
[논문분석] VideoPoet: A Large Language Model for Zero-Shot Video Generation
LLM을 활용한 multimodal diffusion generation [Page, Paper] Dan Kondratyuk , Lijun Yu , Xiuye Gu
Abstract
We present VideoPoet, a model for synthesizing high-quality videos from a large variety of conditioning signals. VideoPoet employs a decoderonly transformer architecture that processes multimodal inputs – including images, videos, text, and audio. The training protocol follows that of Large Language Models (LLMs), consisting of two stages: pretraining and task-specific adaptation. During pretraining, VideoPoet incorporates a mixture of multimodal generative objectives within an autoregressive Transformer framework. The pretrained LLM serves as a foundation that is adapted to a range of video generation tasks. We present results demonstrating the model’s stateof-the-art capabilities in zero-shot video generation, specifically highlighting the generation of high-fidelity motions.
다양한 conditioning에서 high-quality 비디오를 합성하는 모델, multimodal
Large Language Models (LLMs)을 활용해 Video generation
text prompt에 의해 제어되는 별도의 generation 모델에 의존하지 않고 단일 LLM으로 제어
Introduction
- A simple method for training a Large Language Model(LLM) specifically for video generation tasks, utilizing tokenized video and audio data that seamlessly incorporates both text-paired and unpaired video data.
- An approach to super-resolution that increases video resolution within the latent token space using a bidirectional transformer with efficient windowed local attention.
- Evaluations and demonstrations that show case the LLM’s competitive performance, especially in producing realistic and interesting motion.
- modality- specific tokenizers
The tokenizers map input data – i.e. image pixels, video frames, and audio waveforms – into discrete tokens in a unified vocabulary.
- a language model backbone
The LLM accepts image, video and audio tokens as input along with text embeddings, and is responsible for generative multi-task and multimodal modeling
- a super-resolution module
the super-resolution module increases the resolution of the video outputs while refining visual details for higher quality
Tokenization
Image∙video tokenizer:MAGVIT-v2, Audio tokenizer:SoundStream.
또한 처음부터 텍스트로 훈련하는 것보다 사전 훈련된 text encoder(T5 XL)를 사용하는 편이 성능이 더 좋았다고 한다.
Image and video tokenizer
MAGVIT-v2
8fps로 샘플링된 17프레임 2.125초 128×128 해상도 비디오를 토큰화하여 (5,16,16)의 잠재적 모양을 생성한 다음, 어휘 크기가 218인 1280토큰으로 평평하게 만듭니다.
- This causal property
- 첫 번째 프레임 인코딩: 비디오의 첫 번째 프레임은 (1,16,16) 토큰으로 인코딩됩니다. 이 토큰은 정적 이미지를 나타내는 데도 사용될 수 있습니다. 즉, 비디오의 첫 프레임은 이미지로 간주되며, 이 이미지를 나타내는 토큰이 생성됩니다.
- 첫 번째 프레임이 별도로 토큰화되기 때문에 MAGVIT v2는 이미지를 비디오와 동일한 어휘로 표현할 수 있습니다. 이미지는 더 압축적일 뿐만 아니라, 강한 시각적 스타일(예: 예술 그림), 비디오에서는 잘 볼 수 없는 사물, 풍부한 캡션, 훨씬 더 많은 텍스트-이미지 쌍 훈련 데이터 등 비디오에서는 일반적으로 표현되지 않는 많은 학습 가능한 특성을 제공합니다. 이미지로 학습할 때는 이미지의 크기를 128×128로 조정한 다음 (1, 16, 16) 또는 256 토큰의 잠재적 모양으로 토큰화합니다.
- 4프레임 덩어리 인코딩: 그 후, 비디오의 각 4프레임 덩어리는 (1,16,16) 토큰으로 인코딩됩니다. 이는 비디오의 시간적 구조를 유지하면서 데이터를 효율적으로 압축하는 방법입니다.
- 토큰 연결: 이렇게 생성된 토큰들은 첫 번째 (시간적) 차원에서 연결됩니다. 이는 비디오의 시간적 순서를 유지하면서, 모든 프레임을 하나의 연속적인 데이터 스트림으로 표현할 수 있게 합니다.
