
[논문분석] KAN: Kolmogorov–Arnold Networks
KAT에 기반한 Network algorithm : 중간 과정 의미 해석 + 수식 유도 (MLP blackbox와 대조)
[Paper, Code]
Author: Ziming Liu, Yixuan Wang, et al.
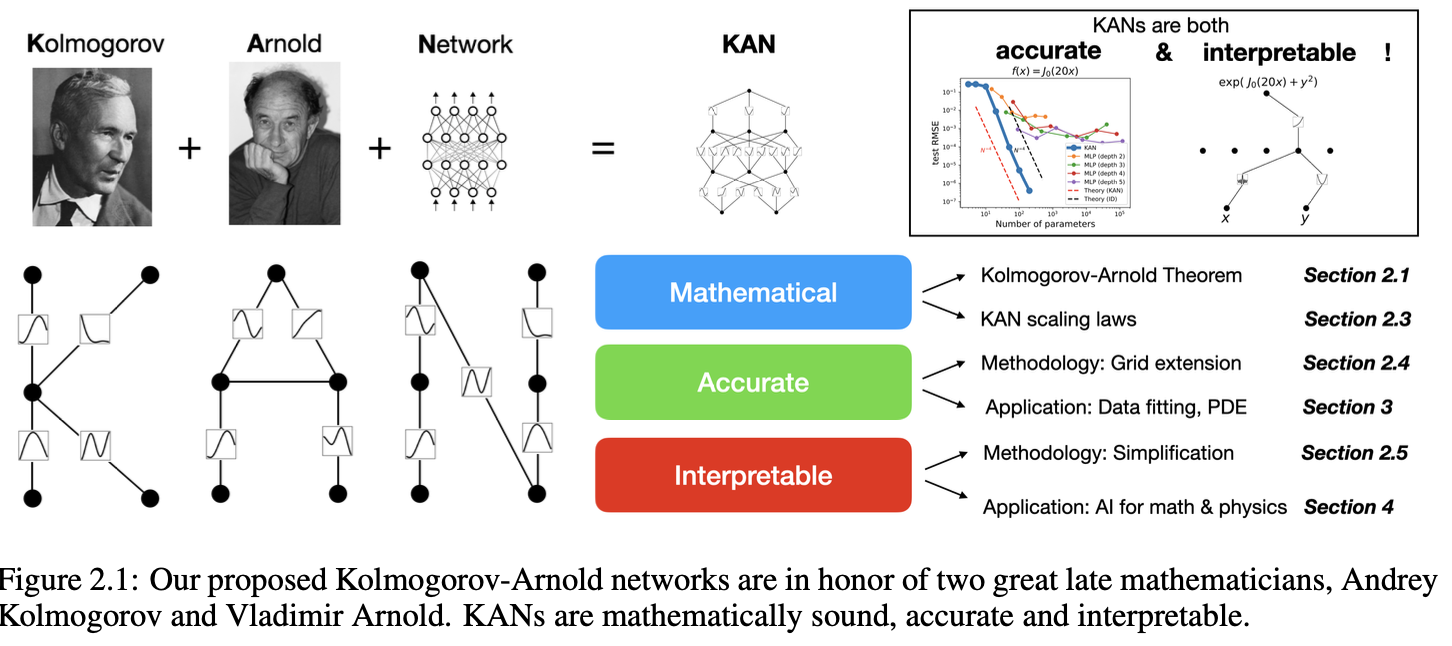
Inspired by the Kolmogorov-Arnold representation theorem, we propose Kolmogorov- Arnold Networks (KANs) as promising alternatives to Multi-Layer Perceptrons (MLPs). While MLPs have fixed activation functions on nodes (“neurons”), KANs have learnable activation functions on edges (“weights”). KANs have no linear weights at all – every weight parameter is replaced by a univariate function parametrized as a spline. We show that this seemingly simple change makes KANs outperform MLPs in terms of accuracy and interpretability, on small-scale AI + Science tasks. For accuracy, smaller KANs can achieve comparable or better accuracy than larger MLPs in function fitting tasks. Theoretically and empirically, KANs possess faster neural scaling laws than MLPs. For interpretability, KANs can be intuitively visualized and can easily interact with human users. Through two examples in mathematics and physics, KANs are shown to be useful “collaborators” helping scientists (re)discover mathematical and physical laws. In summary, KANs are promising alternatives for MLPs, opening opportunities for further improving today’s deep learning models which rely heavily on MLPs.
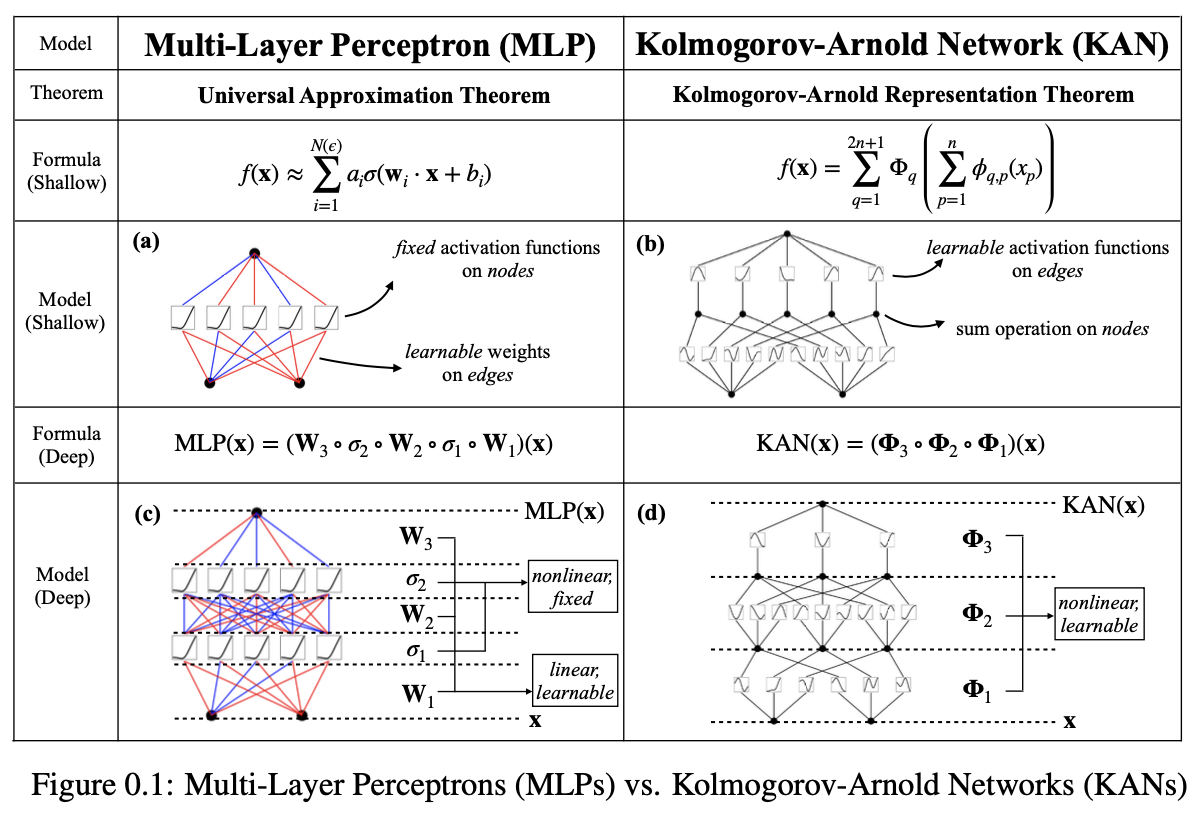
Multi-layer perceptrons (MLPs)
fully-connected feedforward neural networks
nonlinear functions(비선형의 패턴)을 나타내기 위해 linear layer와 active function을 이어붙여 쌓은 것
하지만 MLP는 Transformer에서 다음과 같은 단점이 있음
- 파라미터 효율성: Transformer에서는 대부분의 non-embedding parameters를 차지
- 해석 가능성: Attention 레이어에 비해 MLP는 직관적 해석이 어려움
non-embedding parameters란?
