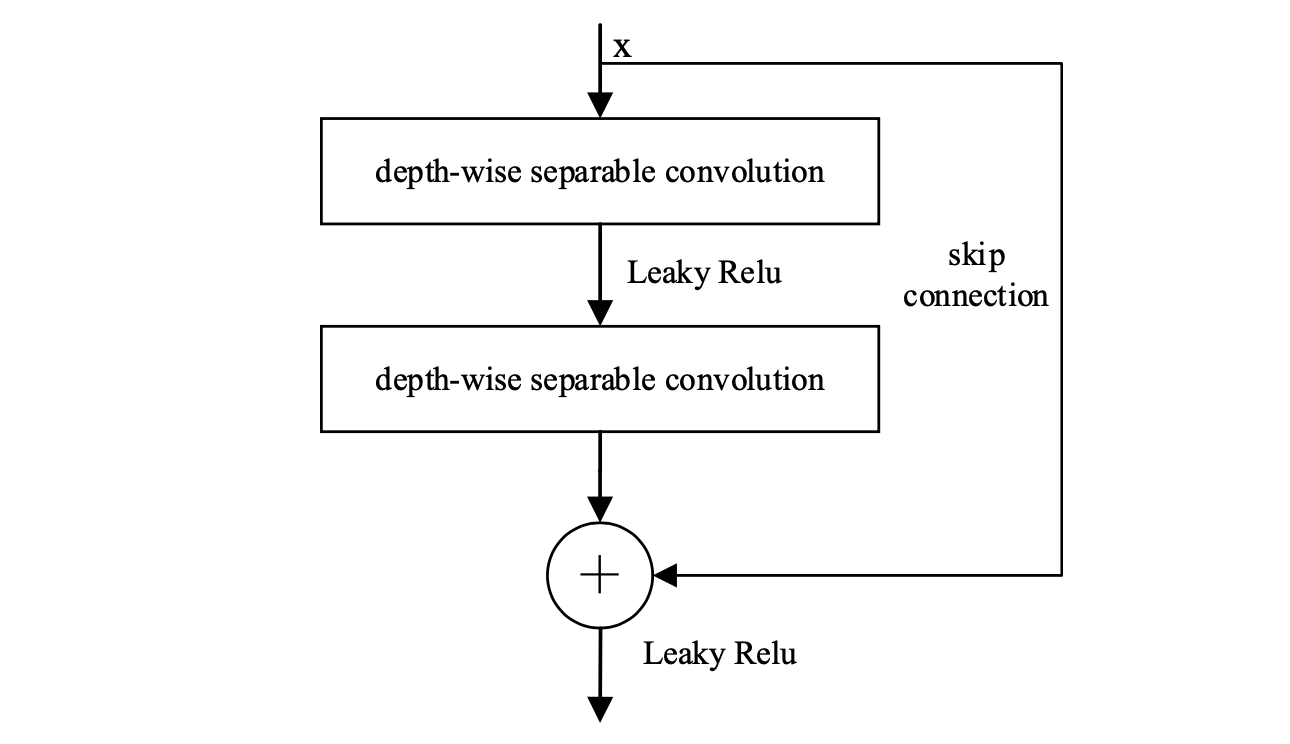
RDSC는 잔여 네트워크를 기반으로 설계되었으며, 다양한 레이어에서 세부 정보를 확산하여 블러 복원 품질을 향상시킵니다. 또한 그래디언트 소멸 문제를 완화하는 메커니즘으로도 작용합니다. RDSC는 두 개의 DSC와 두 개의 Leaky ReLU 활성화 함수로 구성되며, Fig. 3에 그 구조가 나와 있습니다. 먼저, DSC, Leaky ReLU 및 DSC 연산이 입력 정보에 대해 수행됩니다. 그런 다음, 얻어진 특징과 입력 정보는 스킵 연결 방식을 통해 융합됩니다. 마지막으로, 융합 결과는 Leaky ReLU 처리 후 출력됩니다.
