
[논문분석] VideoFusion: Decomposed Diffusion Models for High-Quality Video Generation
Noise 공유를 통한 프레임 간 연관성 향상
[Paper]
University of Chinese Academy of Sciences | Alibaba Group | Ant Group | CRIPAC | CASIA | Nanjing University CVPR 2023
base noise and residual noise 두개로 나눠서 계산
하나의 video clip i개의 프레임 \(\mathrm{x} = \{x^i | i=1,2,...,N\}\) \(\mathrm{z} = \{z^i | i=1,2,...,N\}\)
\[z^i_t = \sqrt{\hat{\alpha}_t}x^i+\sqrt{1-\hat{\alpha}_t}\epsilon_t^i\]확산 과정의 문제점
- 이 문단은 기존의 방식에서 노이즈 \(ε_t\)가 각 프레임에 독립적으로 추가되고, 이로 인해 비디오 프레임 간의 연관성이 무시되는 문제를 설명하고 있습니다.
- 결과적으로, 비디오를 원래 상태로 복원하기 위한 비디오 프레임 간의 노이즈 샘플이 서로 관련성을 가지고 있음에도 불구하고, 그 관련성이 무시된 채로 노이즈가 추가됩니다.
가능한 해결책에 대한 질문
- 마지막 부분은 비디오 프레임 간의 유사성을 활용하여 더욱 효율적으로 더노이징 프로세스를 수행할 수 있는 방법에 대한 질문을 제기합니다.
$x_0$의 기준 프레임 사용 (비디오 프레임들 사이의 상관관계를 최대한 활용하기 위함)
\[\epsilon_t^i = \sqrt{\lambda^i} b_t^i + \sqrt{1-\lambda^i} r_t^i\]a base noise $b_t^i$
a residual noise $r_t^i$
so,
\[z^i_t = \sqrt{\lambda^i} \left(\sqrt{\hat{\alpha}_t} x^i + \sqrt{1-\hat{\alpha}_t} b_t^i\right) + \sqrt{1-\lambda^i} \left(\sqrt{\hat{\alpha}_t} \triangle x^i + \sqrt{1-\hat{\alpha}_t} r_t^i\right)\]diffusion of $x^0$ , diffusion of $\triangle x^i$
but, In previous methods, although $x^0$ is shared by consecutive frames, it is independently noised to different values in each frame, which may increase the difficulty of denoising.
\[z^i_t = \sqrt{\hat{\alpha}_t} x^i + \sqrt{1-\hat{\alpha}_t} \left(\sqrt{\lambda^i} b_t + \sqrt{1-\lambda^i} r_t^i\right)\]그래서 b를 공통으로 놓음.
최종식:
\[z_t^i = \sqrt{\hat{\alpha}_t} z^i_{t-1} + \sqrt{1-\hat{\alpha}_t} \left(\sqrt{\lambda^i} b_t' + \sqrt{1-\lambda^i} {r'}^i_t\right)\]공유된 \(b_t\) 사용의 이유
- 일관된 노이즈 추가: 공통된 노이즈 요소 \(b_t\)를 프레임 전체에 적용함으로써, 비디오의 모든 프레임이 시간에 따라 일관되게 노이즈 처리됩니다. 이는 다른 프레임 간에 상이한 노이즈 패턴을 생성하는 것보다 노이즈를 일관되게 관리할 수 있게 해 줍니다.
- 더노이징의 용이성: 더노이징 네트워크는 노이즈 제거 과정에서 프레임 간의 시간적 연속성을 이용할 수 있습니다. 모든 프레임에 공통된 \(b_t\)가 사용되기 때문에, 네트워크가 일관된 노이즈 패턴을 인식하고 이를 제거하는 것이 더 쉬워집니다.
- 계산 효율성: 노이즈 패턴을 개별적으로 계산하는 것보다 하나의 공통된 노이즈 패턴을 사용함으로써 계산 과정을 간소화할 수 있습니다.
공유된 \(b_t\)의 효과
- 노이즈 관리의 단순화: 더노이징 과정이 단순해지며, 이로 인해 훈련 시간과 계산 비용이 줄어들 수 있습니다.
- 복원 품질 향상: 일관된 노이즈 모델을 사용함으로써 복원된 비디오의 품질이 향상될 수 있습니다. 네트워크가 노이즈를 더 잘 인식하고 제거할 수 있기 때문입니다.
