[논문분석] Reuse and Diffuse: Iterative Denoising for Text-to-Video Generation
LDM에 영감을 얻은 framework called ``Reuse and Diffuse’’
[Page, Paper, Code]
Jiaxi Gu, Shicong Wang
1. Introduction
-
LDM 활용, VidR모델 제안 (Reuse and Diffuse)
Conditioned on an initial video clip with a small number of frames, additional frames are iteratively generated by reusing the original latent features and following the previous diffusion process. Besides, for the autoencoder used for translation between pixel space and latent space, we inject temporal layers into its decoder and fine-tune these layers for higher temporal consistency. We also propose a set of strategies for composing video-text data that involve diverse content from multiple existing datasets including video datasets for action recognition and image-text datasets.
- We propose VidRD, an iterative text-to-video generation method that leverages a temporal- aware LDM to generate smooth videos. By reusing the latent features of the initially generated video clip and imitating the previous diffusion process each time, the following video frames can be produced iteratively.
- A set of effective strategies is proposed to compose a high-quality video-text dataset. We use LLMs to segment and caption videos from action recognition datasets. Image-text datasets are also used by transforming into pseudo-videos with random zooming and panning.
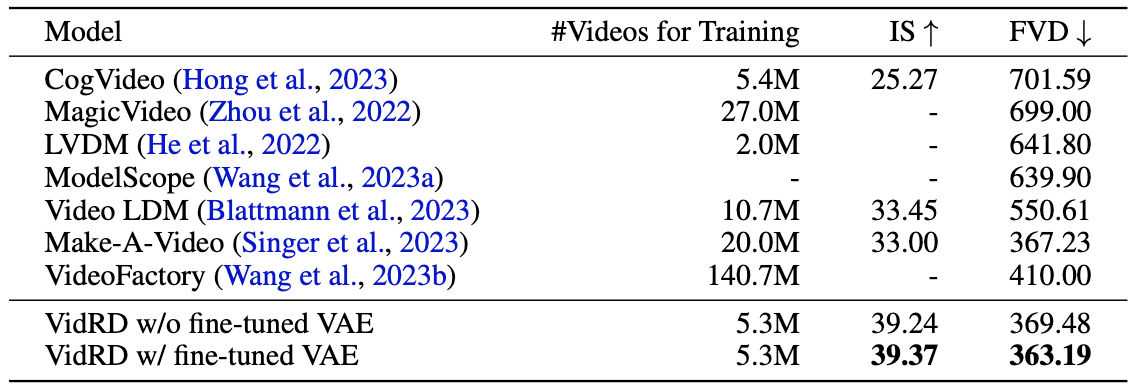
- Extensive experiments on the UCF-101 benchmark demonstrate that VidRD achieves good FVD and IS in comparison with existing methods. Qualitative evaluations also show good results.
이 연구에서는 텍스트를 비디오로 변환하는 새로운 프레임워크인 “Reuse and Diffuse” (VidRD)를 제안하고 있습니다. VidRD는 이전에 생성된 비디오 프레임을 재사용하고 이전의 확산 과정을 모방하여 더 일관성 있는 비디오 프레임을 생성합니다. 이 모델은 효율적인 훈련을 위해 사전 훈련된 이미지 합성용 LDM을 기반으로 하며, Frame-level Noise Reversion (FNR), Past-dependent Noise Sampling (PNS), 그리고 Denoising with Staged Guidance (DSG)라는 세 가지 새로운 모듈을 포함하고 있습니다.
또한, 이 연구에서는 고품질 비디오-텍스트 데이터의 부족 문제를 해결하기 위해 기존 데이터셋을 활용하는 전략을 제시합니다. 이는 행동 인식용 비디오 데이터셋과 이미지-텍스트 데이터셋을 포함하며, 이미지를 무작위로 확대하고 패닝하여 가상의 비디오를 생성함으로써 비디오의 시각적 내용을 크게 풍부하게 만듭니다.
