
[논문분석] Adding Conditional Control to Text-to-Image Diffusion Models
conditioning을 제어할 수 있는 Finetuning 방법 ControlNet을 제안
[Paper, Code]
Lvmin Zhang, Anyi Rao, Maneesh Agrawala
1. Abstract
We present ControlNet, a neural network architecture to add spatial conditioning controls to large, pretrained text- to-image diffusion models. ControlNet locks the production- ready large diffusion models, and reuses their deep and ro- bust encoding layers pretrained with billions of images as a strong backbone to learn a diverse set of conditional controls. The neural architecture is connected with “zero convolutions” (zero-initialized convolution layers) that progressively grow the parameters from zero and ensure that no harmful noise could affect the finetuning. We test various conditioning con- trols, e.g., edges, depth, segmentation, human pose, etc., with Stable Diffusion, using single or multiple conditions, with or without prompts. We show that the training of Control- Nets is robust with small (<50k) and large (>1m) datasets. Extensive results show that ControlNet may facilitate wider applications to control image diffusion models.
conditioning을 제어할 수 있는 ControlNet을 제안
이 논문 선택 이유
이전 streamT2V 에서 언급된 내용에 controlnet이 존재
“we propose the Conditional Attention Module (CAM), which consists of a feature extractor, and a feature injector into Video-LDM UNet, inspired by ControlNet[46].”
“Finally, we use a linear projection Pout. Using a suitable reshaping operation R, the output of CAM is added to the skip connection (as in ControlNet [46]):”
\[x'''_{SC} = x_{CS}+R(P_{out}(x''_{CS}))\]2. Introduction
그러나 텍스트-이미지 모델은 이미지의 공간 구성을 제어하는 데 한계가 있으며 텍스트 프롬프트만으로는 복잡한 레이아웃, 포즈, 모양 및 형태를 정확하게 표현하기 어려울 수 있습니다.
우리가 원하는 이미지 생성하기 힘듬
additional image를 활용 (e.g., edge maps, human pose skeletons, segmentation maps, depth, normals, etc.)
-
spatial masks [6, 20], image editing instructions [10], personalization via finetuning [21, 75], etc.
“노이즈 제거 확산 프로세스를 제한하거나 주의 계층 활성화를 편집하는 등의 ‘훈련이 필요 없는 기술”은 신경망을 처음부터 훈련하거나 광범위하게 미세 조정하는 길고 계산 비용이 많이 드는 과정을 피할 수 있으므로 이미지 생성 및 수정 작업에서 잠재적인 해결책을 제시
즉시 적용: 훈련이 필요 없는 기술은 추가 훈련 없이 사전 훈련된 모델에 바로 적용할 수 있습니다. 따라서 시간이나 리소스 제약으로 인해 모델을 재학습하는 것이 비현실적인 경우 빠른 수정이나 적용에 특히 유용합니다. 리소스 효율성: 이러한 방법은 재학습이 필요 없기 때문에 계산 리소스와 에너지를 절약할 수 있으며, 특히 이미지 데이터와 관련된 대규모 신경망 훈련과 관련된 높은 비용을 고려할 때 매우 중요합니다. 과적합 및 망각 방지: 특정 작업이나 데이터 세트에 대해 모델을 학습시키거나 미세 조정하면 새로운 데이터에 과적합하거나 이전에 학습한 정보를 잊어버리는 경우가 발생할 수 있습니다. 훈련이 필요 없는 방법은 학습된 가중치를 변경하지 않고 모델의 기존 기능을 조작하여 일반화 가능성을 유지하고 이전에 학습된 작업의 성능 저하를 방지합니다. 유연성과 창의성: 주의 레이어 활성화 편집과 같은 기술을 사용하면 입력 조건이나 원하는 결과의 미묘한 변화를 반영하여 출력 이미지를 창의적이고 매우 구체적으로 수정할 수 있습니다. 이는 일반적으로 중요한 변화를 유도하기 위해 대량의 레이블이 지정된 데이터가 필요한 네트워크 재훈련보다 더 유연할 수 있습니다. 신속한 프로토타이핑 및 실험: 연구자와 개발자는 다양한 설정과 수정 사항을 빠르게 실험하여 그 효과를 실시간으로 확인할 수 있으므로 여러 번의 반복과 실험이 일반적인 연구 및 개발 단계에 유리합니다.
다음 해결책 들이 있지만, 깊이 대 이미지, 포즈 대 이미지 등과 같은 더 다양한 문제에는 엔드투엔드 학습과 데이터 기반 솔루션이 필요
-
엔드투엔드 학습 and 데이터 기반 학습
엔드투엔드 학습은 최소한의 전처리 또는 사람이 만든 규칙을 사용하여 단일 모델이 원시 입력 데이터부터 최종 출력까지 특정 작업을 수행하도록 훈련하는 훈련 방법론을 말합니다. 이 접근 방식은 여러 단계 또는 모델이 순차적으로 데이터를 처리하는 기존 방식과 대조적입니다.
- 포괄적 학습: 엔드투엔드 학습은 하나의 작업을 별도의 구성 요소가 처리하는 작은 하위 작업으로 나누는 대신, 전체 프로세스에 대해 한 번에 모델을 학습시키는 것을 목표로 합니다.
- 직접 매핑: 엔드투엔드 학습에서 모델은 이미지, 텍스트, 오디오 등의 원시 입력에서 분류, 번역, 합성 이미지 등의 원하는 출력으로 직접 매핑을 학습하여 다단계 처리에서 놓칠 수 있는 복잡한 패턴을 포착합니다.
데이터 기반 솔루션은 주로 사용 가능한 데이터를 기반으로 모델을 개발하는 접근 방식을 말하며, 사전 정의된 알고리즘이나 사람의 개입보다는 데이터에 크게 의존하여 의사 결정 및 학습 프로세스를 안내합니다.
