[논문분석] A Survey of Large Language Models
Pre-training, Adaptation, Utilization, Capability Evaluation 에 대한 내용 탐구 [Paper]
이번 내용
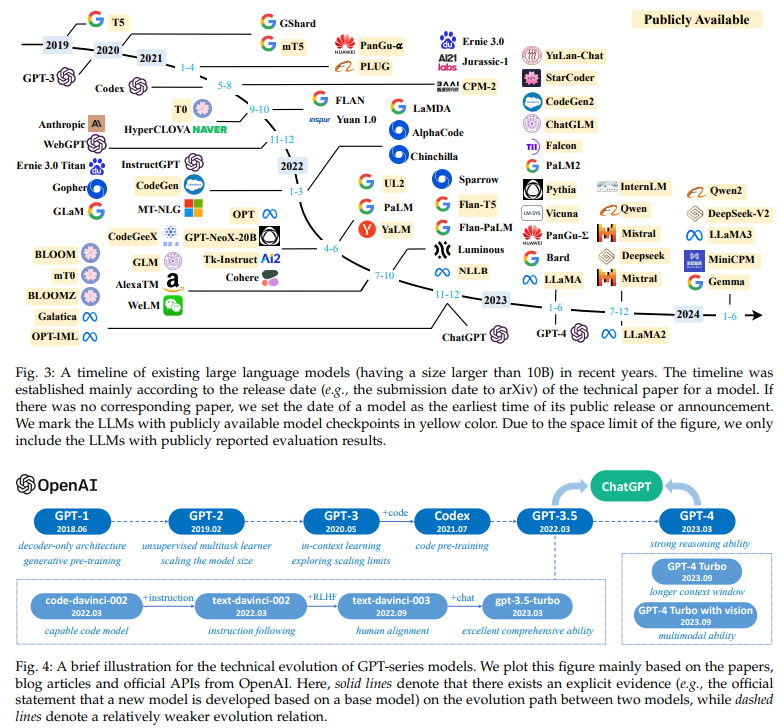
- Section 3: LLMs의 배경과 GPT 시리즈 모델의 발전 과정
다음 내용
- Section 4: LLMs 개발을 위한 이용 가능한 리소스 정리
- Sections 5–8: 사전 훈련, 적응, 활용, 능력 평가에 대한 최근 연구 동향 리뷰
- Section 9: 프롬프트 설계(Prompt Design)를 위한 실용적 가이드
- Section 10: 대표적인 도메인에서 LLMs의 활용 사례
- Section 11: 주요 발견 사항 요약 및 미래 연구 방향 제시
LLM의 등장 배경, 주요 연구 결과, 주요 기술을 소개함으로써 최근의 발전 상황 확인
pre-training, adaptation tuning, utilization, and capacity evaluation : LLM의 네 가지 주요 측면에 초점
LLM을 개발하는 데 사용할 수 있는 리소스를 요약, 향후 방향에 대한 남은 과제에 대해서도 논의
“The limits of my language mean the limits of my world.” —Ludwig Wittgenstein
LLM은 미래 혹은 비어있는 토큰을 예측하도록 학습 됨
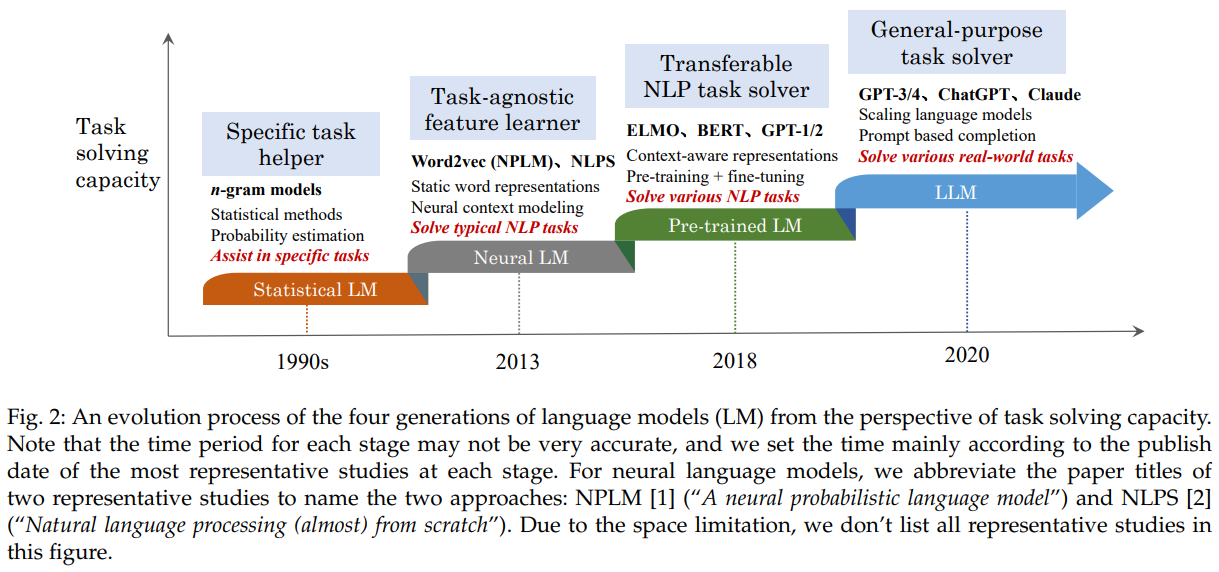
2.1 Statistical language models (SLM)
1990s년대 개발된 통계적 학습 기법 기반 + Markov assumption에 기반한 단어 예측 모델 ⇒ n-gram language models 이라 부름
하지만 차원이 높아지면 step 수 증가 → curse of dimensionality 발생
smoothing strategies 방법 등장 (backoff estimation, Good–Turing estimation) → data sparsity problem 완화
특정 task에 도움을 주는 역할
2.2 Neural language models (NLM)
multi-layer perceptron (MLP) 및 recurrent neural networks (RNNs)과 같은 신경망에 의해 단어 시퀀스의 확률을 characterize
distributed representation of words + aggregated context features (i.e., the distributed word vectors) → the word prediction function
단어 표현 학습 방법으로 word2vec 제안됨
특정 task에 종속되지 않는(Task-agnostic) 일반적 특징 벡터를 학습
2.3 Pre-trained language models (PLM)
ELMo : pre-training a bidirectional LSTM (biLSTM) network 사용 → fine-tuning the biLSTM network = specific downstream tasks
self-attention mechanisms을 도입한 highly parallelizable Transformer architecture → BERT (pre-training bidirectional language models) 이는 large-scale unlabeled corpora에서 동작, 범용적
“pre-training and fine-tuning” learning paradigm이 됨 (GPT-2, BERT 등등이 개발됨)
Context를 이해 → 질의응답, 감성 분류 task
2.4 Large language models (LLM)
PLM을 확장 (e.g., scaling model size or data size) → downstream tasks에서 모델 성능 향상
대화 성능 향상 (few-shot tasks)