예시 : Transformer 모델은 주로 두 가지 주요 구성 요소로 이루어져 있음
1. **Embedding Layer**
- 입력 토큰을 고정된 크기의 벡터로 변환
- 임베딩 테이블이 주요 파라미터
2. **Non-Embedding Layers**
- **Self-Attention Layers (자기-어텐션 레이어)**: Query, Key, Value 행렬로 입력 데이터를 처리
- **MLP (Feed-Forward Network, FFN)**: Attention 레이어의 출력을 비선형 변환하여 더 복잡한 패턴을 학습
- **Layer Normalization**: 안정적인 학습을 보장
본 논문에서는 MLPs를 대체할 KANs 제안
| 특징 | MLPs (Multi-Layer Perceptron) | KANs (Kolmogorov-Arnold Networks) |
|---|---|---|
| 이론적 기반 | 보편 근사 정리 (Universal Approximation Theorem) | Kolmogorov-Arnold 표현 정리 (Representation Theorem) |
| 활성화 함수 위치 | 노드 (Neuron) | 엣지(Edge/Weight) |
| 가중치 구조 | 선형 가중치 행렬 (Linear Weight Matrices) | 학습 가능한 1D 스플라인 함수 (Spline Function) |
| 노드의 역할 | 비선형 활성화 함수 적용 | 신호를 단순히 합산 |
| 비선형성 발생 위치 | 노드 | 엣지 (Spline Function) |
| 해석 가능성 | 상대적으로 낮음 | 상대적으로 높음 |
| 계산 그래프 크기 | 일반적으로 큼 | 더 작고 효율적일 수 있음 |
Kolmogorov-Arnold 표현 정리를 활용해 신경망을 설계하려는 연구는 이미 다수 존재
그러나 대부분의 연구는 깊이(depth)가 2이고 폭(width)이 (2n + 1)인 초기 구조
- 입력 차원 n이 커질수록 폭이 기하급수적으로 증가 → 고차원 문제에서는 네트워크가 지나치게 비대해지고 비효율적 and 비용 증가
- 깊이 2의 얕은 네트워크는 복잡한 조합적 구조 (Compositional Structure)를 효과적으로 학습하기 어려움
- 깊이가 얕고 폭이 넓은 구조에서는 효율적인 학습이 어려움 → 역전파(Backpropagation)와 같은 현대적인 최적화 알고리즘이 제대로 작동 못함
- 이론적으로 모든 연속 함수를 근사할 수 있지만, 실제로는 효율적이지 않은 방식으로 근사할 가능성이 있음 → 깊이가 얕기 때문 비 선형성 부족
3.1 Why the depth is ‘2’ and the width is ‘2n + 1’ ?
Kolmogorov-Arnold Representation Theorem에 의하면 임의의 연속 함수는 두 단계(depth = 2)와 (2n + 1)개의 중간 노드(width)만으로 정확하게 근사가능
깊이를 늘릴 필요 없이 최소한의 깊이(2)와 최소한의 폭(2n+1) 만으로도 충분
예전에는 computing resources의 한계로 복잡한 다층 구조를 학습하기에 어려움이 있었음.
현대적인 Backpropagation 알고리즘이 없었음 → 깊이의 한계
이를 통해 Curse of Dimensionality를 부분적으로 극복
- Volume 증가, 학습 데이터의 부족, 계산량 기하급수적 증가, 유클리드 거리(Euclidean Distance)와 같은 전통적인 거리 메트릭 한계 등으로 인해 발생
- Dimensionality Reduction, Feature Selection, Regularization, more data 등으로 극복
본 논문에서는 위에 문제를 확장해 임의의 깊이(Arbitrary Depth)와 폭(Arbitrary Width)으로 일반화
3.1 KANs sol : Splines + MLPs
- KANs는 본질적으로 Splines와 MLPs의 조합
- 두 모델의 강점을 활용하면서 각자의 약점을 보완
| Splines | MLPs | |
|---|---|---|
| Pros. | - 저차원 함수에서 높은 정확도 - 국소적으로 조정(Local Adjustments) 가능 - 다양한 해상도 전환 가능 |
- 특징 학습(Feature Learning)에 강함 → intrinsic manifold를 배우는데 능함 - 고차원 데이터에서 잘 작동 |
| Cons. | - Curse of Dimensionality, COD에 취약 - 함수의 조합적 구조 활용 불가능 |
- 저차원의 Symbolic 함수 최적화에 비효율적 - 단일 변수 함수(Univariate Function) 최적화 어려움 - Interpretability 낮음 |
KANs는 외부적으로는 MLP처럼 작동하여 특징을 학습, 내부적으로는 Splines처럼 작동하여 높은 정확도로 특징을 최적화
기존 연구 (Relu deep neural networks and linear finite elements, Deep neural networks and finite elements of any order on arbitrary dimensions)에서ReLU 활성화 함수를 사용하는 MLP와 Splines의 연관성 파악 → 결합 가능
- 외부 자유도 (External Degrees of Freedom) 함수의 조합적 구조 Compositional Structure 학습
- 내부 자유도 (Internal Degrees of Freedom) 함수의 단일 변수 함수 (Univariate Functions) 근사
고차원 함수 예시
\[f(x_1, \cdots, x_N) = \exp\left( \frac{1}{N} \sum_{i=1}^{N} \sin^2(x_i)\right)\]입력 벡터 \((x_1,⋯,x_N)\) 의 진폭 패턴을 \(\mathrm{sin}^2\) 으로 변환해 평균값 계산
→ 평균값이 클수록 (즉, 대부분의 sin2(xi) 값이 1에 가까울수록) f의 출력 값이 커짐, 반대 작아짐
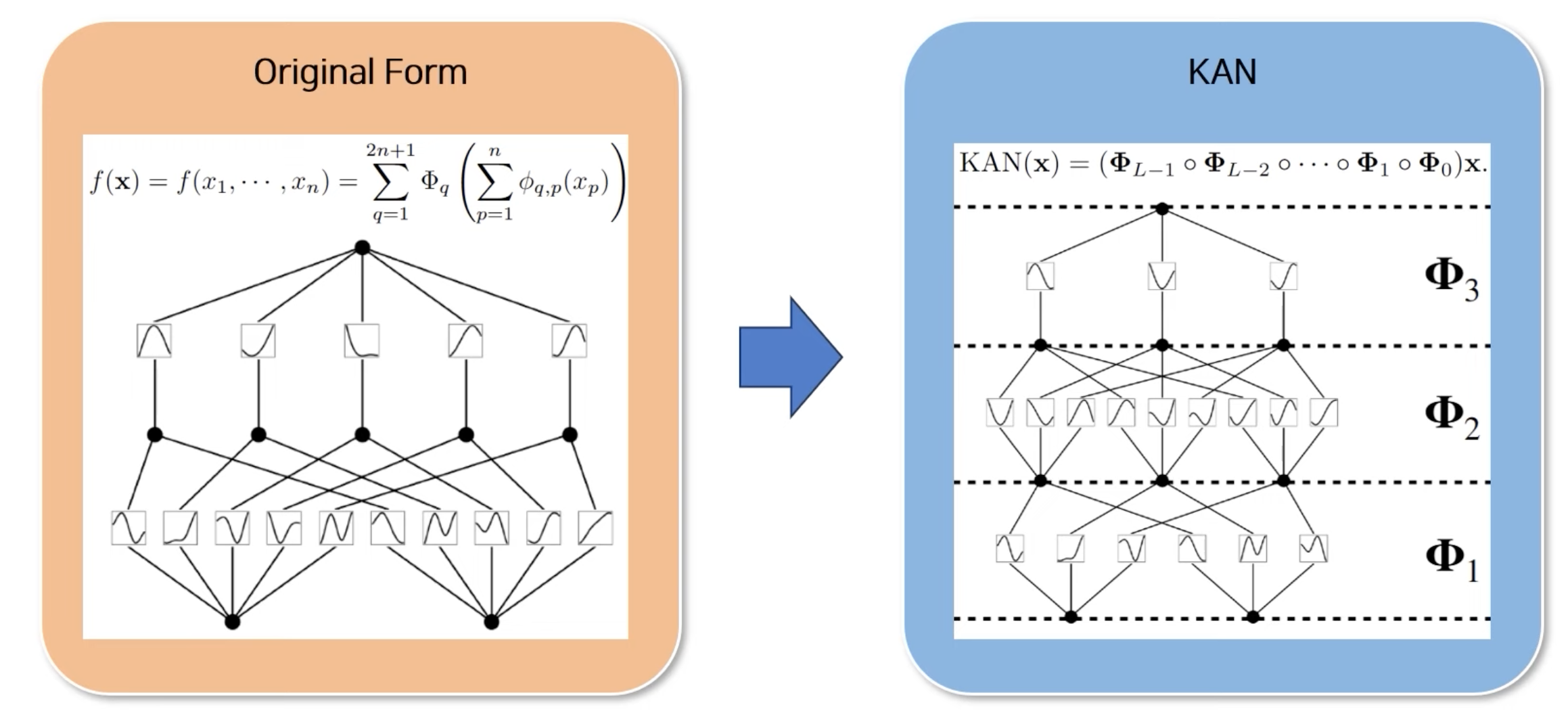
4.1 Kolmogorov-Arnold Representation theorem
\(f(x_1,x_2,⋯,x_n)\) 과 같은 복잡한 다변수 함수는 단변수 함수(Univariate Functions), 유한 개의 덧셈(Addition)만으로 표현할 수 있다.
