
[스터디] Score-Based Generative Models and Diffusion Models
고려대 DMQA 연구실 세미나 자료 [Page]
Score-Based Generative Models
Score : 확률밀도함수의 미분
입력 데이터 x에 대한 미분 (일반적인 파라미터 \(\theta\)에 대한 미분이 아님)
\[score = \nabla_xlogp(x)\]Multivariate Normal Distribution (다변량 정규 분포) 일때
\[p(\mathbf{x}) = \frac{1}{\sqrt{(2\pi)^d |\Sigma|}} \exp\left( -\frac{1}{2} (\mathbf{x} - \boldsymbol{\mu})^T \Sigma^{-1} (\mathbf{x} - \boldsymbol{\mu}) \right)\] \[\nabla_{\mathbf{x}} \log p(\mathbf{x}) = -\Sigma^{-1} (\mathbf{x} - \boldsymbol{\mu})\]데이터의 분포를 몰라도 Score만 알면 데이터 생성 가능
Score를 데이터로부터 추정 (Score matching) → Training
추정된 Score를 바탕으로 새로운 데이터 sampling (Langevin dynamics) → Testing
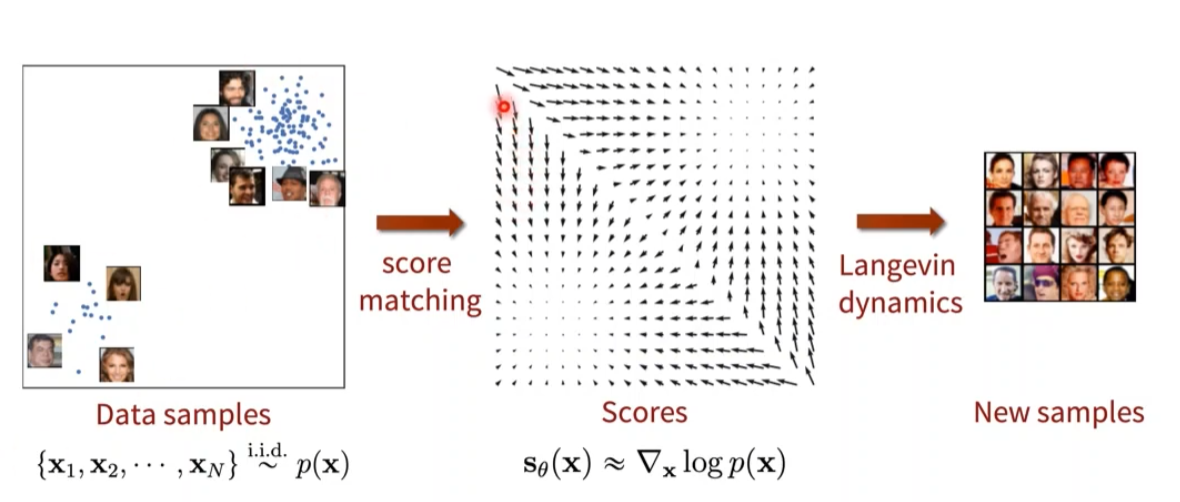

위에 Jacobian Matrix를 계산하는 것이 어려움
Denoising score matching
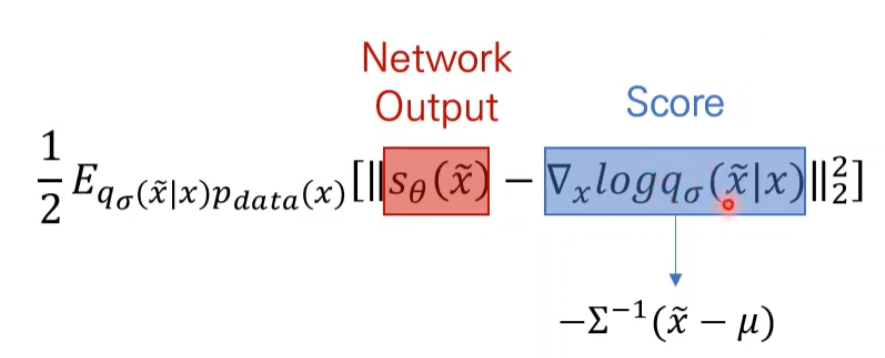
Score Matching Loss
\[\frac{1}{2} \mathbb{E}_{q_\sigma(\tilde{x}|x) p_{\text{data}}(x)} \left[ \| s_\theta(\tilde{x}) - \nabla_x \log q_\sigma(\tilde{x}|x) \|_2^2 \right]\]- \(q_σ(\tilde{x}∣x)\) : 노이즈가 섞인 데이터 x~가 원본 데이터 x에서 샘플링된 확률 분포를 나타냅니다.