- 경험적 접근 방식: 이러한 솔루션은 처음부터 작업하고자 하는 데이터를 중심으로 구축됩니다. 처리하는 데이터에 따라 적응하고 진화하기 때문에 특정 애플리케이션에 맞게 고도로 최적화된 맞춤형 시스템을 구축할 수 있습니다.
- 유연성: 데이터 기반 모델은 입력 패턴이나 분포의 변화에 동적으로 적응할 수 있으므로 다양한 데이터 세트에서 학습된 경우 다양한 시나리오에 걸쳐 강력하게 작동합니다.
요약하면, 엔드투엔드 학습 및 데이터 기반 솔루션은 대량의 데이터에서 직접 학습하여 작업을 자동화하고 최적화하는 포괄적인 방법을 제공하며, 추가 학습 주기 없이 사전 학습된 모델을 조정하는 학습 없는 기법과는 뚜렷한 대조를 이룹니다.
특별 condition을 위한 데이터 셋은 작음 → 이로인해 large pretrained model을 제한된 데이터로 학습 혹은 finetuning 할 경우 overfiting 또는 catastrophic forgeting이 발생할 수 있음 → 학습 파라미터의 수나 순위를 제한함으로써 이러한 망각을 완화할 수 있음
이 문제의 경우, 복잡한 모양과 다양한 고차원적 의미를 가진 야생 상태의 이미지를 처리하기 위해서는 더 심층적이거나 맞춤화된 신경 아키텍처를 설계해야 할 수도 있다.
ControlNet preserves the quality and capabilities of the large model by locking its parameters and making a trainable copy of its encoding layers The trainable copy and the original, locked model are connected with zero convolution layers, with weights initialized to zeros so that they progressively grow during the training.
(1) 효율적인 미세 조정을 통해 사전 훈련된 텍스트-이미지 확산 모델에 공간적으로 국소화된 입력 조건을 추가할 수 있는 신경망 아키텍처인 컨트롤넷을 제안하고, (2) 캐니 에지, 허프 라인에 조건화된 안정적인 확산을 제어하기 위해 사전 훈련된 컨트롤넷을 제시합니다, 사용자 낙서, 사람의 주요 지점, 분할 지도, 도형 법선, 깊이, 만화 선화 등을 조건으로 하는 안정적인 확산을 제어하는 사전 훈련된 제어망을 제시하고, (3) 여러 대안 아키텍처와 비교하는 실험을 통해 방법을 평가하고, 다양한 작업에 걸쳐 이전의 여러 기준선에 중점을 둔 사용자 연구를 수행합니다.
3. Related Work
3.1 Finetuning Neural Networks
신경망을 미세 조정하는 한 가지 방법은 추가 학습 데이터로 직접 학습을 계속하는 것입니다. 하지만 이 접근 방식은 overfitting, mode collapse, and catastrophic for- getting 를 초래할 수 있습니다.
-
HyperNetwork
HyperNetwork는 특히 복잡한 또는 매우 큰 모델들의 효율적인 학습과 파라미터 관리를 위해 고안된 신경망 구조 중 하나입니다. 이 방법은 주로 더 크고 복잡한 신경망의 가중치를 조정하거나 설정하는 데 사용되는 더 작은 신경망을 훈련시키는 데 초점을 맞춥니다. 이러한 구조는 일반적으로 ‘하이퍼네트워크’로 불리며, 큰 네트워크의 효율성과 성능을 크게 향상시킬 수 있습니다.
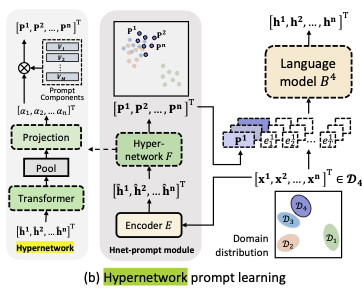
-
Adapter
### Adapter의 주요 특징과 작동 원리:
- 모듈성: Adapter는 사전 훈련된 모델에 삽입되는 작은 네트워크 레이어나 모듈로 구성됩니다. 이 모듈은 원래 모델의 가중치를 직접 조정하지 않으면서도 새로운 작업에 필요한 특화된 학습을 제공합니다.
- 효율성: Adapter 레이어를 추가함으로써, 전체 모델을 처음부터 다시 학습할 필요 없이, 사전 훈련된 네트워크의 강력한 기능을 보존하면서 새로운 작업에 대해 빠르고 효율적으로 모델을 적응시킬 수 있습니다. 이는 특히 대규모 모델에서 계산 비용과 시간을 절약할 수 있습니다.
- 유연성: Adapter는 다양한 작업과 조건에 맞추어 구성될 수 있습니다. 예를 들어, 도메인 적응, 증분 학습, 그리고 다양한 특정 작업들에 적용할 수 있습니다.
### 최근 연구 및 개발:
- ViT-Adapter: 비전 변환기에 특화된 Adapter 모델로, 비전 작업에 최적화된 사전 훈련된 Transformer 모델에 Adapter 레이어를 추가하여 사용합니다.
- T2I-Adapter: Stable Diffusion과 같은 이미지 생성 모델을 외부 조건에 적응시키는데 사용됩니다. 이를 통해, 모델이 다양한 스타일, 테마, 또는 특정 요구 조건에 맞춰 이미지를 생성할 수 있도록 합니다.