DWT 및 IWT
DWT와 IWT는 각각 U-Net 모델의 다운샘플링 및 업샘플링 기능을 담당하며, 서로 다른 주파수에서 다양한 특징 정보를 얻을 수 있게 합니다. 이렇게 함으로써 블러 이미지 처리를 위해 상호 간섭을 줄입니다. DWT와 IWT는 그림 1에 설명된 대로 특징 계수를 추출하고 필터링하는 데 사용됩니다.
E1, E2, E3 결과와 디코더에서 IWT 수행
Haar 웨이블릿은 구현이 쉽고 작동이 간편한 웨이블릿 기저 함수입니다. 따라서 본 연구에서는 이차원 Haar 웨이블릿 변환을 사용하여 이미지 신호를 방향성 서브밴드로 나누었습니다. 필터링은 DWT를 실현하는 효과적인 방법입니다. 먼저, Eq. (1)에 정의된 1차원 고역 통과 필터인 φ(x)를 사용하여 이미지의 각 열을 필터링하고 수직으로 다운샘플링합니다. 다음으로, Eq. (2)에 정의된 φ(x)와 ψ(x)를 사용하여 각 행을 필터링하고 수평으로 다운샘플링합니다. 이 과정은 I_HH와 I_HL의 서브 주파수 정보를 제공합니다. 두 번째 단계에서는 ψ(x) 필터를 사용하여 이미지의 각 열을 필터링하고 수직으로 다운샘플링합니다. 다시 한번, φ(x)와 ψ(x)를 사용하여 각 열을 필터링하고 수평으로 다운샘플링합니다. 이로 인해 I_HH와 I_HL의 서브 주파수 정보를 얻게 됩니다. 네 가지 매개변수의 서브 주파수 정보는 Eq. (3)에서 (6)에 나와 있습니다.
\[\phi(x) = [-1, 1]\] \[\psi(x) = [1, 1]\] \[I_{HL}(x, y) = \phi(x) \psi(y)\] \[I_{HH}(x, y) = \phi(x) \phi(y)\] \[I_{LH}(x, y) = \psi(x) \phi(y)\] \[I_{LL}(x, y) = \psi(x) \psi(y)\]x와 y는 각각 이미지의 행과 열을 나타내며:
- \(I_{HL}\) : 이미지의 수평 고주파 및 수직 저주파 정보
- \(I_{HL}\) : 이미지의 수평 및 수직 고주파 정보
- \(I_{LL}\) : 이미지의 수평 및 수직 저주파 정보
- \(I_{LH}\) : 이미지의 수평 저주파 및 수직 고주파 정보
IWT는 앞서 언급된 필터를 사용하여 네 개의 서브 이미지를 원본 이미지로 복원하는 역연산을 수행합니다. 따라서 원본 이미지는 DWT에 의해 분해되고 IWT를 통해 정보 손실 없이 재구성됩니다. 또한, 다중 레벨 웨이블릿 변환은 \(I_{HL}, I_{HH}, I_{LL}, I_{LH}\) 을 처리함으로써 구현할 수 있습니다. 이차원 Haar 웨이블릿 변환의 경우, 저주파 정보에는 평균값을 사용하고, 고주파 정보에는 φ(x)를 사용합니다.
MLFF 모듈
기존의 개선된 U-Net 네트워크에서는 같은 레이어 내에서만 수평 정보 흐름이 가능하며, 레이어 간 상하 수직 정보 흐름이 제한되어 있습니다. 이에 따라, 다양한 레벨의 U-Net 간의 특징 정보의 흐름을 증가시키는 MLFF 모듈이 설계되었습니다. 이 모듈은 단순히 정보의 추가나 결합에만 의존하지 않고, 다양한 레벨의 정보를 통합하여 중복을 줄입니다. 이는 신경망의 표현 능력을 제한하는 문제를 해결합니다. SKNets를 참고하여, 네트워크의 표현력을 향상시키기 위해 동적 선택 메커니즘이 도입되었습니다. 따라서 MLFF 모듈은 정보 흐름의 유연성을 증가시키며, 정보 중복을 줄이고 모델의 성능을 향상시킵니다. MLFF의 구조는 그림 4에 나와 있으며, U-Net의 세 가지 레벨 간의 교차-레이어 저주파수 세부 사항을 포함합니다.
