
[논문분석] Efficient Streaming LLM for Speech Recognition
[paper]
ASR에 Decoder를 LLM으로 사용, LoRA finetuning
Abstract
Recent works have shown that prompting large language models with audio encodings can unlock speech recognition capabilities. However, existing techniques do not scale efficiently, especially while handling long form streaming audio inputs not only do they extrapolate poorly beyond the audio length seen during training, but they are also computationally inefficient due to the quadratic cost of attention. In this work, we introduce SpeechLLM-XL, a linear scaling decoder-only model for streaming speech recognition. We process audios in configurable chunks using limited attention window for reduced computation, and the text tokens for each audio chunk are generated auto-regressively until an EOS is predicted. During training, the transcript is segmented into chunks, using a CTC forced alignment estimated from encoder output. SpeechLLMXL with 1.28 seconds chunk size achieves 2.7%/6.7% WER on LibriSpeech test clean/other, and it shows no quality degradation on long form utterances 10x longer than the training utterances. Index Terms—Large language models, Speech recognition, Linear scaling.
I. INTRODUCTION
SpeechLLM을 통해 오디오 인코더가 음성을 임베딩으로 변환하면, LLM이 이를 바탕으로 텍스트를 생성하여 (SoTA)높은 정확도를 달성
SpeechLLM의 한계
하지만 긴 음성을 처리하는 데에는 다음과 같은 세 가지 주요 한계가 있습니다.
- 길이 extrapolation 능력 부족: 훈련 데이터보다 긴 음성이 입력되면, 모델이 텍스트 생성을 너무 일찍 중단하여 성능이 급격히 저하
- 높은 계산 비용: 디코더의 어텐션 메커니즘으로 인해, 음성 길이에 따라 추론 비용이 제곱으로 증가하여 비효율적
- 높은 지연 시간: 전체 음성을 한 번에 처리하는 non-streaming 방식이라, 긴 음성일수록 사용자가 체감하는 대기 시간 길다.
audio chunking 방법 사용
accuracy, latency trade off
1) 오디오 청크 크기는 모델 지연 시간을 제어
2) LLM 컨텍스트 크기는 어텐션 연산의 계산 비용을 제어
II. BACKGROUND ON SPEECHLLM
음성 X가 주어졌을 때 텍스트 y가 나타날 조건부 확률을 모델링
이전에 생성된 모든 토큰과 전체 음성 입력을 바탕으로 다음 토큰을 auto-regressive로 예측
\[X = (x_1, . . . , x_T )\]where $x_t ∈ \mathbb{R}^d$ denotes Log-Mel audio features
\[P_{\theta}(y|X) = P_{\theta}(\tilde{y}|X) = \prod_{u=1}^{U+1} P_{\theta}(y_u|y_{1:u-1}, X)\]X는 음성 특징, $y_ u$
는 u번째 텍스트 토큰, θ는 신경망 모델의 파라미터
Training
\[\theta = \arg \min_{\theta} - \frac{1}{N} \sum_{n=1}^{N} \sum_{u=1}^{U+1} \log P_{\theta}(y^{(n)}_u | y^{(n)}_{1:u-1}, X^{(n)})\]주어진 음성/텍스트 데이터 쌍에 대해 전체 훈련 데이터셋의 조건부 확률을 최대화하는 것을 목표
모든 토큰(EOS 포함)에 대한 평균 교차 엔트로피 손실(cross-entropy loss)을 최소화
Inference
주어진 음성 입력 X에 대해 빔 서치(beam search)와 같은 탐색 알고리즘을 사용하여 토큰을 순차적으로 생성
EOS($) 토큰이 생성되면 디코딩이 종료되고, 최종 결과에서 EOS 토큰은 제거
III. SPEECHLLM-XL

Fig. 1: Overview of the proposed model. (A) SpeechLLM-XL consists of an audio encoder, a LLM decoder, and a text embedding layer. The audio sequence is processed in static-length chunks, and the resulting audio encodings (denoted as alphabet) are interleaved with text embedding (denoted as numbers) according to audio-text alignment, and the entire sequence is fed into the LLM. The model is trained for next-token-prediction to generate text tokens for each chunk, plus an EOS token $ indicating the end-of-chunk. (B) We use a limited attention window in the LLM decoder to reduce computation. In this plot, the audio/text encodings in each chunk only attend to previous one chunk besides the current chunk (i.e. token 4 would attend to {a, b, c, d, 1, e, f, g, h, 2, 3, 4}). (C) During training, the audio-text alignment is computed using a CTC forced aligner to align audio encodings and text tokens.
