
[논문분석] StreamingT2V: Consistent, Dynamic, and Extendable Long Video Generation from Text
controlnet에서 영감을 얻은 long video generation [Code, Paper]
Picsart AI Resarch, (PAIR) UT Austin
Introduction
long term video generation
(i) a short-term memory block called conditional attention module (CAM), (ii) a long-term memory block called appearance preservation module (iii) a randomized blending approach that enables to apply a video enhancer autoregressively for in finitely long videos without inconsistencies between chunks.
기존 모델은 short memory에 집중했음, 영상 품질
긴 비디오를 생성해 내려면 다음과 같은 큰 리소스 필요 (using more that 260K steps and 4500 batch size)
CLIP 이미지 인코더가 조건부 프레임을 완벽하게 재구성하는 데 중요한 정보를 잃기 때문에 여전히 청크 간 전역 동작이 일관되지 않는 경향이 있습니다
기존에 SparseCtrl 모델이 있음. → 한번 논문 살펴볼 필요가 있을 듯
conditioning mechanism by sparse encoder를 통해 문제를 해결.
-
단점
이 텍스트는 병렬 작업인 SparseCtrl을 설명하고 있으며, 이 연구는 더 정교한 조건부 메커니즘을 사용하고 있다고 언급합니다. 이 메커니즘은 스파스(sparse) 인코더에 의해 구현되며, 아키텍처는 추가적인 제로-필(zero-filled) 프레임을 조건부 프레임에 연결하여 스파스 인코더에 입력하기 전에 결합하는 것을 필요로 합니다. 그러나 이러한 입력의 불일치는 출력의 불일치로 이어진다고 언급됩니다.
더불어, 본문에서는 모든 이미지-비디오 방식들이 실험을 통해 평가되었다고 언급합니다(5.4절 참조). 그리고 이 방법들은 자기 회귀적으로 마지막 프레임을 이전 청크(chunk)의 조건으로 사용할 때 결국 비디오 정체 현상을 초래한다고 관찰되었다고 언급합니다. 자기 회귀적 방식이란, 출력이 그 이전의 출력에 의존하는 시퀀스 생성 방식을 의미합니다.
이 문장에서 언급된 주요 문제점은 다음과 같습니다:
- 입력 불일치: 조건부 프레임에 제로-필 프레임을 추가함으로써 입력 데이터에 일관성이 결여되어, 이는 출력에서도 불일치를 야기합니다.
- 비디오 정체: 이미지에서 비디오로 변환하는 기법들이 실험적으로 평가되었을 때, 이러한 방식들은 비디오가 시간이 지남에 따라 동일한 이미지 또는 장면에 머무르는 경향이 있다는 것이 관찰되었습니다. 이는 비디오의 자연스러운 흐름을 방해하며, 따라서 동적인 비디오 생성에는 부적합할 수 있습니다.
이와 같은 문제를 해결하기 위해, 입력 데이터의 일관성을 유지하고 자기 회귀적 접근 방식의 한계를 극복할 수 있는 새로운 방법론의 개발이 필요할 것입니다.
이 논문에서 강조하는 부분
Conditional Attention Module (CAM) we propose the Conditional Attention Module (CAM) which, due to its attentional nature, effectively borrows the content information from the previous frames to generate new ones, while not restricting their motion by the previous structures/shapes.
Appearance Preservation Module (APM) 기존 모델들은 이전 프레임만 참고 → 깊이고려 못함 → 시간적 일관성이 떨어지고 비디오가 정체되는 경향이 있을 뿐만 아니라 시간이 지남에 따라 물체의 모양/특성 변화와 비디오 품질 저하가 발생
초기 이미지(앵커 프레임)에서 객체 또는 전체 장면의 모양 정보를 추출하고 해당 정보로 모든 청크의 비디오 생성 과정을 컨디셔닝하는 모양 보존 모듈(APM)을 설계하여 자동 회귀 프로세스 전반에서 객체 및 장면 특징을 유지
randomized blending approach
구조
VQ-GAN autoencoder 활용
Given a video \(\mathcal{V} ∈ \mathbb{R}^{F×H×W×3}\)
latent code \(x_0 ∈ \mathbb{R}^{F ×h×w×c}\) is obtained through frame-by-frame application of the encoder.
each tensor \(x ∈ \mathbb{R}^{\hat{F}×\hat{h}×\hat{w}×\hat{c}}\)
as a sequence \((x^f)^F_{f=1}\) with \(x^f ∈ \mathbb{R}^{\hat{h}×\hat{w}×\hat{c}}\), we obtain the latent code via \(x^f_0 := \mathcal{E}(\mathcal{V}^f)\), for all f = 1, . . . , F .