2. Latent Diffusion Models
large amounts of computational and memory resources, DMs in pixel space are costly.
so, latent space 추가
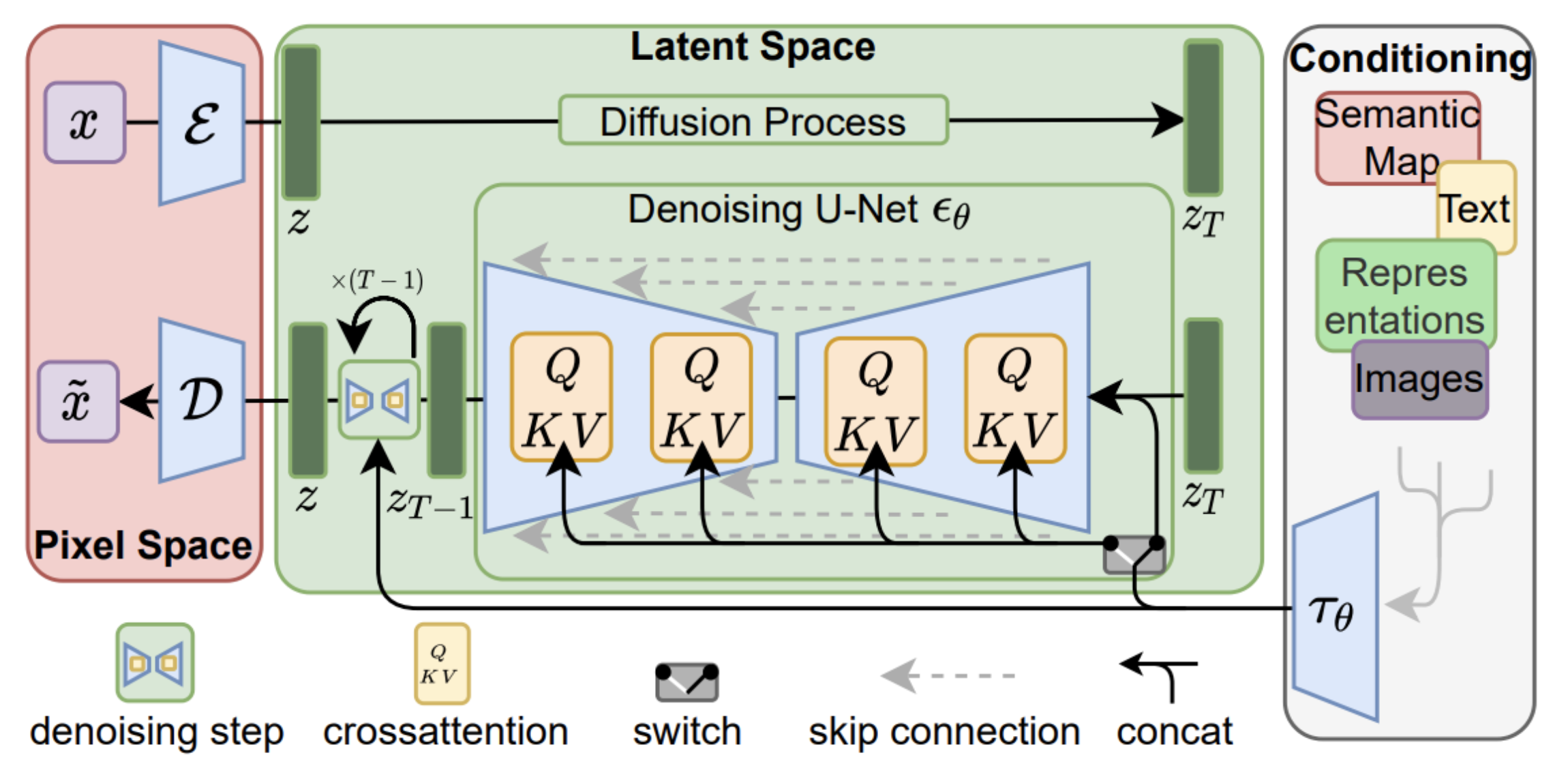
in stabel diffusion
2.1 Model Architecture
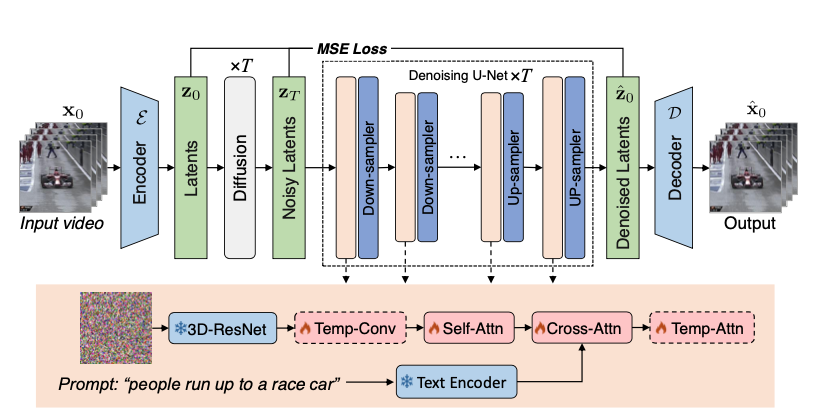
VidRD is based on the pre-trained Stable Diffusion + VAE + U-Net
가장 겉에 VAE
\(\mathbf{x} ∈ R^{B×F×3×H^′×W^′}\) , \(\mathbf{z} = E(x) ∈ R^{B×F×C×H×W }\)

비디오 프레임 간에 시간적 관계 강화를 위해 Temp Conv, Temp attention 두개 추가
이외에 모델들은 the pre-trained model weights of Stable Diffusion 사용
-
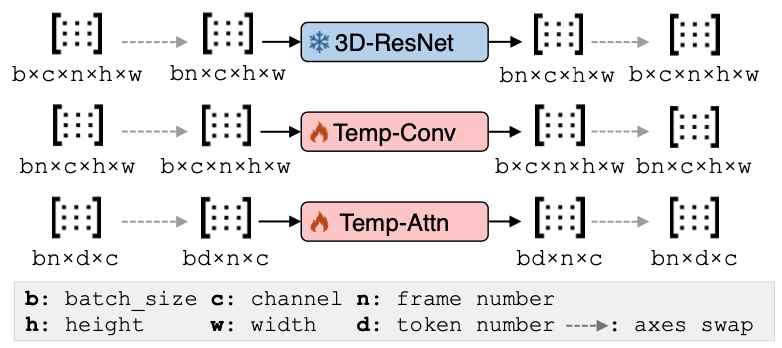
3D ResNet
3D ResNet은 3차원 데이터를 처리하는 데 특화된 신경망
비디오나 3D 이미지와 같은 3차원 데이터에서 공간적 및 시간적 특징을 동시에 학습
3D ResNet의 핵심 구성 요소는 3D 컨볼루션 레이어입니다. 이 레이어는 입력 데이터의 너비, 높이, 그리고 깊이(시간 또는 z축)에 대해 컨볼루션 연산을 수행하여, 3차원 데이터의 공간적 및 시간적 특징을 동시에 학습
(residual connection)도 3D ResNet에 적용 이는 신경망이 깊어질수록 발생하는 그래디언트 소실 문제를 완화하고, 신경망의 학습을 안정화하는 데 도움
-
Temporal Convolution
Temporal Convolution은 시간에 따른 데이터의 패턴을 학습하는 데 사용되는 기법입니다1. 이 기법은 입력 데이터의 시간 축에 대해 컨볼루션 연산을 수행하여 시간에 따른 패턴을 학습합니다1. Temporal Convolution은 주로 Temporal Convolutional Networks (TCNs)와 같은 모델에서 사용되며, 이 모델들은 시계열 데이터의 장기적인 의존성을 학습하는 데 효과적입니다1.