- \(p_{\text{data}}(x)\) : 원본 데이터의 실제 분포를 나타냅니다.
- \(s_\theta(\tilde{x})\) : 학습 중인 모델 θ에 의해 예측된 스코어 함수입니다.
-
$$\nabla_x \log q_\sigma(\tilde{x} x)$$ : x에 대한 노이즈 분포의 로그 확률의 그라디언트를 나타냅니다.
노이즈가 작은 경우에 대한 근사 결과
\[s_{\theta^*}(x) = \nabla_x \log q_\sigma(x) \approx \nabla_x \log p_{\text{data}}(x)\]- \(s_{θ∗}(x)\)는 최적화된 스코어 함수 ( = \(∇_xlog\ q_σ(x)\) )
- 노이즈가 작은 경우 \(log\ q_σ(x)\)는 원본 데이터 분포 \(p_{data}(x)\)와 비슷
- 최적의 스코어 함수는 \(∇_xlog\ p_{data}(x)\)로 근사
Score network
U-Net 사용
input : 데이터 → output : score
Langevin dynamics
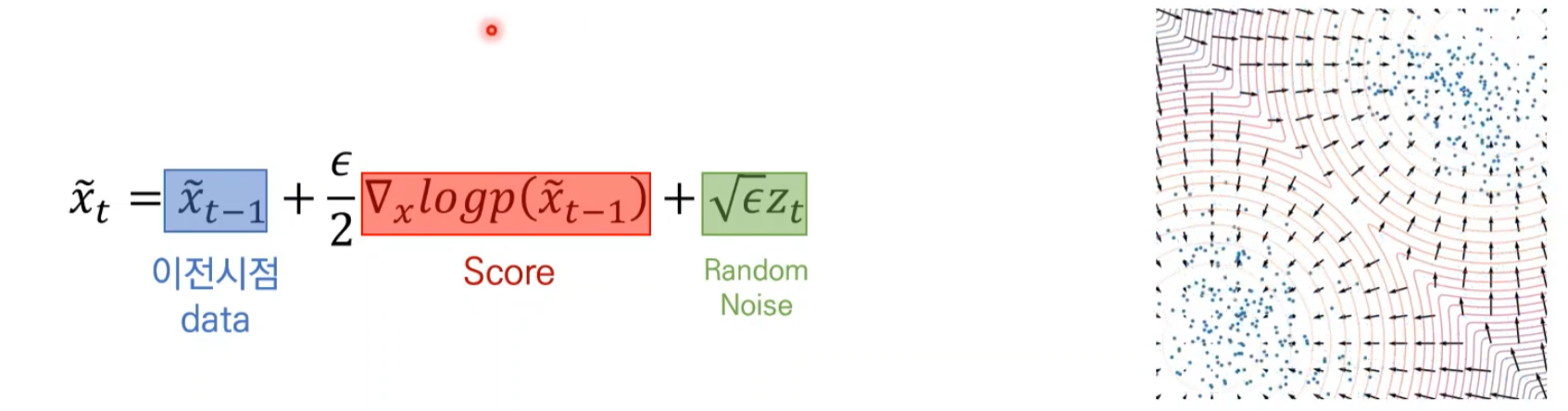
Score network가 잘 학습되었다면 모든 데이터 공간상에서 score 계산 가능
임의의 데이터에서 시작
현재 시점에서 추정된 Score 기반으로 데이터 업데이트