General-purpose Task Solvers → 다양한 작업 가능
task solving capacity
2.5 AGI(Artificial General Intelligence)
ChatGPT와 GPT-4 → 인간 수준 혹은 그 이상의 지능을 구현
- 자연어 처리(NLP): NLP 연구에서 프롬프트 기반 활용 및 LLMs 중심의 연구가 주류
- 정보 검색(IR): 전통적인 검색 엔진 방식 → 대화형 AI(예: ChatGPT)
- 컴퓨터 비전(CV): 시각 정보를 처리하면서 텍스트 기반 대화 기능까지 가능하게 하는, ChatGPT 스타일의 멀티모달 모델 개발
Emergent Abilities
대규모 언어 모델(LLMs)이 일정 규모(파라미터 수, 데이터 크기 등)에 도달했을 때 예상치 못하게 나타나는 새로운 능력이나 행동 → 아래서 자세하게 다룰 예
작은 PLMs(Pre-trained Language Models)에서는 나타나지 않고, LLMs에서만 발생
training 과정의 불투명성 및 높은 비용
Alignment with Human Values
Toxic, Fictitious, Harmful 콘텐츠 생성에 대한 문제
3.1 Background for LLMs
hundreds of billions (or more) of parameters
3.1.1 Formulation of Scaling Laws for LLMs
언어 모델의 성능이 모델 크기, 데이터 크기, 계산량과 어떻게 상호작용 하는지를 수학적으로 설명하는 경험적 규칙
LLMs(대규모 언어 모델)가 더 많은 리소스를 사용할수록 성능이 어떻게 향상 되는지를 보여줌
LLM은 Transformer architecture를 기반으로 함 → Multi-Head Attention을 통해 Context를 파악
초기 소형 언어 모델과 LLMs는 유사한 Pre-training Objective를 사용하지만, LLMs는 모델 크기(Model Size, N), 데이터 크기(Data Size, D), 계산량(Compute, C)이 기하급수적으로 확장
따라서 모델 성능과 자원 할당 최적화를 위한 Scaling Laws가 연구됨
KM Scaling Law (Kaplan et al., 2020, OpenAI)
- LLMs의 성능과 3가지 주요 요소(모델 크기, 데이터 크기, 계산량) 간의 멱법칙(Power-Law Relationship)을 발견
-
주어진 계산 예산(compute budget, C) 하에서 언어 모델의 손실(Language Modeling Loss, L)이 어떻게 변하는지를 수식으로 표현
\[L(N) = \left(\frac{N_c}{N}\right)^{\alpha_N}, \quad \alpha_N \approx 0.076, \quad N_c \approx 8.8 \times 10^{13}\] \[L(D) = \left(\frac{D_c}{D}\right)^{\alpha_D}, \quad \alpha_D \approx 0.095, \quad D_c \approx 5.4 \times 10^{13}\] \[L(C) = \left(\frac{C_c}{C}\right)^{\alpha_C}, \quad \alpha_C \approx 0.050, \quad C_c \approx 3.1 \times 10^{8}\]- L(⋅): 언어 모델의 손실 (Cross-Entropy Loss in nats)
- N: 모델 파라미터 수 (Model Size)
- D: 학습 데이터 토큰 수 (Dataset Size)
- C: 학습 계산량 (Compute)
- \(\alpha_N, \alpha_D, \alpha_C\) : 각 요소의 손실 감소율 (Loss Decay Rate)
- \(N_c, D_c, C_c\) : 최적화 임계값 (Optimal Threshold Values)
- 모델 성능은 모델 크기(N), 데이터 크기(D), 계산량(C)에 따라 멱법칙적으로 변화
- 손실은 모델의 크기, 데이터 양, 계산량을 늘릴수록 감소하지만, 그 비율은 점차 줄어듬 (수익 체감의 법칙, Diminishing Returns).