Method
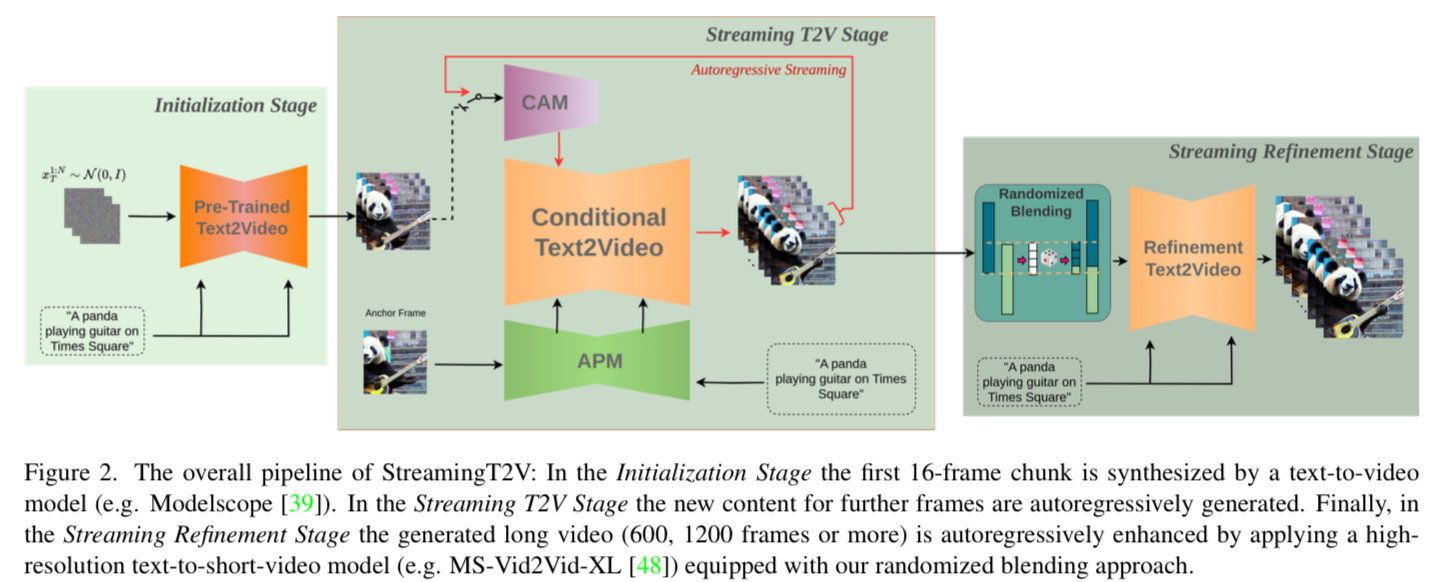
처음 16개의 프레임(256 X 256) → 5seconds 생성 → 이후 higher resolution (720 X 720)
Initialization Stage
pre-trained text-to-video모델을 활용 초기 16프레임 생성
Streaming T2V Stage
autoregressively generating the new content for further frames.
conditional attention module (CAM) : short-term informationlast Fcond = 8 frames of the previous chunk 정보 활용
appearance preservation module (APM) : fixed anchor frame에서 long-term information을 추출
Streaming Refinement Stage
After having a long video (80, 240, 600, 1200 frames or more) generated, we apply the Streaming Refinement Stage which enhances the video by autoregressively applying a high-resolution text-to-short-video model (MS-Vid2Vid-XL)
여기에는 무작위 블렌딩 접근 방식이 포함되어 있으며, 이는 청크 처리를 매끄럽게 수행할 수 있게 도와줍니다. 특히 중요한 점은 이 과정에서 추가적인 훈련이 필요하지 않아 계산 비용을 낮출 수 있다는 것입니다. 이러한 방식은 긴 비디오의 질을 향상시키면서도 경제적인 측면에서 효율적입니다.
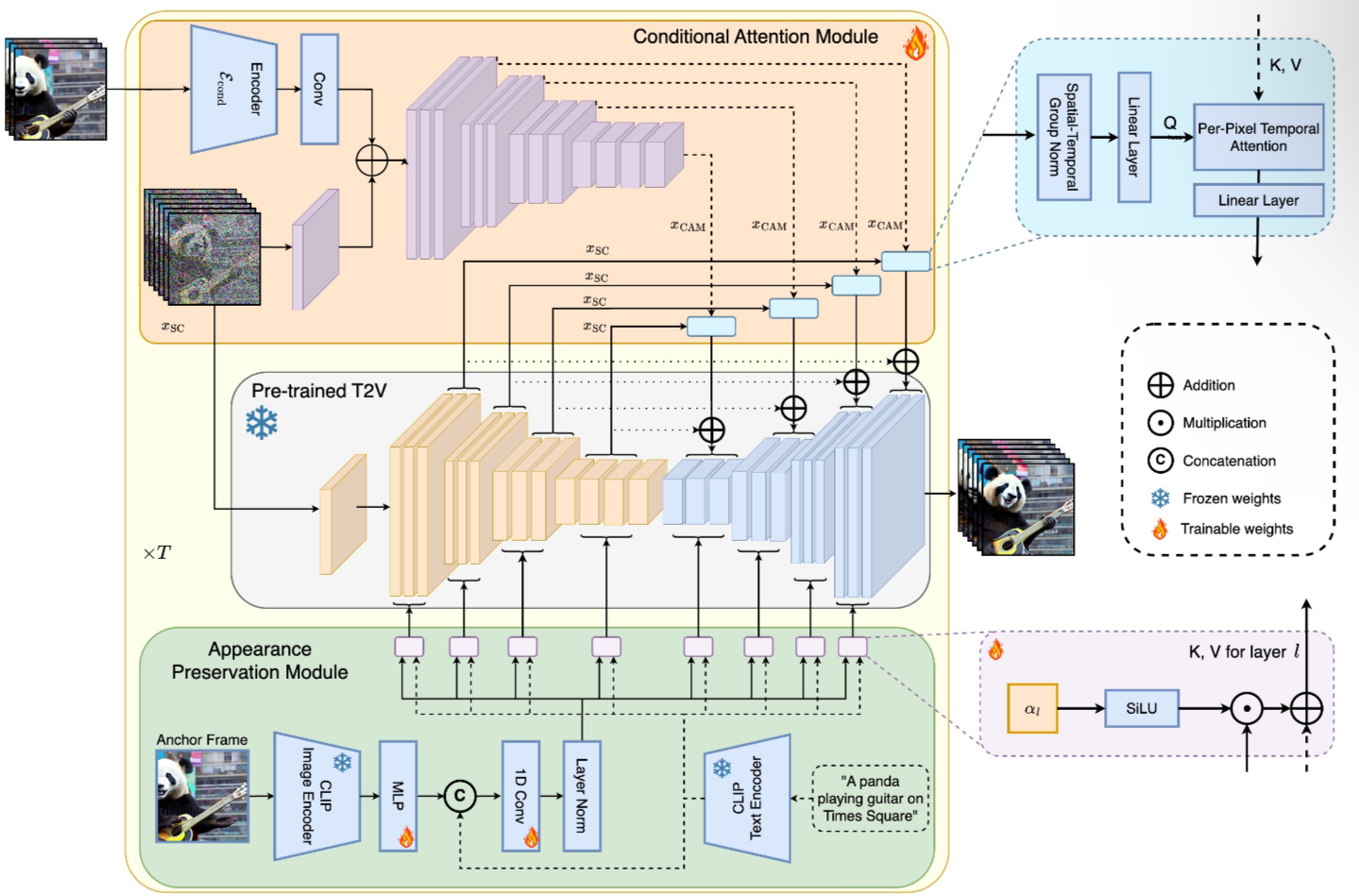
4.1. Conditional Attention Modul
특징 추출기와 특징 인젝터로 구성
ControlNet에서 영감을 받아 Video-LDM UNet에 적용
특징 추출기는 프레임 단위의 이미지 인코더 Econd를 사용하고, Video-LDM UNet이 중간 레이어까지 사용하는 것과 동일한 인코더 레이어를 사용
특징 인젝션의 경우, 각 장거리 스킵 연결은 크로스 어텐션을 통해 CAM에서 생성된 피처에 대응하는 UNet에서 연결