\[f(\mathbf{x}) = f(x_1, \cdots, x_n) = \sum_{q=1}^{2n+1} \Phi_q \left( \sum_{p=1}^{n} \phi_{q,p}(x_p) \right),\]- \(ϕ_{q,p}:[0,1]\) → \(\mathbb{R}\) : 단변수 함수
- \(Φ_q\) : \(\mathbb{R}\) → \(\mathbb{R}\) : 단변수 함수
각 변수를 단변수 함수에 적용한 후 더함 → 내부 합의 결과에 또 다른 단변수 함수를 적용하고 다시 합산 → 단변수 함수와 덧셈으로만 구성 , 2n+1개의 항(term)이 필요 (n에 대해 선형적)
4.1.1 Problem
- \(ϕ_{q,p}:[0,1], Φ_q\) 함수가 Non-smooth Functions 이거나 fractal 형태 일 수 있음 → 근사 힘듬
- Pathological Behavior : 존재성(existence)만 보장, 단변수 함수가 학습하기 쉬운 형태로 존재한다는 보장은 없음 → 실제 구현에서 어려움 존재
4.1.2 위 이론을 다시 주목하는 이유
- Relaxing the Structure : 구조를 일반화해 깊이 제한을 없앰
- Smoothness in Real-world Problems : 실제 물리 시스템이나 이미지 처리 문제는 smooth한 함수를 주로 다룸
- Physicist’s Mindset : typical cases를 다루는 것에 중점
- Structural Learnability : physical, machine learning 문제들이 근본적으로 구조적임
4.2.1 Supervised learning task
\[y_i ≈ f(x_i)\]
를 만족하는 \(\phi_{q,p} , Φ_q\) 를 찾을 수 있으면 ok
두 함수는 단변수 함수 → non-linear function
4.2.2 B-spline curve (Basis spline)
정의
- 곡선이나 함수를 근사할 때 사용되며, 연속적이고 매끄러운 함수 표현을 위해 Local Basis를 사용 전체 곡선이 몇몇 Control Points으로 정의
- 각 제어점은 특정 가중치(학습 가능한 계수)를 가지며, 이 가중치를 통해 곡선의 형태가 조정
-
표현식 : Basis spline 들의 선형 결합
\[\phi_{q,p}(x_p) = \sum_{k=1}^{K} w_{q,p,k} B_k(x_p)\]- \(B_k(x_p)\): Basis Function
- \(w_{q,p,k}\): 학습 가능한 가중치 (Control Point의 계수)
- K: B-spline Basis Function의 개수
장점
- Smooth function approximation for complex functions
- Locality : Control Point가 미치는 범위가 국소적 → 학습 안정
- Flexibility : Basis spline 개수 조절을 통해 다양한 함수 표현 가능
- Trainability : Backpropagation를 통해 w 최적화 가능
모든 학습해야 할 함수가 단변수 함수 (1D functions) → 이를 B-spline 곡선으로 매개변수화
B-spline 곡선: 단변수 함수를 근사하기 위한 곡선 (learnable coefficients를 가짐)
먼저 다음 함수를 따라 설계