Audio Chunking
audio/text pair X, y
- X into chunks ($X_1 . . . , X_k, . . . ,X_K$ ) with chunk size c
- y into chunks ($y_1 . . . , y_k, . . . ,y_K$ )
각 텍스트 청크($y_k$)의 끝에는 문장의 끝을 알리는 EOS($) 토큰 추가
\[P_{\theta}(\tilde{y}|X) = \prod_{k=1}^{K} P_{\theta}(\tilde{y}_k|X_k, \{\tilde{y}_{1:k-1}, X_{1:k-1}\})\]현재 오디오 청크(Xk)와 이전까지의 모든 오디오 및 텍스트 청크 ({$X_{1:k−1},\tilde{y}_{1:k−1}$})를 조건으로 현재 텍스트 청크($\tilde{y}_k$)의 확률을 계산
Context control
현재 청크(k)를 처리할 때, 이전 청크들의 어텐션 값을 캐시(cache)해두고 참조하여 문맥을 파악
컨텍스트 크기(b) 조절: 계산량을 줄이기 위해, 참조하는 이전 청크의 개수(b)를 하이퍼파라미터로 제한 → 긴 음성에서도 어텐션 계산 비용이 선형적으로 증가
Audio-text alignment
CTC Forced Alignment : CTC loss 를 통해 음성 인코딩과 텍스트 토큰 간의 정렬을 강제적으로 진행
실제 정렬 정보를 사용한 모델과 비슷한 정확도를 보임
Inference method
Alignment-Synchronous Search : neural transducer 에서 사용되는 beam search 알고리즘 사용
모든 후보 가설들은 동일한 수의 토큰을 갖도록 유지
IV. EXPERIMENTS
Setting
LibriSpeech 데이터셋 사용
80 channel log mell filter-bank (10ms frame shift, 25ms sliding window)
time reduction layer : stride 4 → 320차원 벡터가 인코더의 입력
Audio encoder : 20개 레이어로 구성된 스트리밍 Emformer 모델을 사용 (총 1억 7백만 개의 파라미터)
LLM decoder : Llama2를 축소한 12개 레이어 모델을 사용 (총 9천 2백만 개의 파라미터)
A. Chunk Size
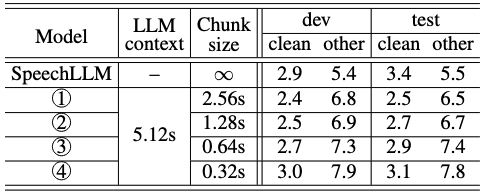
TABLE I: The effect of SpeechLLM-XL audio chunk size on model quality, where both the audio chunk size and LLM context size are measured in seconds. As the audio chunk size is reduced, the model latency is reduced at the cost of higher WER. The non-streaming SpeechLLM is included as a baseline.
지연 시간과 정확도 간의 균형을 확인하기 위해 오디오 청크 크기를 0.32초에서 2.56초까지 다양하게 조절하여 실험
LLM 컨텍스트 크기는 5.12초로 고정
- 긴 발화에 대한 우수성: 스트리밍 모델(2.56초 청크)은 기존의 비스트리밍 SpeechLLM 모델보다 긴 발화에서 발생하는 삭제 오류가 현저히 적어 더 나은 성능을 보임
- 이는 SpeechLLM-XL이 긴 형식의 음성에 더 적합하다는 가설을 뒷받침합니다.