-
이 법칙은 다양한 범위의 모델 크기(768 ~ 1.5B 파라미터), 데이터(22M ~ 23B 토큰), 계산량을 통해 실험적으로 검증
- 대규모 실험과 데이터 분석을 통해 경험적으로 검증된 관계 → 수식적으로 증명 안됨
📌 어떻게 증명하는가?
✅ 주요 변수
- 모델 크기 (Model Size, N)
- 파라미터 수: 768 ~ 1.5B (15억 개의 파라미터)
- 데이터 크기 (Dataset Size, D)
- 학습에 사용된 토큰 수: 22M (2200만 개) ~ 23B (230억 개)
- 계산량 (Compute, C)
- 총 학습 계산량: 다양한 학습 스텝과 GPU 시간 조합
✅ 평가 지표
- Cross-Entropy Loss (L): 언어 모델의 성능을 평가하는 주요 손실 함수
- Scaling Behavior: 각 변수(N, D, C)의 변화에 따른 Loss 감소율을 분석
✅ 방법
각 실험에서 한 가지 변수만 변화 → 로그-로그 스케일 플롯 (Log-Log Scale Plotting) → 직선으로 나타나면 Power-Law Relationship 성립
📌 Power-Law Relationship이란?
\[y=kx^α\]다음과 같은 관계를 만족하는 경우 → 어떤 현상이 거듭 제곱의 패턴을 따르는 것
- y: 종속 변수 (Dependent Variable)
- x: 독립 변수 (Independent Variable)
- k: 비례 상수 (Proportionality Constant)
- α: 멱지수(Exponent) – 관계의 기울기 또는 비율
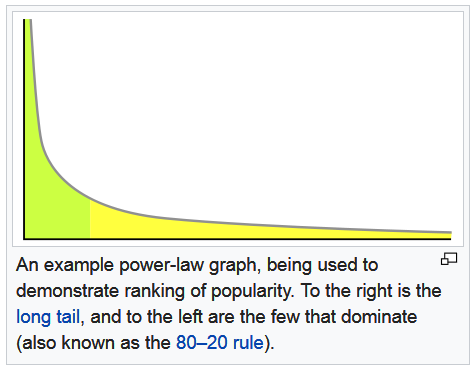
특징
- 비선형적 관계 (Non-linear Relationship)
- 독립 변수 x의 증가에 따라 종속 변수 y가 선형적(일정한 비율)으로 증가하지 않고, 멱지수(α)에 따라 급격하게 변화
- 자기유사성 (Self-Similarity)
- 특정 범위에서 관찰된 패턴이 다른 범위에서도 반복. (프랙탈 구조와 유사함)
- 수익 체감의 법칙 (Diminishing Returns)
- 멱지수 α<1인 경우, x가 증가할수록 y의 증가율이 점차 감소
- 긴 꼬리 분포 (Long Tail Distribution)
- 일부 항목이 매우 큰 값을 가지는 반면, 대부분의 항목은 작은 값 (예: 소수의 유명 유튜버가 엄청난 조회수를 기록하는 현상)
하지만 위 방법 데이터 부족 문제를 간과
Chinchilla Scaling Law (Hoffmann et al., 2022, DeepMind)
KM Scaling Law의 한계를 극복
모델 크기(N)와 데이터 크기(D) 간의 균형을 강조 → 최적의 계산 cost 배분 방식을 제시
\[L(N, D) = E + \frac{A}{N^\alpha} + \frac{B}{D^\beta}\]- L(N, D): 모델 손실
- E: 데이터의 근본적인 손실(irreducible loss, 엔트로피)
- A, B: 스케일링 계수(scaling coefficients)
- α, β: 각각 모델 크기와 데이터 크기에 대한 손실 감소율
- α = 0.34
- β = 0.28
- G: Scaling Coefficient, (A, B, α, β로부터 계산됨)
계산량을 모델 크기(N)와 데이터 크기(D)에 균등하게 분배해야 한다고 주장
KM Scaling Law와 달리, 데이터 부족 현상을 해결하고 모델이 충분한 데이터를 학습할 수 있도록 강조
이 법칙을 따르면, 같은 계산 예산 하에서 더 나은 성능을 달성
| 비교 항목 | KM Scaling Law | Chinchilla Scaling Law |
|---|---|---|
| 중점 요소 | 모델 크기(Model Size)에 집중 | 모델 크기와 데이터 크기의 균형 |
| 계산 예산 분배 | 모델 크기에 더 많이 할당 | 모델 크기와 데이터 크기에 균등 분배 |
| 데이터 중요성 | 상대적으로 과소평가 | 균등한 중요성 부여 |
| 실험 범위 | 중소형 모델 중심 | 더 큰 범위의 모델 실험 |
3.1.2 Discussion on Scaling Laws
◼️Predictable Scaling
작은 모델의 성능 데이터를 바탕으로 더 큰 모델의 성능을 예측하는 것