-
Temporal Attention
Temporal Attention은 시계열 데이터에서 중요한 시간 단계를 자동으로 식별하고 강조하는 기법입니다2. 이 기법은 모델이 시간에 따른 패턴을 학습하면서, 어떤 시간 단계가 가장 중요한 정보를 제공하는지를 학습합니다2. 이렇게 하면 모델은 불필요한 정보를 필터링하고 중요한 정보에 집중할 수 있습니다2.
Convolution은 시간에 따른 패턴을 학습하는 데 초점을 맞추고, Temporal Attention은 중요한 시간 단계를 식별하고 강조하는 데 초점을 맞춥니다
Cross Attention에서 video와 text caption 결합
파란색 부분이 frozen (파라미터 고정 부분) 빨간색 부분이 learnable parameter
-
U-Net
기존방식
이미지 데이터와 비디오 데이터를 사용하는 방식: 첫 번째 방식에서는 이미지 데이터를 사용하여 공간 레이어를 미세 조정하고, 비디오 데이터를 사용하여 시간 레이어를 훈련합니다. 이 방식은 공간적 특징과 시간적 특징을 별도로 학습하므로, 각각의 데이터 유형에 가장 적합한 특징을 추출할 수 있습니다. temporal, spital
본 논문 방식
순수 비디오 데이터를 사용하는 방식: 두 번째 방식에서는 U-Net이 순수 비디오 데이터만을 사용하여 통합적인 방식으로 훈련됩니다. 이 방식에서는 이미지 데이터가 시간적 일관성을 보이는 가상의 비디오로 변환되어 사용됩니다. 이렇게 하면 모델은 원래의 비디오 데이터와 유사한 방식으로 이미지 데이터를 처리할 수 있습니다.
2.2 Video-Text Data Composition
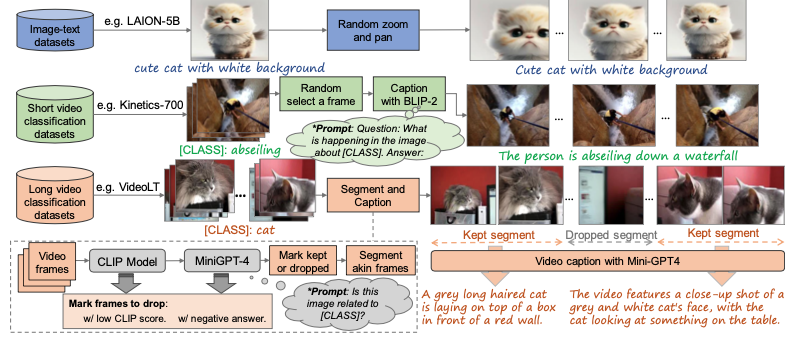
caption 제작할 때 다음 3가지 방법 사용
- Image-text datasets
- Short video classification datasets
- Long video classification datasets. → MiniGPT-4
2.3 Longer Video Generation
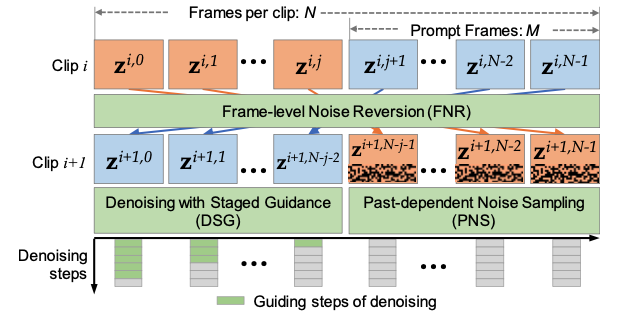
separate prediction model for generating the new video frames following the already generated frames
an iterative approach with a single diffusion model without fine-tuning
총 N개의 프레임 생성 그 속에서 M개 프레임 (하나의 클립에 총 N개의 frame)

To this end, three key strategies are proposed including Frame-level Noise Reversion (FNR), Past-dependent Noise Sampling (PNS), and Denoising with Staged Guidance (DSG).
