
[논문분석] Latent Video Diffusion Models for High-Fidelity Long Video Generation
Latent space 에서 diffusion process
[Page, Paper, Code]
The Hong Kong University of Science and Technology , Tencent AI Lab
1. Abstract
AI-generated content has attracted lots of attention recently, but photo-realistic video synthesis is still challenging. Although many attempts using GANs and autoregressive models have been made in this area, the visual quality and length of generated videos are far from satisfactory. Diffusion models have shown remarkable results recently but require significant computational resources. To address this, we introduce lightweight video diffusion models by leveraging a low-dimensional 3D latent space, significantly outperforming previous pixel-space video diffusion models under a limited computational budget. In addition, we propose hierarchical diffusion in the latent space such that longer videos with more than one thousand frames can be produced. To further overcome the performance degradation issue for long video generation, we propose conditional latent perturbation and unconditional guidance that effectively mitigate the accumulated errors during the extension of video length. Extensive experiments on small domain datasets of different categories suggest that our framework generates more realistic and longer videos than previous strong baselines. We additionally provide an extension to large-scale text-to-video generation to demonstrate the superiority of our work. Our code and models will be made publicly available.
최근 AI로 생성된 콘텐츠가 많은 주목을 받고 있지만, 사실적인 영상 합성은 여전히 어려운 과제입니다. 이 분야에서 GAN과 자동 회귀 모델을 사용한 많은 시도가 있었지만, 생성된 비디오의 시각적 품질과 길이가 만족스럽지 못했습니다. 확산 모델은 최근 괄목할 만한 결과를 보여주었지만 상당한 컴퓨팅 리소스를 필요로 합니다. 이러한 문제를 해결하기 위해 저차원 3D 잠재 공간을 활용하여 제한된 계산 예산에서 기존의 픽셀 공간 비디오 확산 모델보다 훨씬 뛰어난 성능을 보이는 경량 비디오 확산 모델을 소개합니다. 또한 잠재 공간에서 계층적 확산을 제안하여 천 프레임 이상의 긴 동영상을 제작할 수 있습니다. 또한 긴 영상 생성에 따른 성능 저하 문제를 극복하기 위해 영상 길이가 늘어나는 동안 누적된 오차를 효과적으로 완화하는 조건부 잠복 섭동과 무조건 안내를 제안합니다. 다양한 카테고리의 소규모 도메인 데이터 세트에 대한 광범위한 실험 결과, 프레임워크가 기존의 강력한 기준선보다 더 사실적이고 긴 동영상을 생성하는 것으로 나타났습니다. 또한, 대규모 텍스트-비디오 생성에 대한 확장 기능을 제공하여 작업의 우수성을 입증합니다. 코드와 모델은 공개적으로 사용할 수 있습니다.
2. Introduction
고차원적인 비디오 샘플과 실제 비디오 분포의 통계적 복잡성으로 인해 비디오 합성은 매우 어렵고 계산 비용이 많이 든다.
GAN은 모드 붕괴와 훈련 불안정성 문제로 인해 복잡하고 다양한 비디오 배포를 처리하기 위해 GAN 기반 접근 방식을 확장하기 어렵다.
the generation fidelity and resolution (128 128) 또한 아쉽다.
긴 비디오에 대한 성능 저하를 완화하기 위해 조건부 잠재 섭동과 무조건 지침 사용 (conditional latent perturbation and unconditional guidance)
- We introduce LVDM, an efficient diffusion-based baseline approach for video generation by firstly com pressing videos into tight latents.
- We propose a hierarchical framework that operates in the video latent space, enabling our models to generate longer videos beyond the training length further.
- We propose conditional latent perturbation and unconditional guidance for mitigating the performance degradation issue during long video generation.
- Our model achieves state-of-the-art results on three benchmarks in both short and long video generation settings. We also provide appealing results for open domain text-to-video generation, demonstrating the effectiveness and generalization of our models.