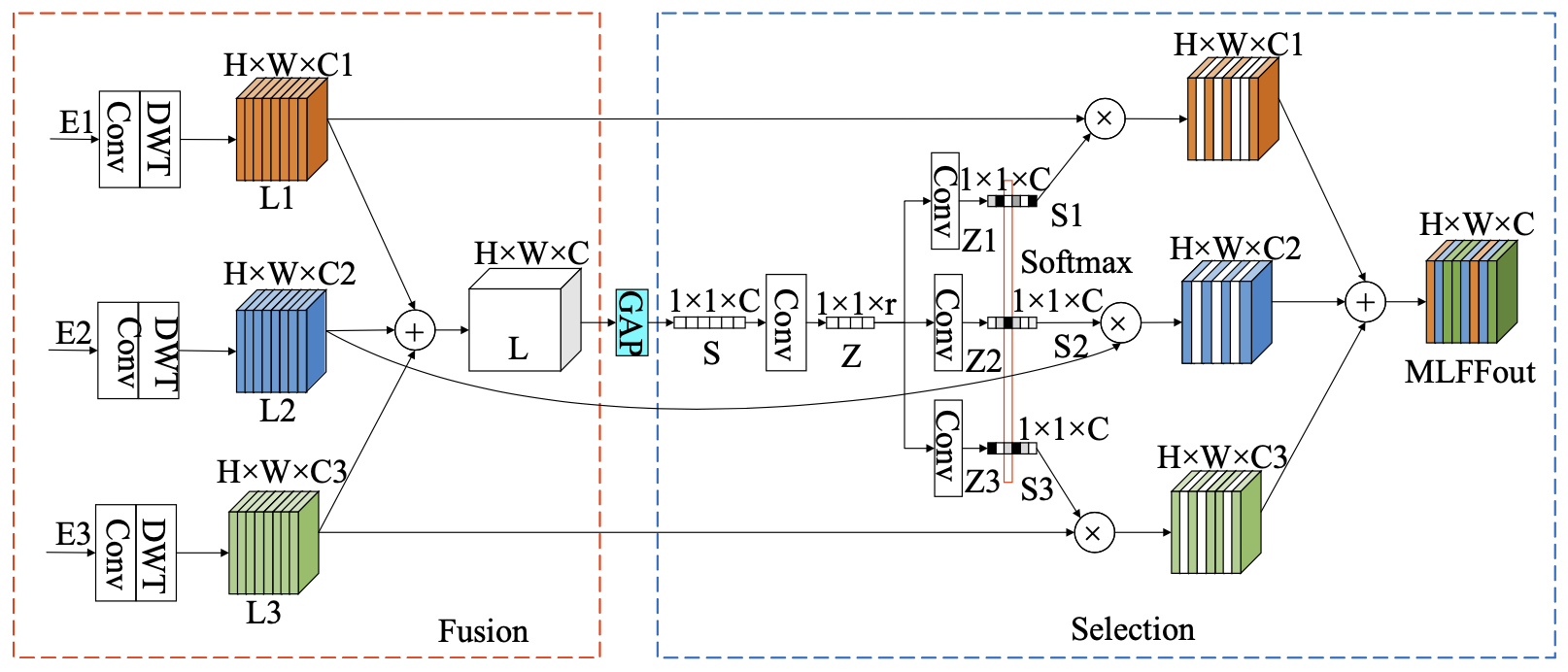
MLFF 모듈은 두 단계로 구성됩니다: 융합과 선택.
