
[논문분석] TREE-CONSTRAINED POINTER GENERATOR FOR END-TO-END CONTEXTUAL SPEECH RECOGNITION
automatic speech recognition (ASR) 분야에서 Contextual Biasing을 통합하는 모델 구조 제안
중요 단어 목록(Biasing list)에 있는 단어의 확률에 집중 하는 TCPGen 모듈
힌트를 주입하여 모델의 판단에 ‘영향’을 주는 것이 아니라, 아예 힌트 목록에서 정답을 ‘복사’해오거나 ‘가리키는(point)’ 별도의 네트워크를 두는 방식
ABSTRACT
Contextual knowledge is important for real-world automatic speech recognition (ASR) applications. In this paper, a novel tree-constrained pointer generator (TCPGen) component is proposed that incorporates such knowledge as a list of biasing words into both attentionbased encoder-decoder and transducer end-to-end ASR models in a neural-symbolic way. TCPGen structures the biasing words into an efficient prefix tree to serve as its symbolic input and creates a neural shortcut between the tree and the final ASR output distribution to facilitate recognising biasing words during decoding. Systems were trained and evaluated on the Librispeech corpus where biasing words were extracted at the scales of an utterance, a chapter, or a book to simulate different application scenarios. Experimental results showed that TCPGen consistently improved word error rates (WERs) compared to the baselines, and in particular, achieved significant WER reductions on the biasing words. TCPGen is highly efficient: it can handle 5,000 biasing words and distractors and only add a small overhead to memory use and computation cost.
Index Terms— pointer generator, contextual speech recognition, attention-based encoder-decoder, transducer, end-to-end
1. INTRODUCTION
AED(Attention-based Encoder-Decoder) 및 RNN-T(Transducer) 모델에 적용
문제점
- 기존 End-to-End 음성 인식 모델은 테스트 시점에 동적으로 주어지는 Contextual information를 통합하기 어려움.
- 문맥 정보에 포함된 단어들은 희귀하지만 내용 전달에 중요함.
- 기존 포인터 생성기(Pointer Generator) 방식은 편향 목록이 클 때 메모리 비효율성 문제가 있음.
작동 방식
- TCPGen은 ‘중요 단어 목록(biasing list)’을 symbolic prefix tree로 구성함.
- 디코딩 각 단계에서 문맥 정보와 디코더 상태를 기반으로 별도의 출력 확률 분포(TCPGen distribution)를 계산함.
- 또한, 생성 확률(generation probability)을 예측하여 원래 모델의 출력 분포와 TCPGen의 분포를 보간(interpolate)함.
- 이러한 방식으로 ‘중요 단어 목록’과 최종 출력 사이에 neural shortcut을 형성함.
장점
- 대용량 ‘중요 단어 목록’을 접두사 트리로 관리하여 메모리 및 계산 효율성을 높임.
- 기존 포인터 생성기와 달리, 단어(whole-word) 단위가 아닌 서브워드(subword) 단위 출력이 가능함.
- 신경망 방식과 기호적 방식의 장점을 결합함.
기존의 DB(Deep Biasing) 및 SF(Shallow Fusion) 방식 대비 단어 오류율(WER)이 향상
Related Work
3. TREE-CONSTRAINED POINTER GENERATOR
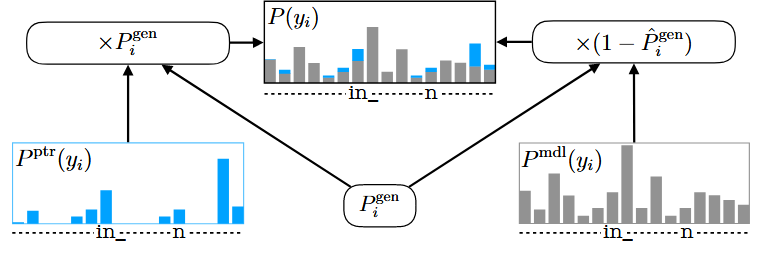
Fig. 1. Illustration of interpolation in TCPGen with corresponding terms in Eqn. (8). P ptr(yi) is the TCPGen distribution. P mdl(yi) is the distribution from a standard end-to-end model. P (yi) is the final output distribution. Pˆgen i and P gen i are the scaled and unscaled generation probabilities.
