
[논문분석] StoryDiffusion : Consistent Self-Attention for long-range inage and video generation
Consistent Self-Attention이라는 새로운 셀프 어텐션 방식을 제안, Semantic Motion Predictor 긴 영상 생성
[Page, Code, Paper]
Yupeng Zhou, Daquan Zhou, Ming-Ming Cheng, Jiashi Feng, Qibin Hou
1. Abstract
For recent diffusion-based generative models, maintaining consistent content across a series of generated images, especially those containing subjects and complex details, presents a significant challenge.
we propose a new way of self-attention calculation, termed Consistent Self-Attention, that significantly boosts the consistency between the generated images and augments prevalent pre- trained diffusion-based text-to-image models in a zero-shot manner.
To extend our method to long-range video generation, we further introduce a novel semantic space temporal motion prediction module, named Semantic Motion Predictor.
It is trained to estimate the motion conditions between two provided images in the semantic spaces. This module converts the generated sequence of images into videos with smooth transitions and consistent subjects that are significantly more stable than the modules based on latent spaces only, especially in the context of long video generation.
By merging these two novel components, our framework, referred to as StoryDiffusion, can describe a text-based story with consistent images or videos encompassing a rich variety of contents. The proposed StoryDiffusion encompasses pioneering explorations in visual story generation with the presentation of images and videos, which we hope could inspire more research from the aspect of architectural modifications.
2. Introduction
요즘 diffusion model이 뛰어난 성능을 보임, 그러나 스토리를 설명하기 위해 일관성 있는(예: 일관된 정체성과 복장을 가진 캐릭터) 이미지와 동영상을 제작하는 것은 기존 모델에게는 여전히 어려운 일입니다.
기존 사례 (논문 확인해보기)
IP-Adapter (Ye et al., 2023)
장점:
- 강력한 이미지 유도: IP-Adapter는 참조 이미지를 사용하여 확산 과정을 유도함으로써 해당 이미지와 유사한 이미지를 생성할 수 있습니다. 이는 높은 시각적 유사성을 요구하는 응용 분야에서 유용할 수 있습니다.
- 일관된 품질 보장: 참조 이미지를 기반으로 이미지를 생성하기 때문에 결과 이미지의 품질이 일관되게 유지될 수 있습니다.
단점:
- 텍스트 프롬프트에 대한 제어력 감소: 강력한 이미지 유도로 인해 텍스트 프롬프트를 통한 생성 내용의 제어가 어려워집니다. 이는 사용자가 텍스트로 더 세밀하게 조정하고자 할 때 제한적일 수 있습니다.
InstantID (Wang et al., 2024) 및 PhotoMaker (Li et al., 2023a)
장점:
- 정체성 제어: 이 모델들은 정체성을 보존하는 데 집중하여 사용자가 지정한 인물의 신원을 일관되게 유지하면서 이미지를 생성할 수 있습니다. 이는 특정 인물을 특징으로 하는 컨텐츠 생성에 적합합니다.
- 높은 사용자 제어력: 사용자가 텍스트 프롬프트를 통해 생성 과정을 더 세밀하게 조정할 수 있어, 원하는 방식으로 이미지를 조정하는 데 유리합니다.
단점:
- 의상 및 시나리오의 일관성 부족: 정체성을 유지하는 데 중점을 둔 결과, 의상이나 배경과 같은 다른 요소들의 일관성이 보장되지 않을 수 있습니다. 이는 특정 시나리오나 스타일을 요구하는 사용 경우에 제한적일 수 있습니다.

따라서 본 논문에서는 텍스트 프롬프트를 통해 사용자의 제어 가능성을 극대화하면서 정체성과 복장 측면에서 일관된 캐릭터를 가진 이미지와 동영상을 생성할 수 있는 방법을 찾고자 합니다.
서로 다른 이미지(또는 비디오 생성의 맥락에서 프레임) 간의 일관성을 유지하기 위한 일반적인 접근 방식은 템포럴 모듈을 사용하는 것, 하지만 이를 위해서는 방대한 연산 자원과 데이터가 필요합니다. 이와는 달리, 저희는 데이터와 계산 비용을 최소화하거나 심지어 제로 샷 방식으로 가벼운 방법을 모색하는 것을 목표
Consistent Self-Attention
- 목적: 이 기술은 배치 내 이미지 간의 상관관계를 구축하여 동일한 정체성과 복장을 갖는 일관된 캐릭터 이미지를 생성합니다. 이는 스토리텔링에서 중요한 역할을 합니다.