Zero-convolution : 초기 값들을 ‘0’으로
덧셈을 사용해서 x를 CAM의 첫 번째 임시 변압기 블록의 출력과 융합
CAM’s features의 injection, video-LDM의 U-net은 skip-connection적용
\[x_{SC} ∈ R^{b×F ×h×w×c}\]spatio-temporal group norm + a linear projection Pin on xSC
\(x′_{SC} ∈ R^{(b·w·h)×F×c}\) 라 할 때 ,
\[x_{CAM} ∈ R^{(b·w·h)×F_{cond}×c}\](Fcond is the number of conditioning frames, via temporal multi- head attention (T-MHA))
T-MHA : Temporal Multi-Head Attention (T-MHA)
\[x''_{SC}=T-MHA(Q=P_Q(x'_{SC}), K=P_K(x_{CAM}), V=P_V(x_{CAM}))\] \[x'''_{SC} = x_{CS}+R(P_{out}(x''_{CS}))\]x_SC:
x_SC는 UNet의 스킵 연결에서 나오는 특성으로, UNet의 각 계층에서 추출된 중간 특성을 의미
x’_SC:
x'_SC는x_SC가 선형 투영P_in을 거쳐 변환된 후의 특성. 이는 CAM의 특성x_CAM과 결합될 준비가 된 상태
x_CAM:
x_CAM는 Conditional Attention Module(CAM)에서 생성된 특성으로, 이전 비디오 청크의 정보를 요약한 데이터. 이 데이터는x_SC와 결합하여 UNet의 디코딩 과정에 중요한 정보를 제공
Temporal Multi-Head Attention (T-MHA)과 QKV:
- Q (Query): 쿼리는 주로 변환을 받아야 할 데이터의 특성. 여기서
Q는 변환된 스킵 연결 특성x'_SC를 사용하여 계산 - K (Key): 키는 비교 대상이 되는 특성을 나타내며,
x_CAM에서 추출. 이 키를 통해x'_SC의 각 요소가x_CAM의 어떤 부분과 가장 관련이 있는지를 결정. - V (Value): 값은 실제로 주목할 데이터를 담고 있으며, 이것 역시
x_CAM에서 추출. 쿼리와 키의 매칭 결과에 따라 이 값이 가중치를 받아x'_SC에 더함.