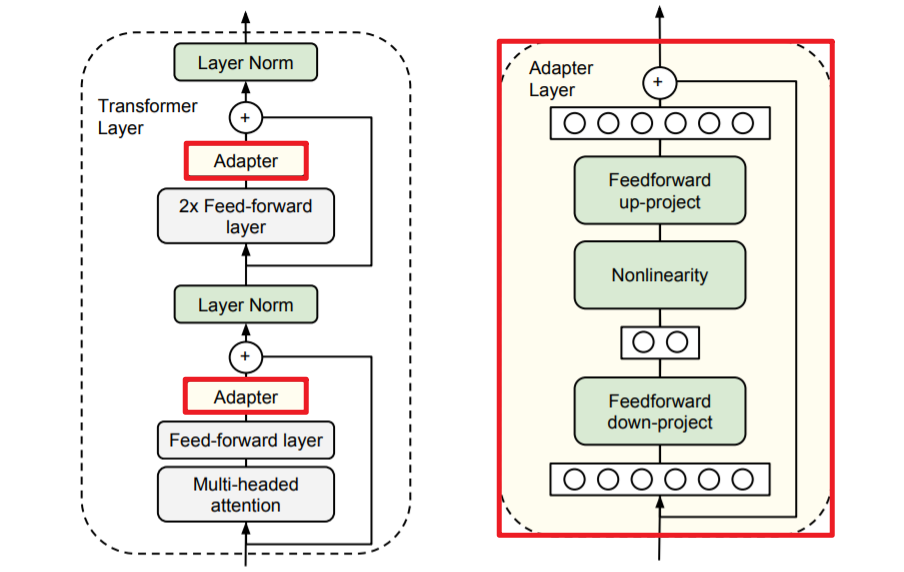
-
difference between hyper and adapter
### 1. 구조적 차이:
- HyperNetworks: 이 방법은 주로 더 큰 신경망의 가중치를 동적으로 생성하기 위해 작은 신경망을 사용합니다. HyperNetwork는 큰 모델의 각 구성 요소에 대한 매개변수를 생성하는 역할을 하여, 이를 통해 큰 모델의 가중치가 특정 태스크나 조건에 맞게 조정될 수 있습니다.
- Adapters: 이들은 사전 훈련된 모델의 특정 층 사이에 삽입되는 작은 모듈 또는 레이어로 구성됩니다. Adapter는 모델의 기존 가중치를 직접적으로 조정하지 않고, 추가된 레이어를 통해 새로운 데이터셋이나 작업에 대한 학습을 가능하게 합니다.
### 2. 적용 목적:
- HyperNetworks: 이 기술은 주로 매개변수의 수가 매우 많거나, 다양한 조건과 스타일에 유연하게 적응해야 하는 복잡한 네트워크에 적용됩니다. 또한, 작은 모델이 큰 모델의 구조를 동적으로 변화시킬 수 있어, 매우 다양한 시나리오에서 사용될 수 있습니다.
- Adapters: 주로 사전 훈련된 모델을 특정 도메인이나 작업에 빠르게 적응시키는 데 사용되며, 계산 비용과 학습 시간을 절약하기 위한 목적이 강합니다. 이는 NLP 또는 컴퓨터 비전 분야의 특정 작업으로 확장하는 데 효과적입니다.
### 3. 유연성과 재사용성:
- HyperNetworks: 다양한 네트워크 및 태스크에 대해 매우 동적이고 유연한 적응력을 제공합니다. 큰 모델의 모든 가중치를 조정할 수 있는 능력 때문에 매우 다양한 변화에 적용 가능합니다.
- Adapters: 특정 모델에 쉽게 추가되어 재사용될 수 있으며, 여러 다른 작업에 대해 특화된 여러 Adapter를 개발하고 이를 저장, 재사용하는 것이 가능합니다.
-
Additive Learning
원래 모델 파라미터를 고정하고, 추가되는 작은 수의 파라미터를 학습
Additive Learning(부가적 학습)은 기존의 모델이나 시스템에 새로운 기능이나 데이터를 추가하면서 학습을 진행하는 방법입니다. 이 개념은 주로 기존 모델의 학습된 지식을 유지하면서, 새로운 정보를 효과적으로 통합하고자 할 때 사용됩니다. 이 방식은 특히 기계 학습에서 증분 학습(Incremental Learning)과 관련이 깊습니다.
Additive Learning의 특징
- 증분 학습: 기존 모델에 점진적으로 데이터를 추가하고, 모델이 새로운 정보를 학습하면서도 이전에 학습한 정보를 잊지 않도록 하는 방식입니다.
- 데이터 통합: 새로운 데이터셋을 기존 데이터셋에 추가하여 전체 모델의 성능을 개선하는데 초점을 맞춥니다. 이는 특히 데이터의 양이 시간에 따라 증가하는 경우 유용합니다.
- 연속적 학습: 모델이 지속적으로 업데이트되며, 변경되는 환경이나 조건에 맞춰 성능을 유지하거나 개선하는데 중점을 둡니다.
Additive Learning과 HyperNetworks 및 Adapters의 차이점
- HyperNetworks와의 차이: HyperNetworks는 하나의 신경망이 다른 신경망의 가중치를 생성하는 구조를 사용하여, 매우 동적인 파라미터 조정이 가능합니다. 이는 주로 복잡한 시나리오에서 모델의 매개변수를 조정할 때 사용됩니다. 반면, Additive Learning은 기존의 학습된 지식에 새로운 데이터를 추가하면서 점진적인 학습을 추구하는 보다 전통적인 방식에 가깝습니다.
- Adapters와의 차이: Adapters는 사전 훈련된 모델에 작은 레이어를 추가하여 새로운 태스크에 적응하는 방식입니다. 이는 구조적인 변화를 최소화하면서도 특정 작업에 효과적으로 적응할 수 있도록 설계되어 있습니다. Additive Learning은 이러한 구조적 변화보다는 데이터의 추가와 지속적인 학습에 더 큰 중점을 둡니다.
Additive Learning은 기본적으로 기존 지식을 보존하면서 새로운 데이터를 계속해서 통합하고 학습하는 접근 방식을 취하며, 이를 통해 모델의 지속적인 성장과 개선을 추구합니다. 이는 데이터가 지속적으로 축적되는 환경에서 특히 유용하며, 기존 모델을 유지하면서도 새로운 정보를 효과적으로 통합하고자 할 때 적합한 방법론입니다.
-
Low-Rank Adaptation (LoRA)
LLM을 fine tuningg하기 위해서 gpu 메모리 많이 필요
- Fully FIne-Tuning 하지 않는다.
- Model weight 를 Freeze 한다.