- 융합 단계: E1, E2, E3는 컨볼루션과 웨이블릿 변환을 거칩니다. 채널 수는 컨볼루션(Convy)에 의해 제어되며, 특징 크기는 웨이블릿 변환(WT)에 의해 제어됩니다. 이를 통해 각 레벨의 특징 정보가 H×W×C로 표현됩니다. 그런 다음 L1, L2, L3의 특징이 결합되어 최종 출력 L로 표현됩니다.
- 선택 단계: L에서 5개의 단계가 글로벌 평균 풀링(GAP)을 통해 얻어지며, H×W×C에서 1×1×C로 특징 크기가 변환됩니다. 다운 채널 컨볼루션 레이어는 이 변환된 특징 벡터를 더 작고 압축된 특징 벡터 Z로 변환합니다. 그런 다음 Z는 컨볼루션 레이어를 거쳐 각기 다른 활성화 채널을 가진 세 개의 특징 벡터 Z1, Z2, Z3를 생성합니다. 소프트맥스가 Z1, Z2, Z3에 적용되어 활성화된 S1, S2, S3를 얻습니다. 이 후, L1, L2, L3 특징 맵을 조정하기 위해 포인트 곱셈 연산이 각각 수행됩니다. 최종적으로, 조정된 특징들이 결합되어 MLFF 출력을 얻습니다.
MLFF의 출력 표현은 다음과 같습니다:
\[MLFFout = S1 × L1 + S2 × L2 + S3 × L3\]모델 구조는 세 개의 MLFF 모듈(MI.FF1, MI.FF2, MI.FF3)이 있으며, 이 모듈들은 융합 부분에서만 다릅니다. 즉, 다른 레벨의 특징 변환은 융합 부분에서 다르게 처리되지만, 이후 선택 부분은 동일합니다.
각 MLFF 모듈의 수식은 다음과 같습니다:
\[MLFF1 = E1 × S1^1 + (Conv(E2))^↓ × S1^2 + (Conv(E3))^↓ × S1^3\] \[MLFF2 = (Conv(E1))^↓ × S2^1 + E2 × S2^2 + (Conv(E3))^↓ × S2^3\] \[MLFF3 = (Conv(E1))^↓ × S3^1 + (Conv(E2))^↓ × S3^2 + E3 × S3^3\]여기서 MLFFi는 모델의 i번째 레이어에서 MLFF의 출력을 나타내며, Conv(·)는 웨이블릿 변환의 작동을 용이하게 하기 위해 채널 수를 조정하는 1×1의 컨볼루션 커널입니다. ↓는 웨이블릿 변환을 통해 얻어진 동일 레벨 크기를 나타내며, ↑는 IWT를 통해 얻어진 동일 레벨 크기를 나타냅니다. ×와 +는 각각 포인트 곱셈 및 특징 요소 간 덧셈 연산을 나타냅니다. Sji는 MLFFi의 다중-레이어 특징 정보 융합 후 선택 단계와 활성화 후 j번째 특징 성분을 나타내며, j의 값은 1, 2, 3입니다.
DMRFAB module
CNN에서 컨볼루션 커널은 특정 영역에 집중하지 않고 전체 이미지를 균일하게 처리합니다. 주의 메커니즘(Attention Mechanisms)은 학습을 통해 이미지의 주요 영역에 집중하고 불필요한 지역 정보를 무시할 수 있습니다. 제안된 DMRFAB 모듈은 SAM과 CAM을 도입한 다중 수용 영역 필드 모듈을 포함하여, 깊은 특징 정보를 더 잘 추출하고 특징 표현 능력을 향상시키며, 최종적으로 이미지 복원 성능을 개선합니다. DMRFAB 모듈은 그림 5에 나와 있으며, 네 개의 MRFAB 유닛과 병목 레이어로 구성됩니다. MRFAB 유닛은 이미지에서 의미론적 특징을 추출하고, 병목 레이어는 특징 수를 줄여 모델의 효율성과 간결성을 향상시킵니다. 밀집 연결(Dense Connection)은 이미지 특징의 전달을 강화하고 특징을 더 효율적으로 사용하도록 합니다. DMRFAB의 수식은 다음과 같습니다:
\[X_{out} = G(H_i[x_0, x_1, ..., x_{i-1}]; \epsilon)\]여기서 \([x_0, x_1, ..., x_{i-1}]\) 는 연속된 0, 1, …, i-1 레이어의 DMRFAB에 의해 생성된 특징 맵을 나타냅니다. \(H_i\) 는 여러 입력 텐서를 단일 텐서로 변환하는 역할을 하고, \(G(\cdot)\) 는 병목 레이어의 출력을 나타냅니다. \(\epsilon\) 는 병목 레이어의 초매개변수(super parameter)이며, 병목 레이어에서 사용되는 필터 크기는 1×1입니다. DMRFAB 모듈에서 사용되는 MRFAB의 구조는 그림 6에 나와 있습니다.
