
[논문분석] Latte: Latent Diffusion Transformer for Video Generation
diffusion model에 Transformer 구조 사용, video generation model [Code, Paper]
Abstract
We propose a novel Latent Diffusion Transformer, namely Latte, for video generation. Latte first extracts spatio-temporal tokens from input videos and then adopts a series of Transformer blocks to model video distribution in the latent space. In order to model a substantial number of tokens extracted from videos, four efficient variants are introduced from the perspective of decomposing the spatial and temporal dimensions of input videos. To improve the quality of generated videos, we determine the best practices of Latte through rigorous experimental analysis, including video clip patch embedding, model variants, timestep-class information injection, temporal positional embedding, and learning strategies. Our comprehensive evaluation demonstrates that Latte achieves state-of-the-art performance across four standard video generation datasets, i.e., FaceForensics, SkyTimelapse, UCF101, and Taichi-HD. In addition, we extend Latte to text-to-video generation (T2V) task, where Latte achieves comparable results compared to recent T2V models. We strongly believe that Latte provides valuable insights for future research on incorporating Transformers into diffusion models for video generation. Project page: https://maxin-cn.github.io/latte project.
저희는 비디오 생성을 위해 새로운 잠재 확산 트랜스포머, 즉 Latte를 제안합니다. Latte는 먼저 입력 비디오에서 시공간적 토큰을 추출한 다음 일련의 트랜스포머 블록을 채택하여 잠재 공간에서 비디오 분포를 모델링합니다. 동영상에서 추출된 상당한 수의 토큰을 모델링하기 위해 입력 동영상의 공간적, 시간적 차원을 분해하는 관점에서 네 가지 효율적인 변형을 도입합니다. 생성된 비디오의 품질을 향상시키기 위해 비디오 클립 패치 임베딩, 모델 변형, 타임스텝 클래스 정보 주입, 시간적 위치 임베딩 및 학습 전략을 포함한 엄격한 실험 분석을 통해 Latte의 모범 사례를 결정합니다. 종합적인 평가 결과, 라떼는 네 가지 표준 비디오 생성 데이터 세트, 즉 FaceForensics, SkyTimelapse, UCF101, Taichi-HD에서 최첨단 성능을 달성하는 것으로 입증되었습니다. 또한 Latte를 텍스트-비디오 생성(T2V) 작업으로 확장하여 최신 T2V 모델과 비교했을 때 비슷한 결과를 얻을 수 있습니다. 라떼는 향후 비디오 생성 확산 모델에 트랜스포머를 통합하는 연구에 귀중한 통찰력을 제공할 것으로 확신합니다.
Introduction
이미지 애플리케이션에 비해 고품질 비디오를 생성하는 데는 여전히 상당한 어려움이 있으며, 이는 주로 고해상도 프레임 내에 복잡한 시공간 정보를 포함하는 비디오의 복잡하고 고차원적인 특성 때문일 수 있습니다. 동시에 연구자들은 확산 모델의 성공에 있어 백본을 혁신하는 것이 중요하다는 사실을 밝혀냈습니다
DiT는 U- Net의 유도적 편향이 잠재 확산 모델의 성능에 중요하지 않다는 것을 입증했습니다. 반면, 주의 기반 아키텍처(Vaswani et al, 2017)는 동영상에서 장거리 텍스트 관계를 캡처할 수 있는 직관적인 옵션을 제공합니다. 따라서 매우 자연스러운 질문이 생깁니다: 트랜스포머 기반의 잠재 확산 모델이 사실적인 동영상 생성을 향상시킬 수 있을까요?