feature extractor
프레임단위 이미지 인코더 사용, Video-LDM UNet이 중간 레이어까지 사용하는 것과 동일한 인코더 레이어를 사용(그리고 UNet의 가중치로 초기화됨)
feature injection은 long-range skip connection, 크로스 어텐션을 통해 CAM에서 생성된 피처에 대응하는 UNet에서 연결
x는 \(\mathcal{E}_{cond}\) 의 output (zero-convolution) → 다음 논문에서 언급된 방법 사용
| [Welcome to JunYoung’s blog | ControlNet 논문 이해하기 및 사용해보기](https://junia3.github.io/blog/controlnet) |
Video-LDM Unet → pre-trained T2V
the UNet’s skip-connection features \(x_{SC} ∈ \mathbb{R}^{ b×F ×h×w×c }\)
We apply spatio-temporal group norm, and a linear projection \(P_{in}$ on $x_{CS}\).
\[x′_{SC} ∈ R^{(b·w·h)×F×c}\] \[x_{CAM} ∈ R^{(b·w·h)×F_{cond}×c}\](여기서 Fcond는 각 공간 위치(및 배치)에 대해 독립적으로 템포럴 멀티 헤드 어텐션(T-MHA)을 통한 컨디셔닝 프레임의 수입니다.)
Using learnable linear maps \(P_Q,P_K,P_V\) , for queries, keys, and values
\[x''_{SC}=T-MHA(Q=P_Q(x'_{SC}), K=P_K(x_{CAM}), V=P_V(x_{CAM}))\] \[x'''_{SC} = x_{CS}+R(P_{out}(x''_{CS}))\]-
\(P_{out}\) 에 zero-initialized 사용
Zero-initialization이란 특정 파라미터나 가중치를 학습 시작 전에 모두 0으로 초기화하는 과정을 말합니다. 이 방식은 특정 신경망 계층의 초기 영향을 최소화하여, 신경망이 학습 과정에서 기존 모델의 출력에 영향을 주지 않도록 하는 데 목적이 있습니다.
위 문맥에서
P_out은 선형 투사(Linear projection)로 사용되며, 처음에는 0으로 초기화됩니다. 이 초기화 방식은P_out이 훈련 초기에 기존 모델의 출력에 영향을 주지 않도록 하여, 모델이 훈련 데이터에 대해 더 잘 수렴하도록 돕습니다. 즉,P_out이 훈련 초기에는 아무런 역할을 하지 않다가, 훈련이 진행됨에 따라 점진적으로 중요한 역할을 하게 됩니다. 이는 훈련의 안정성과 효율성을 높이는 데 기여할 수 있습니다.이와 같은 방식은 특히 복잡한 모델에서, 새로운 구성요소가 도입될 때 기존의 학습된 구조에 갑작스럽게 큰 변화를 주지 않고, 점진적으로 통합되도록 하는데 유용합니다.
CAM은 이전 청크의 마지막 Fcond = 8 조건부 프레임을 입력으로 활용
-
이와 비교되는 sparse encoder
Sparse Encoder의 접근 방식과 문제점:
- Sparse encoder는 특성 주입을 위해 컨볼루션(convolution)을 사용합니다. 이 방식은 추가적인
F - F_cond개의 0으로 채워진 프레임과 마스크를 입력으로 필요로 합니다. 이는 CAM의 접근 방식과 대조적으로, 추가적인 입력 데이터를 필요로 하며, 이 과정에서 입력 데이터의 일관성이 떨어지는 문제가 발생합니다. - 이러한 일관성의 부족은 SparseCtrl을 사용할 때 입력에 대한 불일치를 초래하며, 이는 생성된 비디오에서 심각한 불일치 문제로 이어질 수 있습니다. 이는 섹션 5.3과 5.4에서 더 자세히 다루어집니다.
- Sparse encoder는 특성 주입을 위해 컨볼루션(convolution)을 사용합니다. 이 방식은 추가적인
4.2. Appearance Preservation Module
이 문단은 “Appearance Preservation Module (APM)”이라는 기능에 대해 설명합니다. 이 모듈은 비디오 생성 과정에서 초기 객체와 장면의 특성을 잊어버리는 문제, 즉 자동 회귀 비디오 생성기가 종종 겪는 외관 변화를 심각하게 만드는 문제를 해결하기 위해 설계되었습니다. APM은 비디오 청크를 걸쳐 장면과 객체의 특성을 유지하는 데 도움을 줍니다.
\[x_{cross} = SiLU(\alpha_l)x_{mixed}+x_{text}\]이 섹션에서 설명된 과정은 텍스트 지시에 따른 앵커 프레임의 가이드를 조절하는 데 중요한 역할을 하는 ‘외모 보존 모듈(Appearance Preservation Module, APM)’의 작동 원리를 설명하고 있습니다. 다음 단계로 구성되어 있습니다:
- 이미지와 텍스트 토큰 혼합:
- CLIP 모델에서 추출한 앵커 프레임의 이미지 토큰과 해당 텍스트 지시의 텍스트 토큰을 혼합합니다.
- 이미지 토큰을 확장하여 k=8 개의 토큰으로 만든 다음, 이를 텍스트 토큰과 함께 선형 층을 통해 결합합니다.
- 이후, 이 결합된 토큰들을 토큰 차원에서 연결하고 프로젝션 블록을 사용하여 차원을 조정합니다(
R^b×77×1024).