MRFAB 모듈
그림 6에서 보이는 것처럼, 입력 정보는 먼저 1×1 컨볼루션 커널을 사용하는 컨볼루션 블록으로 입력됩니다. 그런 다음 3×3 컨볼루션 커널과 확장 계수 1, 2, 3, 4를 사용하여 네 개의 특징 추출 브랜치로 특징 정보가 나뉩니다. 연결 작업은 그림 6에 보이는 다섯 개의 브랜치의 병렬 특징 맵을 결합합니다(Eq. (12)). 연결 작업을 통해 결합된 특징 정보는 두 모듈로 전달됩니다: CA 모듈(CA(•)), SA 모듈(SA(•)). CA 모듈은 채널 주의 메커니즘을 구현하고, SA 모듈은 공간 주의 메커니즘을 구현합니다. 이 모듈들의 출력은 개별적으로 포인트 곱셈되어 결합된 정보로 변환됩니다. 그런 다음, 입력은 1×1 컨볼루션 커널을 사용하는 컨볼루션 블록으로 처리됩니다(Eq. (13)). 이 단계는 특징 정보를 결합하고 차원을 줄이는 역할을 합니다.
수식 (12)와 (13)에서 R은 서로 다른 브랜치 수용 필드를 연결하는 특징 맵을 나타냅니다; X는 MRFAB의 입력을 나타냅니다; CA(•)는 CA 모듈의 연산을 나타냅니다; SA(•)는 SA 모듈의 연산을 나타냅니다; Cat(•)는 연결 연산을 나타냅니다; M은 MRFAB 모듈의 출력을 나타냅니다.
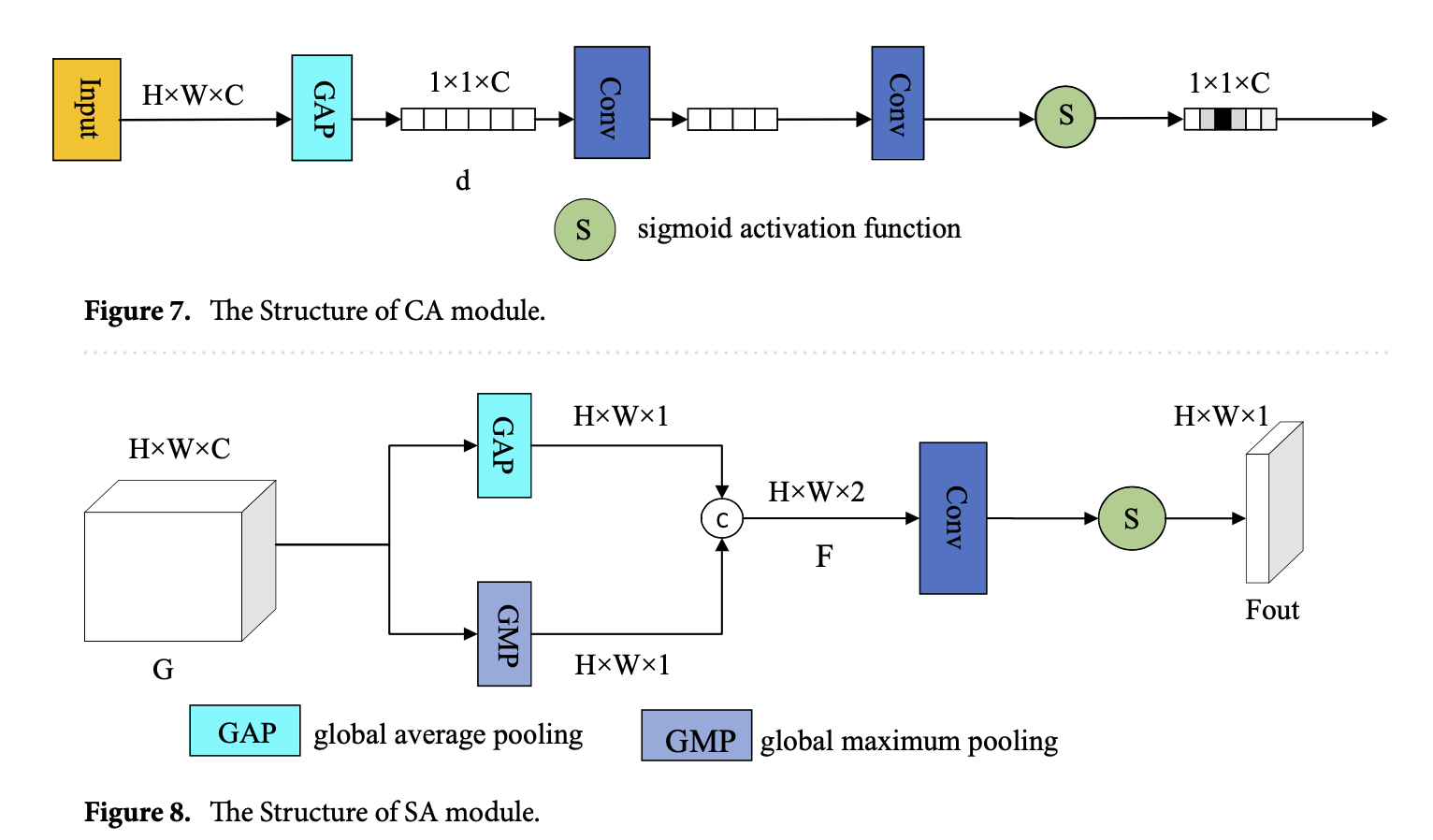
\[R = \text{Cat} \left[ \begin{array}{c} X * W_{1 \times 1} * W_{3 \times 3}^{d=1} \\ X * W_{1 \times 1} * W_{3 \times 3}^{d=2} \\ X * W_{1 \times 1} * W_{3 \times 3}^{d=3} \\ X * W_{1 \times 1} * W_{3 \times 3}^{d=4} \\ X \end{array} \right]\] \[M = Cat[CA(R) * R, SA(R) * R] * W_{1×1}\]CA 모듈은 특징 채널 간의 관계를 압축 및 자극 작업을 통해 매핑합니다. CA 모듈의 구조는 그림 7에 나와 있으며, H×W×C 크기의 입력 특징 맵 G를 사용합니다. 먼저, 글로벌 평균 풀링(GAP)을 수행하여 차원을 압축하고, 1×1×C 크기의 특징 벡터 d를 생성합니다. 그런 다음, 특징 벡터는 두 개의 컨볼루션 레이어를 거쳐 시그모이드 활성화 함수를 통과합니다. CA 모듈은 최종적으로 1×1×C 크기의 특징을 생성합니다.
SA 모듈은 특징 간의 공간적 상관관계를 사용하며, 구조는 그림 8에 나와 있습니다. SA 모듈은 H×W×C 크기의 입력 다차원 특징을 받아들여, 최대 풀링과 평균 풀링을 통해 H×W×1 크기의 특징 맵 F를 생성합니다. 그런 다음, 시그모이드 활성화 함수와 컨볼루션 레이어를 적용하여 H×W×1 크기의 출력 특징 맵 Fout을 생성합니다. SA 모듈의 수학적 표현은 수식 (14)에서 나타냅니다.
\[F_{out} = Sigmoid(Conv(Cat[MAXPool(G), AvgPool(G)]))\]여기서 G는 입력 특징을 나타내며; MAXPool(•)은 글로벌 최대 풀링 작업을 나타내고; AvgPool(•)은 글로벌 평균 풀링 작업을 나타내며; Cat은 연결 작업을 나타내고; Conv(•)는 컨볼루션 작업을 나타내며; Sigmoid(•)는 활성화 함수를 나타냅니다.