- $y_{1:i-1}$ 이전 입력 과 중요 단어들로 만든 prefix tree를 보고 다음에 올 가능성이 높은 $y_i$ 값을 예측
- 줄여진 후보들 중에서, 현재 음성 및 문맥 정보와 가장 잘 맞는 단어 조각이 무엇인지 선택
Prefix Tree
수천 개에 달할 수 있는 ‘중요 단어 목록’을 매우 효율적으로 검색하기 위한 자료구조
[Turin, Turn]이라는 단어가 있다면, Tur라는 단어 조각(subword)까지는 경로가 같음
전체 단어 목록을 매번 검색할 필요 없이, 현재 디코딩 상태에서 가능한 후보군을 극도로 좁힘 → 계산 효
이 유효한 후보들의 집합을 논문에서는 Y_tree 라 부름
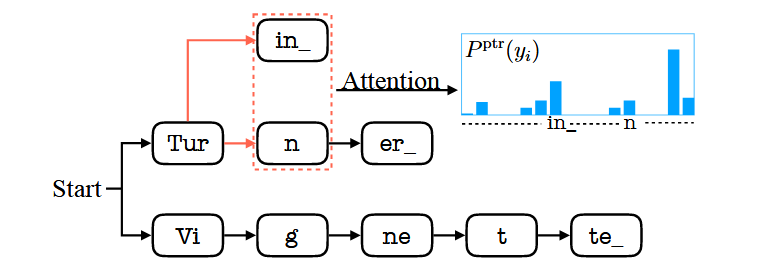
Fig. 2. An example of prefix tree search and attention in TCPGen. With previous output Tur, in and n are two valid word pieces on which attention will be performed. A word end unit is denoted by .
Pointer Network
현재 음성 및 디코딩 정보(query)를 바탕으로, 접두사 트리(Y_tree)에 있는 후보 단어 조각들 중에서 어떤 것이 가장 적합한지 ‘가리키는(pointing)’ 역할
- $q_i$ (Query): 현재 디코딩 상태를 요약한 벡터
- $K$ (Key): subword 전체 집합
- $q_iK^T / \sqrt{d}$ : Attention 메커니즘으로 유사도 계산
- Mask : 접두사 트리(
Y_tree)에 포함되지 않은 단어 조각들의 유사도 점수를 강제로 0으로 만듬 - $P_{ptr}$ (포인터 확률): 마스킹 후 남은 후보들 중에서 Softmax 함수를 통해 최종 확률 분포를 계산 → TCPGen이 예측한 결과
- $h_{ptr}$: 이 확률 분포를 가중치로 사용하여 각 단어 조각의 값(
vj) 벡터들을 합친 결과물로, TCPGen의 예측 정보를 담고 있는 벡터
Generation Probability
기본 ASR 모델의 예측과 TCPGen의 예측 중 어느 쪽을 더 신뢰할지 결정하는 ‘스위치’ 역할
in AED
\[P_{\text{gen}, i} = \sigma(W_{\text{gen}}[h_{\text{dec}, i} ; h_{\text{ptr}, i}])\]in RNN-T
\[P_{\text{gen}, i, t} = \sigma(W_{\text{gen}}[h_{\text{joint}, i, t} ; h_{\text{ptr}, i, t}])\]$P_{gen}$ : 0과 1 사이의 값, 1에 가까우면 TCPGen에 가중치, 0에 가까우면 ASR 모델에 가중치
기본 모델의 상태($h_{dec}$ 또는 $h_{joint}$)와 TCPGen의 예측 결과($h_{ptr}$)를 종합하여 계산되므로, 현재 상황에 맞춰 동적으로 조절
