
[논문분석] TextCraftor: Your Text Encoder Can be Image Quality Controller
Image generaion에서 다양한 Condition을 위한 Finetuning 방법 [Page, Paper] , Code
Abstract
Diffusion-based text-to-image generative models, e.g., Stable Diffusion, have revolutionized the field of content generation, enabling significant advancements in areas like image editing and video synthesis. Despite their formidable capabilities, these models are not without their limitations. It is still challenging to synthesize an image that aligns well with the input text, and multiple runs with carefully crafted prompts are required to achieve satisfactory results. To mitigate these limitations, numerous studies have endeavored to fine-tune the pre-trained diffusion models, i.e., UNet, utilizing various technologies. Yet, amidst these efforts, a pivotal question of text-to-image diffusion model training has remained largely unexplored: Is it possible and feasible to fine-tune the text encoder to improve the performance of text-to-image diffusion models? Our find- ings reveal that, instead of replacing the CLIP text encoder used in Stable Diffusion with other large language mod- els, we can enhance it through our proposed fine-tuning approach, TextCraftor, leading to substantial improvements in quantitative benchmarks and human assessments. Interest- ingly, our technique also empowers controllable image gen- eration through the interpolation of different text encoders fine-tuned with various rewards. We also demonstrate that TextCraftor is orthogonal to UNet finetuning, and can be combined to further improve generative quality.
두가지 문제점
첫째, 제공된 프롬프트와 잘 맞지 않는 이미지를 생성하는 경우가 많습니다[5, 58].
첫 번째 문제를 해결하기 위해 이전 연구에서는 SD에서 사용되는 CLIP 텍스트 인코더[37]를 T5와 같은 다른 대형 언어 모델로 대체하는 방안을 모색했습니다[7, 44]. 그럼에도 불구하고 대규모 T5 모델은 CLIP보다 훨씬 더 많은 매개변수를 가지고 있어 저장 및 계산 오버헤드가 추가로 발생합니다.
둘째, 시각적으로 만족스러운 이미지를 생성하려면 서로 다른 무작위 시드와 수작업 프롬프트 엔지니어링으로 여러 번 다시 실행해야 하는 경우가 많습니다[13, 54].
두 번째 과제를 해결하기 위해 기존 작업에서는 보상 기능을 사용하여 이미지 캡션 데이터 세트와 짝을 이룬 SD에서 사전 학습된 UNet을 미세 조정합니다[8, 35, 57]. 그럼에도 불구하고 제한된 데이터 세트에서 훈련된 모델은 보이지 않는 프롬프트에 대해 고품질 이미지를 생성하는 데 여전히 어려움을 겪을 수 있습니다.
다른 해결시도
pipeline of text-to- image generation 개선 시도
Diffusion model의 U-Net, Text Encoder → 제한이 많음
이번 논문에서 제안하는 바
저희는 사전 학습된 텍스트 인코더를 향상시키기 위한 엔드 투 엔드 미세 조정 기법인 TextCraftor를 제안
쌍을 이루는 텍스트-이미지 데이터 세트에 의존하는 대신, 미학 모델[1] 또는 텍스트-이미지 정렬 평가 모델[24, 55]과 같이 이미지 품질을 자동으로 평가하도록 훈련된 보상 함수를 사용하여 텍스트 인코더를 차별적인 방식으로 개선할 수 있음을 입증
텍스트 크래프터는 훈련 중에 텍스트 프롬프트만 필요하기 때문에 훈련 이미지의 즉각적인 합성을 가능하게 하고 대규모 이미지 데이터 세트의 저장 및 로딩 부담을 덜어줌
- 텍스트 인코더의 미세 조정의 중요성:
- 잘 훈련된 텍스트-이미지 확산 모델에서, 텍스트 인코더를 미세 조정하는 것은 숨겨진 보석과 같으며, 이미지 품질과 텍스트-이미지 정렬에서 상당한 개선을 이끌어낼 수 있습니다. 이는 예를 들어 그림 1과 3에서 확인할 수 있습니다.
- 더 큰 텍스트 인코더, 예를 들어 SDXL을 사용하는 것과 비교할 때, TextCraftor는 추가적인 계산 및 저장 공간 부담을 주지 않습니다. 프롬프트 엔지니어링과 비교했을 때, TextCraftor는 관련 없는 콘텐츠를 생성할 위험을 줄입니다.