✅ 이점
- Knowledge Transfer from Small Models : 대규모 모델은 시간과 리소스가 많이 소모되기 때문에 다양한 학습 전략(예: 데이터 혼합 비율 조정, 학습 스케줄 최적화)을 실험하기 어려움 → 작은 프록시 모델(proxy model)을 통해 최적의 데이터 혼합 비율, 학습 스케줄 등을 먼저 탐색한 후, 이를 대규모 모델에 적용
- Training Monitoring : 대규모 모델 훈련은 시간이 오래 걸리며, 훈련 과정에서 손실 스파이크(loss spike)나 비정상적 학습 상태가 발생 가능 → Scaling Laws를 통해 훈련 초기 단계에서 이상 징후를 감지하고 문제를 조기에 수정가
✅ Diminishing Returns
- Scaling Laws는 일반적으로 성능 향상이 점차 둔화되는 Diminishing Returns 현상을 예측
- 언어 모델 손실이 감소하는 한, 표현 품질(representation quality)과 의미적 콘텐츠(semantic content)는 계속해서 개선될 수 있음 → 손실이 수렴되더라도 다운스트림 작업(Downstream Task)에서의 성능은 계속 향상될 가능성을 의미
✅ Data Constraints 해결
- 데이터 반복 사용 (Data Repetition)
- 데이터 증강 (Data Augmentation)
◼️Task-Level Predictability
Language Modeling Loss 중심 연구에서 Downstream Tasks에서의 성능 개선 연구로 변화
- 손실 감소는 일반적으로 다운스트림 작업 성능 향상과 연관
- 그러나 일부 작업에서는 손실 감소가 성능 저하를 초래 (Inverse Scaling).
- 작업 수준의 Scaling Laws는 작업 메트릭, 난이도, 데이터 품질 등 다양한 요소에 따라 달라짐
- In-Context Learning과 같은 출현적 능력(Emergent Abilities)은 Scaling Laws로 예측하기 어려움
3.1.3 Emergent Abilities of LLMs
작은 모델에서는 존재하지 않지만, 대규모 모델에서는 갑작스럽게 등장하는 능력
모델 규모가 특정 임계값(threshold)을 초과했을 때 성능이 무작위(random) 수준을 훨씬 초과
물리학의 상전이(Phase Transition) 현상과 유사한 패턴
🧠 Emergent Abilities (example)
✅ In-Context Learning (ICL)
자연어로 된 지시(instruction)나 몇 가지 작업 예시(demonstrations)를 제공 받았을 때, 추가 학습이나 경사 하강법(Gradient Update) 없이 주어진 입력 텍스트의 단어 시퀀스를 완성하여 기대하는 출력을 생성하는 능력 → 모델이 사전 훈련된 상태로 제공된 예시나 지시를 이해하고, 이를 기반으로 새로운 작업을 수행
GPT-3 이후로 ICL (맥락 내 학습 능력 좋아짐)
- ICL은 단순한 패턴 매칭이 아니라, 모델이 맥락(Context)을 이해하고 적응할 수 있는 능력
- 모델 규모가 증가함에 따라 더 강력하고 일반화된 ICL 능력이 나타
✅ Instruction Following
다양한 작업을 자연어 지시(instruction) 형태로 설명한 멀티태스크 데이터셋으로 미세 조정(Fine-tuning)되었을 때, 명확한 예시 없이 새로운 작업 지시를 따르는 능력 → LLM은 자연어로 된 설명을 통해 새로운 작업을 수행
Instruction Tuning을 통해 강화
- 모델 크기가 68B에 도달했을 때, Instruction Following 능력이 크게 향상
- 8B 이하 모델에서는 이런 현상이 나타나지 않음 → 모델의 크기가 임계값을 초과해야 이 능력이 명확하게 나타남
📌 Instruction Tuning : 다양한 작업(Task)을 자연어 지시(Instruction) 형태로 설명한 데이터셋을 사용하여 LLM을 미세 조정(Fine-tuning)하는 방법
모델이 지시(instruction)를 이해하고 따르는 능력을 학습 → 특정 태스크에 과도하게 최적화되지 않고 범용적 성능을 유지
- 예시:
- 사용자: “다음 문장을 요약해줘.”
