
[논문분석] Elucidating the Design Space of Diffusion-Based Generative Models
diffusion model에 대한 Practical한 고찰 [Project, Paper]
2022 NeurIPS
Abstract
We argue that the theory and practice of diffusion-based generative models are currently unnecessarily convoluted and seek to remedy the situation by presenting a design space that clearly separates the concrete design choices. This lets us identify several changes to both the sampling and training processes, as well as preconditioning of the score networks. Together, our improvements yield new state-of-the-art FID of 1.79 for CIFAR-10 in a class-conditional setting and 1.97 in an unconditional setting, with much faster sampling (35 network evaluations per image) than prior designs. To further demonstrate their modular nature, we show that our design changes dramatically improve both the efficiency and quality ob- tainable with pre-trained score networks from previous work, including improving the FID of a previously trained ImageNet-64 model from 2.07 to near-SOTA 1.55, and after re-training with our proposed improvements to a new SOTA of 1.36.
Introduction
dense on theory, and derivations of sampling schedule, training dynamics, noise level parameterization, etc. 에 집중되어있음
available design space를 파악하기 어려움
전체 system을 건들이지 않고 개별적인 compnent를 쉽게 수정하기 힘듬
본 논문에서는 Practical standpoint에서 diffusion model에 다양한설계 관점을 분석
-
Taining, sampling 단계에서 나타나는 tanglible object와 algorithm에 집중하여 분석
component들이 어떻게 연결되어 있는지, 전체 시스템에 대한 영향을 분석
denoising score matching 의 관점에서
-
Sampling process 분석
가장 성능이 좋은 discretization 방법, high-order Runge-Kutta method, 다양한 sampler schedule, sampling process에서의 stochasticity의 유용성을 평가
→ sampling step 수 감소
-
Score-modeling neural network의 training 관점에서 여러 설정들을 분석
DDPM, NCSN을 기반으로 pre-conditioning, diffusion model의 loss function 등을 평가
training dynamics를 개선할 수 있는 방법을 탐색
Related Work
기존 방법들 설명
SDE (Stochastic Differential Equation)를 통해 데이터 분포가 여러 시간 단계에서 노이즈를 추가하면서 분포가 점진적으로 가우시안 분포로 수렴 → 그 랜덤한 경로(trajectory)를 학습