- 비디오 데이터의 시간적 특성 활용: 비디오 프레임 간의 시간적 상관성을 활용하여, 프레임 별로 변화하는 내용만을 집중적으로 처리할 수 있으며, 이는 시각적으로 연속적이고 일관된 비디오 시퀀스를 생성하는 데 도움이 됩니다.
- 효율적인 학습: 더노이징 네트워크는 공통된 노이즈 패턴을 더 쉽게 학습할 수 있으므로, 보다 효과적인 훈련이 가능하며, 결과적으로 더 나은 더노이징 성능을 달성할 수 있습니다.
어떻게 모션을 학습할 수 있을까?
- 프레임 간 차이 학습: 분해된 확산 모델은 프레임 간의 변화를 학습함으로써 모션을 인식할 수 있습니다. 잔여 노이즈는 이 변화의 양을 캡처하며, 시간에 따른 변화를 모델링합니다.
- 시간적 연속성 모델링: 비록 노이징 과정이 각 프레임마다 개별적으로 이루어지지만, 분해된 확산 모델은 시간적 연속성을 모델링할 수 있는 구조를 가질 수 있습니다. 예를 들어, 이전 프레임에서 학습된 정보를 다음 프레임의 노이징에 사용할 수 있습니다.
- 옵티컬 플로우 및 모션 추정: 일부 확산 모델은 옵티컬 플로우나 모션 추정을 사용하여 프레임 간의 연속성을 이해합니다. 이를 통해 모델은 프레임 사이에서 움직임을 파악하고 잔여 노이즈를 해당 모션에 맞추어 조정합니다.
- 학습된 상관관계: 학습 과정에서 모델은 잔여 노이즈와 모션 사이의 상관관계를 발견하게 됩니다. 모델이 잔여 노이즈를 통해 프레임 간 변화를 예측하고 이해하게 되면, 이를 바탕으로 모션을 더 정확하게 재현할 수 있습니다.
결국, 이러한 모델은 프레임 간의 변화를 추적하고 이를 모션과 연결 짓는 학습 과정을 통해 모션을 학습합니다. 그리고 이를 통해, 각 프레임에 개별적으로 노이즈를 추가하는 것이라도, 시간에 따른 연속성과 동적인 요소를 반영할 수 있는 능력을 갖추게 됩니다.
We call zbφ as the base generator, which is a denoising network of an image diffusion model. It enables us to use a pretrained image generator, e.g. DALL-E 2 [25] and Imagen [27], as the base generator. In this way, we can leverage the image priors of the pretrained image DPM, thereby facilitating the learning of video data
→ image generator의 decoder를 사용 : \(z^b_\phi\)
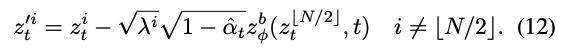
다음식을 residual generator( \(\mathrm{z}^r_{\psi}\) )에 대입
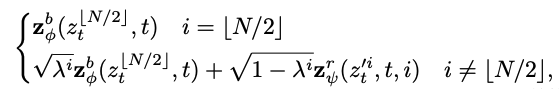
We need to note that the residual generator is conditioned on the frame number i to distinguish different frames.
결국 X0 base noise를 잘 잡아야함. 이미지를 만드는 기초 이기 때문에
- 기준 프레임 설정:
- \(x^0 = x_{⌊N/2⌋}\): 비디오 클립 \(x\)의 중간 프레임을 기준 프레임 \(x^0\)으로 설정합니다. 여기서 \(⌊N/2⌋\)는 비디오 클립의 프레임 수 \(N\)을 2로 나눈 후, 그 결과를 내림한 값입니다.
- \(λ_{⌊N/2⌋} = 1\): 기준 프레임의 \(λ\) 값을 1로 설정함으로써, 기준 프레임이 기본 프레임 \(x^0\)와 완전히 같다는 것을 의미합니다.
- 잠재 변수 \(z_t^i\)에 대한 수식의 간소화:
- \(z_t^i = √α_t x_{⌊N/2⌋} + √(1−α_t)b_t\) (i = ⌊N/2⌋일 때): 기준 프레임에 대한 노이즈 추가 과정은 기본 프레임에 \(√α_t\)를 곱하고, 기본 노이즈 \(b_t\)에 \(√(1−α_t)\)를 곱하여 더합니다.
- \(z_t^i = √α_t x^i + √(1−α_t)(√λ^i b_t + √(1−λ^i)r_t^i)\) (i ≠ ⌊N/2⌋일 때): 기준 프레임이 아닌 다른 프레임들에 대해서는, \(x^i\)와 \(λ^i\)에 따라 계산된 확산 과정을 적용합니다.