- COMMIT [75] encoding
- COMMIT 인코딩은 토큰화 과정에서 인포메이션 누출을 방지하기 위해 입력 조건 영상과 대상 영상을 다르게 처리합니다.
- 전자는 픽셀 마스크가 적용된 조건부 비디오의 토큰화를, 후자는 마스크가 적용되지 않은 전체 비디오에 대한 토큰화를 사용합니다.
Audio tokenizer
We tokenize audio clips with the pre-trained SoundStream [79] tokenizer.
Text tokenizer and embedding as input.
정확하고 고품질의 텍스트 비디오 생성을 위해서는 강력한 텍스트 인코딩이 중요하다는 것을 알게 되었습니다. 일반적으로 사전 학습된 텍스트 표현은 처음부터 텍스트 토큰으로 모델을 학습시키는 것보다 더 나은 성능을 보였습니다. 계산상의 제약으로 인해 모델 규모에 따라 기성품으로 미리 학습된 언어 임베딩을 활용하는 것이 더 효율적이어서 모델이 시각 및 오디오 양식을 생성하고 이해하는 데 더 많은 용량을 할당할 수 있었습니다. 따라서 텍스트 토큰을 모델에 직접 입력하는 대신 먼저 사전 학습된 T5 XL [46] 인코더에 토큰을 입력하여 일련의 텍스트 임베딩을 생성합니다. 텍스트-투-비디오와 같이 텍스트 안내가 필요한 작업의 경우, T5 XL 임베딩은 선형 레이어를 사용하여 트랜스포머의 임베딩 공간에 투영됩니다. 모든 실험에 최대 64개의 텍스트 토큰을 사용합니다.
Language Model Backbone
decoder-only architecture 사용
모든 modelities를 tokenized, so 토큰 공간에서 비디오와 오디오를 생성하는 데 언어 모델을 직접 활용 가능
Decoder-only architecture(UL2)를 백본으로 하는 prefixLM을 사용한다. 어휘 크기 30만 개.
Super-Resolution
Autoregressive transformer를 통해 고해상도 비디오를 생성하는 경우 토큰 길이로 인해 매우 비실용적이므로 spatial super-resolution non-autoregressive video transformer를 개발한다.
-
why?
Autoregressive Transformer를 사용하여 고해상도 비디오를 생성하는 것은 몇 가지 이유로 비실용적일 수 있습니다.
- 토큰 길이: Autoregressive Transformer는 시퀀스의 각 요소를 예측할 때 이전의 모든 요소를 고려합니다 고해상도 비디오를 생성하려면 많은 수의 토큰이 필요하며, 이는 토큰 길이가 길어짐을 의미합니다. 이렇게 긴 토큰 길이는 계산 복잡성을 증가시키고, 메모리 사용량을 늘리며, 학습 시간을 길게 만듭니다
- 시간적 복잡성: Autoregressive Transformer는 자기회귀적인 특성 때문에 시간적으로 복잡합니다. 즉, 각 토큰을 예측하기 위해 이전의 모든 토큰을 고려해야 하므로, 시퀀스가 길어질수록 예측 시간이 증가합니다
- 공간적 복잡성: 고해상도 비디오를 생성하려면 많은 양의 정보를 처리해야 합니다. 이는 공간적 복잡성을 증가시키며, 이로 인해 메모리 요구량이 증가하고, 학습과 추론이 더 어려워집니다
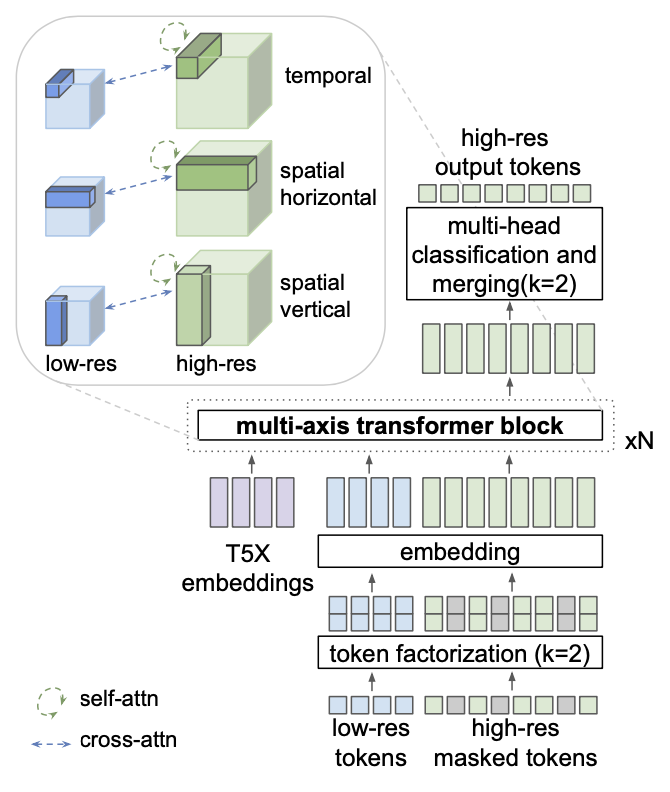
SR transformer에는 3종류의 local window self-attention이 있는 transformer block 3개로 구성되어 있고 cross-attention layer에서는 저해상도 토큰과 텍스트 임베딩을 처리한다.