ODE (Ordinary Differential Equation)를 통해 노이즈 분포에서 데이터 분포로 돌아가는 결정론적 경로 (Deterministic Trajectory)를 계산하는 방법으로 초기값이 정해지면 학습된 경로(trajectory)를 따라 계산
SDE는 학습, ODE는 sampling에 주로 사용
Expressing diffusion models in a common framework
data distribution : \(p_{data}(x)\)
noise (independent data) : \(p(x,\sigma)\)
diffusion model은 랜덤한 가우시안 노이즈에서 조금씩 denoise를 하며 sequential 하게 진행
각 discrete한 sampling step에 일정 noise가 data distribution에 더해지는 형태 → noise가 중첩됨
SDE : continous time 시간에 따라 변하는 확률 process, 각 단계에서 noise를 추가 제거 (stochastic solver) 노이즈가 포함된 미방
PF-ODE : 확률의 flow 초기 noise sampling (\(x_0\))만 ramdom 이후 과정은 deterministic
PF-ODE
noise를 time step에 따라 sampling → \(\sigma(t) ∝ \sqrt{t}\) : constant-speed heat diffusion
하지만 scheduling(노이즈 step을 정하는 일) 작업에서 이론적 편의성이 아닌 실질적 성능에 큰 영향을 미침
정의식
\[\frac{dx}{dt} = -\dot{\sigma}(t) \sigma(t) \nabla_x \log p(x; \sigma(t)),\]\(\nabla_x \log p(x; \sigma(t))\) : score function ,데이터 분포에서 밀도가 높은 영역으로 방향을 설정
\(\dot{σ}\) : time derivative
데이터 분포에 영향을 받음
foward는 데이터 분포에서 멀어지는 방향, backward는 데이터 분포에서 가까워지는 방향
Denoising score matching
데이터에서 노이즈를 분리하고 score function을 계산
\(\nabla_x \log p(x; \sigma(t))\) → 데이터 분포에서 노이즈가 추가된 샘플 x의 density 경사
정규화 상수(normalization constant)에 의존하지 않음 → 복잡한 정규화 상수 없어 계산 쉬움

denoiser function : D(x;σ)는 입력 x에서 노이즈를 제거하는 함수
\[\mathbb{E}_{y \sim p_{\text{data}}} \mathbb{E}_{n \sim \mathcal{N}(0, \sigma^2 I)} \| D(y + n; \sigma) - y \|^2\]L2 loss 를 minimize 하는 방향으로 학습
\[\nabla_x \log p(x; \sigma) = \frac{D(x; \sigma) - x}{\sigma^2}\]score function 과 denoiser 관계 → noise를 제거하는 방향
diffusion model 은 신경망 \(D_θ(x;σ)\)를 구현
Time-dependent signal scaling
Additional scale schedule \(s(t)\) 를 도입,
\(x=s(t)\hat{x}\)를 기존의 non-scaled variable \(\hat{x}\) 의 scaled version
time에 따른 probability density가 변경되고 결과적으로 ODE solution trajectory도 변화
\[\frac{dx}{dt} = \left[ \frac{\dot{s}(t)}{s(t)} x - s(t)^2 \dot{\sigma}(t) \sigma(t) \nabla_x \log p\left(\frac{x}{s(t)}; \sigma(t)\right) \right].\]시간 t에 따라 데이터 x를 스케일링하여 새로운 변수 \(\hat{x}\) 와 관계를 정의