- 효과적이고 안정적인 텍스트 인코더 미세 조정 파이프라인 도입:
- 공개 보상 함수에 의해 감독된 안정적인 텍스트 인코더 미세 조정 파이프라인을 소개합니다. 제안된 정렬 제약은 대규모 CLIP 사전 훈련된 텍스트 인코더의 능력과 일반성을 유지하며, TextCraftor를 동시대 예술 중 첫 번째 일반적인 보상 미세 조정 패러다임으로 만듭니다.
- 공개 벤치마크 및 인간 평가에서의 포괄적 평가는 TextCraftor의 우수성을 입증합니다.
- 다양하고 제어 가능한 스타일 생성을 위한 텍스트 임베딩의 활용:
- 다양하게 미세 조정된 및 원래의 텍스트 인코더들에서 나온 텍스트 임베딩을 보간하여 더 다양하고 제어 가능한 스타일 생성을 달성할 수 있음을 보여줍니다.
- TextCraftor는 UNet 미세 조정과 직교적이며, 개선된 텍스트 인코더로 UNet을 추가로 미세 조정함으로써 품질 개선을 보여줍니다.
Related Works
- Text-to-Image Diffusion Models
이 모델에는 몇 가지 한계가 있습니다.
- 생성된 이미지가 제공된 텍스트 프롬프트와 잘 일치하지 않을 수 있습니다.
- 고품질 이미지를 얻으려면 광범위한 프롬프트 엔지니어링과 다양한 무작위 시드를 사용한 여러 번의 실행이 필요할 수 있습니다
- 이러한 문제점을 해결하기 위한 한 가지 잠재적 개선 방안은 안정적 확산 모델에서 사전 학습된 CLIP 텍스트 인코더를 T5로 교체하고 고품질의 페어링 데이터를 사용하여 모델을 미세 조정하는 것입니다
- 그러나 이러한 접근 방식은 상당한 훈련 비용이 발생한다는 점에 유의해야 합니다. 안정 확산 모델을 처음부터 훈련하는 데만 6,250개의 A100 GPU 일수에 해당하는 상당한 리소스가 필요합니다.
이번 모델은 사전 학습된 텍스트-이미지 모델을 개선하는 동시에 계산 비용을 크게 절감합니다.
Automated Performance Assessment of Text-to-Image Models.
텍스트-이미지 변환 모델의 성능을 평가하는 것은 어려운 문제였습니다.
- 초기 방법에서는 이미지 품질을 측정하기 위해 FID와 같은 자동화된 메트릭을 사용하고 텍스트-이미지 정렬을 평가하기 위해 CLIP 점수를 사용했습니다.
- 그러나 후속 연구에 따르면 이러한 점수는 인간의 지각과 제한된 상관관계를 보인다고 합니다[34]. 이러한 불일치를 보완하기 위해 최근 연구에서는 텍스트-이미지 모델의 이미지 품질을 평가하기 위해 특별히 고안된 훈련 모델을 연구하고 있습니다.
- 예를 들어, 사람이 주석을 단 이미지를 활용하여 품질 추정 모델을 학습시키는 ImageReward [57], PickScore [24], 인간 선호도 점수 [55, 56] 등이 있습니다.
Fine-tuning Diffusion Models with Rewards.
사전 학습된 확산 모델의 내재적 한계에 대응하여 이미지 색상, 구도, 배경과 같은 측면에 초점을 맞춰 생성 품질을 높이기 위한 다양한 전략이 제안되었습니다.
- 한 방향은 확산 모델을 미세 조정하기 위해 강화 학습을 활용합니다[3, 12]. 또 다른 영역에서는 보상 기능을 통해 확산 모델을 차별적인 방식으로 미세 조정합니다[57].
- 이러한 추세에 따라 이후 연구에서는 텍스트-이미지 모델[8, 35]을 통해 학습 가능한 LoRA 가중치[20]로 파이프라인을 확장합니다. 본 연구에서는 이전에 탐색되지 않았던 차원인 차등 가능한 방식으로 보상 함수를 사용하여 텍스트 인코더를 미세 조정하는 새로운 탐구에 대해 살펴봅니다.
Improving Textual Representation.
- 또 다른 연구 분야는 사용자가 제공한 텍스트를 개선하여 향상된 품질의 이미지를 생성하는 데 초점을 맞추고 있습니다.