- 모델: “물론입니다. 여기 요약입니다: …”
- 사용자: “다음 코드를 디버깅해줘.”
- 모델: “오류는 여기서 발생합니다: …”
| Instruction | Input Text | Output Text |
|---|---|---|
| “Translate to French” | “Hello, how are you?” | “Bonjour, comment ça va?” |
| “Summarize the text” | “The quick brown fox…” | “A fox jumped over a dog.” |
✅ Step-by-Step Reasoning
여러 단계의 논리적 추론이 필요한 복잡한 작업(예: 수학 문제)을 해결하기 위해 중간 추론 단계를 통해 최종 답을 도출하는 능력
Chain-of-Thought (CoT) Prompting 전략을 통해 가능해 짐
- 모델이 명시적인 중간 추론 단계를 통해 복잡한 문제를 해결
- 코드 학습(Code Training)이 능력의 출현에 중요한 역할
- PaLM 및 LaMDA → 60B 이상의 모델에서 CoT가 명확한 성능 향상
- CoT Prompting을 통해 LLM은 복잡한 다단계 논리 추론 문제를 해결
능력별 임계값:
- ICL: 13B~175B
- Instruction Following: 68B+
- Step-by-Step Reasoning: 60B+
3.1.4 How Emergent Abilities Relate to Scaling Laws
두 관점의 성능 패턴 비교
| 항목 | Scaling Laws | Emergent Abilities |
|---|---|---|
| 개념 | 모델 크기, 데이터 양, 계산량이 증가함에 따라 성능(언어 모델 손실)이 어떻게 개선되는지를 설명하는 경험적 법칙 | 작은 모델에서는 나타나지 않지만, 모델이 특정 규모에 도달했을 때 갑작스럽게 등장하는 능력 |
| 성능 패턴 | 점진적 개선 (Continuous Improvement) | 급격한 성능 향상 (Sharp Leap) |
| 예측 가능성 | 높음 (Predictable) | 낮음 (Unpredictable) |
| 평가 지표 | 언어 모델링 손실 (Cross-Entropy Loss) | 다운스트림 작업 성능(Task-Specific Performance) |
| 한계 | 수익 체감 (Diminishing Returns) | 임계값(Threshold)이 불명확 |
✅ Misaligned Observations (두 관점 차이)
스케일링 법칙은 점진적 개선(Continuous Improvement)을 예측
출현적 능력은 불연속적 도약(Discontinuous Leap)을 보여줌
Evaluation Metrics Difference
스케일링 법칙: 주로 Cross-Entropy Loss를 사용하여 성능을 평가
출현적 능력: 구체적인 작업(Task-Specific Performance)의 성공 여부에 중점 → 성능이 연속적이기보다 불연속적으로 인식
따라서 New Evaluation Setting이 필요함 → 일부 연구에서는 작업 성능(Task Metrics)의 해상도(Resolution)를 높여 더 예측 가능한 결과를 얻으려고 함
Fundamental Understanding 이해도 동시에 필요 → ‘Grokking’과 같은 현상을 통해 LLM의 작동 원리와 출현적 능력의 메커니즘을 이해하려는 연구가 진행 중
✅ Analogy with Human Learning
두 법칙의 관계는 인간과 유사
- Continuous Improvement : 어린이는 매일매일 성장하지만, 그 변화는 눈에 띄지 않음
- Qualitative Leap : 어느 순간, 단어를 말하던 어린이가 갑자기 문장 단위로 말하는 능력을 획득
- Step-Wise Changes : 능력의 성장은 항상 매끄럽거나 선형적이지 않음
✅ Integrated Understanding
관점 통합
- Scaling Laws → 점진적 성장 (Continuous Improvement)
- 주어진 계산 예산, 데이터 양, 모델 크기에 따라 손실이 서서히 줄어드는 패턴을 예측
- Emergent Abilities → 질적 도약 (Qualitative Leap)
- 모델이 특정 임계값을 초과했을 때 예상치 못한 새로운 능력이 나타남
- Scaling Laws은 예측 가능한 성능 향상을 제공 Emergent Abilities은 비약적인 성능 도약을 설명
3.1.5 Key Techniques for Large Language Models
✅ Scaling
모델 크기(Model Size, N), 데이터 양(Data Size, D), 계산량(Compute, C) 을 늘리면 일반적으로 모델 성능 향상
Scaling Laws의 활용 → Compute Budget은 한정적이기 때문에, 최적의 리소스 배분이 필요
모델 성능은 단순히 데이터 양이 아닌 데이터 품질에 크게 의존
✅ Training
Distributed Training Algorithms 필요 → 모델 크기가 너무 커서
Parallel Strategies
- Data Parallelism (데이터 병렬화)
- Model Parallelism (모델 병렬화)
- Pipeline Parallelism (파이프라인 병렬화)
Optimization Frameworks
- DeepSpeed: 효율적인 분산 훈련 지원.