- 크로스 어텐션 적용:
- 각 크로스 어텐션 레이어 l에 대해, 가중치
αl(초기값 0)을 도입하여 크로스 어텐션을 수행합니다. 이 크로스 어텐션은 혼합된 토큰x_mixed와 텍스트 지시의 인코딩x_text의 가중 합에서 얻은 키(key)와 값(value)을 사용합니다.
- 각 크로스 어텐션 레이어 l에 대해, 가중치
- 결과 계산:
x_cross는SilU(αl)x_mixed + x_text를 계산하여 얻습니다. 여기서SilU는 Sigmoid Linear Unit 활성화 함수로, 입력에 따라 선형 변환을 적용하고 그 결과를 다시 입력과 결합합니다.
이러한 접근 방식은 비디오 생성 과정에서 시각적 일관성을 유지하고, 텍스트 지시에 따라 영상의 정확도를 높이는 데 도움을 줍니다. αl의 학습을 통해 어텐션 메커니즘의 효과를 조절할 수 있으며, 이는 전체 모델의 성능에 중요한 영향을 미칩니다.
자동 회귀 동영상 생성기는 일반적으로 초기 객체와 장면의 특징을 가져오는 데 어려움을 겪으며, 이로 인해 심각한 외관 변화가 발생, 이 문제를 해결하기 위해 유니티는 제안한 모양 보존 모듈(APM)을 사용해 첫 번째 청크의 고정 앵커 프레임에 포함된 정보를 활용하여 장기 메모리를 통합
이를 통해 비디오 청크 생성 전반에 걸쳐 장면과 오브젝트의 특징을 유지하는 데 도움
\[x_{cross} = SiLU(\alpha_l)x_{mixed}+x_{text}\]4.3. Auto-regressive Video Enhancement
이 텍스트는 자동회귀 비디오 향상에 대한 접근법을 설명하고 있습니다. 높은 품질과 해상도를 달성하기 위해, 이 방법은 텍스트-투-비디오 해상도 변환을 사용하여 비디오 시퀀스의 연속 청크 간의 일관성을 개선합니다.
- Refiner Video-LDM 사용: 비디오의 품질과 해상도를 향상시키기 위해, Refiner Video-LDM이라는 높은 해상도 텍스트-투-비디오 모델을 사용합니다. 이 모델은 1280x720 텍스트-투-(짧은)비디오 모델로, 24 프레임 청크를 생성한 뒤에, 각 청크에 노이즈를 추가하고 텍스트-투-비디오 확산 모델(SDEdit 접근법 사용)로 정제합니다.
- 업스케일링과 라텐트 코드 변환: 생성된 24 프레임 비디오 청크를 먼저 양선형(bilinear) 방식으로 목표 해상도로 업스케일링한 다음, 이미지 인코더를 사용하여 라텐트 코드로 변환합니다. 이 라텐트 코드는 추가적인 확산 스텝을 거쳐 더 높은 해상도의 비디오 확산 모델로 정제됩니다.
- 청크 간 중복과 프레임 블렌딩: 연속된 청크는 8프레임의 중복을 가지며, 이는 청크 간 부드러운 전환을 가능하게 합니다. 각 청크에서 생성된 비디오는 뒷 청크의 노이즈 제거 스텝으로 이어지며, 이 과정에서 중복되는 프레임은 이전 청크와 혼합됩니다.
- 확률적 라텐트 혼합: 중복 지역에서 라텐트 코드를 확률적으로 혼합하여 청크 간의 불일치를 줄입니다. 이는 각 중복 프레임에 대해, 이전 청크의 라텐트 코드와 현재 청크의 라텐트 코드를 특정 확률로 혼합하여 사용함으로써 달성됩니다. 이 확률은 프레임 위치에 따라 달라집니다.
이러한 방법은 비디오의 장기간 동안 객체와 장면의 외관을 일관되게 유지하면서 높은 해상도의 비디오 생성을 가능하게 합니다. 이 접근법은 청크 간의 부드러운 시각적 전환을 보장하며, 전체 비디오에서 일관된 시각적 품질을 유지하는 데 중점을 둡니다.
이 설명에서는 “randomized blending approach”가 두 연속 비디오 청크 사이의 일관성을 향상시키기 위해 사용됩니다. 이 접근법은 다음과 같은 단계를 포함합니다:
- 청크의 잠재 코드 고려: 두 연속 청크 \(V_{i-1}\)과 \(V_i\)의 잠재 코드 \(x_{t-1}^0:F(i-1)\)과 \(x_{t-1}^0:O(i)\)을 고려합니다. 여기서 F는 청크 \(V_{i-1}\)의 첫 번째 프레임부터 겹치는 프레임까지의 전환을 매끄럽게 하는 잠재 코드이고, O는 겹치는 프레임부터 \(V_i\) 청크의 후속 프레임까지의 전환을 매끄럽게 하는 잠재 코드입니다.
- 잠재 코드 결합: 두 잠재 코드를 연결(concatenation)하기 전에 무작위로 프레임 인덱스 \(f_{thr}\)를 선택합니다. 이 인덱스는 0에서 O 사이의 값입니다. 그런 다음 \(x_{t-1}^0:F(i-1)\)의 첫 \(f_{thr}\) 프레임의 잠재 코드와 \(x_{t-1}^0:O(i)\)에서 \(f_{thr} + 1\) 프레임부터 시작하는 잠재 코드를 선택하여 결합합니다.