- 연구자들은 LLAMA[53]와 같은 대규모 언어 모델을 사용하여 텍스트 프롬프트를 세분화하거나 최적화합니다. 프롬프트의 품질을 개선함으로써 텍스트-이미지 모델은 더 높은 품질의 이미지를 합성할 수 있습니다.
- 그러나 추가적인 랜더링 모델을 활용하면 계산 및 스토리지 요구 사항이 증가합니다.
- 이 연구는 텍스트 인코더를 미세 조정함으로써 모델이 주어진 텍스트 프롬프트의 미묘한 차이를 파악하여 추가 언어 모델과 관련 오버헤드를 제거할 수 있음을 보여줍니다.
Method
Preliminaries of Latent Diffusion Models
stable diffusion model 사용
\[\underset{\theta}{min} \mathbb{E}_{t∼U[0,1],(\mathbf{x},\mathbf{p})∼p_{data}(\mathbf{x},\mathbf{p}),ε∼N(0,I)} ||\hat{ε}_θ(t,\mathbf{z}_t,\mathbf{c})−\mathbf{ε}||_2 ^2\]Denoising Scheduler – DDIM
\[\mathbf{z}_{t′} =α_{t′} {\mathbf{z}_t −σ_t\hat{\mathbf{\epsilon}}_θ(t,\mathbf{z}_t,\mathbf{c}) \over \alpha_t} + σ_{t′}\hat{\mathbf{\epsilon}}_θ(t,\mathbf{z}_t,\mathbf{c})\]Classifier-Free Guidance
\[\hat{ε} = w\hat{ε}_θ (t, z_t , c) − (w − 1)\hat{ε}_θ (t, z_t , ∅)\]Text Encoder Fine-tuning with Reward Propagation
Directly Fine-tuning with Reward
\[\hat{x}= {z_t −σ_t\hat{ε}_θ(t,z_t,\tau_φ(p)) \over \alpha_t}\]- 확산 과정 정의:
- \(Z_t = \alpha_tX + \sigma_t\epsilon\) : 여기서 \(Z_t\) 는 순방향 확산 과정을 나타내며, \(\alpha_t\) 는 확산 계수, X 는 원본 데이터, \(\epsilon\)은 가우시안 잡음, \(\sigma_t\)는 잡음의 표준 편차입니다.
- 잡음 예측:
- Denoising 과정은 UNet, \(\epsilon_\theta(\cdot)\),을 사용하여 수행되며, 이는 잡음을 예측하는 역할을 합니다. 이러한 과정을 통해 이미지의 원본 데이터를 추정합니다.
- 원본 데이터의 예측:
- 원본 데이터는 다음과 같은 수식으로 예측됩니다:
- \(\hat{X} = \frac{Z_t - \sigma_t\epsilon_\theta(t, Z_t, \tau_\phi(p))}{\alpha_t}\) 여기서 \(\hat{X}\) 는 예측된 원본 샘플입니다. 이 방식은 픽셀 공간 및 잠재 공간 확산 모델 모두에 적용 가능합니다.
- 후처리 및 보상 모델:
- 잠재 공간 확산에서 \(\hat{X}\) 는 VAE 디코더를 통해 후처리되며, 보상 모델에 공급되기 전에 처리됩니다. 이러한 디코딩 과정은 미분 가능하므로 간단히 모델링할 수 있습니다.
- 보상 모델을 이용한 품질 평가 및 최적화:
- 생성된 이미지의 품질을 평가하기 위해 공개 보상 모델 R을 사용하며, 텍스트 인코더와 같은 모델 구성 요소의 최적화를 통해 이미지의 품질을 개선할 수 있습니다.