\(\dot{s}(t)\) : s(t)의 시간에 대한 변화율(미분).
스코어 함수 \(∇_xlogp(x;σ)\) 를 계산할 때, 스케일링 s(t)의 영향을 제거
Solution by Discretization
위 식을 통해 미분 값(경사)를 계산하고 이를 적분으로 해결(numerical integration)
유한한 time step에서 진행(sampling)
Euler 방법 또는 Runge-Kutta 변형과 같은 방식이 사용
SDE 또는 ODE를 푸는 데 사용되는 수치적 방법 중 대표적인 것이 Euler 방법과 Runge-Kutta 방법
Euler 방법 (Euler-Maruyama 방법)
\[dx=f(x,t)dt+g(x,t)dW\]- f(x,t): 결정론적 드리프트(Drift) 항
- g(x,t): 확률적 확산(Diffusion) 항
- dW: 위너 프로세스 (Wiener Process)에서 온 무작위 항
- 장점: 구현이 간단하고 계산 비용이 낮음
- 단점: 큰 시간 스텝에서는 근사 오차가 커질 수 있음
Runge-Kutta 방법 (RK4, DPM-Solver 등)
\[x_{t+Δt}=x_t+Δt/6(k_1+2k_2+2k_3+k4)\]4차 근사 식
- 장점: 더 높은 정확도를 보장하며 시간 스텝을 크게 설정할 수 있음
- 단점: 계산 비용이 Euler 방법보다 높음

최종적으로 논문에서는 3가지의 기존 diffusion model들에 대해, deterministic variant를 위한 formula를 제시 이러한 reframing의 목적은 기존 방법들에서 서로 복잡하게 얽혀있는 independent component를 찾아내는 것에 있음
결과적으로 논문에서 제시하는 EDM framework에는 각 component 간의 implicit dependency가 존재하지 않음
하나의 component를 변경할 때 모델의 수렴성을 위해 다른 component를 수정할 필요가 없음 실제로, 각 component에 대한 적절한 조합은 기존 방법들보다 더 잘 동작 가능함
Method
- DDPM++ const (VP) :DDPM을 기반으로 variance preserving (VP)를 적용
- NCSN++ const (VE) : SMLD를 기반으로 variance exploding (VE)를 적용
- DDIM : imporved DDPM을 활용하는 ADM (dropout) 모델
Improvements to deterministic sampling
Output quality의 향상과 sampling의 computational cost를 줄이는 것은 diffusion model에 대한 주요 개선 방향
여기서 논문은 sampling process와 관련된 choice들이 component들과 independent 하다고 가정
예시 network arhcitecture, training detail → 네트워크 학습 \(D_\theta\) 는 sampling 과정에서 사용하는 time dependent variance \(\sigma(t), s(t), \{ t_i \}\) 와 독립 (dictate 해서는 안됨) → 별개로 설계
네트워크 학습은 샘플링 스케줄 또는 알고리즘에 영향을 주지 않아야함. 반대도 동일
네트워크 \(D_θ\) 는 단순히 데이터를 변환하는 함수 역할
Sampler 측면에서 \(D_\theta\) 는 black box이기 때문 → \(D_θ\)
는 학습이 완료된 후 샘플러가 사용하는 도구일 뿐이며, 내부 작동 방식은 샘플러 설계에 영향을 미치지 않음 (주어진 입력에 대해 출력값을 생성하는 함수)
이로써 다양한 sampler를 독립적으로 최적화 하거나 개선 가능
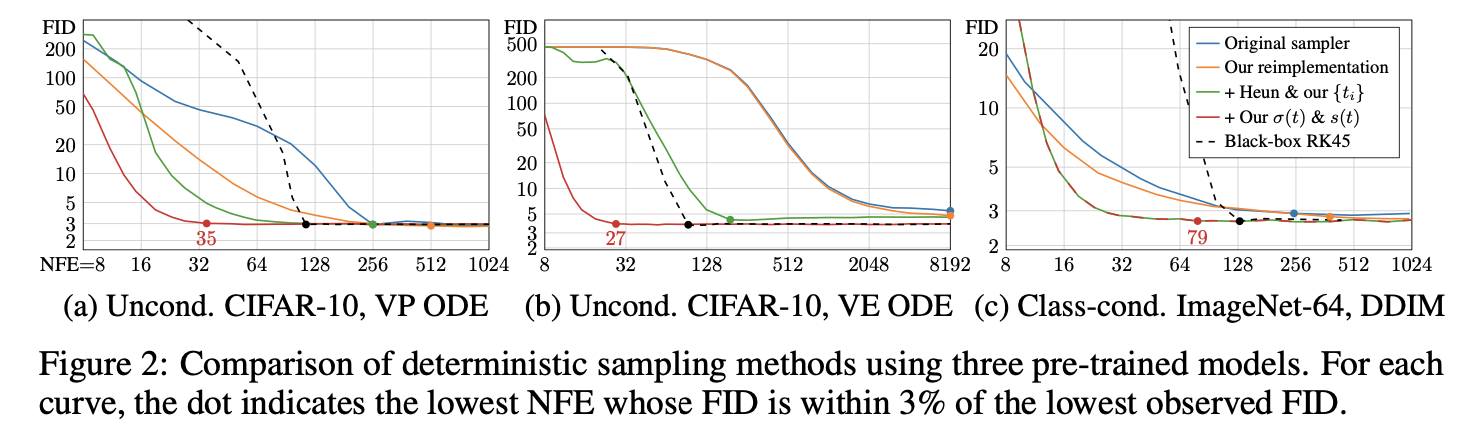
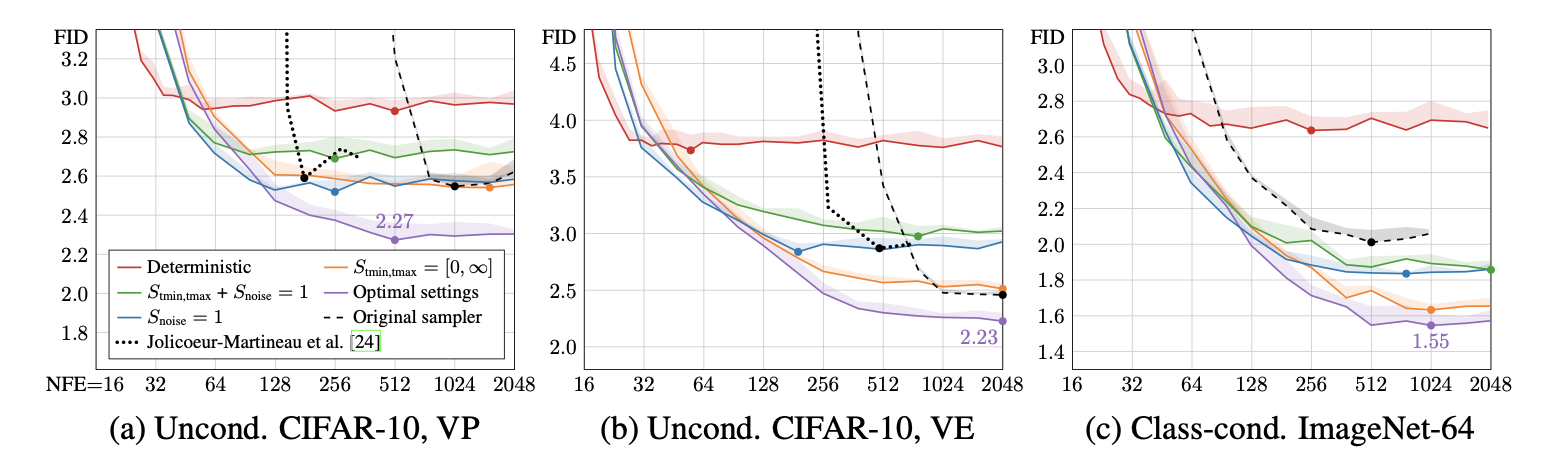
- 원본 샘플러(파란색):
- 기존의 결정적(deterministic) 샘플러로 모델 평가.