\[\hat{P}{\text{gen}, i} = P{\text{gen}, i} (1 - P_{\text{ptr}}(\text{OOL}))\]$P_{gen}$ (Generator Probability): TCPGen이 계산한 ‘순수한’ 신뢰도
$\hat{P}{gen}$ (Scaled Generator Probability)** : **$P{gen}$을 현실적으로 조정한 값, ‘목록에 없음(OOL, Out-Of-List)’ 확률을 미리 빼서 스위치 값을 조절하는 것
조정된 신뢰도 = 원본 신뢰도 × (1 - 목록에 없음 확률)
Interpolation
\[P(y_i) = P_{\text{mdl}}(y_i)(1 - \hat{P}_{\text{gen}, i}) + P_{\text{ptr}}(y_i)P_{\text{gen}, i}\]P(yi) (최종 확률) = P_mdl (기본 모델 확률) × (1 - P_gen) + P_ptr (TCPGen 확률) × P_gen
AED (Attention-based Encoder-Decoder) 모델
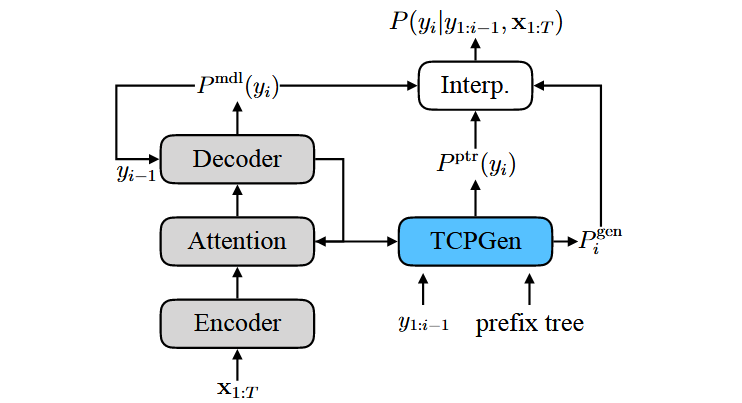
Fig. 3. TCPGen component integrated in AED where Interp. corresponds to the interpolation in Eqn. (8).
쿼리(Query) 계산
\[q_i = W_{Q_c} c_i + W_{Q_y} y_{i-1}\]키(Key) 및 밸류(Value) 계산
\[k_j = W_K y_j\ \ , \ \ v_j = W_V y_j\]생성 확률(Generation Probability) 계산
\[P_{\text{gen}, i} = \sigma(W_{\text{gen}}[h_{\text{dec}, i} ; h_{\text{ptr}, i}])\]기본 모델 출력 확률 (Deep Biasing 적용 시)
\[P_{\text{mdl}}(y_i) = \text{Softmax}(W_O[h_{\text{dec}, i} ; c_i] + W_{db}h_{db,i})\]RNN-T (Recurrent Neural Network Transducer) 모델
RNN-T는 AED와 달리 별도의 contextual vector가 없음
대신, 인코더의 각 시간대(time-step)별 은닉 상태($h_{enc_t}$)와 예측기(predictor)의 직전 토큰($y_{i-1}$)을 합쳐서 Query를 만듬 (현재 시점의 음향 정보와 직전 단어 정보)
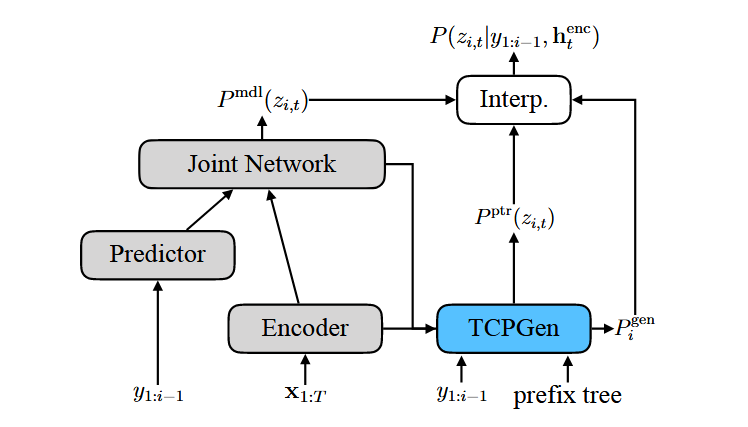
Fig. 4. TCPGen component in the RNN-T model. The Interp. module corresponds to the interpolation in Eqns. (8) and (15).