Frame-level Noise Reversion.
\[\mathbf{z}_0,j ∼\mathcal{N}(0,I), j∈{0,1,...,N−1}\]초기 노이즈 → video의 다양성을 높혀줌
비디오 프레임 전체에 결쳐 기본 노이즈를 공유 → 전반적인 일관성에 도움을 줌
FNR : 클립간의 일관성을 위해 clip간에 초기 노이즈를 세팅
하지만 FNR alone cannot guarantee that videos are natural and smooth and the video content may simply become repetitive within a single clip in some extreme cases.
Past-dependent Noise Sampling
비디오 콘텐츠의 순환을 완화하기 위해, 원래의 무작위 노이즈를 단순히 반복해서 재사용하는 것만으로는 충분하지 않습니다. 따라서 초기 클립 이후 생성되는 비디오 클립과 함께 무작위성이 도입되어야 합니다.
현재 비디오 클립의 생성을 유도하는 M 프레임을 제외하고, 남은 N - M 프레임의 초기 노이즈에 무작위 노이즈가 추가됩니다. 이 남은 프레임들은 이전 비디오 클립의 N - M 프레임으로 초기화됩니다.
이 기법은 비디오의 시간적 일관성을 유지하면서도 다양한 콘텐츠를 생성하는 데 도움이 됩니다. 이는 비디오 생성 모델이 실제 비디오 데이터와 유사한 방식으로 시간적 변화를 모델링할 수 있게 해줍니다. 이러한 접근 방식은 비디오 생성의 품질을 향상시키는 데 중요한 역할을 합니다.
\[\mathbf{z}_T^{i,j}= \begin{cases} \mathbf{z}_T^{i−1,N−j−1}, & \mathrm{if}\ j < M \\ {α\over \sqrt{1+α^2}} \mathbf{z}_T^{i−1,N−j−1} + ε^{i,j}, & \mathrm{otherwise} \end{cases} , ε^{i,j}∼\mathcal{N}(0, {1 \over 1 + α^2} I),α≥0\]Denoising with Staged Guidance.
DSG는 이미 생성된 i번째 비디오 클립이 주어졌을 때, i + 1번째 클립의 시작 비디오 프레임을 i번째 클립의 M 프롬프트 프레임을 따라 높은 시간적 일관성으로 생성하는 것을 목표로 합니다. DSG의 접근 방식은 i번째 클립을 생성하는 데 있는 DDIM 과정에서 잠재 특징을 재사용하여 일부 노이즈 제거 단계를 복제하는 것을 포함합니다.
동시에, 비디오 프레임의 중복을 피하고 역순으로 순서를 바꾸는 것을 피하기 위해, 가이드를 사용한 노이즈 제거를 위한 단계적 전략이 제안됩니다. 구체적으로, 다음과 같은 수식이 제안됩니다:
\[\mathbf{z}_{t-1}^{i,j}= \begin{cases} \mathbf{z}_{t-1}^{i−1,N−j−1}, & \mathrm{if}\ t>(1-\beta)T + {\beta Tj\over M} \\ DDIM(\mathbf{z}_{t}^{i,j},t) , & \mathrm{otherwise} \end{cases} , \ \ \ \beta \in [0,1]\]\(\beta\) : 가이드 노이즈 제거의 정도 if \(\beta = 0\) 비디오 클립의 참조 없이 완전히 DDIM 샘플링으로 노이즈 제거
\(J < M\) 일 경우 더 많은 가이드 제공
2.5 Temporal-Award Decoder Fine-Tuning
Stable Diffusion이라는 원래의 autoencoder는 이미지 합성에 특화되어있다. 따라서 비디오 합성의 성능을 향상시키기 위해 비디오 데이터로 미세 조정하는 것이 필요하다
Autoencoder는 encoder와 decoder를 포함하는 구조로, 이 구조는 Figure 6에 나와 있습니다. 미세 조정 과정에서 encoder는 변경되지 않고, 가중치는 고정됩니다. 또한, 디코딩 후의 시간적 일관성을 향상시키기 위해, 각 블록의 ResNet 다음에 Temp-Conv 레이어를 추가합니다. 효율적인 미세 조정을 위해, 새로 추가된 Temp-Conv 레이어만이 학습 가능합니다.