- 작동 방식: 이 방식은 Q-K-V(질문-키-값) 가중치를 공유함으로써 추가적인 훈련 없이도 일관된 결과를 생성할 수 있습니다. 또한, 시간적 차원을 따라 이동하는 창(sliding window)을 적용하여 입력 텍스트의 길이에 따른 메모리 소모의 최대치를 줄이면서 긴 이야기를 생성할 수 있도록 합니다.
Semantic Motion Predictor
- 목적: 두 이미지 간의 전환을 의미 공간에서 예측하여 스토리의 흐름에 맞는 비디오 프레임을 생성합니다. 이는 이미지의 잠재 공간에서의 움직임을 예측하는 것보다 더 안정적인 결과를 생성한다고 합니다.
- 통합 기술: Guo et al., 2024에 의해 개발된 사전 훈련된 모션 모듈과 함께 사용될 때, 이 방법은 SEINE (Chen et al., 2023) 및 SparseCtrl (Guo et al., 2023)과 같은 최근의 조건부 비디오 생성 방법보다 월등히 개선된 부드러운 비디오 프레임을 생성할 수 있습니다.
접근 방식의 종합
- 스토리 텍스트 처리: 스토리 텍스트를 여러 프롬프트로 나누고 각 프롬프트가 개별 이미지에 해당하도록 합니다. 이렇게 하여 각 이미지가 스토리를 효과적으로 전달할 수 있도록 일관된 이미지를 생성합니다.
- 비디오 스트리밍: 생성된 스토리 프레임을 비디오로 스트리밍하는 과정에서 Semantic Motion Predictor를 사용하여 의미론적 공간에서 이미지 간의 움직임을 예측합니다. 이를 통해 사용자가 긴 스토리를 시각적으로 탐색할 수 있는 비디오를 제작할 수 있습니다.
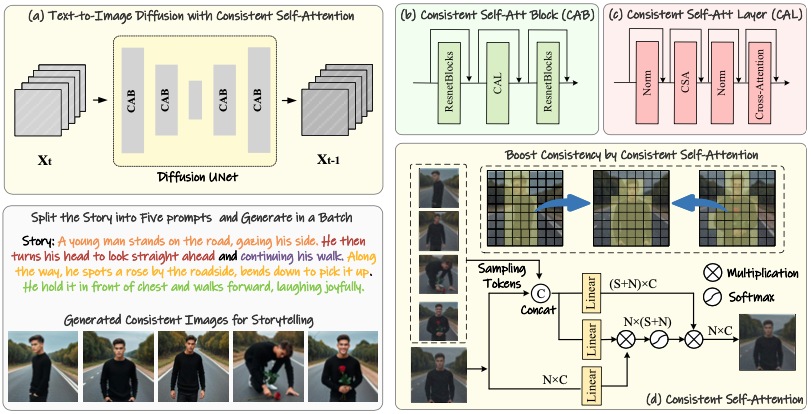
3. Method
첫번째 stage , Consistent Self-Attention → subject-consistent images 생성 : 스토리 텔링으로 활용 or 두번째 stage input
두번째 stage , StoryDiffusion create consistent transition videos based on these consistent images.
Training-Free Consistent Images Generation
The key to addressing the above issues lies in how to maintain consistency of characters within a batch of images
배치내 이미지 간의 연결 설정 필요
기존 U-Net에서 self-attention 자리에 Consistent self-attention을 대입
image features
\(\mathcal{I} ∈ R^{B×N×C}\) : batch size, number of tokens in each image , channel num
기존 attention model
\[O_i = Attention(Q_i,K_i,V_i)\] \[S_i = RandSample(I_1,I_2,..,I_{i−1},I_{i+1},...,I_{B−1},I_B)\]제공된 연구 맥락에서는 신경망 모델을 통해 일관된 주제의 이미지를 생성하는 과정에서 RandSample 함수가 중요한 역할을 합니다. 이 함수는 배치 내의 이미지 간 상호작용을 촉진하는 “일관된 자기 주의(Self-Attention)” 메커니즘의 일부로서, 생성된 이미지 간의 일관성을 유지하는 데 중요합니다.