- FID는 괜찮지만, 일부 구현의 한계로 인해 최적화되지 않은 결과가 존재.
- 통합 프레임워크(주황색):
- 논문에서 제안한 통합 프레임워크로 재구현.
- 원본 샘플러 대비 일관적으로 더 나은 FID 결과를 보여줌.
- 이는 특히 DDIM에서 노이즈 레벨 처리 방식이 더 신중해졌기 때문.
Fréchet Inception Distance (FID) : 생성 된 이미지들과 실제 이미지 분포를 비교, 유사도
Neural Function Evaluations (NFE) : 단일 이미지 생성에서 denoiser를 평가

Discretization and higher-order integrators
ODE를 numerically solve 하는 것은 true solution trajectory를 따르는 approximation과 같음
미방을 계산하는 것은 continous한 Trajectory에 특정 포인트에서의 접선 방향을 구하는 것과 동일 따라서 실제 Trajectory와 오차가 발생할 수 있음 (논문에서는 곡률이 심할 수록 오차가 커진다고 생각 → Trajectory의 선형성 중요)
수치적으로 ODE를 해결하는 과정은 정확한 해를 따르는 대신, 해의 근사치를 계산
so, N개의 단계(step)를 통해 해를 계산할 때, 각 단계에서 Truncation Error 발생 누적
step size h가 작아질수록 오차가 줄어들지만, 계산 비용이 증가 → first order ODE solver \(O(h^2)\)
N을 증가시키면 정확도가 향상
- Euler의 방법:
- 1차 ODE 솔버로, 단계 크기 h에 대해 지역 오차가 O(h2)로 감소
- 계산이 간단하지만 정확도가 상대적으로 낮음
- Runge-Kutta 방법:
- 고차 ODE 솔버로, 더 낮은 오차를 제공
- 그러나 한 단계마다 Dθ를 여러 번 평가해야 하므로 계산 비용이 증가
- Heun의 2차 방법:
- 향상된 Euler 방법(trapezoidal rule), 2차 솔버에 해당
- 지역 오차가 O(h3)로 감소하며, Dθ를 한 단계에서 두 번 평가합니다.
- 장점: 절단 오차와 NFE 사이에서 뛰어난 균형을 제공합니다.
Correction Step
\(x_{i+1}\)를 계산할 때, \(t_i\)와 \(t_{i+1}\) 사이의 \(dt/dx\) 변화량을 고려해 보정
σ=0에 가까워지면 σ가 분모에 등장하기 때문에 0으로 나눌 위험 → 이 경우 Euler 방법 사용
T와 noise
\[t_i=σ^{−1}(σ_i)\] \[\sigma_i = \sigma_{\text{max}}^\rho \left(1 + \frac{i}{N-1} (\sigma_{\text{min}}^\rho - \sigma_{\text{max}}^\rho)\right)^{1/\rho}.\]- ρ: 작은 노이즈 수준 σmin 근처에서 단계 크기를 조정하는 매개변수.
- A,B: σmax와 σmin에 맞춰 조정되는 상수.