또한, 이미지용 autoencoder에서 더 잘 적응하기 위해, Temp-Conv의 마지막 레이어를 0으로 초기화하고 잔차 연결을 적용합니다.
따라서, 비디오 합성의 성능을 향상시키기 위해 원래의 autoencoder를 비디오 데이터로 미세 조정하는 방법입니다. 이 과정은 모델이 비디오 데이터의 시간적 패턴을 더 잘 학습하고, 더 고품질의 비디오를 생성하는 데 도움이 됩니다.
encoder 미세 조정
\[\mathcal{L} = α_{rec}\mathcal{L}_{rec}(\mathbf{x}, \mathcal{D}(\mathcal{E}(\mathbf{x})) + α_{reg}\mathcal{L}_{reg}(\mathbf{x}; \mathcal{E}, \mathcal{D}) + α_{disc}\mathcal{L}_{disc}(\mathcal{D}(\mathcal{E}(\mathbf{x}))\]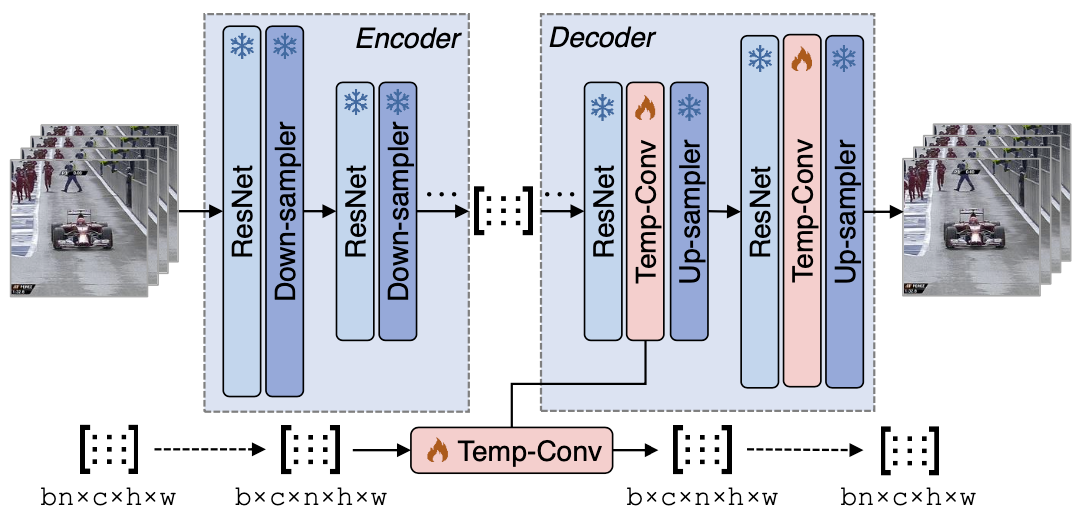
3. Experiments
3.1 Setup
Model architecture and sampling. To exploit the ability of image synthesis models, we use the pre-trained weights of Stable Diffusion v2.1 to initialize the spatial layers of our model. Both the VAE and the text encoder are frozen after they are initialized with pre-trained weights from Stable Diffusion. During model training, only the newly added temporal layers and transformer blocks of the spatial layers are trainable. Since our model is essentially an LDM, VAE of Stable Diffusion but with a fine-tuned decoder is used for latent representation. For LDM sampling, we use DDIM (Song et al., 2021) in all our experiments.
Datasets. 1) Well-captioned video-text datasets 2) Short video classification datasets 3) Long video classification datasets 4) Image datasets **

Evaluation metrics
(i) Fre ́chet Video Distance (FVD) (ii) Inception Score (IS)
3.2 Result