3. Method
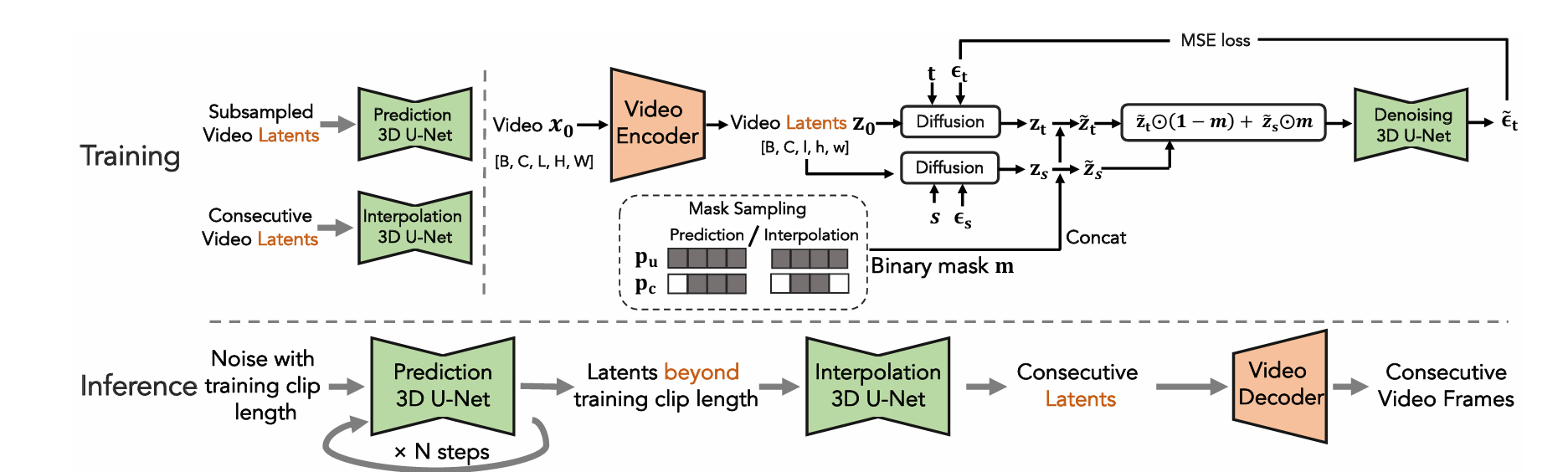
먼저 비디오 자동 인코더를 통해 비디오 샘플을 저차원 잠재 공간으로 압축합니다. 그런 다음 잠재 공간에서 하나의 네트워크에서 무조건 생성 및 조건부 비디오 생성을 모두 수행할 수 있는 통합 비디오 확산 모델을 설계합니다. 이를 통해 생성된 비디오를 임의의 길이로 자동 회귀적으로 자체 확장할 수 있습니다. 그러나 자동 회귀 모델은 시간이 지남에 따라 성능이 저하되는 문제가 있습니다. 생성된 긴 동영상의 일관성을 더욱 향상시키고 품질 저하 문제를 완화하기 위해 계층적 잠복 동영상 확산 모델을 제안하여 먼저 동영상 특허를 드물게 생성한 다음 중간 잠복에서 보간하는 방법을 제안합니다. 또한 긴 비디오 생성 시 화질 저하 문제를 해결하기 위한 조건부 터뷸레이션별 잠복과 무조건적인 가이드를 제안합니다.
3.1. Video Autoencoder
lightweight 3D autoencoder를 통해 압축 진행
\[x_0 \sim p_{data}(x_0)\ ,\ \ \ \ where\ \ x_0 = \mathbb{R}^{H \times W \times L \times 3}\]Encoder
\[\mathrm{z}_0 = \mathcal{E}(\mathrm{x}_0) \ , \ \ where \ \ \mathrm{z}_0 \in \mathbb{R}^{h \times w \times l \times c}\]\(h = H/f_s, w = W/f_s,l = L/f_t\) , fs and ft are spatial and temporal downsampling factors.
Decoder
\[\mathrm{x}_0,\ \ \mathrm{i.e.}\ \ \mathrm{x}_0 = \mathcal{D}(\mathrm{z}_0)\]Temporally shift-equivariant를 보장하기 위해 모든 3차원 컨볼루션에서 replicate padding 사용.