쿼리(Query) 계산
\[q_{i,t} = W_{Q_c} h_{\text{enc}, t} + W_{Q_y} y_{i-1}\]생성 확률(Generation Probability) 계산
\[P_{\text{gen}, i, t} = \sigma(W_{\text{gen}}[h_{\text{joint}, i, t} ; h_{\text{ptr}, i, t}])\]최종 출력 확률 보간
\[P(z_{i,t}) = \begin{cases} P_{\text{mdl}}(\emptyset), & \text{if } z_{i,t} = \emptyset \\ P'(z_{i,t}), & \text{otherwise} \end{cases}\]∅ (blank) : context list에 없는 경우
∅이 아닐 경우에만 TCPGen과의 확률 보간을 수행하고, ∅일 경우에는 원래 모델의 확률을 그대로 사용
4. EXPERIMENTAL SETUP
Data : Librispeech
데이터 증강: SpecAugment 기법을 적용
모델이 TCPGen의 결과에 과도하게 의존하는 것을 막기 위해 40%의 비율로 편향 정보를 무시하는 ‘dropping’ 기법을 사용
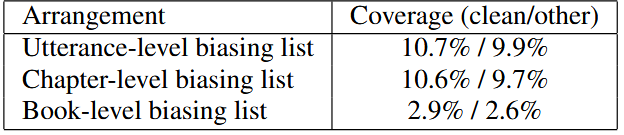
Table 1. Three different biasing list arrangements. Each list comprises 1000 words. Coverage is the total number of biasing word tokens divided by the total number of word tokens in each set.
Biasing List Selection
제 적용 환경을 시뮬레이션하기 위해, 문맥 정보의 범위를 세 가지 수준으로 나누어 편향 목록을 구성
- 발화(Utterance) 수준: 가장 이상적인 시나리오. 정답 문장 자체에 포함된 희귀 단어들을 추출하여 성능 상한선을 확인
- 챕터(Chapter) 수준: 더 현실적인 시나리오. 해당 발화가 포함된 챕터 전체 (약 1000줄)의 텍스트에서 희귀 단어를 추출하여 강연이나 회의의 한 세션 정도의 문맥 확인
- 책(Book) 수준: 가장 현실적인 시나리오. 책 한 권 분량 (약 10000줄)의 매우 넓은 범위의 텍스트에서 희귀 단어를 추출하여 긴 회의나 컨퍼런스 전체의 문맥 성능 확인
- WER (Word Error Rate): 전체적인 단어 인식 오류율.
- R-WER (Rare Word Error Rate): 편향 목록에 포함된 희귀 단어에 대한 오류율.
5. EXPERIMENTAL RESULTS
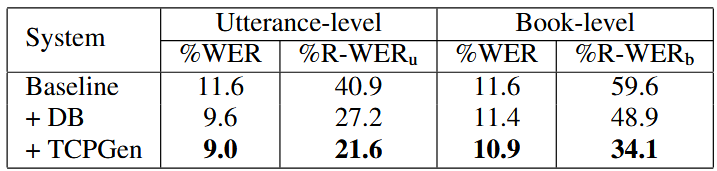
Table 2. WER and R-WER for attention-based model trained on clean-100 data and evaluated on the test-clean set. R-WERu and R-WERb denotes R-WER for utterance and book-level biasing lists respectively. DB used the sum of word piece embeddings.
- TCPGen이 Baseline 및 DB(Deep Biasing) 방식보다 WER(전체 오류율)과 R-WER(희귀 단어 오류율) 모두에서 가장 좋은 성능을 보임.
- 특히 발화 수준(utterance-level) 목록에서 TCPGen은 Baseline 대비 R-WER을 46.5%나 크게 감소시킴.
- TCPGen은 편향 목록에 방해 단어(distractor)가 5,000개까지 늘어나도 안정적인 성능 향상을 보였으며, 추론 속도 저하가 거의 없었음.
