
[논문분석] Lumiere: A Space-Time Diffusion Model for Video Generation
high quality video generation, Google Research [Page, Paper] Google Research, Weizmann Institute, Tel-Aviv University, Technion
Abstract
We introduce Lumiere a text-to-video diffusion model designed for synthesizing videos that portray realistic, diverse and coherent motion a pivotal challenge in video synthesis. To this end, we introduce a Space-Time U-Net architecture that generates the entire temporal duration of the video at once, through a single pass in the model. This is in contrast to existing video models which synthesize distant keyframes followed by temporal super-resolution an approach that inherently makes global temporal consistency difficult to achieve. By deploying both spatial and (importantly) temporal down-and up-sampling and leveraging a pre-trained text-to-image diffusion model, our model learns to directly generate a full-frame-rate, low-resolution video by processing it in multiple space-time scales. We demonstrate state-of-the-art text-to-video generation results, and show that our design easily facilitates a wide range of content creation tasks and video editing applications, including image-to-video, video inpainting, and stylized generation.
video generation을 위한 모델 구조 변경
- image generation model을 활용
- task를 나눠 layer를 쌓는 구조의 한계를 알고 모델이 한번에 받아서 처리할 수 있도록 함
Introduction
SOTA text-to-image(T2I) diffusion model은 이제 복잡한 텍스트 프롬프트를 준수하는 고해상도의 사실적인 이미지를 합성할 수 있으며 광범위한 이미지 편집 및 기타 다운스트림 작업이 가능
이미지 생성은 이미 뛰어남을 인정
대규모 text-to-video(T2V) 기반 모델을 학습시키는 것은 모션으로 인한 추가 복잡성으로 인해 여전히 해결되지 않은 과제
- 자연스러운 움직임을 모델링할 때 오차에 민감
- 추가된 시간 데이터 차원으로 인해 메모리 및 컴퓨팅 요구 사항 증가
- 복잡한 분포를 학습하는 데 필요한 학습 데이터의 규모 측면에서 심각한 문제 발생
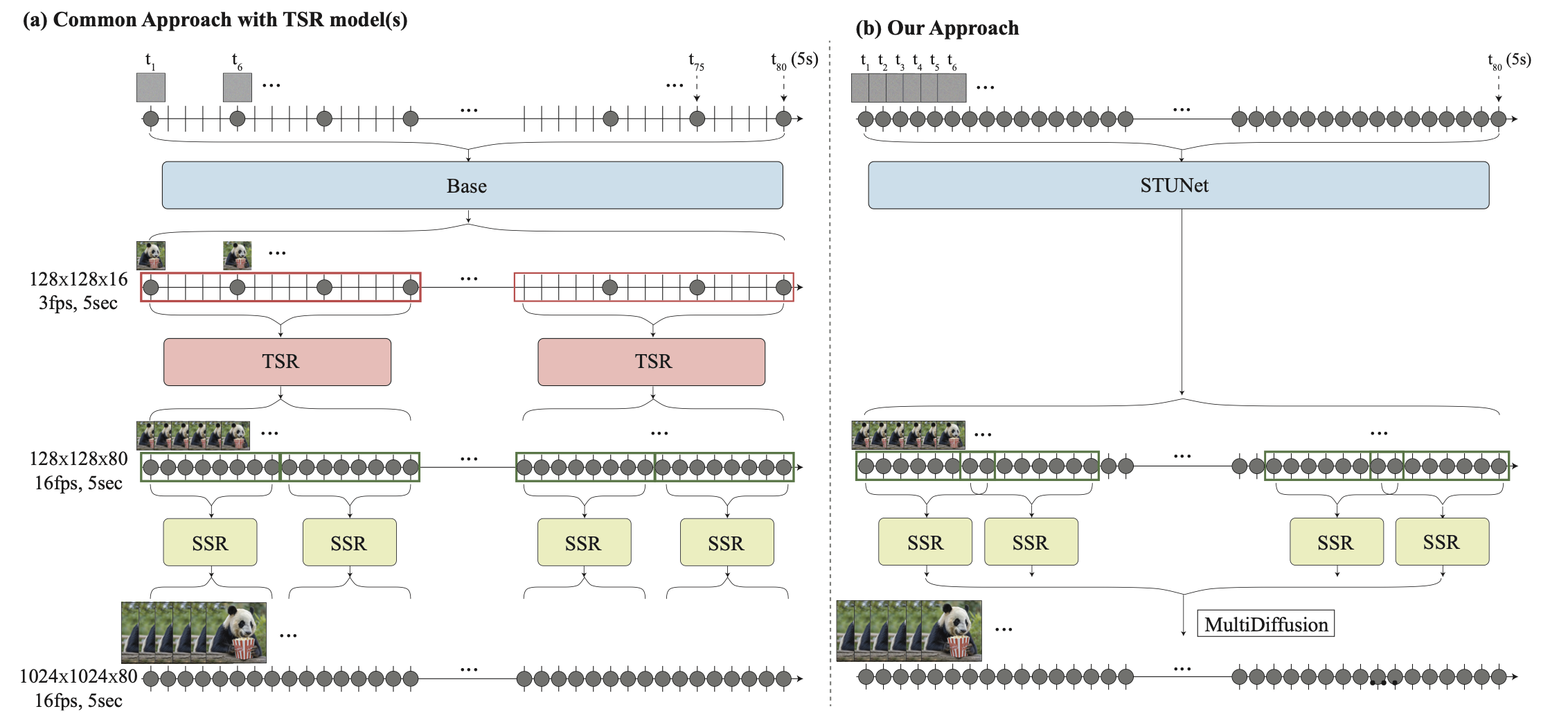
기존 모델들은 동영상 길이, 전반적인 시각적 품질, 생성할 수 있는 사실적인 모션의 정도 측면에서 여전히 제한적
- Base model은 공격적으로 서브샘플링된 키프레임 세트를 생성한다. 여기서 빠른 모션은 일시적으로 앨리어싱되어 모호해진다.
- TSR 모듈은 작고 고정된 시간적 context window으로 제한되므로 전체 동영상에서 앨리어싱 모호성을 일관되게 해결할 수 없다 (ex. 걷기와 같은 주기적인 동작을 합성하는 경우).
- 계단식 학습 방식은 일반적으로 도메인 차이를 겪는다. TSR 모델은 실제 다운샘플링된 동영상 프레임에 대해 학습되지만 inference 시 생성된 프레임을 보간하는 데 사용되어 오차가 누적된다.
본 논문은 동영상 전체를 한 번에 생성하는 새로운 T2V diffusion 프레임워크 제안
공간과 시간 모두에서 신호를 다운샘플링하는 방법을 학습하고 대부분의 계산을 컴팩트한 시공간 표현으로 수행하는 Space-Time U-Net (STUNet) 아키텍처를 사용 ( - > 16fps의 80프레임(5초)을 생성 )
한번에 이루어지기에 일관된 모션 얻을 수 있음
(아키텍처에 공간적 다운샘플링 및 업샘플링 연산만 포함) 해상도 유지 옵션 제거
저자들은 T2I 모델의 강력한 generative prior를 활용하기 위해 사전 학습된 T2I 모델 위에 Lumiere를 구축