Result
데이터셋 및 훈련 세부사항
본 연구에서는 GoPro와 Real Blur 데이터셋을 실험에 사용했습니다. GoPro 데이터셋은 22개의 다른 장면을 포함하는 3214개의 선명한 이미지와 흐린 이미지 쌍으로 구성되어 있습니다. 총 2103개의 이미지 쌍이 훈련 데이터셋으로 사용되었으며, 1111개의 이미지 쌍이 테스트 데이터셋으로 사용되었습니다. Real Blur 데이터셋은 실제 세계에서 동일한 이미지 내용을 가진 흐린 이미지와 선명한 이미지의 대규모 데이터셋으로, 두 개의 하위셋으로 구성됩니다. 첫 번째 하위셋은 카메라에서 직접 얻은 원본 처리되지 않은 이미지를 포함하고, 두 번째 하위셋은 카메라의 이미지 프로세서에 의해 처리된 후 생성된 이미지를 포함합니다. 232개의 저조도 조건 시나리오가 있으며, 여기에는 야간 및 실내 약한 조명 조건이 포함됩니다. 이 시나리오는 일반적인 실제 세계의 장면을 포괄합니다. 이 데이터셋은 다양한 장면에서 캡처된 총 4738개의 이미지 쌍을 포함합니다. Real Blur 데이터셋은 실제 세계 설정에서 딥러닝 모델 기반 이미지 복원 기술을 평가하기 위한 귀중한 연구 데이터를 제공합니다. 실험을 위해 이 데이터셋에서 3758개의 이미지 쌍이 제안된 모델을 훈련하는 데 할당되었으며, 나머지 980개의 쌍은 테스트 및 평가를 위해 예약되었습니다.
모델의 일반화 능력을 강화하기 위해, GoPro와 Real Blur 훈련 데이터셋에 데이터 증강 작업이 수행되었습니다. 이 작업에는 랜덤 회전 및 가우시안 노이즈 추가가 포함되었습니다. 구체적으로, 데이터 증강에는 수평(좌우) 및 수직(상하) 방향으로의 랜덤 플립과 90도, 180도, 270도의 각도로의 회전이 포함되었습니다. 평균 값이 0이고 분산이 0.0001인 가우시안 노이즈도 도입되었습니다. 그 결과, GoPro 훈련 데이터셋은 210
3개의 이미지 쌍에서 8412개의 이미지 쌍으로 확장되었고, Real Blur 훈련 데이터셋은 3785개의 이미지 쌍에서 15,032개의 이미지 쌍으로 확장되었습니다. 이러한 증강 기술을 통해 이미지 쌍의 수가 증가했습니다.
모델의 과적합을 방지하기 위해, 훈련 데이터셋의 이미지는 무작위로 256×256 픽셀 크기로 잘렸습니다. 훈련 기간은 3000 라운드로 설정되었고, 초기 학습률은 1e-4로 설정되었습니다. 매 1000 라운드마다 학습률이 절반으로 감소했습니다. 배치 크기는 10으로 설정되었습니다. 채택된 네트워크 최적화 방법은 Adam으로, β₁ = 0.9 및 β₂ = 0.999 매개변수를 사용했습니다. 실험적 훈련을 가속화하기 위해 GPU를 사용하여 모델을 훈련했으며, 이는 계산 집약적인 이미지 처리 작업에 적합합니다. 본 연구에서 실험 환경과 구성에 대한 자세한 내용은 표 1에 나와 있습니다.