
[논문분석] Sound-guided Semantic Video Generation
GAN을 활용한 sound guided video generation, clip의 latent space를 활용 [Code, Paper]
Abstract
The recent success in StyleGAN demonstrates that pre-trained StyleGAN latent space is useful for realistic video generation. However, the generated motion in the video is usually not semantically meaningful due to the difficulty of determining the direction and magnitude in the StyleGAN latent space. In this paper, we propose a framework to generate realistic videos by leveraging multimodal (sound-image-text) embedding space. As sound provides the temporal contexts of the scene, our framework learns to generate a video that is semantically consistent with sound. First, our sound inversion module maps the audio directly into the StyleGAN latent space. We then incorporate the CLIP-based multimodal embedding space to further provide the audio-visual relationships. Finally, the proposed frame generator learns to find the trajectory in the latent space which is coherent with the corresponding sound and generates a video in a hierarchical manner. We provide the new high-resolution landscape video dataset (audio-visual pair) for the sound-guided video generation task. The experiments show that our model outperforms the state-of-the-art methods in terms of video quality. We further show several applications including image and video editing to verify the effectiveness of our method.
StyleGAN은 video에서 동작하기 어렵다.
사운드-이미지-텍스트 embedding space를 활용하여 video generation framework를 제안
- sound - video alignment
- clip based multimodal embedding
- frame generator
Introduction
sound(2차원 정보) → video(3차원 정보) generation이 쉽지 않음
non-verval sound 문제점
- sound와 visual이 직접 연결되지 않음
- 프레임 간 시간적으로 일관성이 있어야 함
- non-verbal sound - video pair dataset 부족
본 논문에서는
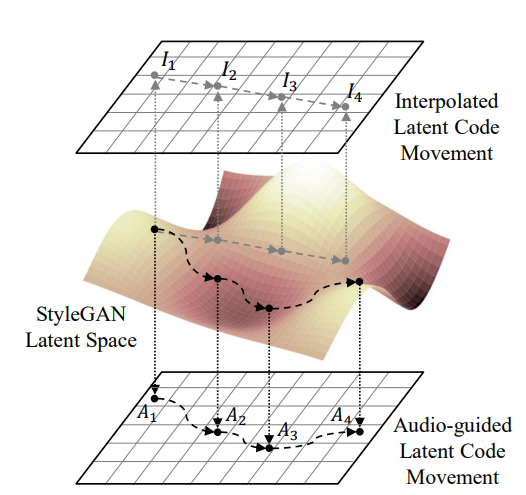
Sound-encoder 를 통해 latent space W+에서 처음 trajectory의 연관성을 찾을 수 있도록 함
다음 CLIP-based multimodal embedding space를 활용 trajectory를 guide
StyleGAN의 latent space에서 latent vector를 움직이면서 사실적인 video를 생성
Related Work
StyleGAN Latent Space Analysis
GAN
Latent Space에서 특정 방향(예: 얼굴 표정, 머리 색깔)을 이동하여 이미지 혹은 비디오를 조작
Sound-guided Video Generation
conditional variational autoencoder method
latent space에서 다음 video frame의 분포를 예측
Sound-guided Video Generation
sound를 이해하고 비디오를 생성할 수 있는 능력 + 시간적 일관성
Sound Inversion Encoder + StyleGAN-based Video Generator
(+CLIP-based의 multimodal (image, text, audio) joint embedding space을 통해 Latent Space guide)
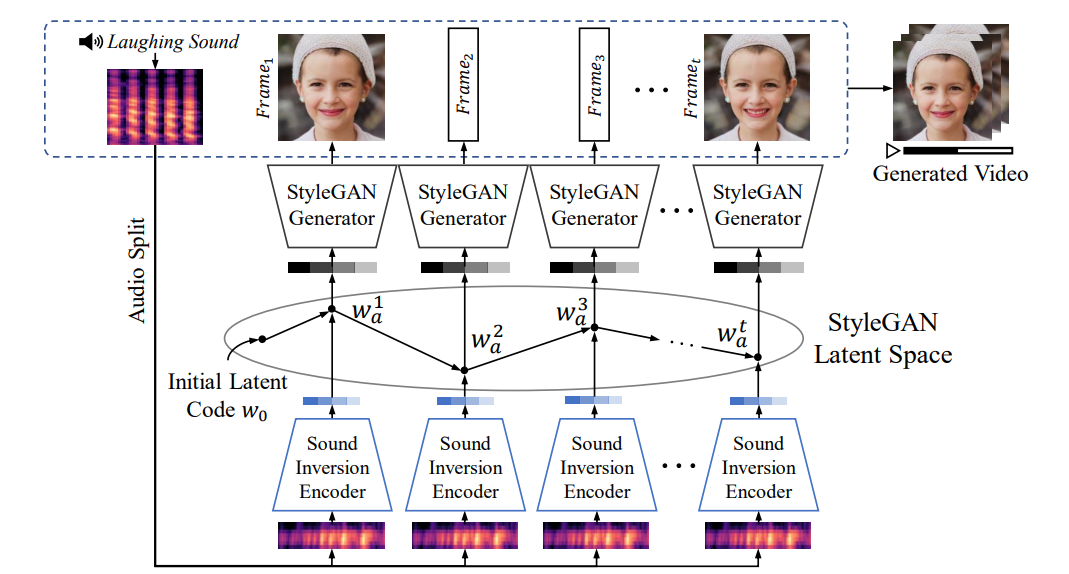
Fig. 3: An overview of our proposed sound-guided video generation model. Our model consists of two main modules: (i) Sound Inversion Encoder (Section 3.1), which processes audio input sequences and generates latent codes for video frame creation, and (ii) StyleGAN-based Video Generator (Section 3.2), which produces temporally consistent and perceptually realistic video frames based on the sound input.