MAGVIT 목표로 SR transformer를 훈련하고 token factorization을 사용하며 classifier-free guidance에 대해 독립적으로 훈련 샘플의 10%에서 LR 조건과 텍스트 임베딩을 제거한다.
- Cross-Attention은 두 개의 다른 임베딩 시퀀스를 혼합합니다. 이 두 시퀀스는 동일한 차원을 가져야 하며, 동일하거나 다른 모달리티를 가질 수 있습니다.
LLM Pretraining for Generation
VideoPoet demonstrates general-purpose generative video modeling by training with a large mixture of multimodal objectives.
Task Prompt Design
- 조건 없는 비디오 생성: 입력에 대한 조건 없이 비디오 프레임을 생성합니다.
- 텍스트-비디오: 텍스트 프롬프트에서 비디오 프레임을 생성합니다.
- 비디오 미래 예측: 다양한 길이의 입력 비디오가 주어지면 미래의 프레임을 예측합니다.
- 이미지-비디오: 입력 이미지로 비디오의 첫 번째 프레임이 주어지면 향후 비디오 프레임을 예측합니다.
- 비디오 인페인팅/아웃페인팅: 마스킹된 비디오가 주어지면, 마스킹된 내용이 채워진 비디오를 예측합니다.
- 비디오 스타일화: 텍스트 프롬프트, 광학적 흐름, 깊이 및 선택적으로 비디오의 첫 번째 프레임이 주어지면 비디오 프레임을 미리 딕션합니다(4.1절 참조).
- 오디오-비디오: 입력 오디오 파형이 주어지면 해당 비디오를 예측합니다.
- 비디오-오디오: 입력 비디오가 주어지면 그에 상응하는 오디오 파형을 예측합니다.
Representing an image as a video.
첫 이미지 생성이 좋아야 좋은 퀄리티의 프레임 생성 가능
MAGVIT V2 tokenizer → 인과적 종속성 → 이미지와 비디오의 첫번째 프레임을 동일하게 취급
end-of-sequence token (
Video token formet
모든 예제에서 두 가지 해상도와 두 가지 프레임 길이로 총 4개의 조합을 사용할 수 있다. 이미지는 128x128 해상도의 1 프레임 비디오로 취급한다.
Video stylization
text : 비디오 내용
the optical flow and depth : 구조
-
the optical flow and depth 란?
Optical Flow(광학 흐름): 이는 두 개의 연속된 비디오 프레임 사이에서 이미지 객체의 가시적인 동작 패턴을 말합니다. 즉, 이미지 내의 객체가 어떻게 움직이는지를 추적하는 기술입니다. 이는 객체 자체가 움직이거나, 카메라의 움직임으로 인해 발생할 수 있습니다1. Optical Flow는 움직임을 통한 구조 분석, 비디오 압축, 비디오 안정화 등 다양한 영역에서 응용할 수 있습니다. Depth(깊이): Depth는 비디오에서 각 픽셀이 카메라로부터 얼마나 떨어져 있는지를 나타내는 정보입니다23. 이는 3D 비디오 시스템에서 중요한 역할을 하며, 대상의 거리 정보를 제공하여 3D 장면의 기하학적 정보를 나타냅니다. Depth 정보는 3D 장면을 더 정확하게 묘사하고, 가상의 시점을 생성하는 데 사용됩니다.
diffusion model 보다는 machine translation using large language models에 가까움
RAFT → the optical flow , MIDAS → depth
확산 모델의 cross-attention과 같은 복잡한 방법 없이 조건을 채널 차원으로 연결하여 tokenizer에 입력하기만 하면 된다. 텍스트 프롬프트를 변경하여 새로운 스타일의 비디오를 생성할 수 있다.