- Megatron-LM: 초대형 모델 훈련을 위한 최적화 프레임워크.
Stability & Optimization Tricks
- Mixed Precision Training: 계산 속도 향상 및 메모리 사용 최적화.
- Training Restart: 손실 스파이크(loss spike)를 해결하기 위한 재시작 기법.
Small Model Prediction
- 소규모 모델을 통해 대규모 모델의 성능을 예측
✅ Ability Eliciting
LLMs는 대규모 데이터로 사전 훈련되지만, 모든 능력이 바로 드러나는 것은 아님 → LLMs가 숨겨진 능력을 효과적으로 발휘하도록 유도하는 과정
In-Context Learning
- 예시와 함께 프롬프트를 제공하여 모델이 맥락을 이해하고 문제를 해결
Chain-of-Thought (CoT) Prompting
- intermediate reasoning steps를 포함하여 복잡한 문제를 해결하도록 유도
Instruction Tuning
- 다양한 작업을 자연어 지시(Instructions) 형태로 설명한 데이터셋으로 모델을 미세 조정 → 새로운 작업에도 높은 범용성
✅ Alignment Tuning
Toxic, Biased, Fictitious 콘텐츠 생성 위험 → Helpful, Honest, Harmless
InstructGPT (OpenAI)
- Reinforcement Learning with Human Feedback, RLHF 을 사용하여 모델을 인간의 기대에 부합하도록 조정
- ChatGPT는 InstructGPT 기반으로 개발됨
✅ Tools Manipulation
LLMs는 텍스트 기반 학습을 통해 훈련 → 수치 계산, 최신 정보 제공 등 텍스트로만 해결하기 어려운 문제
Tool Integration 사용
- 계산기 (Calculator): 정확한 수치 계산 지원
- 검색 엔진 (Search Engine): 실시간 최신 정보 검색
- 외부 플러그인 (External Plugins): ChatGPT는 외부 앱이나 플러그인을 활용하여 기능을 확장
✅ Other Factors
하드웨어 업그레이드: GPU, TPU 등 하드웨어의 발전
효율적 알고리즘: 새로운 알고리즘 개발이 LLMs의 성능과 효율성을 개선
3.2 Technical Evolution of GPT-series Models
Decoder-Only Transformer
- Next Word Prediction을 통해 언어 모델을 학습 → 모델은 주어진 문맥(context)에서 다음에 올 단어를 정확하게 예측하도록 훈련
Scaling Up
- 모델의 크기, 데이터의 양, 계산량을 지속적으로 확장하여 성능을 극대화
- GPT-3는 175B, PaLM은 540B 파라미터를 사용
General-Purpose Task Solver
3.2.1 Early Explorations
초기 실험은 순환 신경망 (Recurrent Neural Networks, RNNs)을 사용하여 수행
그러나 RNN은 장기 의존성 문제 (Long-Term Dependency Problem)로 인해 성능에 한계 존재
2017년 Transformer 아키텍처 등장 이후, OpenAI는 Transformer를 기반으로 언어 모델을 개발하기 시작
✅ GPT-1 (2018)
Transformer (Decoder-Only Transformer)
training technique
- Unsupervised Pre-training
- Supervised Fine-tuning
- Next Word Prediction
✅ GPT-2 (2019)
- 파라미터 수: 1.5B
- 데이터셋: WebText (대규모 웹페이지 데이터셋)
- 목표: 멀티태스크 문제 해결 (Multi-task Solving)
모든 NLP 태스크는 단어 예측 문제로 통합될 수 있다.”
| **p(output | input, task)** |
Multi-task Solving
- 입력(input), 출력(output), 작업(task) 정보를 자연어 텍스트 형식으로 통합.