비디오 트랜스포머를 백본으로 채택한 새로운 비디오 생성용 잠재적 디퓨전 트랜스포머, 즉 Latte를 제안
Latte는 사전 학습된 변형 자동 인코더를 사용하여 입력 비디오를 잠재 공간의 피처로 인코딩하고, 인코딩된 피처에서 토큰을 추출
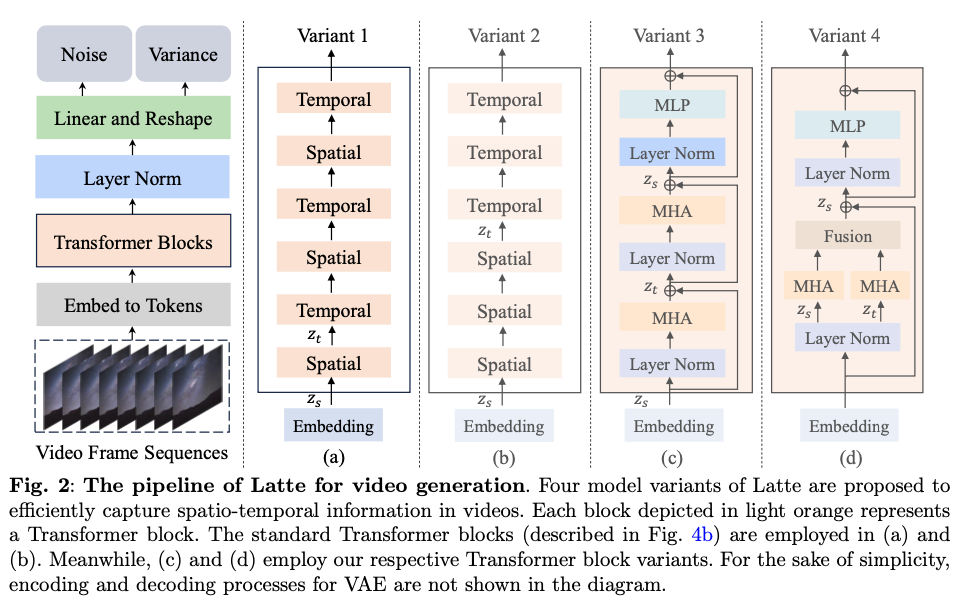
그런 다음 일련의 트랜스포머 블록을 적용하여 이 토큰을 인코딩합니다. 그림 2와 같이 공간 및 시간 정보와 입력 비디오에서 추출된 많은 수의 토큰 사이의 내재된 불일치를 고려하여, 입력 비디오의 공간 및 시간 차원을 분해하는 관점에서 효율적인 Transformer 기반 모델 변형 4가지를 설계
our main contributions
- 비디오 트랜스포머를 백본으로 채택한 새로운 잠복 확산 트랜스포머인 Latte를 소개합니다. 또한 동영상의 시공간 분포를 효율적으로 캡처하기 위한 네 가지 모델 변형을 소개합니다.
- 생성된 비디오의 품질을 향상시키기 위해 비디오 클립 패치 임베딩, 모델 변형, 타임스텝 클래스 정보 주입, 시간적 위치 임베딩, 학습 전략을 종합적으로 살펴보고 비디오 생성을 위한 트랜스포머 기반 확산 모델의 모범 사례를 도출합니다.
- 네 가지 표준 비디오 생성 벤치마크에 대한 실험 결과에 따르면 Latte는 최첨단 메소드에 비해 시간적 일관성이 있는 사실적인 비디오를 생성할 수 있는 것으로 나타났습니다. 또한 Latte는 텍스트에서 비디오로 생성하는 작업에 적용했을 때도 비슷한 결과를 보여줍니다.