Score를 따라 가다보면 높은 확률 값의 데이터 생성
Random Noise는 무작위성을 부여
Problem in Low Density Regions
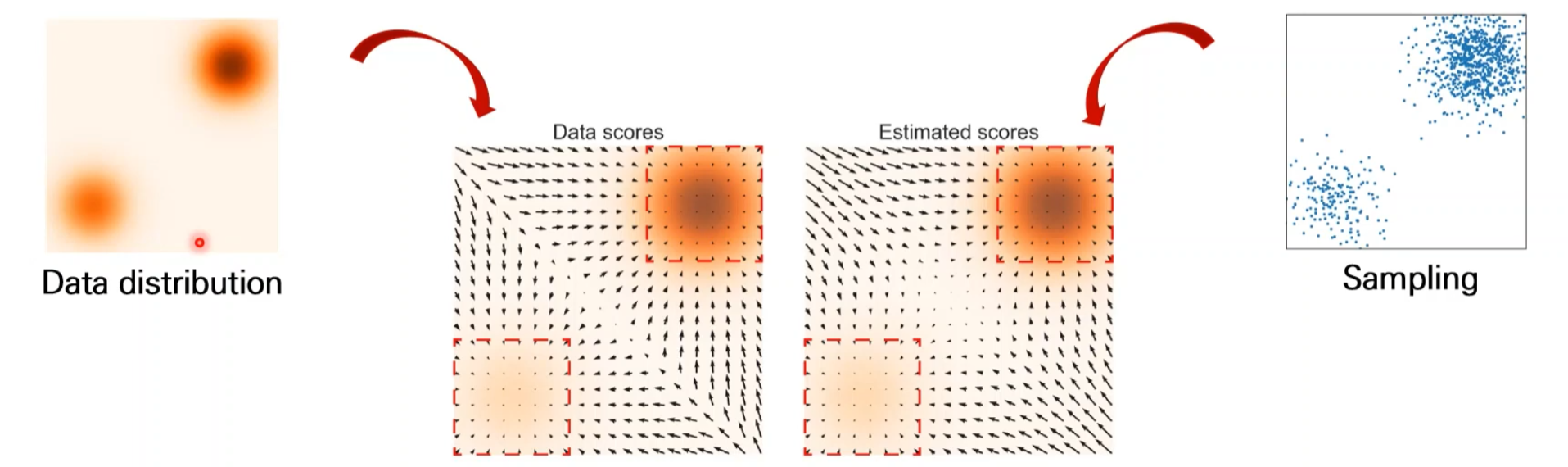
Score가 작은 부분에서는 Score 정보 부정확 (데이터 자체가 부족하기 때문에)
더 빠르게 이동하기 위한 장치로 노이즈 추가

NCSN

초기에는 노이즈 크기를 크게 해서 빠르게 이동하게 하고 점점 노이즈를 감소하면서 샘플링을 진행

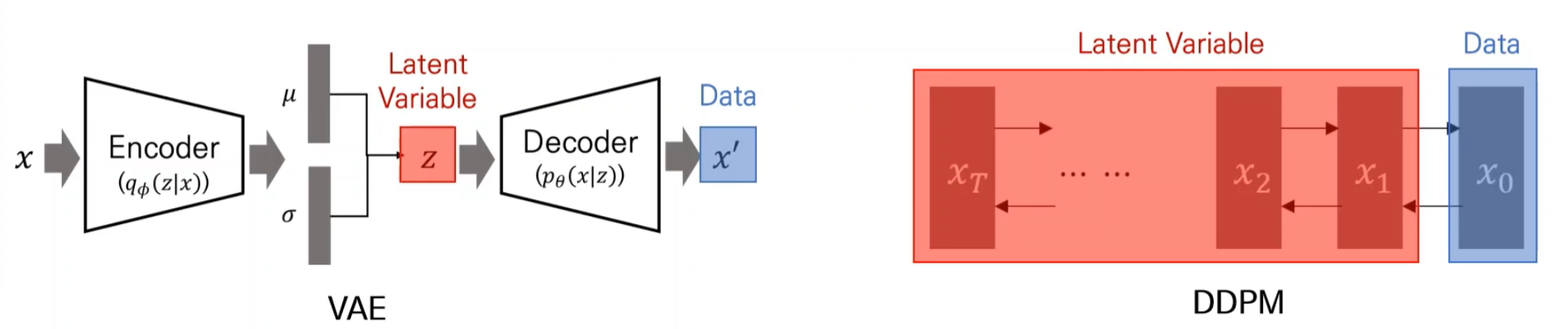
DDMP
Maximum Likelihood Estimation (MLE)