- 학습하는 Layer 는 LoRA_A & LoRA_B 이다. (둘 다 nn.linear 형태)
- Transformer Layer 에 있는 Query, Key, Value, Output(=self attention) 중 선택하여 ( LoRA_B x LoRA_A ) 를 단순히 더해준다.
- Query, Key layer에 더해줬을 때 성능이 가장 좋음
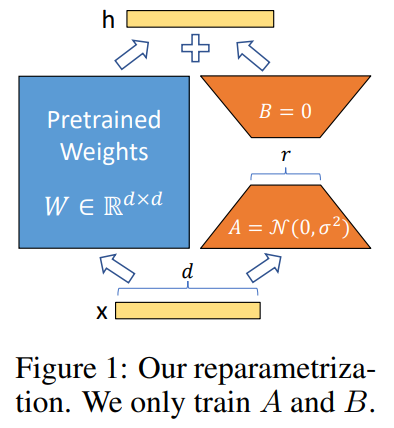
- LoRA와 Adapter의 차이점
주요 차이점
- 적용 방법: LoRA는 모델의 가중치에 직접 저랭크 변형을 적용하는 반면, Adapters는 외부에서 모델 구조에 추가 레이어를 삽입합니다.
- 학습 목적: LoRA는 주로 매개변수의 수를 적게 늘리면서도 효율적으로 특정 태스크에 모델을 적응시키는 것에 초점을 맞춥니다. 반면, Adapters는 모델을 다양한 태스크에 유연하게 적용할 수 있도록 설계되어 있습니다.
- 모델 구조의 변경: LoRA는 기존 모델의 가중치 구조 내에서 작동하는 반면, Adapters는 실제로 모델 구조에 새로운 레이어를 추가하여 작업 적응성을 개선합니다.
두 방법 모두 사전 훈련된 모델을 새로운 작업에 효과적으로 적용할 수 있도록 돕지만, 그들이 선택한 기술적 접근법과 적용 범위에는 뚜렷한 차이가 있습니다. LoRA는 효율성과 계산 최적화에 더 중점을 두는 반면, Adapters는 유연성과 다양한 태스크의 적용 가능성에 초점을 맞춥니다.
-
Zero-Initialized Layers : 위 논문에서 사용하는 방법
Zero-initialized layers는 신경망에서 특정 네트워크 블록들을 연결하기 위해 사용되는 방법 중 하나로, 이 레이어들의 초기 가중치를 0으로 설정하는 것을 의미합니다. 이러한 접근 방식은 네트워크의 학습 동안 가중치가 데이터로부터 자연스럽게 조정될 수 있도록 하면서, 학습 초기에 네트워크가 어떠한 가정도 하지 않도록 설계됩니다.
### Zero-Initialized Layers의 기본 원리
Zero-Initialized Layers는 가중치를 0으로 초기화하여 시작합니다. 이는 네트워크의 가중치가 학습 과정에서 데이터로부터 학습되어야 하며, 초기 가중치가 모델의 학습이나 예측에 영향을 주지 않도록 함을 목표로 합니다.
### Zero-Initialized Layers의 장점
- 단순성과 명확성: 가중치를 0으로 설정하면 네트워크 설계가 단순해지고, 학습 과정에서 가중치가 어떻게 변화하는지 관찰하기 쉬워집니다.
- 경험적 오류 최소화: 가중치를 0으로 초기화하면 초기 예측에 대한 편향을 최소화할 수 있습니다. 이는 특히 네트워크의 출력이 초기 가중치에 민감한 경우 유용합니다.
### Zero-Initialized Layers의 단점
- 학습 시작의 어려움: 모든 가중치가 0으로 초기화되면, 신경망은 초기 학습 단계에서 입력에 대한 어떠한 정보도 학습할 수 없게 됩니다. 이는 학습의 시작을 지연시키거나, 최적화 과정에서 복잡성을 증가시킬 수 있습니다.
- 대칭성 문제: 특히 심층 네트워크에서, 모든 가중치가 동일하게 초기화되면 각 레이어의 뉴런들이 동일한 출력을 내게 되어, 학습 동안 유용한 특징을 추출하는데 제한을 받을 수 있습니다.
Image Diffusion
Controlling Image Diffusion Models
(Text-guided control methods focus on adjusting prompts, manipulating CLIP features, and modifying cross-attention)
MakeAScene : encodes segmentation masks into tokens to control image generation.
SpaText : maps segmentation masks into localized token embeddings.
GLIGEN : learns new parameters in attention layers of diffusion models for grounded generating.
Textual Inversion and DreamBooth : can personalize content in the generated image by finetuning the image diffusion model using a small set of user-provided example images.
Prompt-based image editing : provides practical tools to manipulate images with prompts.
Voynov et al. : propose an optimization method that fits the diffusion process with sketches.
4. Method
ControlNet은 large pretrained T2V diffusion model에서 공간적으로 제한된 작업별 이미지 조건으로 강화할 수 있는 구조
4.1 ControlNet
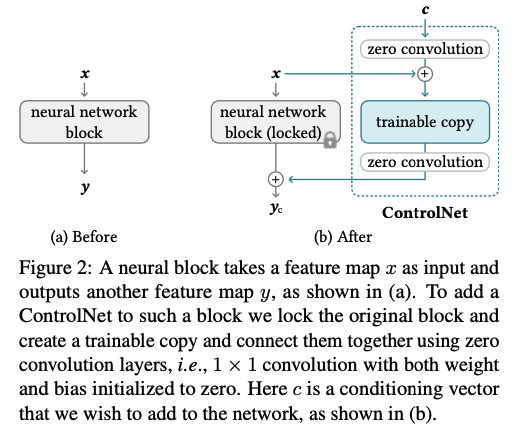
기존 resnet block, conv-bn-relu block, multi-head attention block, transformer block 과 같은 a single unit of a neural network에 다음과 같이 추가적인 ControlNet을 더한다.