Methodology
Preliminary of Latent Diffusion Models
Latent diffusion models (LDMs)
(Nichol and Dhariwal, 2021)에 따라 학습된 역과정 공분산 Σθ로 확산 모델을 훈련하려면 전체 DKL 항을 최적화해야 하며, 따라서 Lvlb로 표시되는 전체 L로 훈련
또한 Σθ는 εθ를 사용하여 구현 우리는 비디오 생성을 위해 1) 인코더 E를 사용하여 각 비디오 프레임을 잠재 공간으로 압축하고, 2) 확산 프로세스가 비디오의 잠재 공간에서 작동하여 잠재 공간 및 시간 정보를 모델링한다는 점에서 LDM을 확장
이 작업에서 εθ는 트랜스포머로 구현됩니다. 모든 모델은 Lsimple과 Lvlb를 모두 사용하여 훈련
The model variants of Latte
동영상에서 시공간 정보를 효율적으로 캡처하기 위해 라떼의 네 가지 모델 변형이 제안
Variant 1 : interleaved fusion
두 가지 유형의 트랜스포머 블록, 즉 공간 트랜스포머 블록과 시간 트랜스포머 블록으로 구성
전자는 동일한 시간 인덱스를 공유하는 토큰 사이에서만 공간 정보를 캡처하는 데 초점을 맞추고, 후자는 “interleaved fusion” 방식으로 시간 차원에 걸쳐 시간 정보를 캡처
-
“Interleaved fusion”은 시공간적(Spatio-temporal) 정보 통합을 위한 기법 중 하나
특정 시점의 공간적 정보를 먼저 처리한 후, 이를 시간적 정보와 교차적으로 융합하는 방식으로 동작
### Interleaved Fusion의 과정
“Interleaved fusion”은 다음과 같이 시공간적 정보를 융합합니다:
- 공간적 정보 캡처 (Spatial Information Capture): 공간 변환기 블록이 각 프레임 내의 공간적 상호작용을 모델링합니다. 이는 동일한 시간 인덱스를 가지는 토큰들 사이의 공간적 관계를 학습하는 단계입니다.
- 시간적 정보 캡처 (Temporal Information Capture): 시간 변환기 블록이 각 공간적 위치에서의 시간적 상호작용을 모델링합니다. 이는 시간 차원에서의 토큰들 사이의 관계를 학습하는 단계입니다.
잠재 공간 \(V_L ∈ \mathbb{R}^{F ×H ×W ×C}\) 에 비디오 클립 가정 wka
\(\hat{z} ∈ \mathbb{R}^{n_f×n_h×n_w×d}\) 로 표시되는 토큰 시퀀스로 변환
F, H, W, C는 각각 잠재 공간에서 비디오 프레임 수, 비디오 프레임의 높이, 너비, 채널
잠재 공간의 비디오 클립 내의 총 토큰 수는 각각 nf × nh × nw이며, d는 각 토큰의 크기
\[z = \hat{z} + p\]spatial Transformer block의 입력 →
\[z_s ∈ \mathbb{R}^{n_f ×t×d}\] : 공간 정보를 캡처
\(t = n_h × n_w\)는 각 temporal index의 토큰 수
공간 정보를 포함하는 zs → 시간 정보를 캡처하는 데 사용되는 temporal Transformer block의 입력
\(z_t ∈ \mathbb{R}^{t×n_f ×d}\)로 재형성
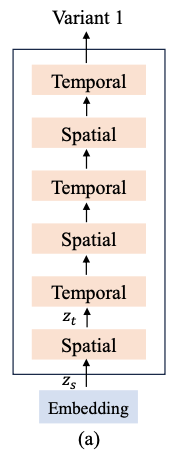
Variant 2 : late fusion
Variant 1과 동일한 수의 트랜스포머 블록으로 구성, 공간 트랜스포머 블록과 시간 트랜스포머 블록의 입력 모양은 각각 \(z_s ∈ \mathbb{R}^{n_f ×t×d}\) 및 \(z_t ∈ \mathbb{R}^{t×n_f ×d}\)
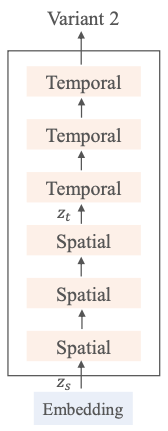
Variant 3
Variant 1과 Variant 2는 주로 트랜스포머 블록의 인수분해에 중점
Variant 3은 트랜스포머 블록의 다중 헤드 주의 분해에 중점을 둡니다.