ρ의 효과:
- ρ=3는 모든 단계에서 절단 오차를 거의 동일하게 만듬
- 그러나, ρ 값이 클수록(5∼10) 샘플링 성능이 향상
- 논문에서는 ρ=7을 사용
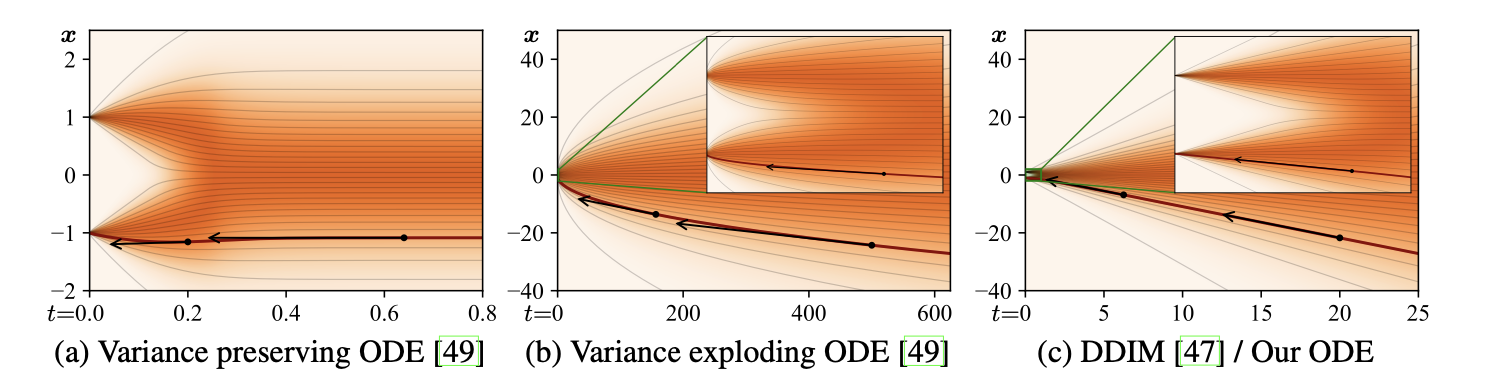
Trajectory curvature and noise schedule
두 부분의 선택이 model의 sampling 정확도에 미치는 영향 설명
\(dx/dt\) 의 Curvature (곡률) 은 Truncation Error의 영향을 줌 → 클수록 더 많은 오차 → 곡률 줄이기
σ(t)와 s(t) 함수는 ODE의 해 궤적(Trajectory)의 곡률을 정의
σ(t)=t와 s(t)=1로 설정
s(t)는 시간에 따라 변하는 함수로, x의 크기를 조정 → 스케일링 효과 제거
\[\frac{dx}{dt} = \frac{x - D(x; t)}{t}.\]시간 t와 노이즈 수준 σ가 동일하게 작동 → 샘플링 경로를 더 쉽게 이해하고 구현
Sampling Trajectory의 linearlty : 노이즈 수준이 크거나 작을 때는 경로가 거의 선형이고, 곡률이 크게 발생하는 영역은 중간 노이즈 수준 (좁은σ범위)에 집중
Stochastic sampling
Langevin Diffusion SDE
Langevin Diffusion SDE는 결정론적 경로와 확률적 노이즈가 결합된 형태
| Deterministic Sampling | Langevin Diffusion SDE |
|---|---|
| ODE를 사용하여 이미지를 샘플링 | 각 샘플링 단계에서 새로운 노이즈를 주입하여 데이터를 업데이트 |
| 이전 단계에서 계산된 x를 기반으로 후속 단계 \(x_{i+1}\) 를 계산하며, 추가적인 노이즈 주입 없이 진행 | Langevin Diffusion의 확률적 요소를 활용해 샘플을 점진적으로 데이터 분포로 이동 |
| ODE를 역으로 계산 가능 → 변환 복원의 용이 | 새로운 노이즈를 주입하여 이전 단계에서 발생한 오류를 보정 |
| 계산이 간단하고 모델 구조와 독립적으로 작동 | 퀄리티가 높음 |
| 퀄리티가 떨어짐 | 노이즈 주입과 계산이 추가되므로 계산 비용이 증가 |
두가지 결합
각 샘플링 단계 \(x_i\)에서:
- 기존의 ODE 계산 방식에 따라 xi+1 계산.
- 노이즈 주입 및 보정을 통해 추가적으로 샘플 업데이트.
Euler–Maruyama 방법과의 차이
- Euler–Maruyama:
- 노이즈를 먼저 추가한 후, ODE 단계를 수행.
- 그러나 노이즈 주입 후 상태를 고려하지 않고 초기 상태를 기반으로 계산.
- 제안된 방법:
- 노이즈 주입 후 업데이트된 상태를 고려하여 ODE 단계를 수행.
- 이는 큰 단계(큰 Δt)에서 샘플링 효율성과 정확도를 높이는 데 유리.