- 잠재 코드 업데이트: 위에서 결합된 새로운 잠재 코드로 전체 긴 비디오의 잠재 코드를 업데이트합니다. 이는 이전과 이후의 청크 간에 부드러운 전환을 보장하는 데 도움을 줍니다.
이러한 “randomized blending” 방식은 겹치는 영역에서 두 청크 사이의 경계를 더 자연스럽게 만들어 줌으로써, 비디오의 일관성을 개선하고 시각적으로 끊김 없이 연속되는 비디오 생성을 가능하게 합니다.
이 섹션은 비디오 생성 프로젝트의 실행 세부사항을 설명합니다. 주요 내용은 다음과 같습니다:
- 프레임 생성: 프로젝트는 총 16개의 프레임(
F)을 생성하며, 이 중 8개의 프레임(F_cond)을 조건부 프레임으로 사용합니다. 이는 조건부 주의 모듈(CAM)과 외모 보존 모듈(APM) 훈련에 사용됩니다. - 데이터셋: 훈련에는 공개적으로 이용 가능한 데이터셋이 사용되며, CAM 훈련 동안에는 초당 3프레임(3FPS)의 256x256 해상도에서 16 프레임을, CAM+APM 훈련에는 32 프레임을 사용합니다.
- 프리징과 훈련: 사전 훈련된 Video-LDM의 가중치를 고정시킨 후, 새로운 CAM 레이어들을 배치 크기 8과 학습률 5e-5로 400,000번의 스텝 동안 훈련합니다. 이후 CAM+APM을 추가적으로 훈련합니다.
- 앵커 프레임: 첫 번째 16 프레임 중에서 임의로 앵커 프레임을 선택하여 이를 기반으로 다음 프레임들을 조건부로 생성합니다. 이는 텍스트 지시에 따라 CLIP 정보를 활용하여 고급 의미 정보만을 추출합니다.
- 이미지 인코더
E_cond: CAM에서 사용되는 이미지 인코더는 2D 컨볼루션 층, 레이어 정규화, SiLU 활성화 함수로 구성됩니다. - 비디오 향상: 입력 비디오는 600 스텝 동안 확산(diffuse) 처리되어 향상됩니다. 추가적인 실행 세부사항은 부록에 제공됩니다.
Experiments
Ablation Study
- CAM for conditioning
- Add-Cond: CAM 없이 제로 컨볼루션을 통해 조건 프레임을 UNet의 스킵-연결에 추가, 조건 프레임은 제로 패딩 처리되고, 프레임을 지시하는 마스크와 연결
- Conc-Cond: CAM을 사용하지 않고 조건 프레임과 마스크를 UNet 입력 채널에 추가
각 방법을 훈련한 후 SCuts 점수로 평가했으며, 이 점수는 비디오 내 장면 전환의 빈도를 측정하는 지표로, 낮을수록 더 일관된 비디오를 의미
- Conc-Cond: SCuts 점수 0.24
- Add-Cond: SCuts 점수 0.284
- CAM 사용: SCuts 점수 0.03
결과는 CAM을 사용한 방법이 가장 일관된 비디오를 생성
-
Long-Term Memory

장기 기억을 활용하여 긴 비디오 생성에 미치는 영향을 분석
- 인물 재식별 점수: APM이 없을 때 93.42, APM이 있을 때 94.95로, APM이 신원 및 외형 보존에 기여함
- LPIPS 이미지 거리 점수: APM 없이 0.192, APM 있을 때 0.151로, APM 사용 시 장면 보존이 20% 이상 개선
- Randomized Blending for Video Enhancement
- B: 각 비디오 청크를 독립적으로 향상시키는 방법.
- B+S: 연속적인 청크에 대해 공유된 노이즈를 사용하지만, 무작위 혼합은 사용하지 않음.
연구에서는 광학 흐름의 표준 편차를 계산해 시간적 부드러움을 평가했습니다. 결과는 다음과 같습니다:
- B: 8.72
- B+S: 6.01 (노이즈 공유를 통해 31% 개선)
- StreamingT2V (무작위 혼합): 3.32 (B 대비 62% 개선)
비디오 청크 간의 일관성을 크게 향상시키며, 시간적 부드러움과 시각적 품질에서도 뛰어난 성능을 발휘
Implementation Details
F = 16 프레임을 생성하고 Fcond = 8 프레임을 조건 컨디셔닝과 노이즈 제거를 위해 각각 17번째 프레임부터 시작하여 처음 8개 프레임과 16개 프레임을 사용, 이렇게 하면 조건 프레임과 앵커 프레임 사이에 큰 시간 간격이 있는 추론과 학습을 일치시킬 수 있습니다. 앵커 프레임을 무작위로 샘플링함으로써 모델에 프레임 인덱스를 제공하지 않기 때문에 모델은 높은 수준의 의미 정보를 추출하는 데만 CLIP 정보를 활용
CAM에 사용되는 이미지 인코더 Econd는 스택형 2D 컨볼루션, 레이어 노멀 및 SiLU 활성으로 구성됩니다. 비디오 인핸서의 경우 T′ = 600 스텝을 사용하여 입력 비디오를 diffuison
Metrics
이 문서에서 설명하는 지표는 비디오의 시간적 일관성, 텍스트 정렬 및 각 프레임의 품질을 측정하는 데 사용되는 다양한 방법들을 다룹니다. 세 가지 주요 지표는 다음과 같습니다:
- SCuts (Scene Cuts):
- 목적: 비디오 내에서 감지된 장면 전환의 수를 계산하여 비디오의 시간적 일관성을 평가합니다.