T2I 모델은 픽셀 공간에서 작동, base model과 spatial super-resolution (SSR) 네트워크의 계단식 구조
SSR 네트워크는 높은 공간 해상도에서 작동하기 때문에 동영상 전체에 적용하는 것은 메모리 요구 사항 측면에서 불가능
일반적인 SSR은 동영상을 겹치지 않는 세그먼트로 분할하고 결과를 함께 연결하는 temporal windowing 접근 방식을 사용 → 이로 인해 window 사이의 경계에서 결과가 일관되지 않을 수 있음
저자들은 파노라마 이미지 생성에서 글로벌 연속성을 위해 제안된 접근 방식인 Multidiffusion을 시간 도메인으로 확장하여 temporal window에서 SSR을 계산하고 결과를 전체 동영상 클립에 대해 글로벌하게 일관되게 집계하는 것을 제안
Lumiere
Space-Time U-Net
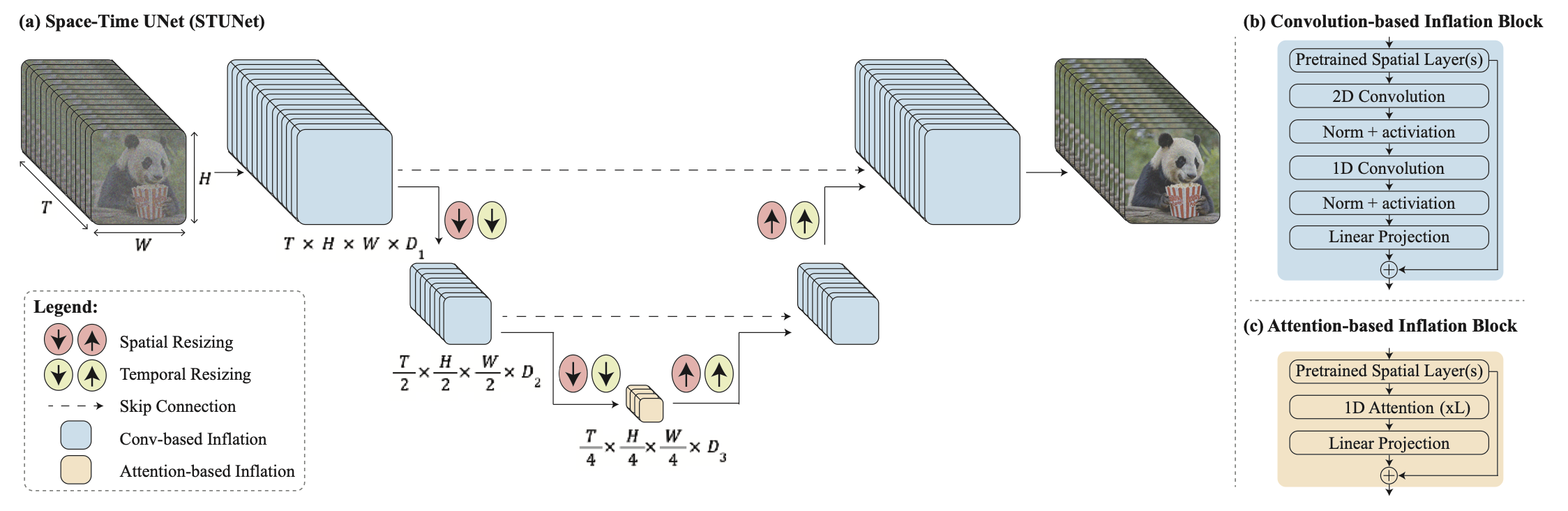
사전 학습된 각 spatial resizeing 모듈 뒤에 시간적 다운샘플링 모듈과 업샘플링 모듈을 삽입
프레임워크는 기본 모델과 공간 초고해상도(SSR) 모델로 구성
그림에서 볼 수 있듯이, 기본 모델은 거친 공간 해상도로 전체 클립을 생성
기본 모델의 출력은 시간 인식 SSR 모델을 사용하여 공간적으로 업샘플링되어 고해상도 비디오가 생성
Space-Time U-Net (STUnet)
space-time U-Net 사용
T2I 아키텍처에서 temporal block을 인터리브((특히 얇은 막 같은 것을) 끼우다)하고, 사전 학습된 각 공간 크기 조정 모듈에 따라 temporal down 및 up sampling 모듈을 삽입
temporal block은 temporal convolution(그림 4b)과 temporal attention(그림 4c)를 포함합니다. 특히, 가장 거친 레벨을 제외한 모든 레벨에 인수분해 시공간 컨볼루션(그림 4b)을 삽입하여 풀-3D 컨볼루션에 비해 네트워크의 비선형성을 높이면서 계산 비용을 줄이고, 1D 컨볼루션에 비해 표현력을 높임.
temporal attention의 계산 요구 사항은 프레임 수에 따라 4제곱으로 증가하기 때문에 동영상의 시공간 압축 표현을 포함하는 가장 낮은 해상도에서만 temporal attention이 통합
프레임 수에 따른 4제곱 증가:
- 2D 어텐션의 경우 계산량은 입력 크기의 2제곱에 비례합니다. 그러나 Temporal Attention은 시간적 차원까지 포함하므로, 여기서 계산량이 4제곱으로 증가합니다.