\[f(\mathbf{x}) = f(x_1, \cdots, x_n) = \sum_{q=1}^{2n+1} \Phi_q \left( \sum_{p=1}^{n} \phi_{q,p}(x_p) \right),\]Activation Functions(단변수 함수)를 엣지(edge)에 배치
- 각 입력이 전달되는 엣지에서 활성화 함수가 작동
- 노드(Node): 단순 덧셈(Summation)만 수행
- 즉, activate function을 계산한 이후, 각 노드에서 sum
-
기존 MLPs 식 (차이 비교)
\[h^{(l)}=σ(W^{(l)}h^{(l−1)}+b^{(l)})\]
4.2.3 Deep KANs
여기까지는 기존 연구들과 유사, 추가로 Deep KANs 만들기 → ‘KAN 층(KAN Layer)’의 정의
KAN의 한 층
\[Φ=\{ϕ_{q,p}\},\ \ \ p=1,2,⋯,n_{in},\ \ \ q=1,2,⋯,n_{out}\]- \(n_{in}\): 입력 차원 (Input dimension)
- \(n_{out}\): 출력 차원 (Output dimension)
- 각 함수 \(ϕ_{q,p}\) 는 학습 가능한 매개변수(parameters)
이 식은 다음과 같이 구성
- 1층 (Inner Layer):
- \[n_{in}=n\]
- \[n_{out}=2n+1\]
- 2층 (Outer Layer):
- \[n_{in}=2n+1\]
- \[n_{out}=1\]
다음을 통해 Stacking layers가 가능 → deep KAN
4.2.4 KAN layer shape
layer를 정수 배열로 표현
\[[n_0,n_1,⋯,n_L]\]- \(n_i\) : i번째 층의 노드(node) 수
- \((l, i)\) : l번째 층의 i번째 뉴런(neuron)
- 각 뉴런의 활성화 값(activation value)은 \(x_{l,i}\) 로 표시
활성화 함수가 엣지(edge)에 대응
\[ϕ_{l,j,i},\ \ \ l=0,⋯,L−1,\ \ \ i=1,⋯,n_l,\ \ \ j=1,⋯,n_{l+1}\]- \(l\) 과 \(l+1\) 사이에 \(n_l n_{l+1}\) 개의 활성화 함수가 존재
- 활성화 함수는 \((l,i)\) 에서 \((l+1,j)\) 로 연결되는 엣지에 적용
활성화 값은 다음과 같이 계산 : 엣지 \((l,i)→(l+1,j)\) 에서 활성화 함수가 적용된 후의 값
\[\widetilde{x}_{l,j,i} = \phi_{l,j,i}(x_{l,i})\]- \(x_{l,i}\) : (l,i) 뉴런의 입력값
(l+1,j) 뉴런의 최종 활성화 값은 엣지에서 변환된 모든 값의 합
\[x_{l+1,j} = \sum_{i=1}^{n_l} \phi_{l,j,i}(x_{l,i})\]\(Φ_l\) 는 l번째 KAN 층을 나타내는 Function Matrix : 행렬 형태로 표현
\[\mathbf{x}_{l+1} = \begin{pmatrix} \phi_{l,1,1}(\cdot) & \phi_{l,1,2}(\cdot) & \cdots & \phi_{l,1,n_l}(\cdot) \\ \phi_{l,2,1}(\cdot) & \phi_{l,2,2}(\cdot) & \cdots & \phi_{l,2,n_l}(\cdot) \\ \vdots & \vdots & \ddots & \vdots \\ \phi_{l,n_{l+1},1}(\cdot) & \phi_{l,n_{l+1},2}(\cdot) & \cdots & \phi_{l,n_{l+1},n_l}(\cdot) \end{pmatrix} \mathbf{x}_l\]KAN Network