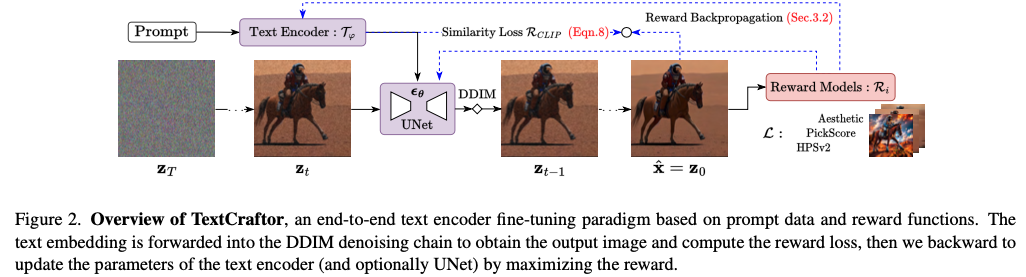
- 손실 함수 정의:
- 손실 함수 \(L(\phi)\)는 보상 모델 R을 사용하여 정의됩니다. 이는 ( R )을 최대화하려는 목표를 가집니다: \(L(\phi) = -R(\hat{x}; \rho)\) 여기서 \(\hat{x}\) 는 예측된 이미지이며, \(\rho\) 는 보상 모델의 파라미터를 나타냅니다.
- 미세 조정과정:
- 미세 조정 과정에서 CLIP 텍스트 인코더의 가중치만 수정되고, UNet 모델은 고정됩니다. 이는 보상 모델을 사용하여 생성된 이미지의 품질을 평가하고 최적화하는 작업을 수행하기 위한 것입니다.
- 노이즈의 영향 고려:
- 초기(노이즈가 많은) 시간 단계에서 생성된 이미지 \(\hat{x}\) 는 부정확하고 신뢰도가 낮을 수 있습니다. 이로 인해 예측된 보상이 의미가 덜하게 됩니다.
- Liu 등[27]은 노이즈가 있는 잠재 상태 \(Z_t\) 에 직접 미세 조정을 적용하는 대신 보다 신뢰할 수 있는 접근 방식을 제안합니다.
Discussion
- 직접적인 미세 조정은 일반적인 확산 모델의 훈련 체계와 유사합니다. 이는 텍스트-이미지 쌍 데이터를 사용하여 보상을 예측하는 과정을 포함합니다.
- 논의된 방식은 다양한 공개적으로 이용 가능한 보상 모델을 활용하여, 연구의 유연성과 지속 가능성을 높이고자 합니다.
Prompt-Based Fine-tuning
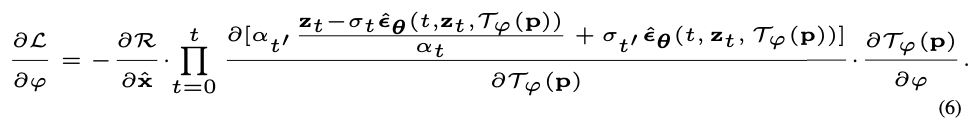
수식 분석:
\[\frac{\partial L}{\partial \phi} = -\sum_{t=0}^{T} \frac{\partial R}{\partial \hat{x}} \cdot \frac{\partial \hat{x}}{\partial \phi}\]여기서,
- \(L(\phi)\)는 손실 함수입니다.
- \(R\) 은 보상 함수로, 생성된 이미지의 품질을 평가합니다.
- \(\hat{x}\) 는 예측된 이미지로, 식에서는 \(Z_t - \sigma_t \epsilon_{\theta}(t, Z_t, \tau_{\phi}(p)) / \alpha_t\) 와 같이 정의됩니다.
수식 도출 과정:
- 보상 함수의 미분:
- 보상 함수 (R)은 예측된 이미지 \(\hat{x}\) 에 의존하므로, \(\hat{x}\) 의 변화에 따라 R 의 값이 어떻게 변하는지를 나타내는 \(\frac{\partial R}{\partial \hat{x}}\) 항이 필요합니다.
- 예측된 이미지의 미분:
- \(\hat{x} \ 는 \ \ \ Z_t, \epsilon_{\theta}(t, Z_t, \tau_{\phi}(p)), \sigma_t, 및 \ \ \alpha_t\) 에 의존하므로, 이 변수들을 통해 \(\phi\) 에 대한 미분을 계산합니다. 이 과정에서 체인 룰을 사용하여 \(\frac{\partial \hat{x}}{\partial \phi}\) 를 구합니다.
- 체인 룰 적용:
- 손실 함수 L에 대한 \(\phi\)의 미분은, R에 대한 \(\hat{x}\)의 미분과 \(\hat{x}\)에 대한 \(\phi\)의 미분의 곱을 시간 t에 대해 누적한 것과 동일합니다. 이를 통해 각 파라미터 \(\phi\)가 최종 손실 값에 미치는 영향을 계산할 수 있습니다.