- 다양한 작업이 단어 예측 문제로 변환될 수 있음을 입증.
Extended principles
- 지도 학습(Supervised Objective)과 비지도 학습(Unsupervised Objective)은 본질적으로 동일하며, 하나의 글로벌 최적화 목표(Global Minimum)로 통합
- 충분한 능력을 가진 언어 모델은 비지도 학습만으로도 다양한 작업을 해결할 수 있다고 주장
Ilya Sutskever의 통찰
- 텍스트 예측은 단순한 패턴 매칭이 아니라, World Knowledge의 압축
- 언어 모델은 텍스트가 생성된 Process을 학습, 단어 예측이 정확할수록 이 과정의 해상도(Resolution) 향상
단어 예측이 모든 NLP 문제를 해결하는 단일 목표가 될 수 있음
3.2.2 GPT-3 : Capacity Leap
GPT-2는 비지도 멀티태스크 학습(Unsupervised Multi-task Learning)을 목표로 했지만, 실제 성능은 지도 학습(Supervised Fine-tuning)을 사용한 최신 모델들에 미치지 못함
GPT-2는 비교적 작은 모델 크기로 인해 주로 다운스트림 작업(예: 대화 모델)에 맞춤형 미세 조정(Fine-tuning)해 사용
- 출시 연도: 2020년
- 파라미터 수: 175B (GPT-2의 약 100배)
- 핵심 혁신: In-Context Learning (ICL) 도입
- 목표: 지도 학습 없이 Zero-shot 또는 Few-shot 방식으로 다양한 작업을 수행
- 학습 패러다임:
- 사전 학습 (Pre-training): 다음 단어 예측 (Next Word Prediction)
- In-Context Learning (ICL): 자연어로 된 지시나 예시를 통해 새로운 작업 수행
자연어 텍스트로 주어진 지시(Instructions)와 몇 가지 예시(Demonstrations)를 통해 추가 학습 없이 새로운 작업을 수행하는 능력
- Zero-shot Learning, Few-shot Learning 능력 향상
- 다양한 NLP 작업에서 탁월한 성능 발휘: 언어 이해, 번역, 질의응답 등
- 특수 작업: 복잡한 논리 추론, 도메인 적응
- Emergent Abilities의 출현: 모델 규모가 증가하면서 새로운 능력(예: 복잡한 논리 문제 해결)이 나타남
GPT-3의 성능은 기존의 Scaling Laws에서 예측된 성능 수준을 초과
더 큰 모델이 더 강력한 In-Context Learning (ICL) 능력을 보임
→ PLM에서 LLM으로의 전환점
3.2.2 GPT-3 and GPT-3.5 : Capacity Enhancement
✅ Training on Code Data
- GPT-3의 한계: 복잡한 논리적 추론(예: 코드 생성, 수학 문제 해결)에서 부족함
- 해결책: Codex (2021) – GPT-3를 기반으로 GitHub 코드 데이터셋을 사용해 미세 조정(Fine-tuning)
텍스트와 코드 임베딩(Text and Code Embedding) 학습을 위한 대조 학습(Contrastive Learning) 접근법 사용
선형 분류(Linear Probe Classification), 텍스트 검색(Text Search), 코드 검색(Code Search)에 개선된 성능
✅ Human Alignment
RLHF (Reinforcement Learning with Human Feedback) 기술 사용
유해한(Toxic), 편향된(Biased), 허구적(Fictitious) 콘텐츠 없앰
- 인간이 주석을 달아 선호도를 평가
3.2.2 The Milestones of Language Models
✅ ChatGPT (2022)
- 기반 모델: GPT-3.5, GPT-4
- 훈련 방식: InstructGPT와 유사한 훈련 프로세스, 차이점 대화(Conversation)에 최적화됨.
- 인간이 생성한 대화 데이터를 사용 (사용자와 AI 역할을 모두 포함).
- InstructGPT 데이터셋과 결합하여 훈련.
- Multi-turn Dialogue에서 Context를 정확하게 유지 → 사용자와 자연스러운 대화를 수행
- World Knowledge 포함
✅ GPT-4 (2023)
- 주요 변화: 텍스트 기반 입력 → 멀티모달 입력 (Multimodal Signals)
- 기반 아키텍처: 디코더 전용 Transformer (Decoder-Only Transformer)
- 목표: 복잡한 문제 해결 및 안전성 강화
Multimodal Inputs
- 텍스트뿐만 아니라 이미지, 그래프 등 다양한 입력 신호를 처리
더 높은 수준의 논리적 추론 및 복잡한 문제 해결 능력
6개월간의 반복적 정렬(Iterative Alignment): RLHF(인간 피드백을 통한 강화 학습) 알고리즘 개선.
