
TDNN (Time Delay Neural Network)
TDNN(Time Delay Neural Network, 시차 신경망)은 순차적인(sequential) 데이터, 특히 음성 신호와 같은 시계열(time-series) 데이터의 패턴을 효과적으로 인식하기 위해 설계된 인공 신경망 아키텍처입니다. 1989년 알렉스 와이벨(Alex Waibel)과 동료들에 의해 처음 제안되었으며, 특히 음성 인식 분야에서 중요한 발전을 이끌었습니다.
TDNN의 핵심 아이디어는 시간적 이동에 불변한(시간 관점 : time-equivariant(Invariant) 위치 관점 : shift-invariant) 특징을 학습하는 것입니다. 이는 가중치 공유(Weight Sharing)를 통해 위치 정보를 보존하며 특징을 추출(time-equivariant)하고, 최종적으로 풀링(Pooling)을 통해 위치 정보를 제거하여 불변성(shift-invariant)을 획득하는 두 단계의 과정으로 이해할 수 있습니다. 즉, 특정 패턴이 시퀀스의 어느 시점에 나타나더라도 이를 동일한 패턴으로 인식하는 능력을 갖추는 것을 목표로 합니다. 사실상 1차원 CNN으로 간주할 수 있습니다.
1. TDNN의 핵심 개념: 시간 지연과 가중치 공유
TDNN은 어떻게 시간의 흐름을 처리하고 이동 불변성을 획득할까요? 이는 두 가지 핵심 메커니즘을 통해 이루어집니다.
-
시간 지연(Time Delay)과 로컬 수용장(Local Receptive Field): 일반적인 완전 연결 신경망(Fully Connected NN)과 달리, TDNN의 뉴런은 이전 계층의 모든 뉴런과 연결되지 않습니다. 대신, 특정 시간대의 뉴런은 이전 계층의 제한된 시간 범위(window) 내에 있는 뉴런들과만 연결됩니다. 예를 들어, 한 뉴런이
t-2, t-1, t시점의 입력만 보도록 설계하는 것입니다. 이 ‘창문’을 통해 국소적인 시간 패턴을 포착하며, 이를 ‘로컬 수용장’이라고 합니다. -
가중치 공유(Weight Sharing): 이것이 TDNN의 가장 중요한 특징입니다. 하나의 로컬 수용장에 적용되는 가중치(필터)가 시간 축을 따라 이동하며 동일하게 적용됩니다. 즉,
t시점에서 패턴을 감지하는 데 사용된 가중치 세트가t+1,t+2등 다른 모든 시점에서도 똑같이 재사용됩니다. 이는 마치 CNN에서 하나의 필터(커널)가 이미지의 모든 위치를 훑으며 특징을 추출하는 것과 완벽하게 동일한 원리입니다.
이러한 가중치 공유 덕분에, 모델은 학습해야 할 파라미터 수를 크게 줄일 수 있으며, 특정 패턴이 시퀀스의 어느 위치에 나타나더라도 이를 안정적으로 감지하는 ‘time-equivariant’ 특징을 자연스럽게 학습하게 됩니다. 그리고 이렇게 추출된 동변성 특징들을 후속 풀링(Pooling) 단계에서 종합하여 최종적인 이동 불변성(shift-invariant)을 완성합니다.
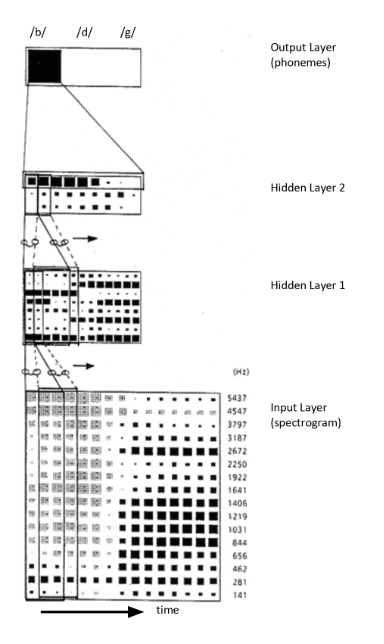
TDNN의 기본 구조 예시 (출처: Wikipedia)
2. TDNN의 구조와 작동 원리
TDNN의 구조는 일반적으로 입력층, 하나 이상의 은닉층, 그리고 출력층으로 구성됩니다.
-
입력층 (Input Layer): 음성 인식의 경우, 음성 신호를 짧은 프레임으로 자르고 각 프레임에서 추출한 특징 벡터(예: MFCC)의 시퀀스가 입력으로 들어옵니다. 예를 들어,
[... x_{t-2}, x_{t-1}, x_t, x_{t+1}, x_{t+2}, ...]와 같은 형태입니다. - 은닉층 (Hidden Layers):
- 첫 번째 은닉층의 뉴런들은 입력층의 특정 시간 윈도우(예: 3개 프레임)에 연결됩니다. 예를 들어, 은닉층의
t시점 뉴런은 입력층의[x_{t-1}, x_t, x_{t+1}]을 입력으로 받습니다. - 이때
t시점 뉴런에 적용된 가중치는t+1시점 뉴런이[x_t, x_{t+1}, x_{t+2}]를 처리할 때도 동일하게 사용됩니다(가중치 공유). - 더 깊은 은닉층은 이전 은닉층의 출력을 다시 특정 시간 윈도우로 묶어 입력으로 받습니다. 이를 통해 계층이 깊어질수록 더 넓은 시간대의 추상적인 특징을 학습할 수 있습니다. 예를 들어, 두 번째 은닉층은 더 긴 시간(예: 5~7개 프레임)에 걸친 음소(phoneme) 수준의 패턴을 인식할 수 있습니다.