수식의 구성 및 각 변수의 의미:
- \(\frac{\partial L}{\partial \phi}\) : 손실 함수 L에 대한 파라미터 \(\phi\)의 그래디언트입니다. 이 값은 파라미터 \(\phi\)를 어떻게 조정해야 손실 L을 줄일 수 있는지를 알려줍니다.
- R : 보상 함수로, 생성된 이미지 \(\hat{x}\)의 품질을 평가합니다. R의 값이 높을수록 이미지의 품질이 좋다고 평가된 것입니다.
- \(\hat{x}\): 예측된 이미지입니다. 이 이미지는 모델의 출력으로, 주어진 입력 데이터와 모델 파라미터에 따라 달라집니다.
- \(\frac{\partial R}{\partial \hat{x}}\): 보상 함수 R을 예측된 이미지 \(\hat{x}\)에 대해 미분한 값입니다. 이는 \(\hat{x}\)의 작은 변화가 \(R\)에 어떤 영향을 미치는지를 나타냅니다.
- \(\frac{\partial \hat{x}}{\partial \phi}\): 예측된 이미지 \(\hat{x}\)를 모델 파라미터 \(\phi\)에 대해 미분한 값입니다. 이는 \(\phi\)의 변화가 \(\hat{x}\)에 어떻게 영향을 미치는지 보여줍니다.
미분의 사용 이유 및 방법:
- 미분 사용: 미분을 사용하는 이유는 모델의 출력인 \(\hat{x}\)와 최종 목표인 보상 R이 파라미터 \(\phi\)의 작은 변화에 어떻게 반응하는지 정량적으로 평가하기 위해서입니다. 미분값은 파라미터의 변화가 결과에 미치는 민감도를 측정합니다.
- 곱셈의 의미: \(\frac{\partial R}{\partial \hat{x}}\)과 \(\frac{\partial \hat{x}}{\partial \phi}\)를 곱하는 이유는 연쇄 법칙(Chain Rule)을 적용하여, 파라미터 \(\phi\)가 최종 보상 R에 미치는 영향을 계산하기 위해서입니다. 이 곱셈은 파라미터 변경이 보상에 어떻게 전파되는지를 나타냅니다.
- 합으로 계산하는 이유: t=0에서 T까지 모든 시간 단계에 대해 그래디언트를 누적하는 이유는 각 시간 단계에서의 변경이 최종 파라미터 \(\phi\)에 미치는 영향을 전체적으로 반영하기 위함입니다. 모든 시간 단계에서 발생하는 그래디언트의 영향을 종합하여 파라미터를 업데이트하는 것이 더 안정적이고 효과적인 학습을 도모합니다.
이 과정은 모델을 효과적으로 학습시키고, 최적의 성능을 달성하기 위해 필수적인 요소입니다. 그래디언트 기반 최적화는 딥 러닝과 머신 러닝에서 가장 흔히 사용되는 기법 중 하나로, 파라미터를 조정하여 원하는 목표(이 경우에는 높은 보상 점수)를 달성하도록 합니다.
메모리 문제의 원인
식 6에 제시된 과정은, 각 시간 단계에서 계산 그래프를 역전파 체인에 누적시키므로, 초기 (노이즈가 많은) 시간 단계에서 메모리를 많이 사용합니다. 이는 계산 그래프가 모든 연산과 중간 값들을 저장해야 하기 때문에 발생합니다.
그래디언트 체크포인팅
이 문제를 해결하기 위해, ‘그래디언트 체크포인팅’ 기술이 사용됩니다. 이 기술은 메모리 사용량을 계산량과 교환함으로써, 필요할 때만 중간 결과를 다시 계산하고 저장합니다. 이 방법은 모델의 훈련을 보다 메모리 효율적으로 만들어 주면서도 필요한 역전파 계산을 수행할 수 있도록 합니다.
훈련 과정의 특징
- 중간 결과는 즉석에서 계산되므로, 훈련은 하나의 단계씩 해결되는 문제로 볼 수 있습니다. 이는 각 단계가 독립적으로 처리되며, 필요한 계산만 수행되어 메모리 효율이 높아집니다.
- 그러나, 그래디언트 체크포인팅을 사용하더라도, 초기 단계에서는 그라데이션 폭발과 소실 문제로 인해 여전히 어려움을 겪을 수 있습니다.