네트워크 출력 : L개의 층(layer)으로 구성되며, 입력 벡터 x0에 대해 최종 출력
\[\text{KAN}(\mathbf{x}) = (\mathbf{\Phi}_{L-1} \circ \mathbf{\Phi}_{L-2} \circ \cdots \circ \mathbf{\Phi}_1 \circ \mathbf{\Phi}_0) \mathbf{x}\]- ∘: 층 간 합성(Composition)
4.2.5 Relationship between KAN and Kolmogorov-Arnold Representation
\[f(\mathbf{x}) = \sum_{i_{L-1}=1}^{n_{L-1}} \phi_{L-1,i_{L},i_{L-1}} \left( \sum_{i_{L-2}=1}^{n_{L-2}} \phi_{L-2,i_{L-1},i_{L-2}} \left( \cdots \left( \sum_{i_0=1}^{n_0} \phi_{0,i_1,i_0}(x_{i_0}) \right) \right) \right)\]
- 모든 중간 층에서 각 엣지마다 단변수 함수 \(ϕ_{q,p}\) 가 적용
- 활성화 함수(엣지) → 합산(노드)
4.2.6 Difference between KAN and MLP
\[\text{MLP}(\mathbf{x}) = (\mathbf{W}_{L-1} \circ \sigma \circ \mathbf{W}_{L-2} \circ \sigma \circ \cdots \circ \mathbf{W}_1 \circ \sigma \circ \mathbf{W}_0) \mathbf{x}\]
학습 파라미터 : 선형 가중치와 편향
학습 파라미터 : 단변수 함수(1D Functions)
4.2.7 Implementation details
Residual Activation Functions
Spline으로 기본적인 ϕ 모습(low-frequency components) 학습 이후, 학습이 안된 만큼의 ϕ를 Silu(residual)의 합으로 계산
\[\phi(x) = w_b b(x) + w_s \text{spline}(x)\]논문에서 Silu를 더해주어야만 학습이 진행된다고 함 (smooth)
아래 그림 참고
- zero에서는 smooth하지 않음
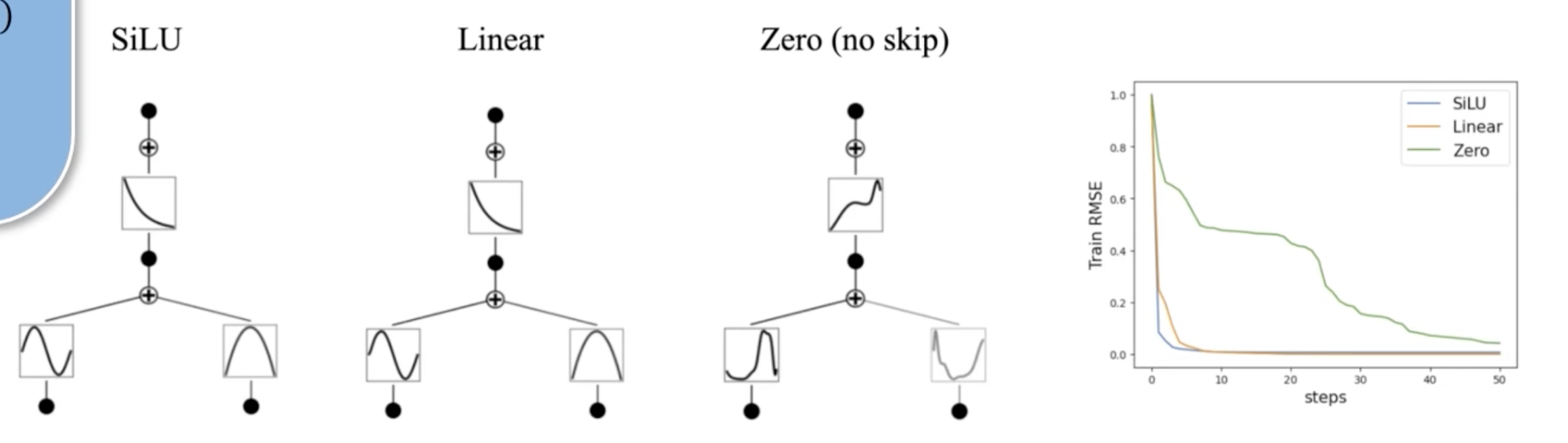
- \(w_b\): 기저 함수 \(b(x)\) 의 가중치
- \(w_s\): 스플라인 함수의 가중치
b(x)는 대부분의 경우 SiLU 함수로 설정
\[\text{spline}(x) = \sum_i c_i B_i(x)\]Spline Function은 B-Spline의 선형 결합으로 매개변수화
- \(c_i\) : 학습 가능한 매개변수
- \(B_i(x)\): B-스플라인의 기본 함수
Initialization Scales
각 활성화 함수는 초기화 시 \(w_s=1\) 로 설정되며, 스플라인은 초기값으로 \(spline(x)≈0\) 으로 설정
\(w_b\) : Xavier 초기화 기법을 사용하여 초기화 (linear layer에서 사용되는 방법)
Update of Spline Grids
각 스플라인 그리드는 입력 활성화에 따라 실시간으로 업데이트
스플라인은 경계가 고정된 영역 내에서 정의되지만, 훈련 중에 활성화 값은 해당 영역을 벗어날 수 있음
입력에 따라 동적으로 스플라인 그리드를 업데이트하여 이러한 문제를 해결