기존 SDE는 노이즈 주입 속도 β(t)의 선택이 고정적
수식
foward, backward 식 동시에 씀
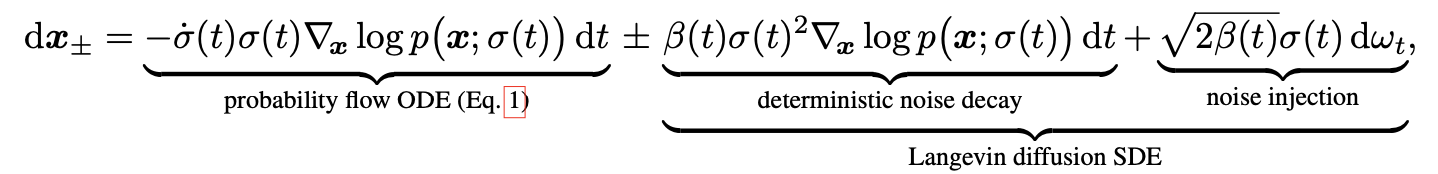
Langevin term은 deterministic score-based denoising term과 stochastic noise injection term의 합으로 구성
SDE에서는 β(t)=˙σ(t)/σ(t)를 사용하여 forward process에서 score를 vanish → β(t) 상대적인 노이즈 비율(Relative Rate of Noise Replacement)
이론적으로 최적의 β(t)는 수식적으로 정의되기 어려우며, 경험적으로(empirically) 결정
- Probability Flow ODE Term
deterministic score-based denoising - Langevin Diffusion
역전파 과정(Reverse Process)에서 결정론적 경로를 정의
\[-\dot{\sigma}(t)\sigma(t)\nabla_x \log p(x; \sigma(t)) \, dt\]- Deterministic Noise Decay Term:
노이즈 감소율에 따라 데이터 분포를 결정론적으로 조정
\[\beta(t)\sigma(t)^2 \nabla_x \log p(x; \sigma(t)) \, dt\]stochastic noise injection - Langevin Diffusion 확률 항:
랜덤 노이즈를 추가
\(ω_t\) : 위너 프로세스(Wiener Process)에서 샘플링된 노이즈
\[\sqrt{2\beta(t)}\sigma(t) \, d\omega_t\]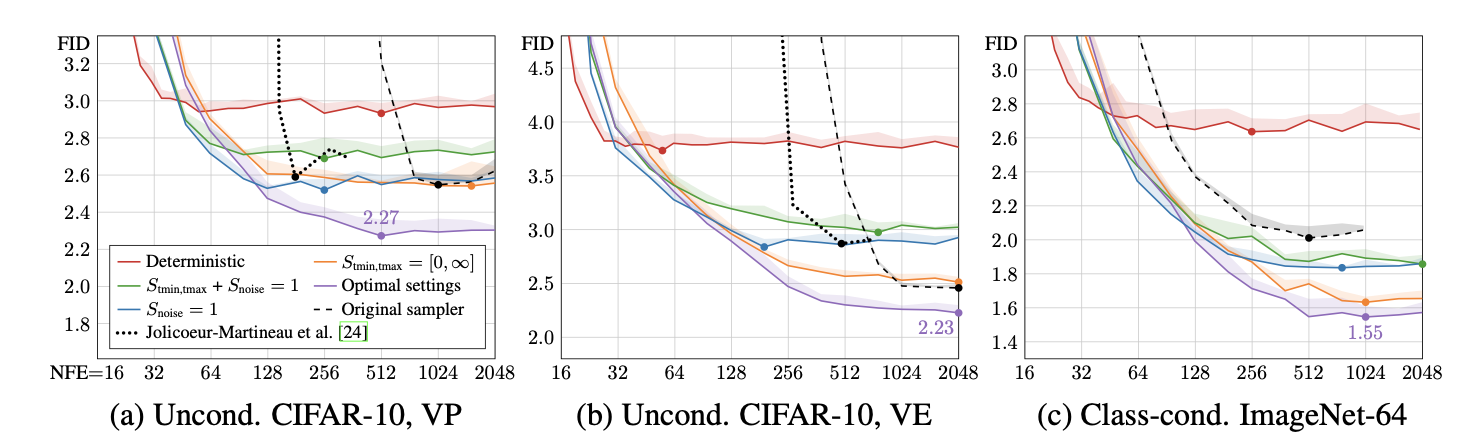
Our stochastic sampler
Langevin SDE의 구조를 따르지만, ODE Solver와 Noise Injection을 명확히 분리하여 더 효율적
Stochastic Sampler는 스케줄링된 시간 단계에 따라 Noise Injection과 ODE Solver를 결합해 효율적으로 샘플링을 수행
EDM은 2nd order deterministic ODE integrator와 noise 추가/제거에 대한 explicit Langevin-like churn을 결합한 stochastic sampler를 제안
낮은 NFE (Number of Function Evaluations)로 높은 품질의 샘플링 달성
Step 1: Noise Injection (“Churn”)
현재 샘플 \(x_i\)와 노이즈 수준 \(t_i=σ(t_i)\)에서 시작
노이즈를 추가하여 더 높은 노이즈 수준 \(\hat{t}=t+γt\)으로 이동
- \(γ_i≥0\): 노이즈 스케일링 계수
- 이 단계는 Langevin-like Noise Injection을 수행합니다.