- 첫 번째 은닉층의 뉴런들은 입력층의 특정 시간 윈도우(예: 3개 프레임)에 연결됩니다. 예를 들어, 은닉층의
- 출력층 (Output Layer)과 풀링(Pooling):
- 여러 은닉층을 거쳐 추출된 시간 동변성(time-equivariant) 특징들은 시간 축에 따라 펼쳐져 있는 상태입니다. 즉, “어떤 특징이 어느 시점에 나타났는지”에 대한 위치 정보를 포함하고 있습니다. 최종적인 분류(예: 단어 인식)를 위해서는 이 위치 정보를 제거하고 전체 시퀀스를 요약하는 과정이 필요한데, 이것이 바로 풀링(Pooling)의 역할입니다.
- 풀링은 시간 축에 걸쳐 나타난 특징들을 하나의 고정된 크기 벡터로 압축(요약)하는 과정입니다. 가장 널리 쓰이는 방법은 전역 평균 풀링(Global Average Pooling)으로, 시간 축 전체에 대한 특징들의 평균을 구해 위치 정보를 효과적으로 제거하고 시퀀스 전체를 대표하는 특징 벡터를 만듭니다.
이 과정을 통해 모델은 음소나 단어의 등장 ‘시점’과는 무관하게 최종적인 분류를 수행할 수 있는 이동 불변성(Shift-Invariant)을 확보하게 됩니다.
3. TDNN과 다른 신경망 모델과의 비교
| 모델 | 컨텍스트 처리 방식 | 주요 특징 | 장점 | 단점 |
|---|---|---|---|---|
| TDNN | 고정된 크기의 컨텍스트 윈도우 | 가중치 공유, 이동 불변성 (1D CNN과 유사) | 계산 효율성이 높음, 국소적 패턴 학습에 강력함 | 컨텍스트 윈도우 밖의 장기 의존성 학습에 한계가 있음 |
| RNN | 이전의 모든 시점 정보를 순환적으로 전달 | 순환 연결, 은닉 상태(Hidden State)를 통한 메모리 | 가변 길이 시퀀스 처리 가능, 이론적으로 무한한 컨텍스트 | 그래디언트 소실/폭주 문제, 장기 의존성 학습 어려움 |
| CNN | 고정된 크기의 로컬 필터(커널) | 가중치 공유, 이동 불변성 (주로 2D/3D 공간) | 공간적 계층 구조 학습에 매우 효과적 | 시계열 데이터의 순서 정보 자체를 모델링하진 않음 |
결론적으로 TDNN은 본질적으로 1차원 CNN입니다. 역사적으로 음성 인식 분야에서 시간적 특징을 다루기 위해 ‘TDNN’이라는 이름으로 먼저 발전했지만, 그 핵심 원리는 CNN과 같습니다. RNN과는 컨텍스트를 처리하는 방식에서 근본적인 차이가 있는데, TDNN은 ‘고정된 창문’을 통해 보는 반면, RNN은 이전의 모든 정보를 ‘요약’하여 계속 전달하는 방식입니다.
4. TDNN의 진화: TDNN-F와 최신 동향
초기 TDNN은 음성 인식 분야에서 큰 성공을 거두었지만, 더 효율적이고 성능 좋은 모델을 위한 연구가 계속되었습니다.
-
TDNN-F (Factored TDNN): 최신 음성 인식 시스템(특히 Kaldi 툴킷)에서 널리 사용되는 중요한 변형입니다. TDNN-F의 핵심은 TDNN 계층의 가중치 행렬을 두 개의 더 작은 행렬로 분해(factorize)하는 것입니다. 이는 특이값 분해(SVD)와 유사한 원리를 적용한 것으로, 모델의 전체 파라미터 수를 크게 줄이면서도 성능은 유지하거나 오히려 향상시키는 효과를 가져옵니다. 이로 인해 더 깊고 넓은 네트워크를 효율적으로 훈련할 수 있게 되었습니다.
-
ECAPA-TDNN: 화자 인식(Speaker Verification) 분야에서 최첨단 성능을 보이는 모델 중 하나입니다. 기존 TDNN 구조에 채널 주의(Channel Attention), 전파(Propagation), 집계(Aggregation) 메커니즘을 강조하여 더 정교하고 강력한 화자 임베딩을 추출합니다. (관련 논문 링크)
5. 장점 및 단점
장점
- 계산 효율성: RNN에 비해 병렬 처리가 용이하여 훈련 속도가 빠릅니다.
- 강력한 지역 패턴 학습: 고정된 윈도우 내의 지역적인 패턴(예: 음소)을 학습하는 데 매우 효과적입니다.
- 이동 불변성: 가중치 공유 덕분에 패턴의 위치 변화에 강건한 모델을 만들 수 있습니다.
단점
- 제한된 컨텍스트: 컨텍스트 윈도우의 크기가 고정되어 있어, 윈도우보다 훨씬 긴 장기 의존성(long-term dependency)을 학습하는 데에는 명백한 한계가 있습니다. (이 부분은 LSTM, GRU, Transformer 등이 강점을 가집니다.)
- 하이퍼파라미터 민감성: 윈도우 크기를 어떻게 설정하느냐가 모델 성능에 큰 영향을 미칩니다.