- Trained neural block: \(\boldsymbol{y}=\mathcal{F}(x;\boldsymbol{\Theta})\),
(with. $h, w, c$ as the height, width, and number of channels in the map)
- zero convolution layers : \(\mathcal{Z} (·; ·)\)
- Freeze the parameters $\mathcal{\Theta}$ and trainable copy the parameters \(\mathcal{\Theta_c}\) → trainable copy model은 외부 conditioning vector, c를 input으로 받음
- 이를 통해 large model을 다양한 입력 조건을 처리하기 위한 깊고 견고하며 강력한 backborn으로 사용가능
- “backbone”은 신경망 구조에서 중추적인 역할을 하는 기본적인 신경망을 의미
-
ControlNet과 기존 모델과의 연결 : decoder 부분에서 zero convolution 을 한 후 기존 모델 decoder와 연결
\[\boldsymbol{y}_c =\mathcal{F}(\boldsymbol{x};Θ)+\mathcal{Z}(\mathcal{F}(\boldsymbol{x}+\mathcal{Z}(\boldsymbol{c};Θ_{z1});Θ_c);Θ_{z2})\]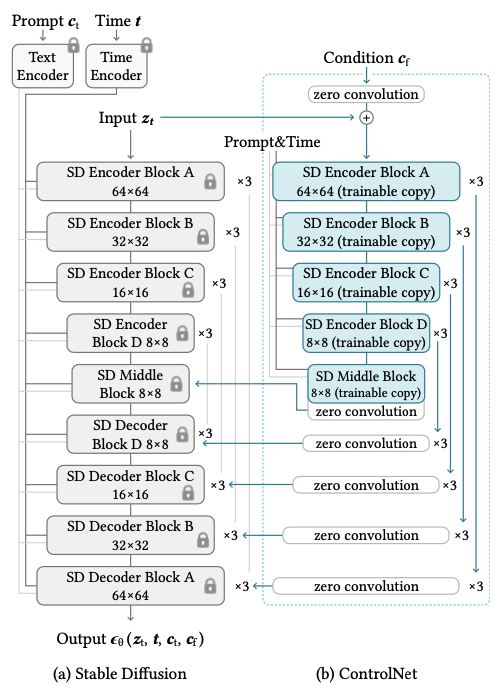
1×1 컨볼루션의 주요 기능
- 채널 수 조정: 1×1 컨볼루션을 사용하면 출력 피처 맵의 채널 수를 증가시키거나 감소시킬 수 있습니다. 이는 네트워크가 필요에 따라 더 많은 피처를 학습하거나, 불필요한 피처를 줄여 계산 효율성을 높이는 데 도움이 됩니다.
- 계산 복잡성 감소: 특히 깊은 네트워크에서, 1×1 컨볼루션은 채널 수를 조절함으로써 전체적인 연산량을 줄일 수 있습니다. 예를 들어, 많은 수의 채널을 가진 피처 맵을 먼저 1×1 컨볼루션을 통해 채널 수를 줄인 후, 더 큰 필터 크기의 컨볼루션을 적용하면 전체적인 파라미터 수와 계산량을 줄일 수 있습니다.
- 네트워크 학습 향상: 1×1 컨볼루션은 다른 컨볼루션 레이어들 사이에 위치하여, 채널 간의 정보를 조합하고 피처를 더 잘 통합할 수 있도록 합니다. 이는 네트워크가 더 복잡하고 다양한 패턴을 학습하는 데 도움을 줄 수 있습니다.
- 초기에는 zero convolution layer가 0으로 초기화 되어있어 \(\boldsymbol{y}_c=\boldsymbol{y}\)
- Zero convolution 레이어에서 가중치와 편향이 모두 0으로 초기화
- 훈련 초기에는 모델이 미숙하고 불안정할 가능성이 높기 때문에, 무작위 잡음이나 불필요한 변동성이 모델의 중요한 부분(backbone)에 영향을 줄 있음
- Zero convolution을 사용하면, 이러한 초기 잡음이나 불필요한 신호가 학습 과정에 영향을 미치지 않도록 할 수 있음. 즉, Zero convolution은 이러한 초기 잡음을 ‘필터링’함으로써, 모델의 핵심 구조나 중요 파라미터가 잘못된 방향으로 학습되는 것을 방지
4.2 ControlNet for Text-to-Image Diffusion : example, stable diffsion
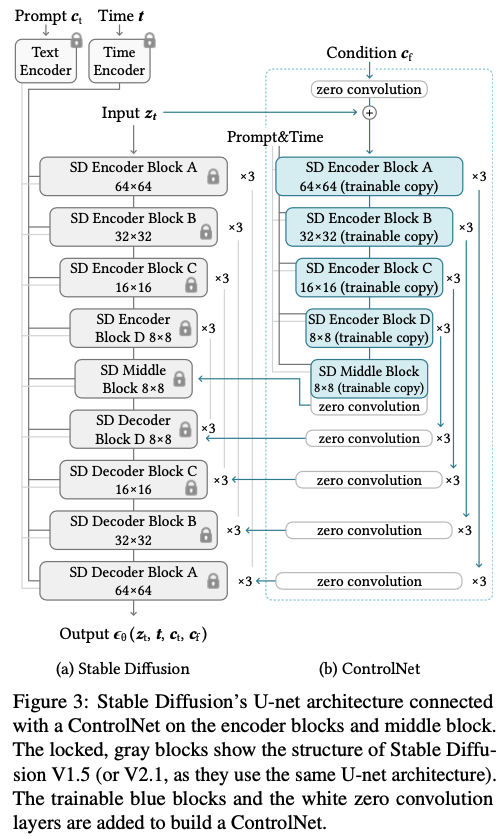
Encoder, Decoder 각각 12개 ,총 24개
4 resnet layers, 2 Vision Transformers (ViTs), 8 blocks are down-sampling or up-sampling convolution layers, 등등
‘SD 인코더 블록 A’는 4개의 리셋 레이어와 2개의 ViT를 포함하며, ‘×3’은 이 블록이 세 번 반복됨을 나타냄
텍스트 프롬프트는 CLIP 텍스트 인코더[66]를 사용하여 인코딩
diffusion timesteps are encoded with a time encoder using positional encoding.