Step 2: ODE Backward Integration
초기 상태 x,t를 기반으로 ODE 계산하는 기존 방법과 다르게 노이즈를 추가한 후 새로운 상태 \(\hat{x},\hat{t}\) 에서 ODE 계산
Noise Injection이 완료된 샘플 \(\hat{x}\) 에서 시작
ODE Solver 를 사용하여 노이즈 수준을 \(\hat{t}\) 에서 \(t_{i+1}\)로 감소시키며 새로운 샘플 \(x_{i+1}\)을 생성
\[x_{i+1}=ODE\_Solve(\hat{x},\hat{t},t_{i+1})\]Step Size (∆t)가 클 경우 제안된 Stochastic Sampler가 더 정확하고 안정적인 결과를 보장.
| Langevin Diffusion SDE | Stochastic Sampler | |
|---|---|---|
| 목적 | SDE Solver로 확률적 경로 따르기 | ODE Solver + Noise Injection 단계적으로 사용 |
| Noise Injection | 연속적 (\(\sqrt{2β(t)σ(t)}dω_t\)) | 명확하게 분리된 단계로 노이즈 추가 (\(\hat{t}=t+γt\)) |
| ODE Integration | 확률적 요소가 섞여있음 | Noise Injection 이후 상태에서 명확하게 ODE Solver 수행 |
| 정확성 | 작은 스텝일 때 정확 | 큰 스텝에서도 정확성 유지 가능 |
| 계산 비용 | 스텝 수가 많을수록 비용 증가 | 효율적 (Noise Injection과 ODE Solver의 명확한 분리) |
| 랜덤성 | 연속적으로 노이즈가 추가됨 | 명확하게 정의된 Noise Injection 단계에서만 노이즈 추가 |
| step 이동과 동시에 노이즈가 추가 → 불확실성 증가 | step 이동과 노이즈 단계를 나눠서 설정 |

Practical considerations
Stochasticity (Noise Injection)는 초기 샘플링 단계에서 발생한 오류를 수정하는 데 효과적
하지만, 과도한 노이즈 주입과 제거는 다음과 같은 문제를 유발
- 세부 정보 손실 (Loss of Detail): 이미지의 미세한 디테일이 점차 사라짐.
- 색상 포화 (Oversaturation): 매우 낮거나 높은 노이즈 수준에서 색상이 과포화됨.
이유: Denoiser 네트워크 (\(D_θ(x;σ)\))가 미분 방정식의 conservative vector field 조건을 완벽하게 따르지 않을 수 있음. 이로 인해 Langevin Diffusion의 이론적 가정이 위반되어 문제가 발생
Denoiser 네트워크 (\(D_θ(x;σ)\))는 이상적인 Score Function에 최대한 근사해야 함
하지만 노이즈가 과도하게 되면 다음과 같은 문제 발생
- 경로 의존성(Path Dependency)
- 같은 시작점과 끝점을 가지더라도 이동 경로에 따라 다른 결과가 발생할 수 있습니다.
- 비정확한 Score Function 근사
- Denoiser가 Score Function을 잘못 학습하거나, 데이터 분포를 완벽하게 반영하지 못함.
- Drift (편향)
- 데이터가 예상된 확률 분포를 벗어나 이동할 수 있습니다.
- 예: 색상이 과포화(Oversaturation)되거나, 세부 정보가 손실됨.