모델구조
- 입력 sound를 Sound Inversion Encoder 로 제공
- video 생성을 위한 latent code를 생성
- Latent Space에서 넘어온 latent vector로 일괄된 frame을 생성
Inverting Sound Into the StyleGAN Latent Space
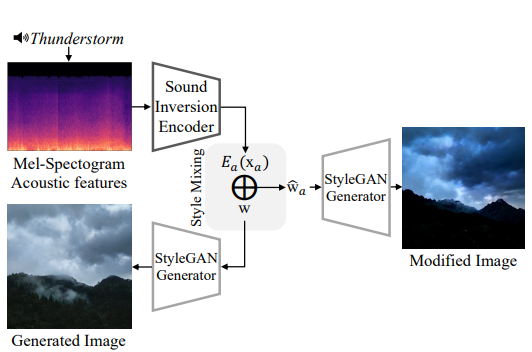
sound-guided latent code
\[\hat{\mathrm{w}}_a = E_a(\mathrm{x}_a) + \mathrm{w}\]Sound Inversion Encoder는 \(*E_a(⋅)*\)
Melspectrogram Acoustic feature \(X_a\)
\(X_a\)를 입력으로 받아서 pre-trained StyleGAN feature space W+ 의 latent feature \(*w_a\)출력*
CLIP-based embedding space : Contrastive learning 으로 학습
\[L_{\text{CLIP}}^{(a \leftrightarrow v)} = 1 - \frac{F_v(G(\hat{w}_a)) \cdot F_a(X_a)}{\|F_v(G(\hat{w}_a))\|_2 \cdot \|F_a(X_a)\|_2}\]위 식을 통해 latent code \(*\hat{w}_a*\)로 생성된 이미지와 audio input간의 cosine 거리를 최소화
G(⋅)은 StyleGAN generator
\(*F_v(⋅)*\)과 \(*F_a(⋅)*\)은 각각 CLIP의 image, audio encoder
Sound Inversion Encoder들의 loss식
\[L_{\text{enc}} = L_{\text{CLIP}}^{(a \leftrightarrow v)} + L_{\text{CLIP}}^{(a \leftrightarrow t)} + \lambda_b \| \hat{w}_a - \bar{w}_a \|_2^2\]audio-video clip loss, audio-text clip loss
\(\bar{w}_a\) 는 encoder를 통해 생성된 latent code의 평균값
Sound-guided Semantic Video Generation