As tested on a single NVIDIA A100 PCIE 40GB, optimizing Stable Diffusion with ControlNet requires only about 23% more GPU memory and 34% more time in each training iteration, compared to optimizing Stable Diffusion without ControlNet.
23% more GPU memory and 34% more time 으로 최적화가 가능하다.
4.3 ControlNet의 추가
ControlNet을 Stable Diffusion에 추가하는 과정은 다음과 같습니다:
- 입력 조건 이미지 변환: 각 입력 조건 이미지(예: 에지, 포즈, 깊이 등)를 원래 크기인 512×512에서 64×64 피처 공간 벡터로 변환합니다. 이 크기는 Stable Diffusion의 잠재 이미지 크기와 일치합니다.
- 인코딩 네트워크 사용: 이 과정에는
E(·)라는 작은 네트워크가 사용됩니다. 이 네트워크는 4개의 컨볼루션 레이어(각각 4×4 커널과 2×2 스트라이드 사용, ReLU 활성화 함수 사용)로 구성되어 있으며, 16, 32, 64, 128 채널을 각각 사용합니다. 가우시안 가중치로 초기화되고 전체 모델과 함께 합동으로 훈련됩니다. - 조건 벡터 생성: 위의 인코딩 네트워크는 이미지 공간의 조건
ci를 피처 공간의 조건 벡터cf로 변환합니다. - ControlNet 입력: 생성된 조건 벡터
cf는 ControlNet으로 전달되어 이미지 생성 과정에 사용됩니다.
Training
input image
\(z_0\), a noisy image \(z_t\)
a set of conditions including time step t, text prompts \(c_t\), a task-specific condition $$c_f$
image diffusion algorithms learn a network \(ε_θ\)
\[\mathcal{L}=\mathbb{E}_{\boldsymbol{z}_0,\boldsymbol{t},\boldsymbol{c}_t,\boldsymbol{c}_f,ε∼\mathcal{N}(0,1)} \left[\left|\left|ε−ε_θ(z_t,t,c_t,c_f)\right|\right|_2^2 \right]\]L is the overall learning objective of the entire diffusion model
4.4 ControlNet의 특징 및 훈련 전략
- 텍스트 프롬프트 조작: 훈련 과정 중 텍스트 프롬프트
ct의 50%를 빈 문자열로 대체합니다. 이 방법은 ControlNet이 입력 조건 이미지(예: 에지, 포즈, 깊이 등)의 의미론적 내용을 직접 인식하고, 프롬프트를 대체하는 능력을 향상시킵니다. - Zero Convolution의 역할: Zero convolution은 네트워크에 추가 노이즈를 생성하지 않습니다. 따라서 모델은 항상 고품질의 이미지를 예측할 수 있어야 합니다. 훈련 과정에서 모델은 점진적으로가 아닌 갑자기 입력 조건 이미지를 따르는 것을 성공적으로 학습하며, 이는 보통 10K 최적화 스텝 이내에 일어납니다. 이 현상을 “갑작스러운 수렴 현상”이라고 합니다.
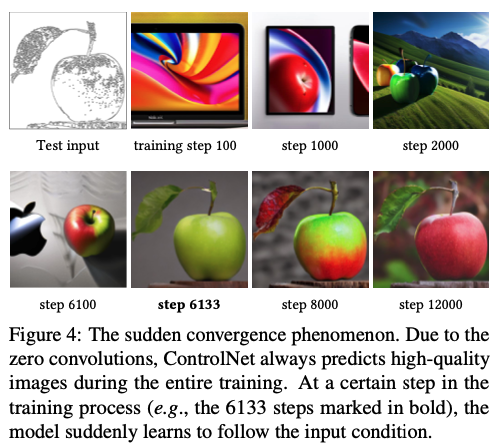
4.5 Inference
Classifier-free guidance resolution weighting
base CFG formulation
\[ε_{prd} = ε_{uc} + β_{cfg} (ε_c − ε_{uc} )\]\(ε_{prd} , ε_{uc} , ε_c, β_{cfg}\) : 모델의 최종 출력, 비조건부 출력, 조건부 출력, 사용자가 지정한 가중치

조건 이미지 추가 방식
- 둘 다에 추가 ( \(ε_{uc} , ε_c\) 둘 다에 추가)
- 이 방식에서 조건 이미지는 모델의 비조건부 출력(ϵuc)과 조건부 출력(ϵc) 둘 다에 추가됩니다.
- 결과적으로, 모델은 조건부와 비조건부 출력 사이에 차이를 만들지 않게 되며, 이는 CFG의 가이던스 효과를 완전히 제거합니다.
- CFG 가이던스가 제거되면, 모델은 주어진 조건에 덜 의존하게 되어 더 일반적이고 자연스러운 이미지를 생성할 수 있습니다. 이는 Figure 5b에서 확인할 수 있습니다.
- \(ε_{uc}\) 에만 추가
- 조건 이미지가 모델의 조건부 출력(ϵc)에만 추가되는 경우, CFG의 가이던스가 강화됩니다.
- 이 경우, 모델은 주어진 조건(예를 들어, 특정 객체의 스타일이나 포즈)을 더 강하게 반영하여 생성된 이미지에 더 명확하게 표현됩니다. 이는 Figure 5c에서 확인할 수 있습니다.
CFG Resolution Weighting
논문에서 제안하는 해결책은 조건 이미지를 먼저 ϵc에 추가한 다음, Stable Diffusion과 ControlNet 사이의 각 연결에 가중치 wi를 곱하는 것입니다. 이 가중치는 각 블록의 해상도에 따라 다르게 설정됩니다:
여기서 hihi는 i번째 블록의 크기입니다 (예: h1=8h1=8, h2=16h2=16, …, h13=64h13=64).