- 최적의 균형점: 청크 크기를 줄이면 지연 시간은 줄지만 단어 오류율(WER)은 증가하는 경향을 보임, 연구에서는 1.28초의 청크 크기가 최적
B. LLM Context
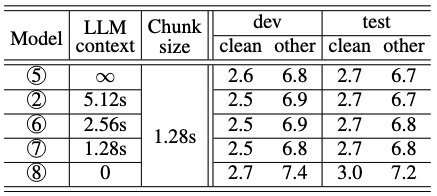
TABLE II: The effect of LLM left context size on WER. There is little degradation in accuracy as we reduce the LLM context from ∞ to 1.28s, until we completely removed all the previous chunks from the LLM context.
LLM이 얼마나 많은 과거 정보를 참조하는지(LLM 컨텍스트)가 모델 성능에 미치는 영향을 분석
오디오 청크 크기는 1.28초로 고정
- 적은 컨텍스트로도 충분: LLM 컨텍스트 크기를 전체에서 1.28초까지 줄여도 성능 저하가 거의 없음 적은 양의 컨텍스트만으로도 모델이 잘 작동하며, 추론 비용을 제곱에서 선형으로 줄일 수 있음을 의미
- 최소한의 컨텍스트는 필수: 그러나 컨텍스트를 완전히 제거했을 때(0초)는 성능이 눈에 띄게 저하 단순히 오디오를 분할하여 독립적으로 처리하는 방식은 효과적이지 않으며,이전 청크의 정보를 활용하는 것이 여전히 중요 함
C. CTC Forced Alignment
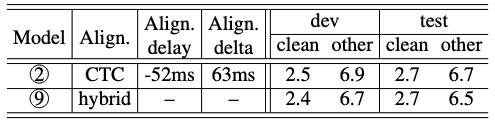
TABLE III: The quality of CTC forced alignment compared against the reference hybrid alignment. The CTC alignment is on-averaged 52ms ahead of the hybrid alignment, as indicated by the negative alignment delay. The SpeechLLM-XL model trained with reference hybrid alignment slightly out-performs CTC forced alignment.
하이브리드 모델 기반의 참조 정렬과 비교
- 정렬 품질: CTC 강제 정렬로 계산된 토큰의 종료 시간은 참조 정렬보다 평균 52ms 빨랐으며, 두 정렬 간의 평균 시간 차이(절대값)는 63ms로 매우 근소
- ASR 성능에 미치는 영향: 참조 정렬을 사용해 훈련한 모델이 CTC 강제 정렬을 사용한 모델보다 약간 더 나은 성능 이는 CTC 정렬 시 토큰 종료 시간이 약간 더 빠르게 예측되는 경향 때문일 수 있음
D. Length Extrapolation
훈련 데이터보다 긴 오디오를 처리하는 능력 실험
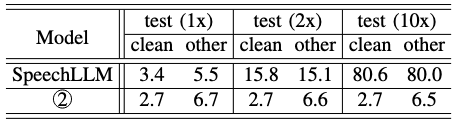
TABLE IV: The length extrapolation ability of SpeechLLM and SpeechLLM-XL, both of which are trained on regular LibriSpeech utterances. SpeechLLM significantly degrade when tested on concatenated utterances that are 2x of the training length. SpeechLLM-XL extrapolates to 10x of the training length with no quality degradation.
테스트 데이터를 여러 번 이어 붙여 길이를 2배, 10배로 늘려 실험을 진행
- 기존 모델의 한계: 기존 SpeechLLM 모델은 훈련 데이터보다 2배만 길어져도 단어 오류율(WER)이 3배 이상 급증하며 사실상 긴 음성 처리에 실패
- SpeechLLM-XL의 뛰어난 성능: 반면, SpeechLLM-XL은 훈련 데이터보다 10배 긴 오디오에서도 성능 저하 없이 완벽하게 동작
- 중요성: 이러한 길이 외삽 능력은 예측 불가능한 길이의 입력에 대해 모델을 더 강건하게 만들고, 훈련 효율성을 높이는 동시에 긴 음성에 대한 품질을 유지할 수 있게 해 중요함
V. ADDITIONAL BASELINES AND RELATED WORKS
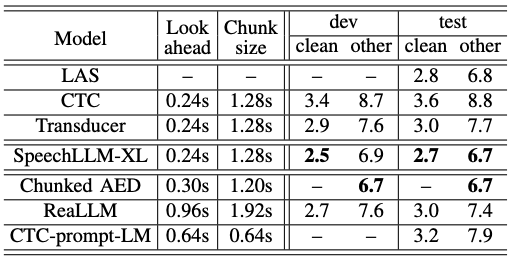
TABLE V: SpeechLLM-XL is competitive when compared to other streaming ASR models with similar latency and training recipe.