입력 분포에 맞춰 그리드 포인트 조정 (위치 조정)
parameter count
| 특성 | KAN | MLP |
|---|---|---|
| 파라미터 수 | \(O(N^2LG)\) | \(O(N2L)\) |
| 학습 효율성 | 높은 표현력 (스플라인 사용) | 단순한 구조로 더 적은 파라미터 |
| 일반화 성능 | 더 적은 NN으로 더 나은 일반화 | 높은 NN 필요 |
| 해석 가능성 (Interpretability) | 더 높은 해석 가능성 | 낮은 해석 가능성 |
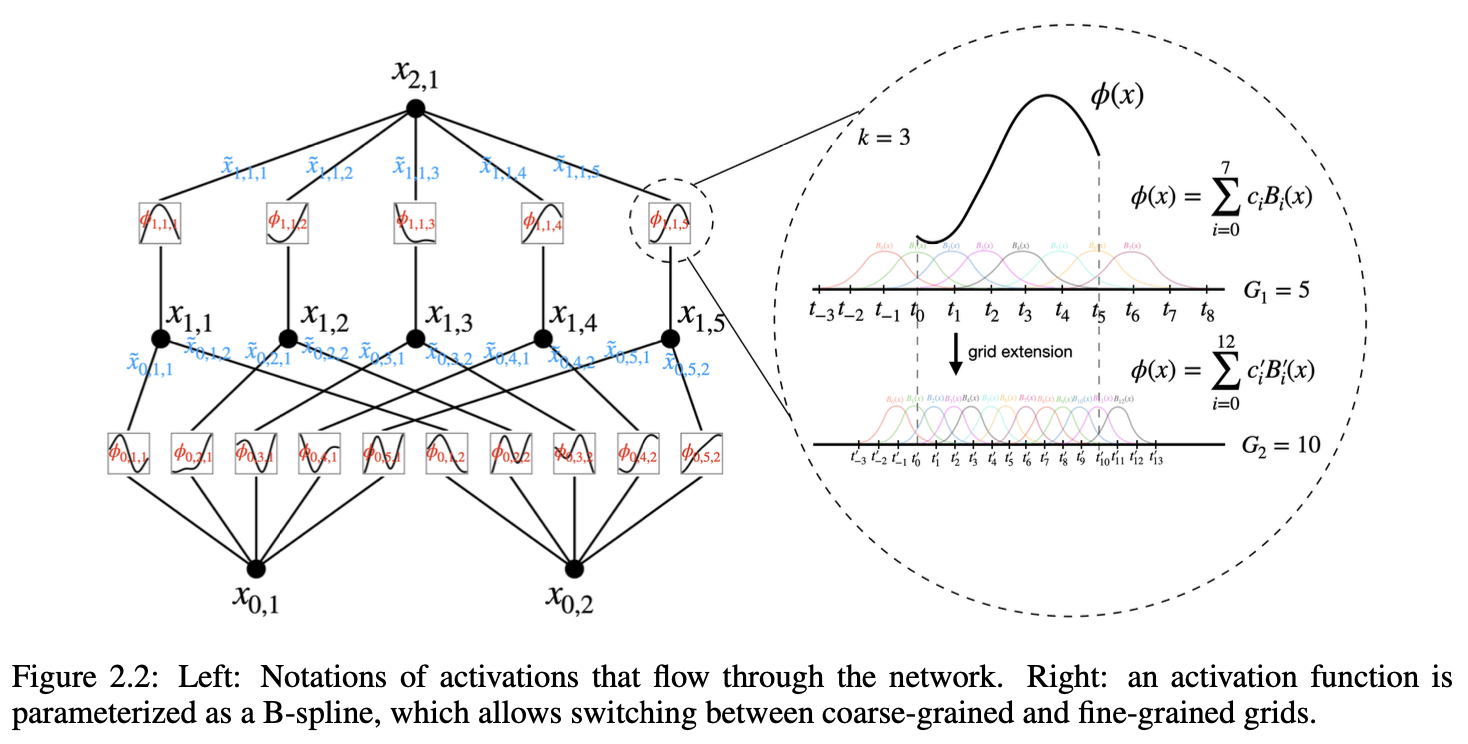
4.2.8 Grid extension
Accuracy 높일 수 있는 방법
초기에는 적은 제어점으로 시작(Coarse) → 더 복잡한 함수가 필요한 경우 확장(Fine)
초기에는 낮은 제어점으로 시작 : overfitting 방지
\[\{ c'_j \} = \arg\min_{\{ c'_j \}} \mathbb{E}_{x \sim p(x)} \left( \sum_{j=0}^{G_2 + k - 1} c'_j B'_j(x) - \sum_{i=0}^{G_1 + k - 1} c_i B_i(x) \right)^2\]최소제곱법(Least Squares Algorithm)을 기반으로, 미세한 그리드에서의 스플라인 파라미터를 최적화하여 거친 그리드와의 차이를 최소화
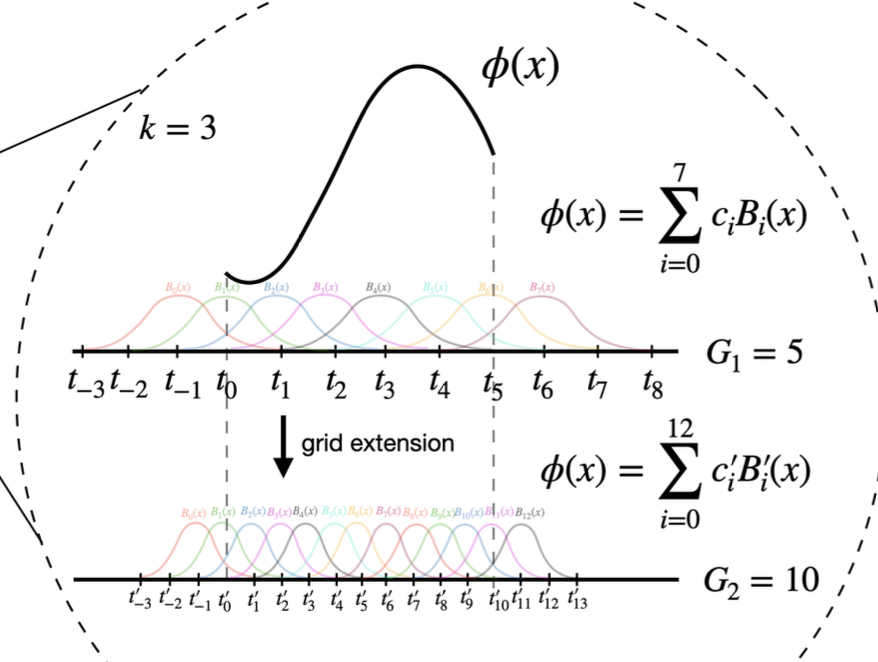
| 특징 | Grid Extension | Update of Spline Grids |
|---|---|---|
| 목표 | 기존 모델을 더 세밀하게 개선 | 입력 데이터에 따라 실시간 조정 |
| 시점 | 학습 이후 또는 모델 개선 단계 | 학습 과정 중 지속적 발생 |
| 기법 | 기존 파라미터를 기반으로 새로운 그리드 확장 | 활성화 값에 따라 동적으로 업데이트 |
| 방식 | 최적화(Least Squares Algorithm)를 통해 미세한 그리드로 확장 | 입력 분포에 맞춰 그리드 포인트 조정 |
| 재학습 필요성 | 없음 (기존 파라미터 활용) | 없음 (실시간 조정) |
| 사용 사례 | 더 높은 정확도 필요 시 | 학습 데이터의 분포가 동적으로 변화할 때 |
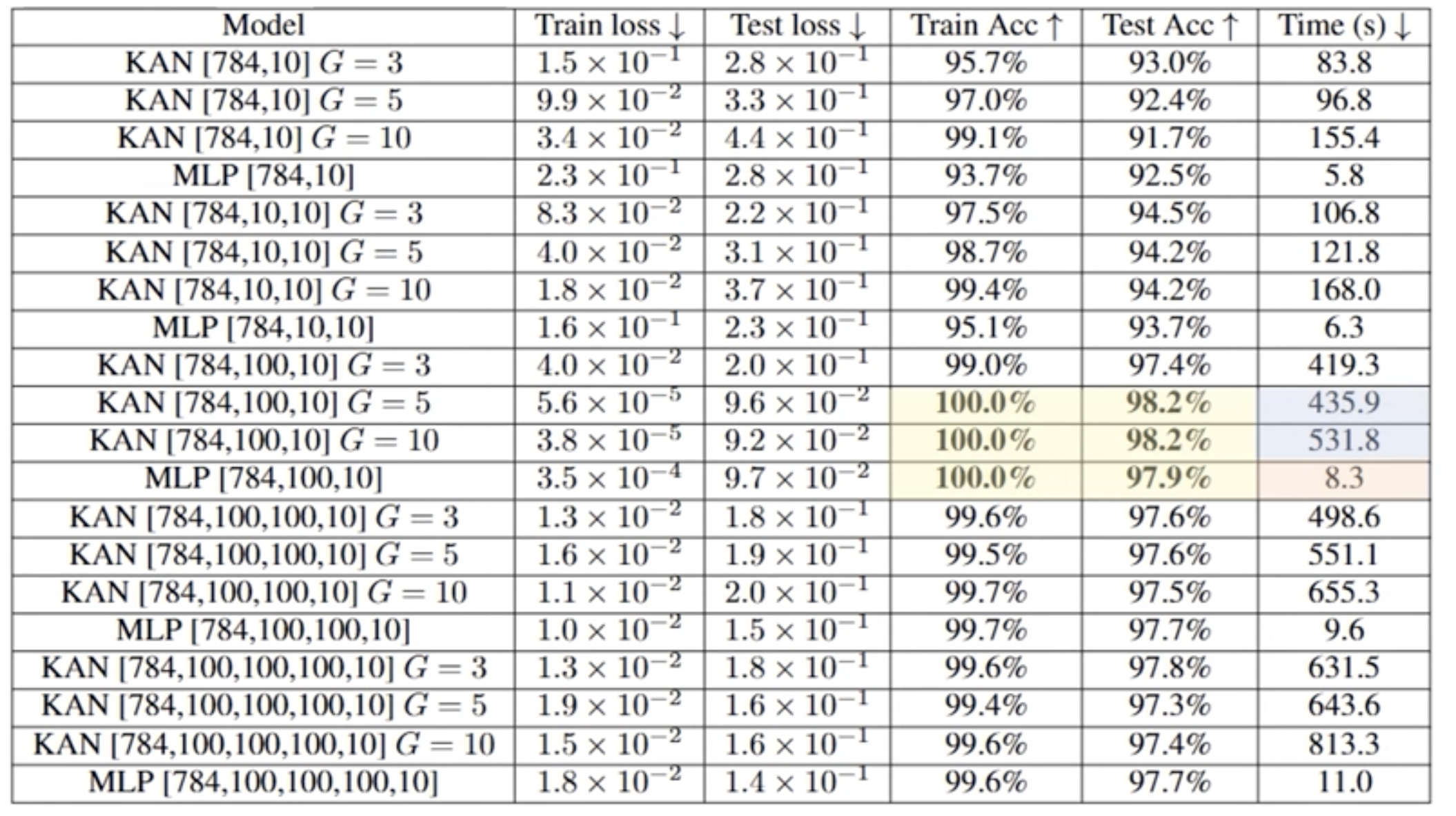
5.1 Overall
Training 방법 : 데이터 집합의 구조에 가장 잘 맞는 KAN 모양을 선택하는 방법
데이터 세트가 f(x, y) = exp(sin(πx)+y2) 기호식을 통해 생성된다는 것을 알고 있다면, [2, 1, 1] KAN이 이 함수를 표현할 수 있다는 것을 알 수 있음
그러나 실제로는 priori하게 정보를 알 수 없으므로 이 모양을 자동으로 결정할 수 있는 접근 방식
- start from a large enough KAN
- train it with sparsity regularization followed by pruning
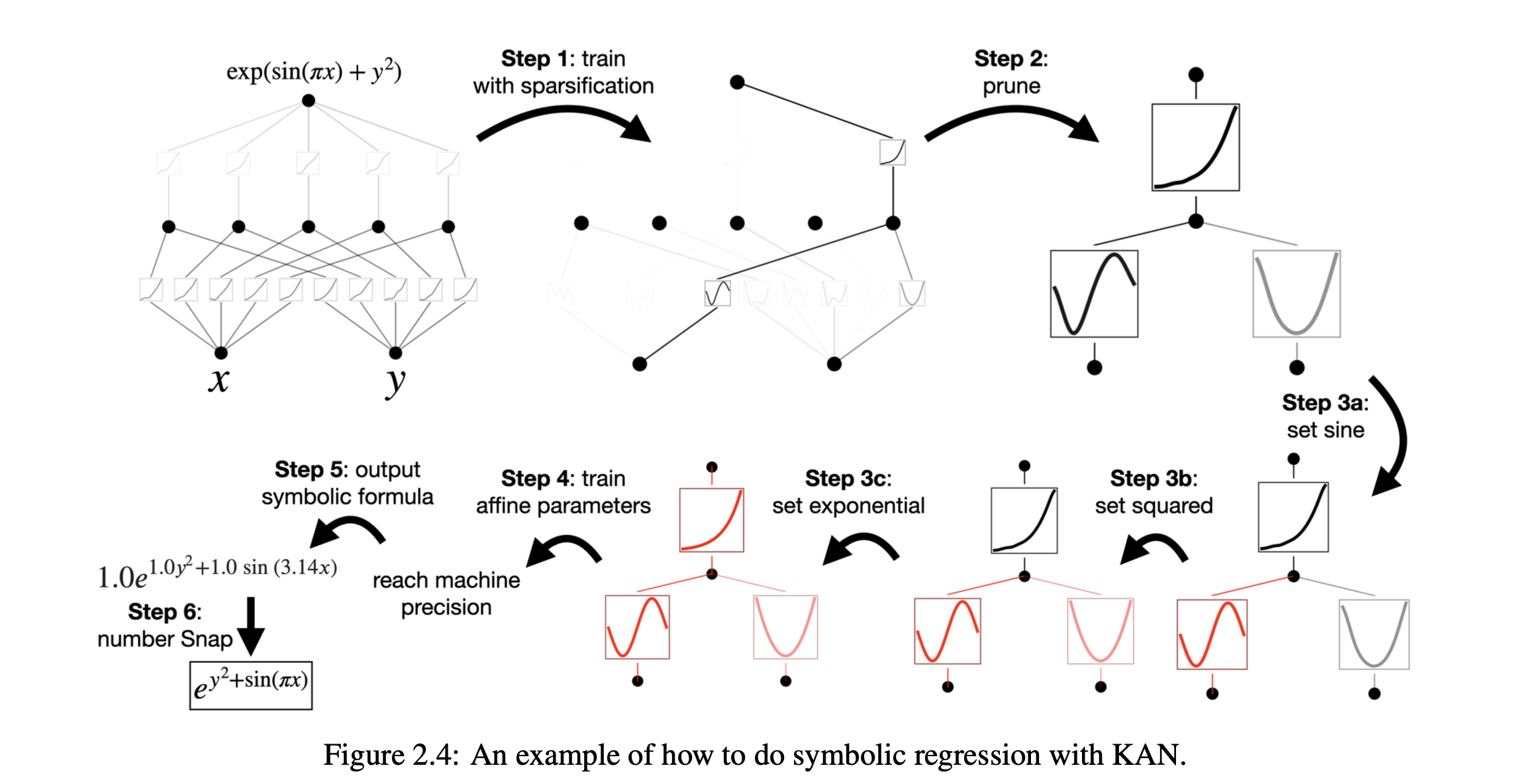
아래는 자세한 techniques
5.2 Simplification techniques
5.1 Sparsification
MLP (Multi-Layer Perceptron):
- L1 정규화(L1 Regularization)는 선형 가중치(linear weights)에 적용
- 목표: 가중치 값 중 일부를 0으로 만들어 네트워크를 희소(sparse)하게 만듦.