Likelihood : 주어진 파라미터를 이용한 분포가 모집단의 분포일 확률
Likelihood가 미분해서 0인 포인트로 정의
Latent Variable을 반복해서 실행 (Markov chain으로)
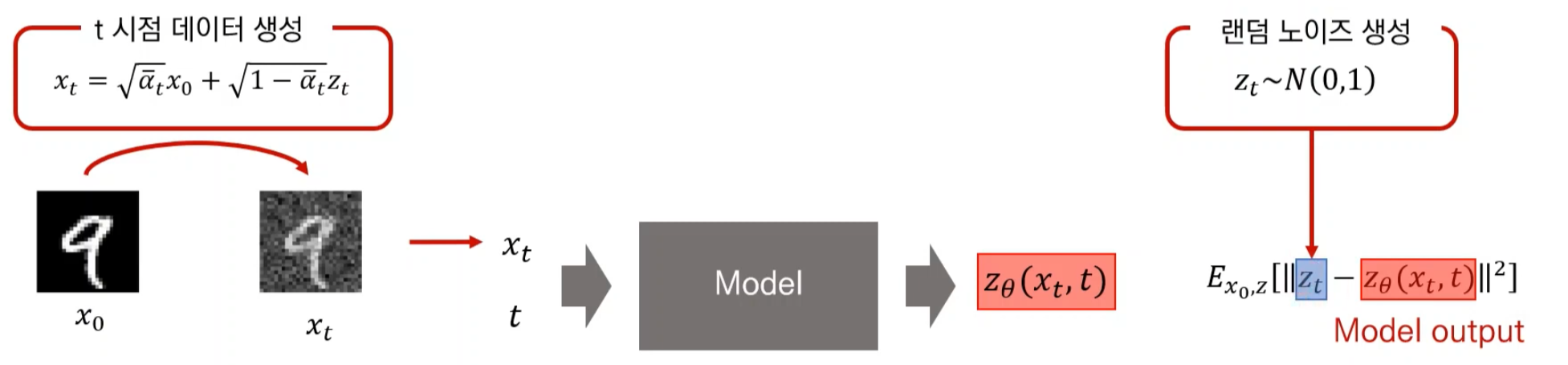
Training
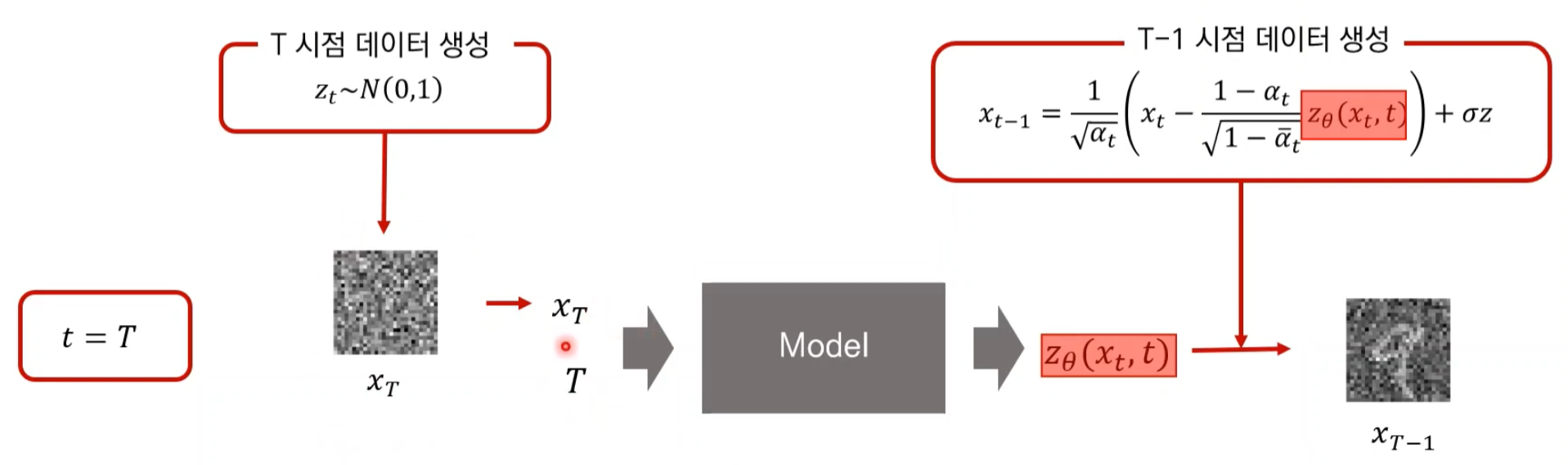
Testing
Score-based Generative Models with SDEs
ODE ( Ordinary Differential Equation → Solve → x(t) 해)