추가 분석 및 시각화
- 섹션 4.2에서는 단계 선택에 대한 자세한 분석을 제공하며, 제안된 프롬프트 기반 보상 미세 조정에 대한 추가 설명이 그림 2와 알고리즘 1에서 제공됩니다. 이는 시각적 자료와 함께 보다 구체적인 설명을 통해 이해를 돕습니다.

Loss Function
이 문서의 섹션 3.3은 여러 보상 함수를 사용하여 모델을 미세 조정하는 방법과 그에 따른 손실 함수 \(L_{\text{total}}\) 에 대해 설명하고 있습니다. 여러 보상 함수를 결합함으로써 더 강력하고 다양한 학습 신호를 모델에 제공할 수 있지만, 주의 깊은 조정이 필요하다는 점을 강조하고 있습니다.
손실 함수 \(L_{\text{total}}\)
- 식 7에서 손실 함수는 여러 보상 함수 \(R_i\) 의 가중합으로 정의됩니다. \(L_{\text{total}} = \sum_i \gamma_i R_i(\hat{x}_i; p)\) 여기서 \(\gamma_i\) 는 각 보상 함수의 가중치이며, 이를 통해 다양한 보상 함수들의 영향력을 조절할 수 있습니다.
주의 사항
- 보상 함수의 한계: 특정 보상 함수는 자체적으로 특정 범위 또는 특성에 제한될 수 있으며, 이로 인해 모델이 특정 측면만을 과도하게 학습할 수 있습니다. 이는 모드 붕괴(mode collapse)나 기억 상실(catastrophic forgetting) 같은 문제를 일으킬 수 있습니다.
- 개별 보상 함수의 한계: 하나의 보상 함수만 사용하는 경우, 모델이 특정 유형의 데이터에 지나치게 특화되어 다양성이 떨어질 수 있습니다.
해결 방안
- 다양한 보상 함수의 조합: 여러 보상 함수를 조합함으로써 모델이 다양한 특성을 학습하고, 보다 일반화된 성능을 발휘하도록 유도할 수 있습니다.
- 조기 종료 (early stopping): 과적합을 방지하고 모델이 너무 특정 보상 함수에 특화되는 것을 방지하기 위해 조기에 훈련을 중단하는 방법이 사용될 수 있습니다.
CLIP 공간 유사성
- 식 8에서는 CLIP 공간에서의 유사성을 항상 온라인 제약으로 설정합니다. \(R_{\text{CLIP}} = \cos(\text{sim}(\mathcal{T}(x), \tau_p(p)))\) 여기서 \(\mathcal{T}\) 는 이미지의 CLIP 인코더, \(\tau_p\) 는 텍스트의 CLIP 인코더입니다. 이는 텍스트 임베딩과 이미지 임베딩 사이의 코사인 유사성을 최대화하여, 텍스트와 이미지 사이의 의미적 일치를 높이는 것을 목표로 합니다.
결론
이 접근 방법은 모델이 더 넓은 범위의 데이터에 대해 일반화된 학습을 수행할 수 있도록 지원하며, 특정 도메인에만 과적합되는 것을 방지합니다. CLIP 공간 유사성을 통해 텍스트와 이미지 사이의 일치도를 강화하고, 이를 통해 모델의 실제 성능을 향상시킬 수 있습니다.
-
두 loss식의 차이점
제공된 두 식은 각각 모델의 손실 함수를 정의하고, 그 손실 함수에 대한 파라미터의 그래디언트를 계산하는 데 사용되는 식입니다. 두 식은 모델 최적화 과정에서 각기 다른 목적과 역할을 수행합니다.
### 1. 손실 함수 정의 \(L_{\text{total}}\)
\[L_{\text{total}} = \sum_i \gamma_i R_i(\hat{x}_i; p)\]- 목적: 이 식은 모델의 총 손실 함수를 정의합니다. 여러 개의 보상 함수 \(R_i\) 를 사용하여 각각의 보상 함수에 대한 결과를 가중합하여 전체 손실을 계산합니다.
- 변수 설명:
- \(\gamma_i\) 는 각 보상 함수의 중요도를 조절하는 가중치입니다.
- \(R_i\) 는 보상 함수로, 예측된 이미지 \(\hat{x}_i\) 와 텍스트 프롬프트 p에 대한 성능을 평가합니다.