- 도구:
AdaptiveDetector알고리즘과PySceneDetect패키지를 사용하여 기본 매개변수로 장면 전환을 감지합니다.
- MAWE (Motion Aware Warp Error):
- 목적: 비디오가 일관된 움직임을 보이고 왜곡(warp) 오류가 낮을 때 낮은 값을 반환하여 움직임의 양과 왜곡 오류를 조화롭게 평가합니다.
- 계산:
- W(ν): 프레임과 그 후속 왜곡된 프레임 간의 평균 제곱 L2 픽셀 거리를 계산합니다.
- OFS(ν):
Optical Flow Score를 사용하여 비디오에서 모든 광학 흐름 벡터의 평균 크기를 계산합니다. - 공식: \(MAWE(ν) = \frac{W(ν)}{c \cdot OFS(ν)}\), 여기서 c는 두 메트릭의 다른 스케일을 조정하는 값입니다.
- CLIP을 이용한 텍스트 및 이미지 정렬:
- 목적: 비디오의 각 프레임이 주어진 텍스트 설명과 얼마나 잘 일치하는지 평가합니다.
- 도구: CLIP 모델을 사용하여 각 비디오 시퀀스에 대해 텍스트 인코딩과 이미지 인코딩 간의 코사인 유사도를 계산합니다.
이러한 지표들은 비디오 생성 모델의 품질을 종합적으로 평가하는 데 도움을 주며, 각 프레임의 미적 품질도 추가로 평가합니다. 모든 메트릭은 비디오별로 계산된 후 모든 비디오에 대해 평균을 내어 정량적 분석을 수행합니다.
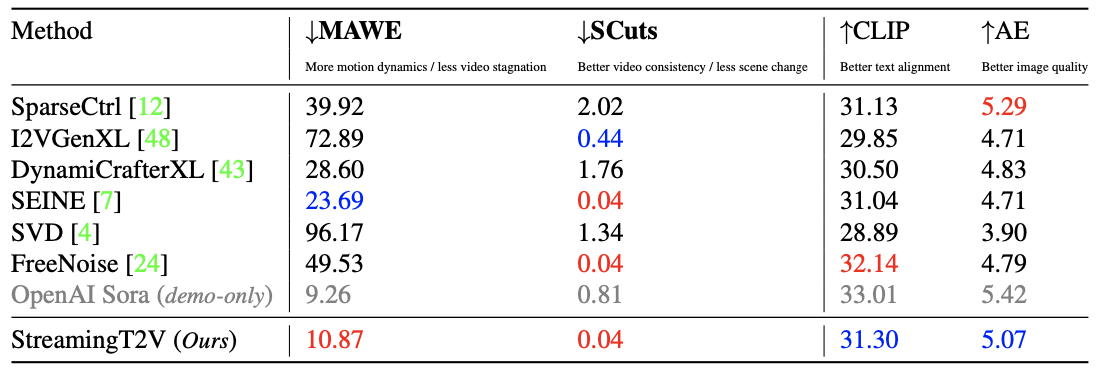
Comparison with Baselines
Benchmark. : 모든 방법에서 공개된 모델 가중치와 하이퍼파라미터를 사용
동일한 비디오-LDM 모델을 사용하여 텍스트 프롬프트가 주어진 16프레임으로 구성된 첫 번째 청크를 생성하고 동일한 리파이너 비디오-LDM을 사용하여 720x720 해상도로 향상
비디오를 생성하는 동시에 해당 청크의 마지막 프레임을 조건으로 모든 자동 회귀 방법을 시작
다른 공간 해상도에서 작동하는 메서드의 경우 첫 번째 청크에 제로 패딩을 적용
Appendix
Ablation studies
Effectiveness of APM : 제안된 APM 모듈을 통한 장기 정보 사용 덕분에 동영상 전체에서 신원 및 장면 특징이 보존, 장기 기억에 액세스하지 않고도 이러한 물체와 장면의 특징은 시간이 지남에 따라 변화
Randomized Blending. : X-T 슬라이스 시각화에서 무작위 블렌딩이 부드러운 청크 전환으로 이어진다는 것, 강화된 비디오 청크를 무작위로 연결하거나 공유 노이즈를 사용하면 결과 비디오에 청크 간에 눈에 띄는 불일치가 발생
Implementation details
Streaming T2V Stage
- 기본 정의:
- \(\epsilon_0(x_t, t, \tau, a)\) 는 잠재 코드 \(x_t$, 확산 단계 $t$ , 텍스트\)\tau\(, 그리고 앵커 프레임\)a$$ 에 대한 노이즈 예측입니다.