- L1 정규화는 가중치의 절댓값 합을 손실 함수에 추가하여 가중치 값이 0에 가까워지도록 유도 → 가중치가 작은 경우 최적화 과정에서 정확히 0으로 수렴
- 손실 함수의 그래디언트가 L1 항에 의해 절벽 (Sharp Slope)을 형성
- L2: 가중치를 부드럽게 줄일 뿐, 정확히 0이 되지는 않음
KAN에는 선형 가중치가 없음 → activation functions이 가중치 역할
추가로 Entropy Regularization 적용
L1 Norm of Activation Function
\[|\phi|_1 \equiv \frac{1}{N_p} \sum_{s=1}^{N_p} \left| \phi(x^{(s)}) \right|\]- \(N_p\): 입력 샘플의 수
- \(ϕ(x^{(s)})\): s번째 입력 샘플에서의 활성화 함수 출력 값
각 활성화 함수가 입력에 대해 평균적으로 얼마나 큰 출력을 내는지 나타냄
Average Output Magnitude를 의미 → 전체적으로 L1 Norm 을 통해 모든 활성화 함수나 가중치의 절댓값을 0으로 수렴시키는 방향으로 작동
의미있는 부분은 Prediction Loss로 보존 의미 없는 부분은 L1 Norm loss 에 의해 0으로 수렴
값이 작을수록 함수가 더 sparse
MLP에서 L2와 유사 → 따라서 정확히 0이 될 수 없고 Entropy 필요
L1 Norm of KAN Layer
\[|\Phi|_1 \equiv \sum_{i=1}^{n_{\text{in}}} \sum_{j=1}^{n_{\text{out}}} |\phi_{i,j}|_1\]- \(n_{in}\): 입력 노드 수
- \(n_{out}\): 출력 노드 수
- \(∣ϕ_{i,j}∣_1\): i번째 입력 노드와 j번째 출력 노드 사이 활성화 함수의 L1 노름
Entropy Regularization
\[S(\Phi) = - \sum_{i=1}^{n_{\text{in}}} \sum_{j=1}^{n_{\text{out}}} \frac{|\phi_{i,j}|_1}{|\Phi|_1} \log \left( \frac{|\phi_{i,j}|_1}{|\Phi|_1} \right)\]- \(∣ϕ_{i,j}∣_1\): i번째 입력과 j번째 출력 사이의 활성화 함수의 L1 노름
- \(∣Φ∣_1\): 전체 레이어의 L1 노름
활성화 함수의 출력을 확률 분포로 해석 → Entropy 최소화
로그 안의 값 : 각 활성화 함수가 전체 네트워크에서 차지하는 비율
이를 통해 MLP L1에서 정확히 0으로 수렴하는 효과를 낼 수 있음
초기에는 함수들이 균일하게 분포 엔트로피가 높음 → 손실 함수를 최소화하기 위해 특정 활성화 함수에만 집중 → sparse
Total Loss Function
\[\ell_{\text{total}} = \ell_{\text{pred}} + \lambda \left( \mu_1 \sum_{l=0}^{L-1} |\Phi_l|_1 + \mu_2 \sum_{l=0}^{L-1} S(\Phi_l) \right)\]- \(ℓ_{pred}\): 예측 손실 (Prediction Loss)
- \(λ\): 전체 정규화 강도를 조절하는 하이퍼파라미터