그림 2 (c)에서 볼 수 있듯이, 이 Variant은 처음에는 공간적 차원에만 자기 주의를 집중한 후 시간적 차원을 추가
결과적으로 각 트랜스포머 블록은 공간 및 시간 정보를 모두 캡처
Variant 1 및 Variant 2와 마찬가지로 spatial multi-head self-attention and temporal multi-head self-attention에 대한 입력은 각각 \(z_s ∈ \mathbb{R}^{n_f ×t×d}\) 및 \(z_t ∈ \mathbb{R}^{t×n_f ×d}\)
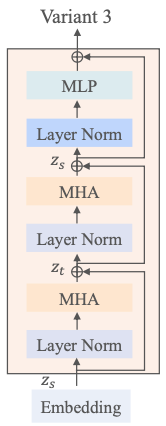
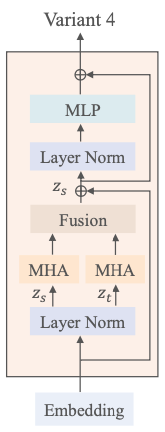
Variant 4
multi-head attention(MHA)를 두 가지 구성 요소로 분해
각 구성 요소는 그림 2 (d)와 같이 주의 헤드의 절반을 활용
공간적, 시간적 차원에서 토큰을 개별적으로 처리하기 위해 서로 다른 구성 요소를 사용
이러한 서로 다른 구성 요소에 대한 입력 형태는 각각 \(z_s ∈ \mathbb{R}^{n_f ×t×d}\) 및 \(z_t ∈ \mathbb{R}^{t×n_f ×d}\)
두 개의 서로 다른 attention을 계산한 후에는 \(z_t ∈ \mathbb{R}^{t× n_f ×d}\) 및 \(z_t' ∈ \mathbb{R}^{n_f× t×d}\) 로 재형성합니다. 그런 다음 트랜스포머 블록의 다음 모듈에 대한 입력으로 사용되는 zs에 zt′를 더함.
트랜스포머 백본 이후 중요한 절차는 비디오 토큰 시퀀스를 디코딩하여 예측된 노이즈와 예측된 공분산을 모두 도출하는 것
두 출력의 모양은 입력 \(V_L ∈ \mathbb{R}^{F ×H ×W ×C}\) 의 모양과 동일합니다.
표준 선형 디코더와 재형성 연산을 사용하여 이를 달성
여기서부터 다시 필요
The empirical analysis of Latte
Latent video clip patch embedding
비디오 클립을 임베드하기 위해 다음과 같이 두 가지 방법 사용
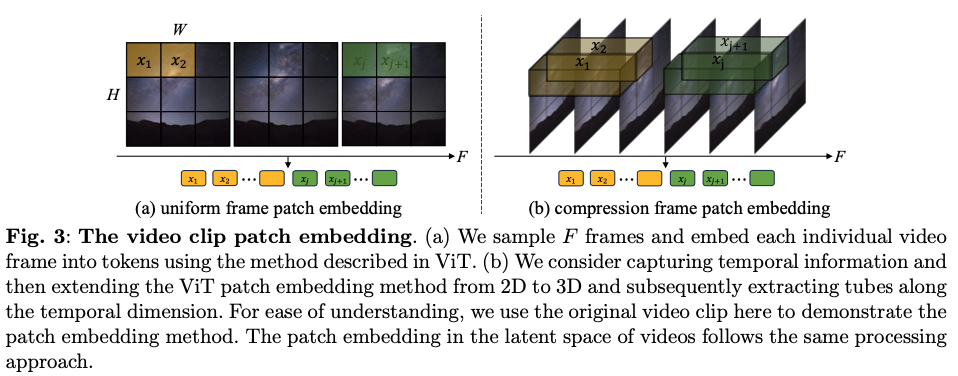
Uniform frame patch embedding
그림 3 (a)에서 볼 수 있듯이, 각 비디오 프레임에 ViT에 설명된 패치 임베딩 기법을 개별적으로 적용
모든 비디오 프레임에서 겹치지 않는 이미지 패치를 추출할 때 \(n_f, n_h, n_w\ \ 는 \ \ F, {H\over h}, {W\over w}\)와 동일
h와 w는 각각 이미지 패치의 높이와 무게