- \(\tau_{null}\)과 \(a_{null}\) 은 각각 비어있는 텍스트 문자열과 모든 픽셀 값이 0인 이미지를 나타냅니다. 이는 노이즈 예측에서 조건이 없는 경우를 시뮬레이션하기 위해 사용됩니다.
- 다중 조건 분류기 없는 가이드:
- 이 방식에서는 노이즈 예측에 여러 조건을 동시에 고려합니다. 이를 위해 기본 노이즈 예측에서 텍스트와 앵커 프레임에 대한 가중치를 적용한 수정을 통해 최종 예측값을 계산합니다.
- $\omega_{text}$와 $\omega_{anchor}$는 텍스트와 앵커 프레임에 대한 가중치입니다.
- 수식 구성:
- $\epsilon_0(x_t, t, \tau_{null}, a_{null})$은 아무런 조건이 적용되지 않은 기본 노이즈 예측입니다.
- 첫 번째 항 $\epsilon_0(x_t, t, \tau, a_{null})$은 텍스트 조건만 적용된 노이즈 예측이며, 여기서 $a_{null}$ 은 앵커 프레임이 무시된다는 것을 의미합니다.
- 두 번째 항 $\epsilon_0(x_t, t, \tau, a)$는 텍스트와 앵커 프레임 둘 다 고려한 노이즈 예측입니다.
- 각 조건에 따른 노이즈 예측의 차이를 사용하여 최종 노이즈 예측을 조정합니다.
계산 과정:
- 먼저, 모든 조건이 제거된 상태에서의 노이즈 예측을 기준으로 설정합니다.
- 텍스트에 의한 영향을 계산하기 위해, 텍스트가 주어진 상태와 주어지지 않은 상태에서의 노이즈 예측 차이에 텍스트 가중치를 곱한 값을 추가합니다.
- 앵커 프레임에 의한 영향도 비슷한 방식으로 계산하여 추가합니다.
- 이렇게 해서 얻은 결과는 다양한 조건을 동시에 고려한, 최종적인 노이즈 예측값입니다.
이 수식은 텍스트와 이미지(앵커 프레임)를 동시에 고려함으로써, 생성된 비디오가 주어진 텍스트 설명과 앵커 프레임의 시각적 정보와 더 잘 일치하도록 돕습니다. 이는 비디오 생성에서의 일관성과 정확성을 높이는 데 중요한 역할을 합니다
.
Ablation models
제공하신 내용은 Add-Cond와 Conc-Cond라는 두 가지 Ablation 모델에 대한 구체적인 구현 세부사항을 설명하고 있습니다. 각 모델은 비디오 생성 과정에서 조건부 프레임을 다르게 처리하여, 기본 모델인 CAM과 비교됩니다. 자세한 설명은 다음과 같습니다:
1. Add-Cond 모델
Add-Cond 모델은 CAM의 특성(인코더와 중간 계층의 출력)에 제로 컨볼루션(zero-convolution)을 적용하고, UNet의 스킵-연결 특성과 결합하여 사용합니다. 이 방법은 ControlNet을 모사하는 방식으로 구현되었습니다.
- 마스크 M의 정의와 사용법:
- 비디오 \(V\) 는 \(F \times H \times W \times 3\) 형태로 주어지며, \(V\)는 프레임 수(16개)를 의미합니다.
- \(M\) 은 각 프레임별로 조건부 처리를 할지를 결정하는 이진 마스크입니다. \(M[f, i, j, k] = 1\)이면 해당 위치의 픽셀이 조건부 처리에 사용됩니다.
- 학습 동안 \(M\) 은 무작위로 설정되며, 추론 시에는 처음 8개 프레임은 마스크를 0으로, 마지막 8개 프레임은 1로 설정하여 이전 청크의 마지막 8 프레임을 조건으로 사용합니다.
2. Conc-Cond 모델
Conc-Cond 모델은 UNet의 첫 번째 컨볼루션을 수정하여, 마스크된 조건 프레임을 입력으로 추가합니다.
- 마스크 M과 입력 처리:
- \(M\) 은 Add-Cond와 유사하게 사용되며, 프레임을 0(사용하지 않음) 또는 1(사용)으로 설정합니다.
- \([z_t, \mathcal{E}(V) \odot M, M]\)을 입력으로 사용합니다. 여기서 \(\odot\)은 원소별 곱셈을 나타내며, \(\mathcal{E}(V)\)는 VQ-GAN 인코더로부터 나온 비디오 \(V\)의 인코딩 결과입니다.
- 학습 시에는 \(M\) 을 무작위로 설정하고, 추론 시에는 이전 청크의 마지막 8개 프레임을 조건으로 설정합니다.
핵심 차이점
- Add-Cond는 제로 컨볼루션을 통해 기존 CAM의 특성을 변형 없이 사용하면서 스킵 연결을 통해 UNet에 통합합니다.
- Conc-Cond는 첫 번째 컨볼루션을 수정하여 직접적으로 조건 프레임을 입력 채널에 추가합니다.
이 두 모델은 CAM과 비교하여 조건부 입력 처리 방식에서 차이를 보이며, 각각의 장단점과 효율성을 분석하기 위해 실험에서 사용됩니다.