- 기본 노이즈 \(b_t\)의 추정:
- 수식 (11)에 따라, 기준 프레임을 이용하여 모든 프레임의 기본 노이즈 \(b_t\)를 한 번의 순방향 패스로 추정할 수 있습니다. 이는 기본 생성기(base generator)라고 불리는, 사전 훈련된 DPM의 역확산(denoising) 기능을 사용하여 이루어집니다.
- 사전 훈련된 이미지 생성기의 사용:
- 저자들은 사전 훈련된 이미지 생성기(예: DALL-E 2, Imagen)를 기반으로 한 기본 생성기를 사용하여 전체 비디오에 대한 기본 노이즈 \(b_t\)를 생성합니다. 이는 이미지 DPM을 사용하여 비디오의 확산 과정을 촉진하는 데 도움이 됩니다.
- 기본 노이즈 제거:
- \(z^i_t\)에서 사전에 추정된 기본 노이즈 \(z^b_{ϕ}(z_t^{⌊N/2⌋}, t)\)를 제거하여 \(z'^i_t\)를 생성합니다. 이는 이미 기본 노이즈가 제거된 더 깨끗한 버전의 잠재 변수를 의미합니다.
- 잔여 노이즈 생성기:
- \(z'^i_t\)를 잔여 생성기 \(z^r_{ψ}\)에 입력으로 제공합니다. 이 생성기는 프레임 번호 \(i\)에 의존적으로 잔여 노이즈 \(r'^i_t\)를 추정합니다. 이미 기본 노이즈 \(b_t\)가 제거되었기 때문에 \(z'^i_t\)는 원래의 \(z^i_t\)보다 노이즈가 적을 것으로 예상됩니다.
- 노이즈 예측:
- 수식 (7)과 (11)을 통해 \(ε^i_t\)의 노이즈를 예측합니다. 이는 잔여 노이즈 생성기 \(z^r_{ψ}\)를 사용하여 \(z'^i_t\)에서 잔여 노이즈를 추정하고, 기본 프레임에서의 노이즈를 다시 더하는 과정입니다.
- 잠재 변수 업데이트:
- \(z^i_t\)는 업데이트되어 다음 잠재 확산 변수로 이동하며, 이 과정은 최종 샘플 \(x^i\)를 얻을 때까지 반복됩니다.
이 과정은 두 가지 중요한 부분으로 나눠서 비디오 더노이징을 처리합니다. 첫 번째 부분인 기본 프레임 \(x^{⌊N/2⌋}\)는 상대적으로 복잡하고 디테일이 풍부하여 더 큰 사전 훈련된 이미지 생성 모델을 사용하여 재구성합니다. 두 번째 부분인 잔여 프레임 \(Δx^i\)는 비교적 학습이 쉽기 때문에 더 작은 네트워크를 사용하여 처리합니다. 이렇게 함으로써 전체적인 방법론의 효율성을 높일 수 있습니다.
종합하면, 이 방법은 기본 프레임에 더 많은 컴퓨팅 자원을 할당하고, 잔여 프레임은 덜 복잡하기 때문에 더 적은 자원을 사용하여 전체 더노이징 프로세스의 효율성과 효과를 극대화합니다.
We attribute this to the domain gap between the image data and video data.
→ 이상과 다르게 고정했을 때 잘 동작하지 않는 부분이 있었다.
Thus it is helpful to simultaneously finetune the base generator $z^b_θ$ on the video data with a small learning rate. We define the final loss function as:

base generator를 이미지로 학습시키고 난 이후에 residual generator를 학습시키는데 residual generator에서도 base generator를 미세 조정을 한다는 거구나
ChatGPT
정확합니다. 기본 생성기(base generator)는 이미지 데이터에 대해 사전 학습된 상태이고, 이후에 비디오 데이터를 처리하기 위해 잔차 생성기(residual generator)가 도입됩니다. 잔차 생성기는 비디오의 각 프레임에 대한 추가적인 디테일을 모델링합니다.
사전 학습된 기본 생성기는 고정된 상태로 사용하는 대신에, 잔차 생성기와 함께 훈련하면서 동시에 미세 조정(finetune)됩니다. 이는 비디오 프레임의 특정 시점에 대해 예측을 더 잘 할 수 있도록 하기 위해서입니다. 잔차 생성기는 비디오 프레임 사이의 차이(예를 들어 움직임이나 시간에 따른 변화)를 학습하며, 기본 생성기의 출력에 이 잔차를 더해 전체 비디오 프레임을 생성합니다.