RandSample(I1, I2, ..., Ii-1, Ii+1, ..., IB-1, IB)의 목적:
이 함수는 현재 이미지 \(I_i\) 를 제외한 배치 내의 다른 이미지 특징들에서 무작위로 샘플링하는 데 사용됩니다. 표기법 I1, I2, ..., Ii-1, Ii+1, ..., IB-1, IB는 배치에서 \(i\)번째 위치에 있는 이미지를 제외한 모든 이미지를 나타냅니다.
작동 방식:
- 이미지 배치: \(B\)개의 이미지가 있는 배치를 가정하고, 현재 \(I_{th}\) 이미지를 처리 중입니다.
- 현재 이미지의 제외: 함수는 \(I_i\) 를 샘플 세트에서 제외함으로써 자기 참조를 피합니다. 이는 일관성이 이미지 자체에서 나오는 것이 아니라 배치 내 다른 이미지와의 관계에서 발생하도록 보장하는 데 중요합니다.
- 샘플링: 이 다른 이미지들의 특징에서 무작위로 일부 토큰(또는 부분)을 선택합니다. 이 무작위 샘플링은 전체 테마 또는 일관성을 유지하면서 다양성을 도입합니다.

일관된 자기 주의에서의 역할:
다른 이미지들에서 샘플링한 토큰들을 현재 이미지 \(I_i\) 의 원래 토큰과 결합합니다. 이 결합된 토큰 세트는 자기 주의 메커니즘을 위한 새로운 키와 값 쌍을 계산하는 데 사용됩니다. 이 과정에서 현재 이미지의 원래 쿼리 \(Q_i\) 는 변경되지 않습니다. 이 방법은 주의 메커니즘이 단순히 같은 이미지 내에서만 초점을 맞추는 것이 아니라 다른 이미지의 특징도 포함하도록 보장함으로써, 다른 장면의 비디오나 애니메이션 스토리보드와 같이 일련의 이미지에서 내러티브 또는 시각적 일관성을 유지하는 시나리오에서 특히 유용합니다.
중요성:
이 방법은 모델을 재훈련할 필요 없이 다른 이미지들이 제공하는 다양한 맥락에 동적으로 적응할 수 있게 해, 현장에서 일관된 이미지 세트를 즉시 생성하는 데 더 유연하고 강력하게 만듭니다.
요약하면, RandSample 함수는 생성된 이미지 배치가 다양성뿐만 아니라 광범위한 일관성도 유지할 수 있도록 하는데 결정적인 구성 요소로, 복잡한 이미지 생성 작업을 처리하는 신경망 모델의 정교한 행동에 중요한 기여를 합니다.
배치 내 다른 이미지와 비교하는 장점
- 주제 일관성의 강화: 다른 이미지의 특성을 참조함으로써, 각 이미지가 전체 배치의 컨텍스트를 반영하도록 합니다. 이는 전체적으로 조화롭고 일관된 스타일의 이미지를 생성할 수 있게 도와줍니다.
- 강화된 특성 학습: 다른 이미지로부터 정보를 통합함으로써, 네트워크가 보다 풍부하고 다양한 특성을 학습할 수 있습니다. 이는 모델이 더 일반화된 특성을 인식하고, 더 나은 품질의 이미지를 생성하는 데 도움을 줍니다.
- 효율적인 정보 이용: 이미지 간의 상호작용을 통해 각 이미지가 포함하고 있는 정보를 최대한 활용합니다. 이는 특히 제한된 데이터로부터 학습할 때 유용하며, 각 이미지의 독립적인 처리보다 정보의 활용도를 높여 줍니다.
- 학습 프리(Training-Free) 방법의 가능성: 이러한 접근 방식은 모델이 사전 학습 없이도 배치 내 다양한 이미지 특성을 효과적으로 통합하고, 일관성 있는 출력을 생성할 수 있도록 지원합니다.