재구성 손실 + 적대적 손실로 훈련됨 : reconstruction loss \(\mathcal{L}_{rec}\) and an adversarial loss \(\mathcal{L}_{adv}\).
reconstruction loss은 픽셀 수준의 평균제곱오차(MSE) 손실과 지각 수준의 LPIPS[47] 손실로 구분
adversarial loss은 픽셀 수준의 reconstruction loss로 인해 일반적으로 발생하는 재구성 시 흐림을 제거, realism를 더욱 개선하기 위해 사용
\[\mathcal{L}_{AE} = \min_{\mathcal{E}, \mathcal{D}} \max_{\psi} \left( \mathcal{L}_{rec} \left( x_0, \mathcal{D}(\mathcal{E}(x_0)) \right) + \mathcal{L}_{adv} \left( \psi \left( \mathcal{D}(\mathcal{E}(x_0)) \right) \right) \right)\]where \(\psi\) is the discriminator used in adversarial training
3.2.Base LVDM for Short Video Generation
Revisiting Diffusion Models.
video latent space에서 동작
\[\begin{align} q(\mathbf{z}_{1:T} | \mathbf{z}_0) &:= \prod_{t=1}^{T} q(\mathbf{z}_t | \mathbf{z}_{t-1}), \\ q(\mathbf{z}_t | \mathbf{z}_{t-1}) &:= \mathcal{N}(\mathbf{z}_t; \sqrt{1 - \beta_t} \mathbf{z}_{t-1}, \beta_t \mathbf{I}). \end{align}\]이외에는 모두 기존 diffusion model과 동일
\[\begin{align} p_\theta(\mathbf{z}_{0:T}) &:= p(\mathbf{z}_T) \prod_{t=1}^{T} p_\theta(\mathbf{z}_{t-1}|\mathbf{z}_t), \\ p_\theta(\mathbf{z}_{t-1}|\mathbf{z}_t) &:= \mathcal{N}(\mathbf{z}_{t-1}; \mu_\theta(\mathbf{z}_t, t), \Sigma_\theta(\mathbf{z}_t, t)), \\ \mu_\theta(\mathbf{z}_t, t) &= \frac{1}{\sqrt{\alpha_t}} \left( \mathbf{z}_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \epsilon_\theta(\mathbf{z}_t, t) \right), \\ \mathcal{L}_{\text{simple}}(\theta) &:= \left\lVert \epsilon_\theta(\mathbf{z}_t, t) - \epsilon \right\rVert_2^2, \end{align}\]$\epsilon$ is drawn from a diagonal Gaussian distribution
Video Generation Backbone
Video Diffusion Models를 따라 1x3x3 컨볼루션과 temporal attention 도입.
Adaptive group normalization을 사용하여 채널별 scale 및 bias를 제어하기 위해 정규화 모듈에 timestep 임베딩 주입.
공간-시간 결합 attention은 분리 attention에 비해 모델 복잡성을 증가시키고 때때로 무작위 위치에 아티팩트(점 같은 잡음)를 유발하며, 성능상의 큰 이점은 없다는 것이 관찰 됨
3.3.Hierarchical LVDM for Long Video Generation
앞서 언급한 프레임워크는 훈련 중 입력 프레임 수에 따라 길이가 결정되는 짧은 동영상만 생성 가능
긴 비디오 생성을 용이하게 하기 위해 자동적으로 점진적인 방식으로 이전 코드에 조건부 텐트 코드를 생성할 수 있는 조건부 잠재 확산 모델을 제안
또한 자동 점진적 생성의 오류 누적 문제를 완화하기 위한 몇 가지 기술을 제시
Autoregressive Latent Prediction.
각 프레임의 채널 차원에 마스크 채널을 추가하고 마스크에 따라 zti를 z0i로 교체함으로써, 나머지 프레임을 조건으로 새로운 프레임을 생성할 수 있는 조건부 모델과 무조건 모델을 공동으로 훈련할 수 있다. (모두 0이면 무조건 모델)
\[\tilde{\mathbf{z}}_t = \left\{ \tilde{\mathbf{z}}_t^i = \left[ \mathbf{z}_t^i, \mathbf{m}^i \right] \right\}_{i=1}^{l} = \left\{ \tilde{\mathbf{z}}_t^i \right\}_{i=1}^{l}, \tilde{\mathbf{z}}_t^i \in \mathbb{R}^{h \times w \times (c+1)}\] \[\tilde{\mathbf{z}}_0 = \left\{ \tilde{\mathbf{z}}_0^i = \left[ \mathbf{z}_0^i, \mathbf{m}^i \right] \right\}_{i=1}^{l} = \left\{ \tilde{\mathbf{z}}_0^i \right\}_{i=1}^{l}, \tilde{\mathbf{z}}_0^i \in \mathbb{R}^{h \times w \times (c+1)}\] \[\tilde{\mathbf{z}}_t \leftarrow \tilde{\mathbf{z}}_t \odot (1 - \mathbf{m}) + \tilde{\mathbf{z}}_0 \odot \mathbf{m}\]Hierarchical Latent Generation
자기회귀 방식으로 순서대로 긴 비디오를 생성하면 시간이 지남에 따라 오류가 누적되어 품질이 저하될 수 있다. 따라서 계층 생성 전략 사용.