손실 함수는 비디오 데이터를 기반으로 하여 이 두 생성기가 얼마나 잘 협력하여 결과를 생성하는지를 평가합니다. 미세 조정은 이 손실을 최소화하도록 기본 생성기의 파라미터를 조정하는 방식으로 이루어집니다. 그러나 중요한 것은 이 과정에서 기본 생성기가 과도하게 조정되어 사전에 학습한 정보를 잃어버리지 않도록 주의하는 것입니다. 따라서, 손실 함수에서 사용하는 stop-gradient 연산은 기본 생성기가 업데이트되는 것을 방지하여, 오직 잔차 생성기만이 주요하게 조정되도록 합니다.
기존에는 image를 diffusion model로 생성하고 temporal layer를 따로 두어서 비디오를 만들었는데 이제는 diffusion model에서 한번에 생성되겠네
맞습니다, 여러분이 언급한 접근 방식은 비디오 생성에 있어서 기존의 이미지 생성 모델과 시간적 층(temporal layer)을 결합하는 것과는 다릅니다. 기존 방식에서는 이미지를 생성하는 diffusion 모델과는 별도로 시간적인 변화를 모델링하는 부분이 필요했습니다.
이 새로운 방식은 사전 학습된 이미지 생성 모델(기본 생성기)에 추가적인 구조(잔차 생성기)를 도입하여 비디오 데이터를 직접 처리할 수 있게 합니다. 잔차 생성기는 기본 생성기가 만든 이미지에 시간적인 디테일을 추가함으로써, 한 번에 비디오 프레임을 생성할 수 있습니다. 이렇게 함으로써, 각각의 프레임을 개별적으로 생성한 다음 시간적인 연결성을 부여하는 복잡한 과정 없이, 비디오 내에서 자연스러운 시간적 연속성을 가진 프레임들을 직접 생성할 수 있게 됩니다.
이러한 접근법은 모델이 이미지와 비디오 간의 복잡한 동적 관계를 보다 잘 학습하고 이해하게 함으로써, 향상된 비디오 생성 결과를 얻을 수 있도록 도와줍니다. 또한, 이 방법은 더 나은 일관성과 품질의 비디오를 생성하는 데 도움이 됩니다.
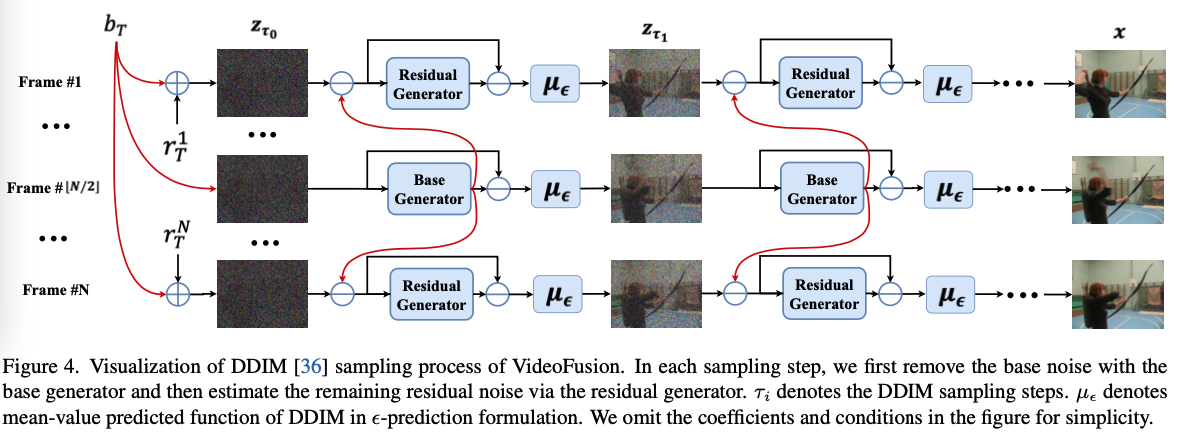
Q : 기준을 중앙이 아니라 가운데로 잡은 이유가 뭘까요? 시간순으로 학습을 하는게 더 상식적인데, 시간순과 시간의 역순을 동시에 학습해야함 → 가운데를 기준으로 loop 가 생길 가능성이 높은 것 아닌가?
Q : 각 프레임 간의 연관성을 어떻게 두는가
이 모델은 프레임 번호 i 에 조건을 부여받는 “잔차 생성기”를 사용하여 각 프레임을 구별합니다.