Algorithm 1 Consistent Self-Attention
def ConsistentSelfAttention(images_features, sampling_rate, tile_size):
"""
images_tokens: [B, C, N]
sampling_rate: Float (0-1)
tile_size: Int
"""
output = zeros(B, N, C), count = zeros(B, N, C), W = tile_size
for t in range(0, N - tile_size + 1):
# Use tile to override out of GPU memory
tile_features = images_tokens[t:t + W, :, :]
reshape_featrue = tile_feature.reshape(1, W*N, C).repeat(W, 1, 1)
sampled_tokens = RandSample(reshape_featrue, rate=sampling_rate, dim=1)
# Concat the tokens from other images with the original tokens
token_KV = concat([sampled_tokens, tile_features], dim=1)
token_Q = tile_features
# perform attention calculation:
X_q, X_k, X_v = Linear_q(token_Q), Linear_k(token_KV), Linear_v(token_KV)
output[t:t+w, :, :] += Attention(X_q, X_k, X_v)
count[t:t+w, :, :] += 1output = output/count
return output
Semantic Motion Predictor for Video Generation
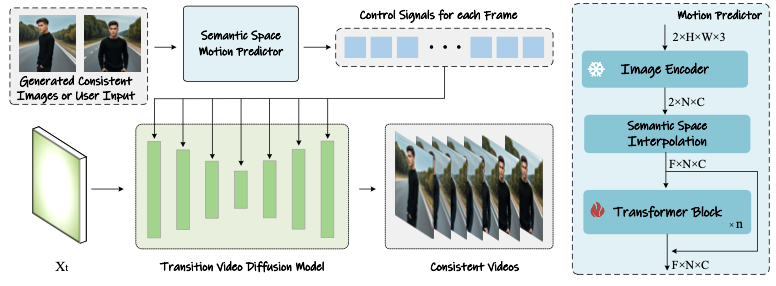
이 텍스트는 이미지 시퀀스를 사용하여 비디오를 생성하는 과정과 관련된 최근 연구의 한계점을 논의하고 있습니다. 특히, 알려진 시작 프레임과 종료 프레임을 기반으로 중간 프레임을 생성하는 비디오 생성 기술의 문제점을 지적하고 있습니다. 여기서 언급된 기술들, SparseCtrl과 SEINE,은 두 이미지 간의 상태 차이가 클 때, 이를 안정적으로 결합하여 의미 있는 중간 프레임을 생성하지 못한다고 합니다.
문제의 핵심
- 템포럴 모듈 의존성: 이 기술들은 중간 프레임을 생성하기 위해 주로 시간적 변화를 추적하는 템포럴 모듈에 의존합니다. 이 모듈은 시간적 변화를 관리하지만, 큰 상태 변화에는 적응하지 못하는 한계를 가지고 있습니다.
- 공간 정보의 부족: 템포럴 모듈이 각 공간 위치의 픽셀을 독립적으로 처리함으로써, 전체적인 공간적 맥락을 충분히 고려하지 못합니다. 이는 중간 프레임에서 물리적으로 의미 있는 동작의 연속성을 제대로 모델링하지 못하게 만듭니다.
- 장거리 동작 모델링의 어려움: 시작 프레임과 종료 프레임 사이에 큰 차이가 있는 경우, 템포럴 모듈만으로는 장거리에 걸친 동작을 효과적으로 추론하고 재현하는 데 한계가 있습니다. 이는 비디오의 질을 저하시키고, 불안정한 비디오 결과를 초래할 수 있습니다.
해결 방안의 방향성
- 공간적 연결성 강화: 템포럴 모듈과 함께 공간적 정보를 통합하는 새로운 모델 설계가 필요합니다. 이를 통해 이미지 간의 연속성을 보다 자연스럽게 다룰 수 있습니다.
- 멀티-스케일 처리: 다양한 스케일에서 이미지 특성을 처리하여 미세한 디테일과 큰 구조 모두를 잘 반영할 수 있는 모델을 개발할 필요가 있습니다.
- 장기 의존성 학습: 시작과 종료 프레임 사이의 장거리 의존성을 학습할 수 있는 알고리즘의 개발이 중요합니다. 이를 위해 더 긴 시퀀스를 처리할 수 있는 모델의 구축이 요구됩니다.
이와 같은 연구와 개발은 비디오 생성 기술을 향상시켜, 자연스러운 비디오 시퀀스를 생성하는 데 기여할 수 있습니다. 따라서 이 분야에서의 기술적 발전은 더 실감나고 질 높은 비디오 콘텐츠 제작으로 이어질 수 있습니다.