Compression frame patch embedding
두 번째 접근 방식은 그림 3 (b)와 같이 ViT 패치 임베딩을 시간적 차원으로 확장하여 잠재 비디오 클립의 시간적 정보를 모델링하는 것
시간적 차원을 따라 보폭 s로 튜브를 추출한 다음 이를 토큰에 매핑, nf는 겹치지 않는 균일한 프레임 패치 임베딩과 달리 F와 동일
이 방법은 패치 임베딩 단계에서 시공간 정보를 본질적으로 통합합니다. 압축 프레임 패치 임베딩 방법을 사용하는 경우, 표준 선형 디코더 및 리쉐이핑 작업에 이어 출력 잠복 동영상의 시간적 업샘플링을 위해 3D 전치 컨볼루션을 통합하는 추가 단계가 필요
Timestep-class information injection
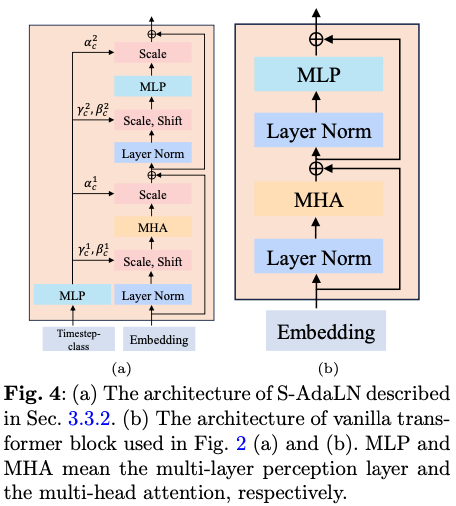
- 토큰으로 취급하는 방법: 타임스텝이나 클래스 정보를 별도의 토큰으로 간주하여 모델 입력에 직접 포함
- 적응형 레이어 정규화(AdaLN) 사용: 입력 정보 ccc를 기반으로 선형 회귀를 통해 \(\gamma_c\)와 \(\beta_c\)를 계산하여 AdaLN 공식을 적용
여기서 h는 트랜스포머 블록 내의 숨겨진 임베딩
또한 \(\alpha_c\)를 계산하여 잔여 연결 앞에 적용하는 확장 가능한 적응형 레이어 정규화(S-AdaLN)를 제안
Temporal positional embedding
시간적 위치 임베딩을 통해 모델이 시간 정보를 이해하도록 두 가지 방법
- 절대 위치 인코딩: 다양한 주파수의 사인 및 코사인 함수를 사용하여 각 프레임의 정확한 위치 정보를 제공
- 상대 위치 인코딩: RoPE(Rotary Position Embedding)를 활용하여 프레임 간의 상대적인 시간적 관계를 모델링
Enhancing video generation with learning strategies
비디오 생성 품질 향상을 위한 학습 전략
Learning with pre-trained models
사전 학습된 모델을 통한 학습. 이미지넷에서 사전 훈련된 DiT 모델에서 Latte를 초기화
사전 훈련된 DiT 모델에서 직접 초기화하면 매개변수가 누락되거나 호환되지 않는 문제가 발생
위치 임베딩을 시간적으로 확장하고 원래의 레이블 임베딩 레이어를 제거하여 문제를 해결
Learning with image-video joint training
이미지와 비디오 생성을 동시에 학습하여 모델의 성능을 향상
동일한 데이터 세트에서 무작위로 선택된 비디오 프레임을 비디오 끝에 추가하고, 시간 모듈에서는 프레임 토큰을 제외하여 연속적인 비디오 생성을 지원