- 예를 들어, 프레임 수가 10개일 때는 계산량이 10^4 = 10,000입니다. 그러나 프레임 수가 20개로 늘어나면 계산량은 20^4 = 160,000으로 증가합니다.
저차원 피처 맵에서 작업하면 제한된 계산 오버헤드로 여러 개의 템포럴 어텐션 블록을 쌓을 수 있습니다.
Align your latents: High- resolution video synthesis with latent diffusion models. 논문에서 제안된 바와 같이 새로 추가된 파라미터를 훈련하고, 사전 훈련된 T2I의 가중치는 고정된 상태로 유지
특히, 일반적인 인플레이션 접근법은 초기화 시 T2V 모델이 사전 학습된 T2I 모델과 동등하게, 즉 독립적인 이미지 샘플의 모음으로 비디오를 생성하도록 보장합니다. 그러나 우리의 경우 시간적 다운 샘플링과 업 샘플링 모듈로 인해 이 속성을 충족하는 것이 불가능합니다. 경험적으로 이러한 모듈을 가장 가까운 이웃의 다운 샘플링과 업 샘플링을 수행하도록 초기화하면 좋은 출발점을 얻을 수 있다는 것을 발견했습니다(앱 B 참조).
Multidiffusion for Spatial-Super Resolution
메모리 제약으로 인해 확장된 SSR 네트워크는 동영상의 짧은 세그먼트에서만 작동
시간적 경계에서 발생하는 아티팩트를 방지하기 위해 시간 축을 따라 Multidiffusion을 사용
각 generation step, noisy 한 비디오 입력 \(J ∈ \mathbb{R}^{H ×W ×T ×3}\) 를 \(\{J_i\}^N_{i=1}\)의 겹치는 세그먼트 집합으로 분할
\(J_i ∈ \mathbb{R}^{H ×W ×T ' ×3}\) ( i 번째 segment + 지속 시간이 T ′ < T )
세그먼트별 SSR 예측을 조정하기 위해 \(\{Φ(Ji)\}^N_{i=1}\) , 노이즈 제거 단계의 결과를 최적화 문제의 해로 정의
\[\arg\min_{J'} \sum_{i=1}^{n} \|J' - \Phi(J_i)\|^2.\]Applications
추가 layer가 적기 때문에 쉽게 downstream 수행 가능
Stylized Generation
단순한 ‘플러그 앤 플레이’ 접근 방식은 종종 왜곡되거나 정적인 동영상을 생성하는 것으로 관찰 → 이는 미세 조정된 공간 레이어에서 시간 레이어로의 입력 분포가 크게 편차되어 발생한다는 가설을 세움
GAN 기반 보간 접근법(Pinkney & Adler, 2020)의 성공에 영감을 받아, 미세 조정된 T2I 가중치인 Wstyle과 원래 T2I 가중치인 Worig를 선형적으로 보간하여 스타일과 동작 사이의 균형을 맞추는 방법을 선택
\[W_{\mathrm{interpolate}} = α W_{\mathrm{style}} + (1 - α) - W_{\mathrm{orig}}\]
Figure 6: Stylized Generation. Given a driving style image and its corresponding set of fine-tuned text-to-image weights, we perform linear interpolation between the fine-tuned and pre-trained weights of the model’s spatial layers. We present results for (A) vector art styles, and (B) realistic styles. The results demonstrate Lumiere’s ability to creatively match a different motion prior to each of the spatial styles (frames shown from left to right). See Sec. 4.1 for details.
“수채화”와 같이 보다 사실적인 스타일은 사실적인 모션을 생성하는 반면, 벡터 아트 스타일에서 파생된 다른 덜 사실적인 공간 선행은 그에 상응하는 독특한 비현실적인 모션을 생성