먼저 자기회귀 생성 모델이 잠재 희소 프레임 세트를 생성한 다음, 프레임 간 마스크가 모두 0인 희소 프레임에서 훈련된 또 다른 자기회귀 생성 모델을 사용하여 누락된 프레임을 채운다.
Conditional Latent Perturbation
조건부 오류를 완화하기 위해 Cascaded Diffusion Models의 truncated conditioning에서 영감을 받은 조건부 잠재 섭동을 사용한다.
z0에 확산 프로세스를 수행하여 소량의 노이즈가 추가된 zs를 조건으로 사용하고 샘플링 시에는 자기회귀 예측 동안 노이즈를 지속적으로 추가한다. (노이즈가 있는 조건에서 훈련했으므로)
Unconditional Guidance
자기회귀 예측의 오류 누적으로 조건부 점수가 모델 학습 분포를 벗어날 수 있다.
공동 훈련을 통해 하나의 모델로 무조건 및 조건부 점수를 추정할 수 있으므로 classifier-free guidance를 통해 샘플링 프로세스를 안내하여 품질 저하를 완화한다.
\[\tilde{\epsilon}_{\theta} = (1 + w) \epsilon_c - w \epsilon_u,\]4. Experiments
4.1. Experimental Setup
Datasets : UCF-101 [34], SkyTime-lapse [43], and Taichi [28].
4.3. Short Video Generation

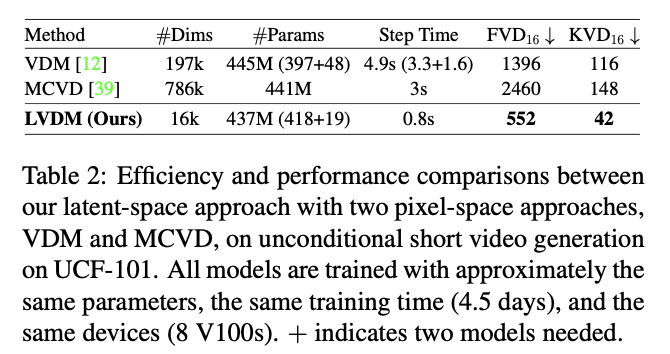
4.4. Long Video Generation

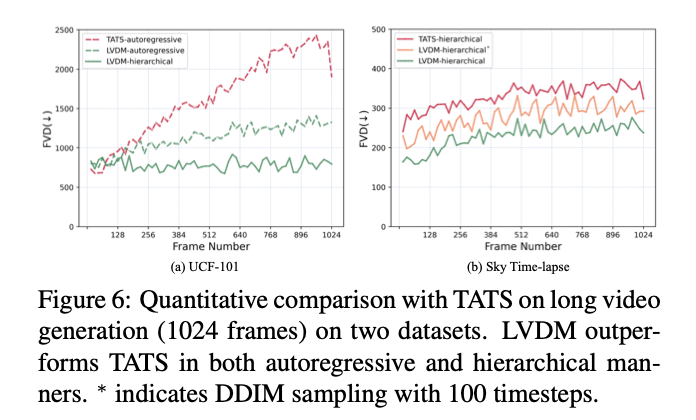
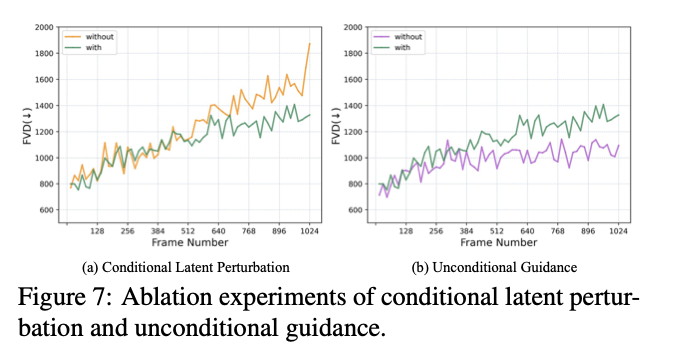
5. Extension for Text-to-Video Generation
webvid dataset 사용