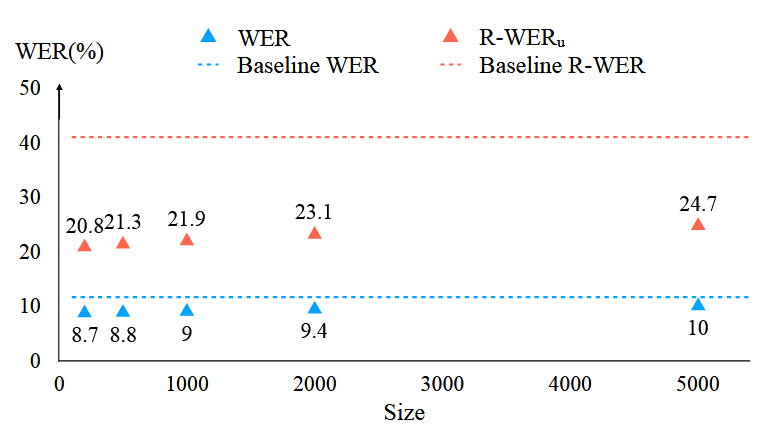
Fig. 5. WER and R-WERu as a function of the number of distractors using utterance-level biasing lists. Baseline results correspond to the first row in Table 2, and TCPGen results with 200, 500, 1000, 2000 and 5000 distractors are shown.
‘중요 단어 목록’에 정답과 상관없는 방해 단어를 최대 5,000개까지 섞어 놓아도, TCPGen의 성능(WER 및 R-WER)은 크게 저하되지 않고 꾸준히 개선된 성능을 보임
방해 단어의 개수가 1,000개일 때와 5,000개일 때의 음성 인식 속도(추론 속도)에 차이가 없었음
TCPGen이 접두사 트리(prefix tree)를 사용하여 문맥 정보를 매우 효율적으로 처리
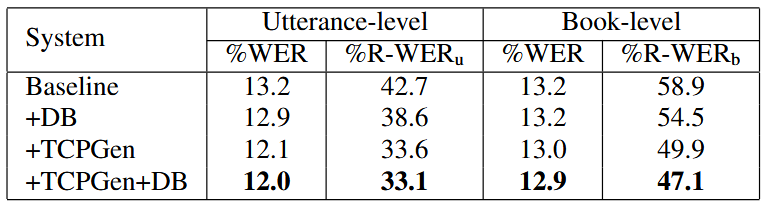
Table 3. WER and R-WER for RNN-T trained on clean-100 data and evaluated on the test-clean set. DB uses hdb without TCPGen and hTCPGen with TCPGen. R-WERu and R-WERb denotes R-WER for utterance and book-level biasing lists respectively.
- RNN-T 모델에서 TCPGen의 성능 향상 폭은 AED 모델보다 작았음.
- TCPGen과 DB를 함께 사용했을 때 가장 좋은 성능을 달성함.
- 발화 수준 목록에서 WER 8.3%, R-WER 21.3%의 상대적 감소를 보임.

Table 4. WER and R-WER (in brackets) evaluated on test-clean and test-other sets for AED trained on 960-hour data. DB uses the sum of word piece embeddings. All three levels of biasing lists contain 1000 distinct word. SF stands for LM shallow fusion with a LM weight of 0.3. R-WER with ∗ indicates that the book-level R-WER reduction is significant (p ≤ 0.001) compared to the baseline.
- 대용량 데이터셋에서도 TCPGen이 WER과 R-WER 모두 가장 우수한 성능을 기록함.
- 외부 언어 모델을 결합하는 SF(Shallow Fusion)를 적용해도 TCPGen이 여전히 최고의 성능을 유지함.
- 챕터 수준(chapter-level) 목록에서는 형태적으로 유사한 단어(예: STRENGTH, STRENGTHEN) 때문에 성능 저하가 관찰됐으나, 그럼에도 TCPGen이 다른 모델보다 뛰어났음.