이 방법을 통해 CFG의 가이던스 강도를 줄이면서도, 모델이 조건 이미지에 기반한 더 정확하고 상세한 이미지를 생성할 수 있도록 합니다. 이는 Figure 5d에서 보여진 결과를 달성할 수 있게 하며, 이를 “CFG Resolution Weighting”이라고 합니다.
이 접근 방식은 이미지의 특정 조건을 더 세밀하게 제어하고, 생성된 이미지의 품질을 높이는 데 기여할 수 있습니다. ControlNet과 결합된 CFG의 이러한 적용은 다양한 이미지 생성 작업에서 매우 유용할 수 있습니다.
Composing multiple ControlNets
작동 방식의 구체적 설명:
- 독립적 처리: 각 ControlNet은 입력 이미지에 대해 특정한 조건 처리를 담당합니다. 예를 들어, 하나의 ControlNet은 이미지의 에지 정보를 추출하고, 다른 ControlNet은 포즈 데이터를 처리합니다.
- 결과의 통합: 각 ControlNet에서 처리된 결과는 별도의 가중치 조정이나 복잡한 조정 없이 Stable Diffusion 모델에 직접 추가됩니다. 이는 각 조건이 갖는 고유한 정보를 모델에 효과적으로 반영하게 하며, 이들 조건의 결과를 동시에 반영하여 최종 이미지를 생성합니다.
- 병렬적 접근: 각 ControlNet의 작업은 병렬적으로 이루어질 수 있으며, 각각의 네트워크가 독립적으로 특정 조건의 처리를 마친 후 결과를 합산합니다. 이러한 방식은 처리 시간을 절약하고, 각 조건의 특성을 효율적으로 활용할 수 있게 합니다.

5. Experiments
Qualitative Results

our results with various conditions without prompts
ControlNet은 input conditioning image를 강하게 반영
Ablative Study
(1) replacing the zero convolutions with standard convolution layers initialized with Gaussian weights
(2) replacing each block’s trainable copy with one single convolution layer, which we call ControlNet-lite
- 프롬프트 없음: 어떠한 지시어도 제공되지 않은 상태.
- 불충분한 프롬프트: 조건 이미지에 있는 객체를 완전히 커버하지 못하는 프롬프트, 예를 들어 “고품질, 세밀하며 전문적인 이미지”와 같은 기본 프롬프트.
- 상충하는 프롬프트: 조건 이미지의 의미를 변경시키는 프롬프트.
- 완벽한 프롬프트: 필요한 내용의 의미를 설명하는 프롬프트, 예를 들어 “멋진 집”.

(a) : 제로 컨볼루션 사용 모델
(b) : 표준 컨볼루션 레이어 사용 모델
(c) : ControlNet-lite
ControlNet-lite의 성능
- 경량화된 ControlNet-lite는 조건 이미지를 해석하는 데 충분한 성능을 제공하지 못합니다. 특히 프롬프트가 없거나 불충분한 조건에서 성능이 부족합니다. 이는 ControlNet-lite가 간소화된 구조로 인해 필요한 정보를 충분히 학습하고 추출하지 못하기 때문입니다.
제로 컨볼루션의 교체 효과
- 제로 컨볼루션을 표준 컨볼루션으로 교체한 경우, ControlNet의 성능이 ControlNet-lite와 비슷한 수준으로 떨어집니다. 이는 제로 컨볼루션의 교체가 사전 훈련된 백본(backbone)의 파괴를 초래하고, 이로 인해 훈련 가능한 사본에서의 미세조정 과정이 비효율적으로 이루어지는 것을 시사합니다.
훈련 가능한 사본 및 사전 훈련된 백본의 역할
- 사전 훈련된 백본은 모델이 초기에 학습한 복잡한 패턴과 특징을 보존하는 핵심 구조입니다. 제로 컨볼루션을 제거하고 이를 표준 컨볼루션으로 대체할 경우, 이 백본이 파괴되어 모델이 초기에 학습된 효과적인 특성을 잃어버리게 됩니다. 이는 전체적인 모델 성능에 부정적인 영향을 끼치며, 특히 조건 이미지를 해석하고 적절히 반응하는 데 필요한 정보 처리 능력이 저하됩니다.
Quantitative Evaluation
User study.
스케치를 통해 이미지 생성
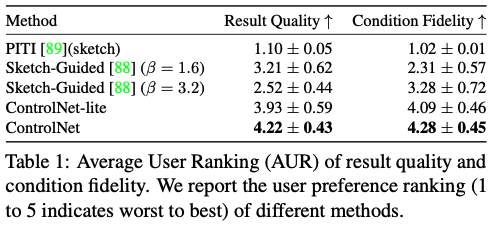
12명의 사용자에게 ‘표시된 이미지의 품질’과 ‘스케치에 대한 충실도’를 기준으로 5개씩 20개의 결과 그룹에 대해 개별적으로 순위를 매기도록 요청
사용자가 각 결과의 순위를 1부터 5까지(낮을수록 나쁨) 매기는 선호도 지표로 평균 인간 순위(AHR)를 사용합니다.
Comparison to industrial models.
이 내용은 Stable Diffusion V2 Depth-to-Image (SDv2-D2I)와 ControlNet을 비교하는 실험에 대한 설명입니다. SDv2-D2I는 대규모의 NVIDIA A100 클러스터를 사용하여, 수천 시간의 GPU 시간과 1200만 개 이상의 훈련 이미지로 훈련된 반면, ControlNet은 동일한 깊이 조건을 사용하지만 훨씬 적은 20만 개의 훈련 샘플, 하나의 NVIDIA RTX 3090Ti 그래픽 카드, 그리고 단 5일의 훈련 기간으로 훈련되었습니다.

실험 설계 및 방법
- 이미지 생성: 두 모델(SDv2-D2I와 ControlNet)은 각각 100개의 이미지를 생성합니다.
- 사용자 테스트: 12명의 사용자를 대상으로 이 두 방법에 의해 생성된 이미지를 구분하도록 교육합니다. 이후, 200개의 이미지를 생성하고 사용자들에게 각 이미지가 어떤 모델에 의해 생성되었는지 판별하도록 요청합니다.