- 에너지 비보존 (Energy Non-Conservation)
- 확률 흐름이 보존되지 않아 데이터가 잘못된 에너지 상태로 이동할 수 있습니다.
해결책
- Stochasticity의 범위 제한
- Stochasticity 양 조정 (\(γ_i\))
- Noise Scaling Factor 정의
- Schurn: 전체적인 stochasticity 양을 조정하는 파라미터.
- N: 총 샘플링 스텝 수.
- Noise Clamping:
- 새로 추가되는 노이즈가 기존 이미지에 이미 존재하는 노이즈 양보다 더 많아지지 않도록 제한합니다.
- Noise Scale Slightly Above 1
- 새로 추가되는 노이즈의 표준편차를 살짝 늘려서 세부 정보 손실을 보정
Denoiser가 과도하게 노이즈를 제거하는 경향을 완화
대부분의 Denoiser는 L2 손실 함수로 훈련되기 때문에 평균 회귀 (Regression Toward the Mean)가 발생 → Denoiser가 노이즈를 너무 많이 제거
L2 Loss의 경우 모델이 예측할 때 평균적인 결과로 수렴하려는 경향이 있고, 평균적으로 가장 작은 오차가 발생하는 방향으로 수렴
이미지의 고주파 성분(세부 정보, 날카로운 경계선)은 L2 손실에서 큰 오차로 해석 ( 제곱이기에 이상치(outlier)에 매우 민감)
이는 세부 정보를 유지하기보다는 데이터를 부드럽게(smooth) 만들어버림.
(L2 손실은 평균적으로 노이즈를 제거하지만, 데이터의 고주파 성분(세부 정보)을 과도하게 손상)
- L1 손실 (MAE, Mean Absolute Error)는 중앙값(Median)을 예측
Evaluation
Preconditioning and training
입력/출력 스케일링(preconditioning), 손실 함수 설계, 노이즈 레벨 선택, 데이터 증강 등을 통해 모델의 성능을 크게 개선하는 방법을 제안
Preconditioning: Neural Network의 입력과 출력 스케일 조정
Diffusion 모델의 입력 x=y+n (신호 y와 노이즈 \(n∼\mathcal{N}(0,σ^2I)\)의 합)
노이즈 레벨 σ 가 크면, 입력 x의 크기가 매우 커지며 출력 \(D_θ(x;σ)\) 계산 시 오차가 증폭
- 기존 방법은 Dθ를 직접 신경망으로 설계하지 않고, 대신 새로운 네트워크 Fθ를 훈련하여 간접적으로 Dθ를 계산합니다:\(D_θ(x;σ)=x−σF_θ(⋅)\)
한계
- 노이즈가 큰 경우(σ가 클 때), Fθ는 노이즈 n을 정확히 제거해야 하므로 미세한 조정이 필요
- 네트워크 오차가 σ에 비례해 증폭되므로, 큰 노이즈 수준에서 정확한 계산이 어려움
so, 스킵 연결 \(c_{skip}(σ)\) 및 스케일링 함수 사용
\[D_\theta(x; \sigma) = c_\text{skip}(\sigma)x + c_\text{out}(\sigma) F_\theta\big(c_\text{in}(\sigma)x; c_\text{noise}(\sigma)\big),\] \[\mathbb{E}_{\sigma, y, n} \left[\lambda(\sigma) \|D(y + n; \sigma) - y\|^2 \right],\] \[\mathbb{E}_{\sigma, y, n} \lambda(\sigma)c_\text{out}(\sigma)^2 \left\| F_\theta\big(c_\text{in}(\sigma)(y+n); c_\text{noise}(\sigma)\big) - \frac{c_\text{out}(\sigma) y - c_\text{skip}(\sigma)(y+n)}{c_\text{out}(\sigma)} \right\|^2,\]noise sampling 분포
- 낮은 σ: 노이즈가 너무 작아 학습이 어렵고 의미 없음.
- 높은 σ: 출력이 평균 데이터셋 값에 가까워져 학습이 덜 중요.
so, 중간 노이즈 수준에서 학습을 집중할 수 있도록, 로그 정규 분포로 샘플링
\[p_\text{train}(\sigma) \propto \exp\left(-\frac{(\log \sigma - \mu)^2}{2 \tau^2}\right),\]loss 가중치
\[\lambda(\sigma) = \frac{1}{c_\text{out}(\sigma)^2}.\]