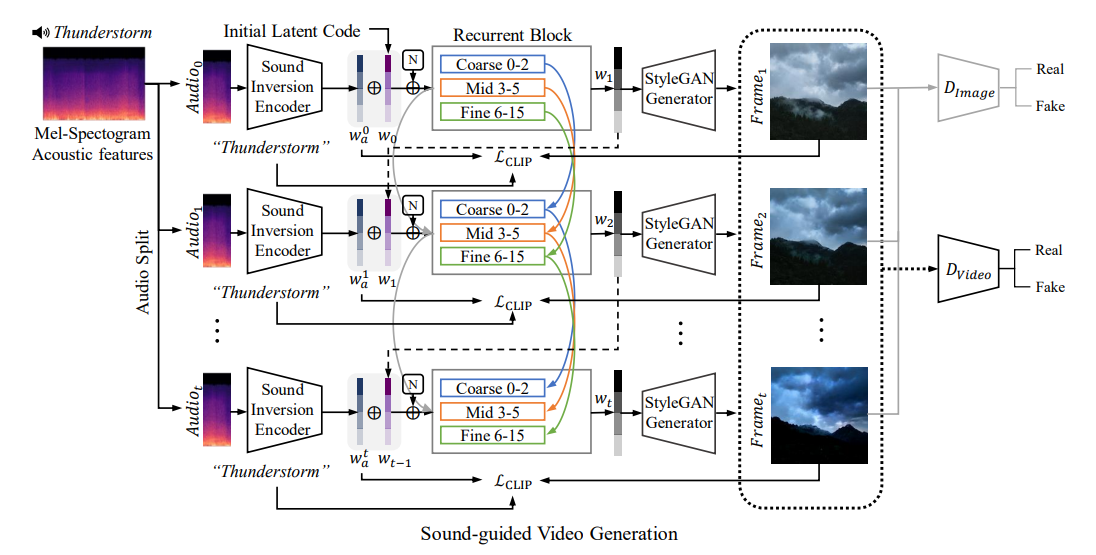
sound-guided video generation model의 구조도
Recurrent Module for Latent Code Sequence Generation : frame generation
\[\hat{w}_a^t = \left( E_{\text{RNN}}^{\text{coarse}}(\hat{w}_a^{t-1}), E_{\text{RNN}}^{\text{mid}}(\hat{w}_a^{t-1}), E_{\text{RNN}}^{\text{fine}}(\hat{w}_a^{t-1}) \right)\]\(*E_{RNN}(⋅)*\) 은 Recurent Neural Network
시간 t 별로 잘라진 audio 신호를 바탕으로 \(\hat{w}_a^t\) latent code를 생성
t-1시점의 latent code를 바탕으로 다음 time step의 latent code를 예측 → 이전 frame의 style을 반영하여 semantic한 연관성을 유지
\[\tilde{v} = \left[G(\hat{w}_a^1), G(\hat{w}_a^2), \dots, G(\hat{w}_a^T)\right]\] \[L_D = L_{D_v} + L_{D_I} = \mathbb{E}[\log D_I(v)] + \mathbb{E}[1 - \log D_I(\tilde{v})]\]adversarially → 더 realistic하게
\[\min_{\theta_G} \max_{\theta_{D_v}} L_{D_v} + \min_{\theta_G} \max_{\theta_{D_I}} L_{D_I} + \min_{\theta_{E_a}} \lambda_{\text{enc}} L_{\text{enc}}\]최종 loss function
Experiments
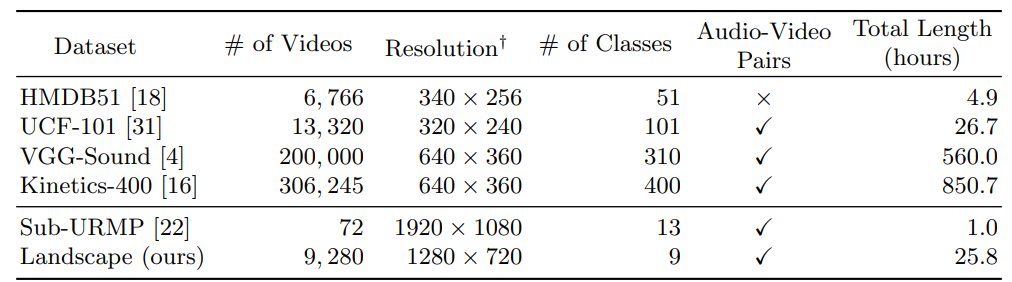
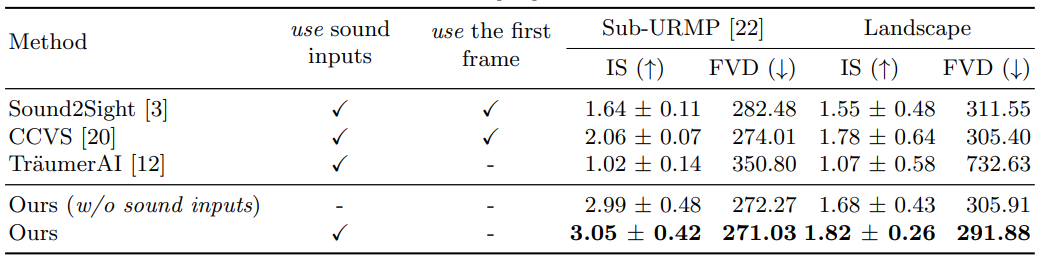
Ablation Studies
CLIP Loss for StyleGAN Inversion
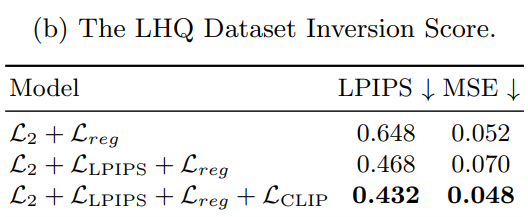
Effect of Multiple Recurrent Blocks for Rich Style Information