- 성능 측정: 사용자의 평균 정확도는 0.52 ± 0.17로 나타났습니다. 이는 통계적으로 두 방법에 의해 생성된 이미지 결과가 거의 구별할 수 없음을 의미합니다.
결과 해석
- 모델 성능의 유사성: 비록 ControlNet이 훨씬 적은 자원과 훈련 데이터를 사용했음에도 불구하고, 사용자들은 두 모델에 의해 생성된 이미지를 구별하는 데 큰 어려움을 겪었습니다. 이는 ControlNet이 상대적으로 적은 자원으로도 SDv2-D2I와 비슷한 수준의 이미지 품질을 달성할 수 있음을 시사합니다.
- 비용 효율성: ControlNet의 접근 방식은 자원 사용량을 크게 줄임으로써 비용 효율적인 대안을 제시합니다. 이는 특히 자원이 제한적인 환경에서 고품질의 이미지 생성 모델을 개발하고자 할 때 매우 유용할 수 있습니다.
Condition reconstruction and FID score. 이 문단은 ADE20K 데이터셋을 사용하여 여러 이미지 생성 방법의 조건 충실도를 평가하는 과정을 설명, 생성된 이미지의 품질을 평가하기 위해 다양한 측정 기준을 사용하는 방법에 대해서도 설명
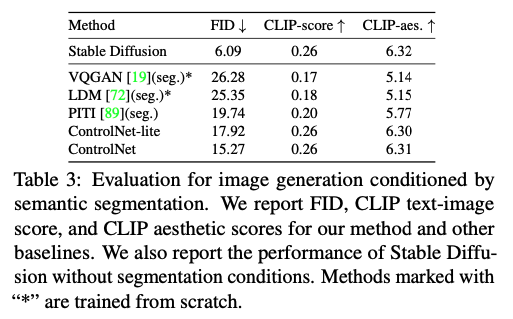
조건 재구성 및 평가 방법
- ADE2 충실도를 평가하는 데 사용됩니다.
- OneFormer의 사용: OneFormer는 최신 세그멘테이션 방법으로, ground-truth 데이터셋에 대해 0.58의 Intersection-over-Union (IoU) 성능을 달성합니다. IoU는 모델이 생성한 세그멘테이션 결과와 실제 세그멘테이션 간의 오버랩을 측정하는 지표로, 값이 높을수록 성능이 좋다는 것을 의미합니다.
- IoU 재계산: 다양한 방법으로 ADE20K 세그멘테이션을 사용하여 이미지를 생성한 후, OneFormer를 사용하여 이 세그멘테이션을 다시 감지하고 재구성된 IoU를 계산합니다. 이는 각 생성 방법이 얼마나 정확하게 입력 조건을 반영하여 이미지를 생성하는지를 평가하는 데 사용됩니다.
이미지 품질 측정 지표
- Frechet Inception Distance (FID): FID 점수는 생성된 이미지와 실제 이미지 간의 분포 거리를 측정합니다. 낮은 FID 점수는 생성된 이미지가 실제 이미지와 통계적으로 유사함을 의미하며, 이미지 품질의 우수성을 나타냅니다.
- CLIP 점수: 텍스트-이미지 CLIP 점수와 CLIP 미학 점수는 생성된 이미지가 주어진 텍스트 설명과 얼마나 잘 일치하는지, 그리고 미학적으로 얼마나 매력적인지를 평가합니다. 이 점수들은 생성 모델이 얼마나 효과적으로 텍스트 기반 조건을 시각적으로 번역하는지를 평가하는 데 사용됩니다.
추가 정보
- 상세한 실험 설정 및 추가 데이터는 보조 자료에서 확인할 수 있습니다. 이 자료는 평가 방법과 결과에 대한 더 깊은 이해를 제공하며, 연구의 투명성과 재현성을 보장하는 데 도움을 줍니다.
Comparison to Previous Methods

Discussion

이 섹션에서는 ControlNet의 훈련과 관련된 몇 가지 주요 사항을 논의하고 있습니다. 다루고 있는 주제들은 훈련 데이터셋의 크기가 모델 성능에 미치는 영향, 내용 해석 능력, 그리고 커뮤니티 모델로의 전이 가능성 등입니다.
1. 훈련 데이터셋 크기의 영향
- 로버스트성: ControlNet은 제한된 데이터셋(예: 1,000개의 이미지)에서도 훈련이 붕괴되지 않는 안정성을 보여줍니다. 심지어 소규모 데이터셋을 사용하여도 모델이 인식 가능한 사자 이미지를 생성할 수 있었다는 점이 이를 증명합니다. 이는 ControlNet이 소량의 데이터에서도 유효한 학습을 할 수 있음을 나타냅니다.
- 확장 가능한 학습: 더 많은 데이터가 제공될 때 학습이 확장 가능함을 보여줍니다. 즉, 훈련 데이터셋의 크기가 커질수록 모델의 성능도 향상되며, 이는 일반적으로 머신 러닝 모델에 적용되는 원리와 일치합니다.
2. 내용 해석 능력
- 의미론적 이해: ControlNet은 입력 조건 이미지에서 의미론적 내용을 포착하는 능력을 가지고 있습니다. 이는 모델이 다양한 조건에 따라 적절한 이미지를 생성할 수 있는 능력을 의미하며, 예를 들어 특정 객체의 특성이나 상황을 이미지에 반영할 수 있습니다.
3. 커뮤니티 모델로의 전이 가능성
- 네트워크 토폴로지 변경 없음: ControlNet은 사전 훈련된 Stable Diffusion 모델의 네트워크 토폴로지를 변경하지 않기 때문에, 다양한 커뮤니티 모델에 직접 적용할 수 있습니다. 이는 ControlNet이 다양한 기존 모델과 호환될 수 있음을 의미하며, Comic Diffusion이나 Protogen 3.4와 같은 모델에도 적용 가능함을 보여줍니다.