SDE = ODE + Randomness
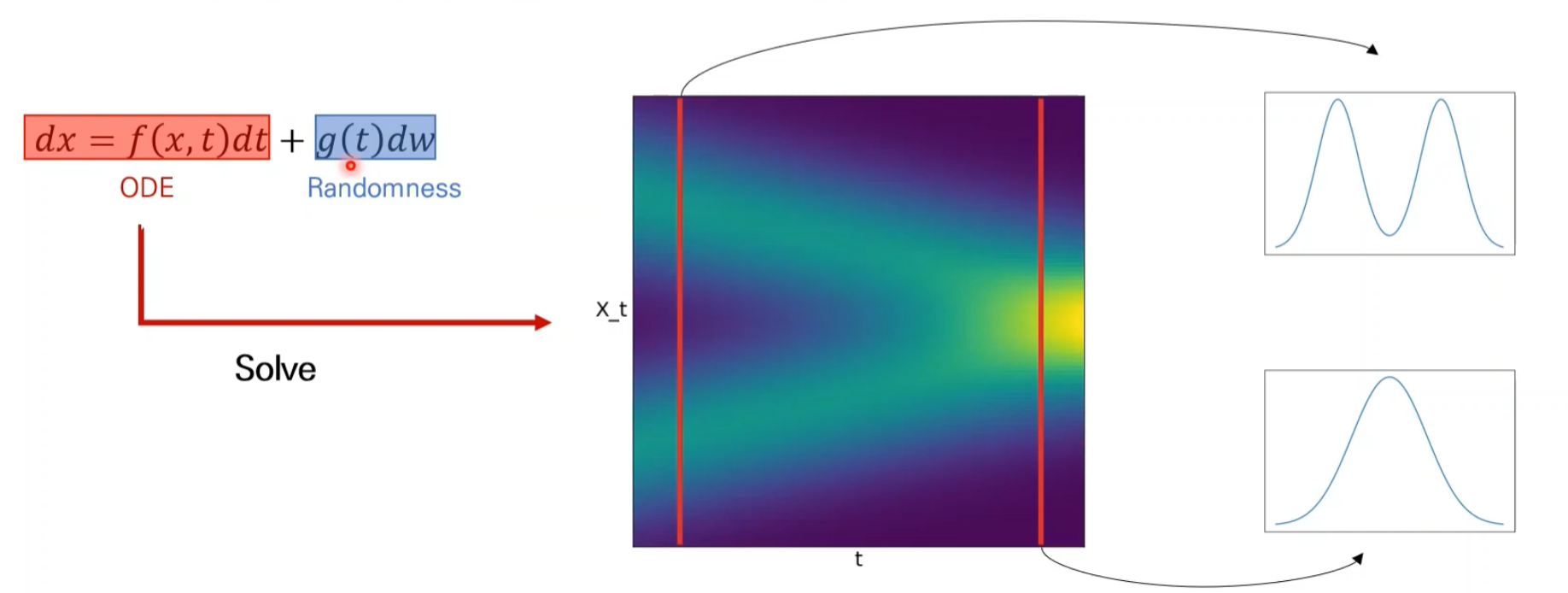
SDE를 푼다 = random process (확률 변수들의 나열)
확률 분포
NCSN = DDPM
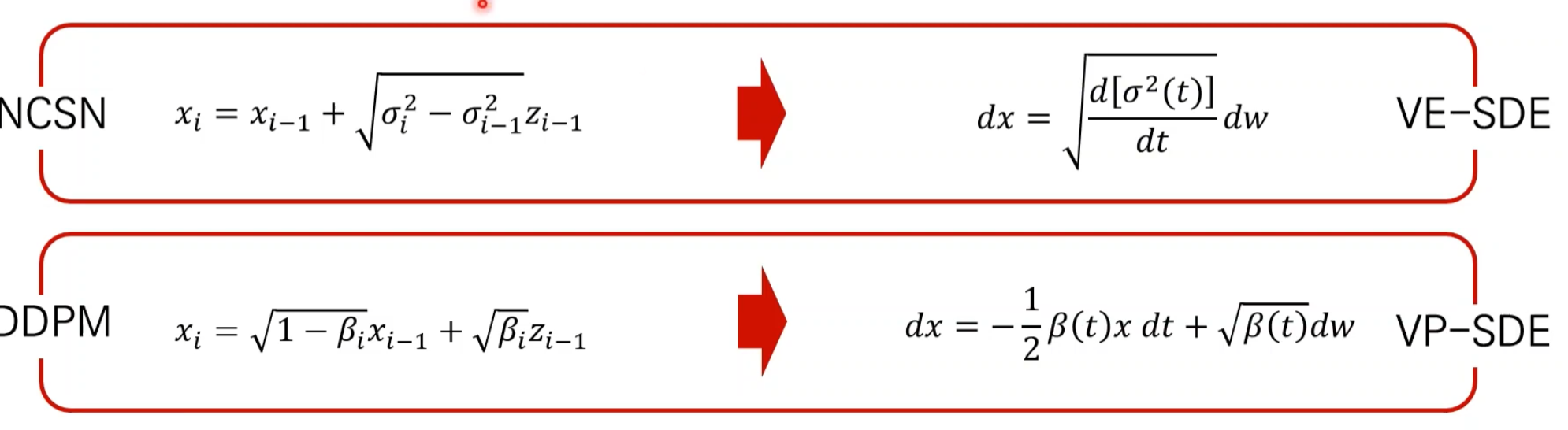
VE = variance exploding
VP = variance Preserving
결국 같음 → SDE로 통합
Testing
SDE를 풀 수 있는 다양한 solver가 있음

predictor : reverse SDE를 푸는 코드
corrector : Langevin dynamics를 적용하는 코드