- 이 식은 다양한 요소들을 조합하여 모델의 성능을 다각도로 평가하고, 여러 목표를 동시에 최적화하려는 의도를 반영합니다.
### 2. 그래디언트 계산식
\[\frac{\partial L}{\partial \phi} = -\sum_{t=0}^{T} \frac{\partial R}{\partial \hat{x}} \cdot \frac{\partial \hat{x}}{\partial \phi}\]- 목적: 이 식은 손실 함수 \(L\)에 대한 파라미터 \(\phi\)의 그래디언트를 계산합니다. 이 그래디언트는 파라미터를 업데이트하는 데 사용되며, 모델을 최적화하는 기본적인 메커니즘입니다.
- 변수 설명:
- \(\frac{\partial R}{\partial \hat{x}}\) 는 보상 함수 \(R\)를 예측된 이미지 \(\hat{x}\)에 대해 미분한 값으로, \(\hat{x}\)의 작은 변화가 보상 함수에 미치는 영향을 나타냅니다.
- \(\frac{\partial \hat{x}}{\partial \phi}\)는 예측된 이미지 \(\hat{x}\)를 파라미터 \(\phi\)에 대해 미분한 값으로, 파라미터의 변화가 최종 이미지에 어떤 영향을 미치는지 보여줍니다.
### 두 식의 차이점
- 용도의 차이: 첫 번째 식은 모델의 손실을 계산하는 데 사용되며, 다양한 목표를 반영하는 종합적인 손실 값을 제공합니다. 두 번째 식은 이 손실 함수를 기반으로 파라미터를 어떻게 조정해야 할지를 계산하는 데 사용됩니다.
- 계산의 차이: 첫 번째 식은 직접적인 손실 값을 계산하는 반면, 두 번째 식은 손실 함수의 파라미터에 대한 감도(미분)를 계산하여, 이를 통해 파라미터 업데이트 방향과 크기를 결정합니다.
이 두 식은 모델 훈련과 최적화 과정에서 상호 보완적으로 작용하며, 모델의 성능을 향상시키기 위한 중요한 역할을 수행합니다.
UNet Fine-tuning with Reward Propagation
- 직교성(Orthogonality):
- 텍스트 인코더와 UNet은 서로 독립적으로, 또는 유사한 학습 목표를 가지고 최적화될 수 있습니다. 이는 두 시스템이 서로 영향을 주지 않으면서도 각각의 성능을 독립적으로 향상시킬 수 있음을 의미합니다.
- 미세 조정 방법:
- UNet의 미세 조정은 안정된 확산(Stable Diffusion)에서 사전 훈련된 UNet을 기반으로 진행됩니다. 이는 텍스트-이미지 생성 작업 외에도 다른 하류 작업에 UNet을 사용할 수 있게 합니다.
- 도메인 이동을 피하고 기존의 특성을 유지하기 위해, 미세 조정된 텍스트 인코더 \(\tau_{\phi}\) 는 고정된 채로 유지하고, UNet의 파라미터 \(\theta\) 만을 최적화합니다.
- 학습 목표:
- UNet의 학습 목표는 식 6과 유사하게 설정됩니다. 이는 UNet 파라미터 \(\theta\) 의 최적화를 통해 이루어지며, 이 과정에서 \(\epsilon_{\theta}\) , 즉 노이즈 예측 네트워크의 파라미터를 중점적으로 조정합니다.
실용적 적용
이 접근 방식은 텍스트 인코더와 UNet이 각각 최적화될 수 있도록 함으로써, 전체 시스템의 유연성과 적용 범위를 넓힙니다. 예를 들어, 텍스트 인코더가 특정 유형의 텍스트 데이터에 대해 더 잘 최적화되도록 할 수 있으며, 동시에 UNet은 다양한 이미지 처리 작업에 적합하도록 조정될 수 있습니다. 이러한 분리된 최적화 방식은 전체 모델의 성능을 향상시키고, 특정 도메인이나 작업에 대한 과적합을 방지할 수 있습니다.
결론적으로, 이 섹션은 UNet을 이용한 미세 조정이 기존의 텍스트-이미지 생성 작업 뿐만 아니라 다양한 시각적 작업에 유연하게 적용될 수 있도록 하는 방법론을 제시하고 있습니다.