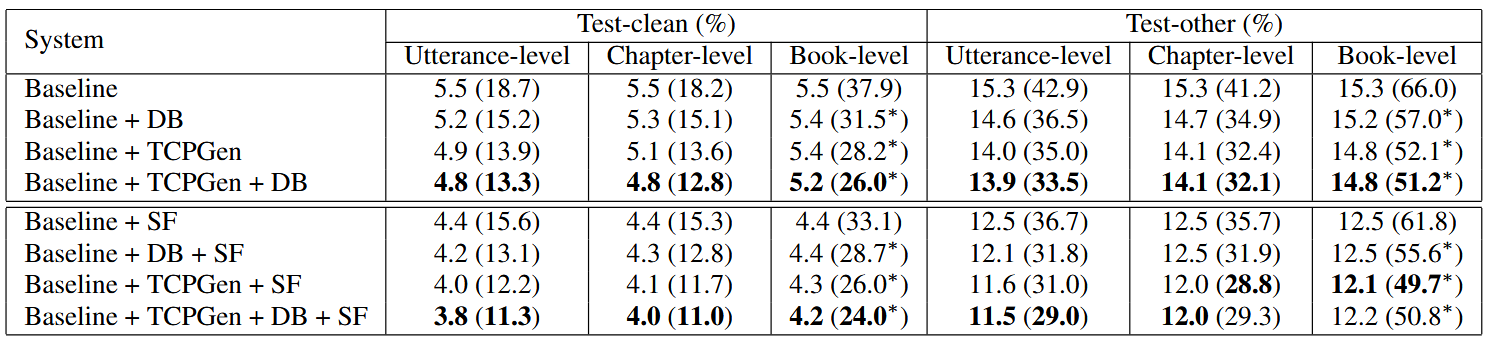
Table 5. WER and R-WER (in brackets) evaluated on the test-clean and test-other sets for RNN-T trained on 960-hour data. DB uses hdb without TCPGen and hptr with TCPGen. All three levels of biasing lists contain 1000 distinct word. SF stands for LM shallow fusion with a LM weight of 0.3. R-WER with ∗ indicates that the book-level R-WER reduction is significant (p ≤ 0.001) compared to the baseline.
- RNN-T에서도 편향 기술들이 전반적인 성능을 향상시켰지만, R-WER 감소 효과는 AED만큼 크지 않았음.
- 이는 RNN-T 모델의 구조상 손실(loss) 계산 방식이 달라 TCPGen에 대한 의존도가 AED보다 낮기 때문으로 분석됨.
- 이러한 낮은 의존도 덕분에 챕터/책 수준 목록 사용 시 성능 저하 폭이 AED보다 작았음.

Table 6. WER and R-WERb (in bracket) on test-other for AED with different book-level biasing list sizes and LM shallow fusion. WER with ∗ indicates a significant WER reduction at p ≤ 0.05, and RWERb with ∗ indicates a significant reduction at p ≤ 0.001.
- 편향 목록의 크기를 늘리자(더 많은 희귀 단어 포함), R-WER은 일관되게 감소했음.
- 하지만 목록 크기를 5,000개까지 늘렸을 때는, 추가된 방해 단어 때문에 편향 목록에 없는 단어의 오류가 늘어나 전체 WER 개선 효과는 상쇄되었음.

Fig. 6. Heat map showing the generation probability for each word piece in an utterance taken from recognition results: 1 AED + TCPGen; 2 RNN-T + TCPGen; 3 RNN-T + TCPGen + DB, to show how each system spots where to use contextual biasing. Biasing words are vignette and Turner.
RNN-T 모델이 AED 모델보다 생성 확률을 더 낮게 예측하는 경향
AED보다 외부 단어 목록(biasing list)에 덜 의존
- AED: 단어를 하나씩 예측할 때마다 손실(loss)을 계산하므로, 매번 TCPGen이 관여, 따라서 TCPGen에 더 많이 의존하도록 학습
- RNN-T: 음성의 매 프레임마다 손실을 계산하는데, 대부분은 아무 단어도 출력하지 않는
blank (∅)심볼, 실제 단어가 나와 TCPGen이 관여하는 순간은 전체 학습 과정에서 일부, 따라서 자연스럽게 TCPGen에 대한 의존도가 낮아짐