1. 고전적인 베이스라인 모델과의 비교
먼저, 널리 사용되는 고전적인 음성 인식 모델들과 성능을 비교했습니다.
- LAS (Listen, Attend and Spell): SpecAugment 데이터 증강 기법이 적용된 비스트리밍 모델입니다. 인코더는 BiLSTM, 디코더는 RNN 구조를 가집니다.
- 비교 결과: SpeechLLM-XL은 스트리밍 모델이고 모델 크기도 더 작음에도 불구하고, 비스트리밍인 LAS 모델보다 더 나은 성능을 보였습니다.
- CTC 및 Transducer: 연구진은 SpeechLLM-XL의 인코더와 유사한 구조를 가진 CTC 모델과 Transducer 모델을 직접 훈련하여 비교했습니다. 이 모델들은 SpeechLLM-XL보다 파라미터 수가 훨씬 큽니다 (CTC 2억 4600만, Transducer 2억 5600만).
- 비교 결과: SpeechLLM-XL은 두 모델보다 파라미터 수가 훨씬 적음에도 불구하고 눈에 띄게 더 나은 성능을 기록했습니다.
2. 다른 스트리밍 인코더-디코더(AED) 모델과의 비교
다음으로, 스트리밍 ASR을 위해 제안된 다양한 인코더-디코더(AED) 모델들과 비교했습니다.
- Chunked AED: 이 모델은 SpeechLLM-XL과 유사하게 ‘청킹(chunking)’ 아이디어를 활용하는 가장 관련성 높은 최신 연구입니다.
- 비교 결과: SpeechLLM-XL은 Chunked AED와 비슷한 인코더 및 디코더 조건 하에서 유사한 단어 오류율(WER)을 보였습니다.
- 주요 차이점: SpeechLLM-XL의 가장 큰 차별점은 셀프-어텐션 기반의 디코더-온리 아키텍처를 사용한다는 것입니다. 이 구조 덕분에 이미 널리 사용되는 사전 훈련된 LLM과 통합하기가 훨씬 용이하다는 장점이 있습니다.
3. 다른 디코더-온리 스트리밍 모델과의 비교
마지막으로, 스트리밍 ASR을 위한 다른 디코더-온리 모델들과 비교했습니다. 이 분야는 아직 많이 연구되지 않은 영역입니다.
- ReaLLM: 각 인코더 프레임이 LLM을 프롬프트하여 텍스트를 생성하게 하는 최신 연구입니다. 이 모델은 계산량이 오디오 길이에 따라 제곱으로 증가하는 단점이 있습니다.
- 비교 결과: SpeechLLM-XL은 ReaLLM보다 더 적은 인코더 지연 시간과 더 작은 디코더 청크 크기를 사용함에도 불구하고 훨씬 더 나은 성능을 보였습니다.
- CTC-prompt-LM: CTC 인코더에서 생성된 프레임들을 필터링하여 LLM의 프롬프트로 사용하는 관련 연구입니다. 이 연구에서는 CTC 강제 정렬이 잘 작동하지 않아 다른 방식을 사용했으며, 청크의 끝을 결정하기 위해 CTC와 디코더 점수를 융합하는 복잡한 빔 서치 방식을 사용합니다.
- 비교 결과: SpeechLLM-XL은 CTC-prompt-LM 모델보다 훨씬 더 큰 차이로 우수한 성능을 보였습니다.