Text layout
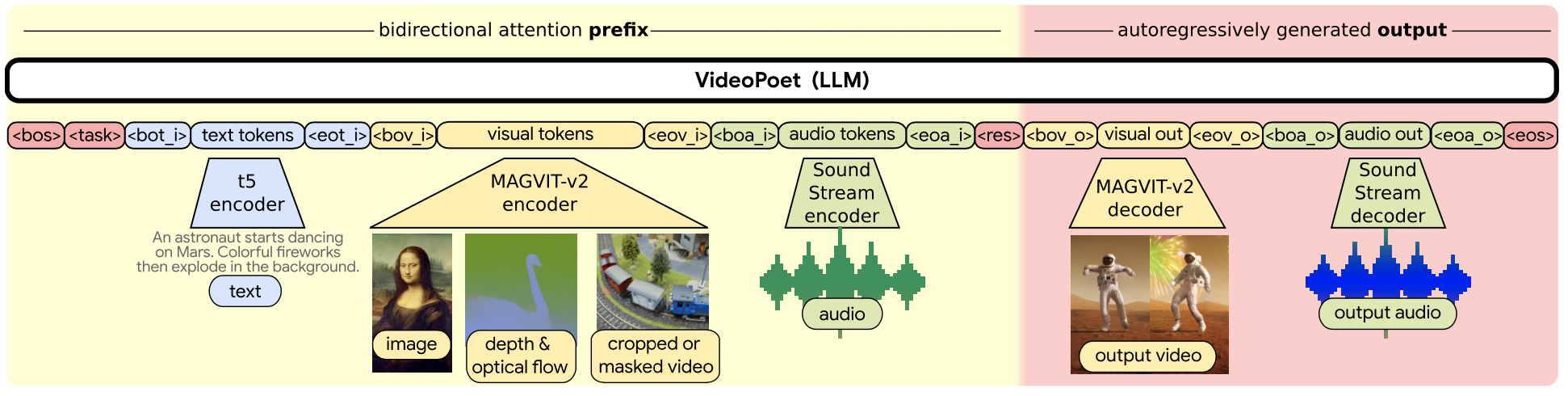
LLM은 text, video, audio token을 입력으로 visual, audio token을 출력하며 prompting을 위한 특수 토큰은 다음과 같다.
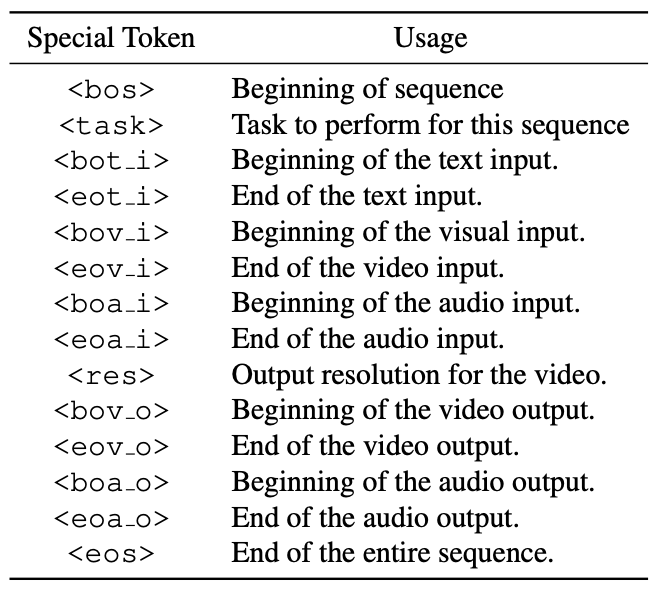
무조건의 경우에는 해당 작업의 특수 토큰과 입력 토큰을 생략한다.
출력에 대한