안전 보상 신호 (Safety Reward Signal): 유해한 응답 방지
Red Teaming: 악의적 요청이나 유해한 콘텐츠를 방지하기 위한 테스트 기법 도입
Predictable Scaling
- 작은 계산 자원을 사용해 최종 성능을 예측할 수 있는 기술 도입
- 훈련 효율성 극대화.
Optimization mechanisms
- 인프라 개선과 최적화 기법으로 모델 성능 극대화
환각(Hallucination) 문제 감소
✅ GPT-4V 및 GPT-4 Turbo (2023)
GPT-4V
- 시각 능력 (Vision Capabilities):
- 이미지 입력을 통해 복잡한 시각적 문제 해결 가능
- 설명, 분석, 객체 인식 등 다양한 작업 수행
- 위험 완화 (Risk Mitigation):
- 시각 입력에서 발생할 수 있는 위험 요소를 평가 및 완화 - AI의 멀티모달 기능이 실질적인 애플리케이션으로 확장
GPT-4 Turbo
- 모델 용량 확장: GPT-4보다 더 강력한 성능
- 지식 소스 업데이트: 2023년 4월까지의 데이터 포함
- 긴 컨텍스트 윈도우: 최대 128k 토큰 지원
- 성능 최적화: 비용 절감, 응답 속도 개선
- 기능 업데이트:
- Function Call: 기능 호출 지원
- 일관된 출력 (Reproducible Outputs) 지원
- Assistants API:
- 특정 목표를 수행하는 에이전트(Assistants) 개발을 쉽게 지원
- 명령, 도구 사용, 추가 지식 통합 가능
- 멀티모달 확장:
- DALL·E 3: 이미지 생성
- Text-to-Speech (TTS): 텍스트를 음성으로 변환
- Voice Samples: 음성 샘플 제공
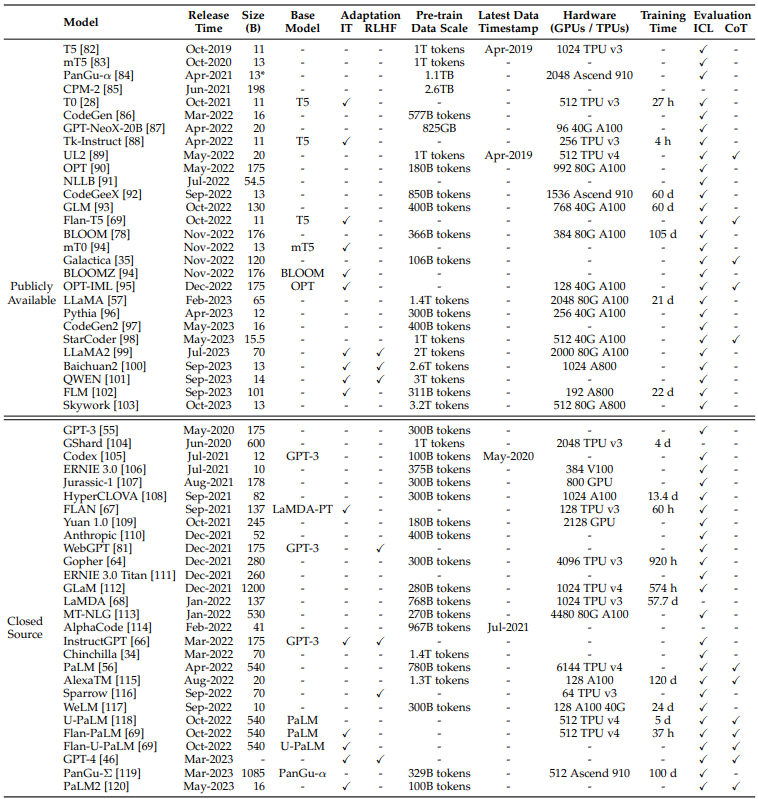
TABLE 1: Statistics of large language models (having a size larger than 10B in this survey) in recent years, including the capacity evaluation, pre-training data scale (either in the number of tokens or storage size) and hardware resource costs. In this table, we only include LLMs with a public paper about the technical details. Here, “Release Time” indicates the date when the corresponding paper was officially released. “Publicly Available” means that the model checkpoints can be publicly accessible while “Closed Source” means the opposite. “Adaptation” indicates whether the model has been with subsequent fine-tuning: IT denotes instruction tuning and RLHF denotes reinforcement learning with human feedback. “Evaluation” indicates whether the model has been evaluated with corresponding abilities in their original paper: ICL denotes in-context learning and CoT denotes chain-of-thought. “*” denotes the largest publicly available version.