- \(μ_1\): L1 정규화 가중치 (\(μ_1=1\))
- \(μ_2\): 엔트로피 정규화 가중치 (\(μ_2=1\))
- \(∣Φ_l∣_1\): \(l\) 번째 레이어의 L1 노름
- \(S(Φ_l)\): \(l\) 번째 레이어의 엔트로피 정규화
5.2 Visualization
각 활성화 함수의 중요도를 시각적으로 확인
활성화 함수 ϕl,i,j의 투명도는 tanh 함수를 통해 설정
\[\text{Transparency} \propto \tanh(\beta A_{l,i,j})\]- β=3: 스케일링 파라미터 (일반적으로 3)
- \(A_{l,i,j}\): 활성화 함수의 중요도나 크기
작은 값의 활성화 함수는 더 투명하게 표시되고, 중요한 활성화 함수만 강조
5.3 Pruning
\(I_{l,i}\) 와 \(O_{l,i}\) 가 모두 임계값 \(θ=10^{−2}\) 보다 낮으면 해당 노드는 제거
Incoming Score
\[I_{l,i} = \max_k(|\phi_{l-1,i,k}|_1)\]- \(I_{l,i}\): l번째 층의 i번째 뉴런의 입력 스코어
- k: 이전 층(\(l−1\))의 활성화 함수
Outgoing Score
\[O_{l,i} = \max_j(|\phi_{l+1,j,i}|_1)\]- \(O_{l,i}\): \(l\) 번째 층의 \(i\) 번째 뉴런의 출력 스코어
- \(j\): 다음 층(\(l+1\))의 활성화 함수
5.4 Symbolification
symbolic한 함수로 치환
파라미터화 되여있는 함수 → 수식
아래와 같이 초기화
\[y \approx cf(ax + b) + d\]- a,b,c,d: 선형 변환 파라미터
- x: 활성화 함수의 입력값
- y: 활성화 함수의 출력값
- f: 지정된 기호적 함수 (예: cos(x),log(x))
5.5 Addition
필요에 따라 추가 과정
Affine Transformation
최종 수식 획득
최종 Appoximation에서 중간 과정 및 수식을 찾을 수 있음 → 해석이 가능 (MLP는 불가능)
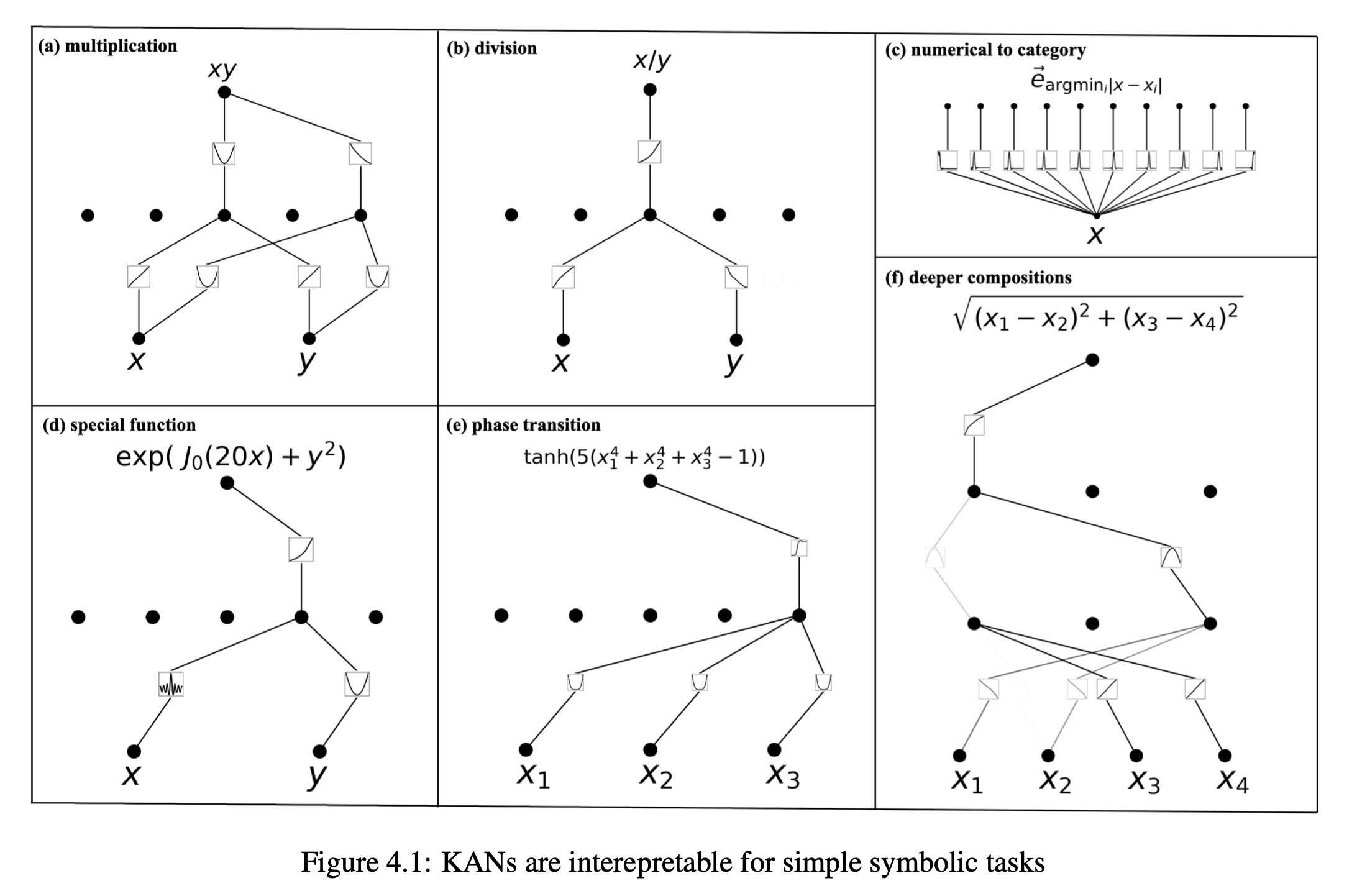
다양한 case study가 있음
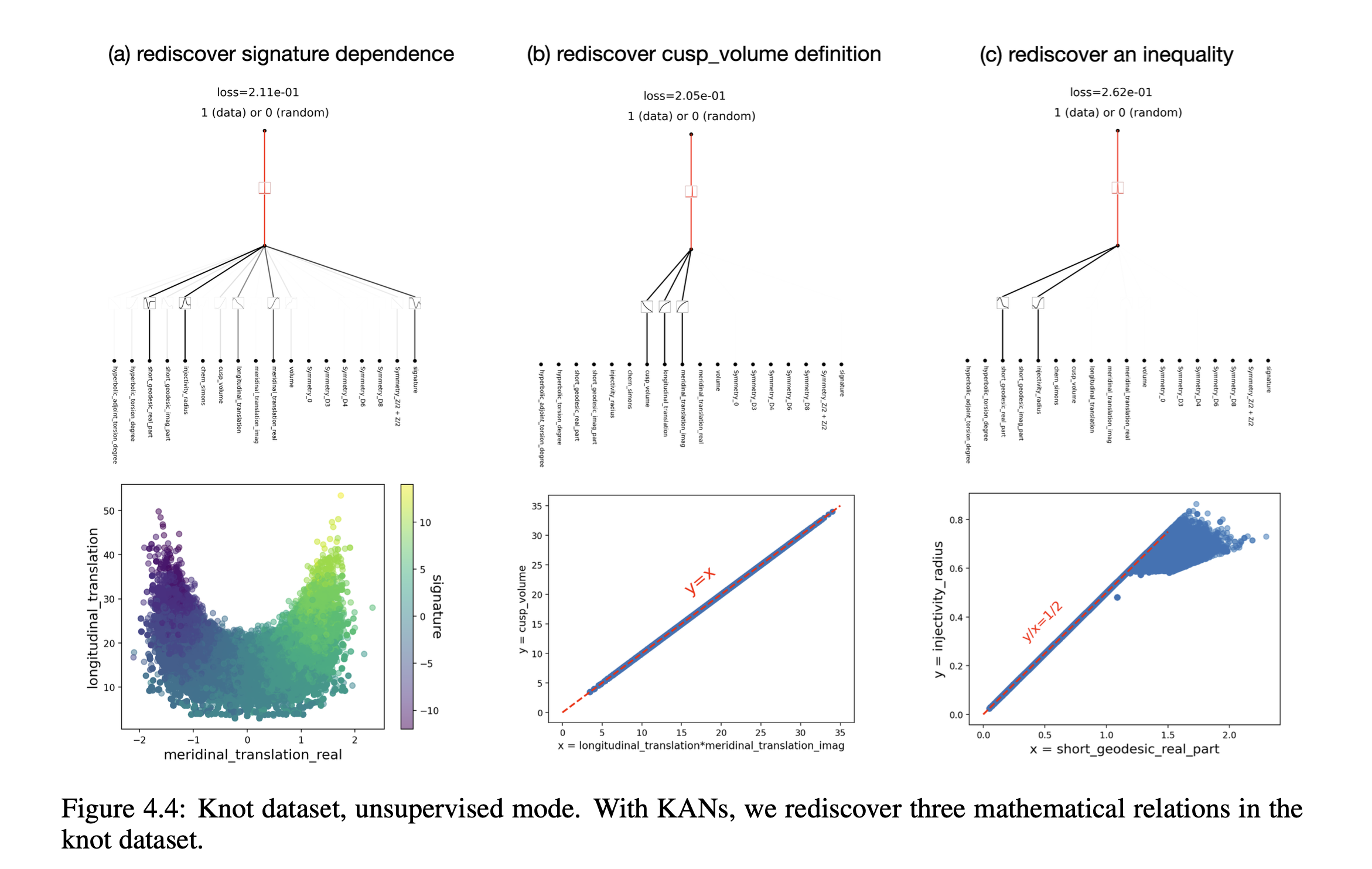
변수 내 변수간 새로운 수식 발견
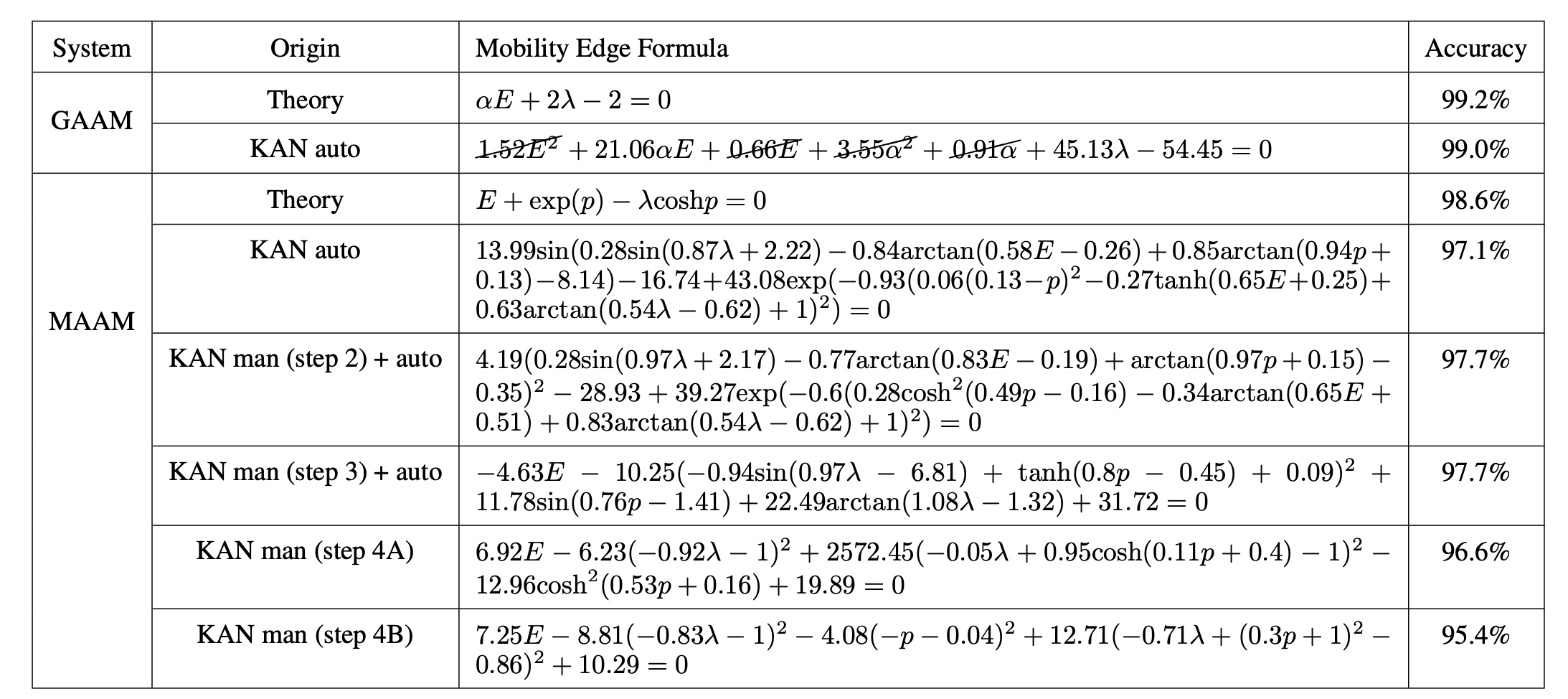
아직 비효율성이 큼 : Node 수가 같더라고 단순한 Multiplication에 비해 Spline은 작업량이 큼
참고한 논문리뷰 내용 정리 부분 참고 링크
Universal Approximation Theorem (UAT 정리)
벡터 \(x \in [0,1]^n\) 를 입력으로 하는 모든 Continuous한 함수 \(f: [0,1]^n \to \mathbb{R}\) 에 대해 항상 G 와 같은 Approximation이 Exist
\(N, a_j, y_j, \theta_j (1 \leq j \leq N)\) 가 존재
\[G(x) = \sum_{j=1}^{N} a_j \sigma \left( y_j^T (x + \theta_j) \right)\]여기서 F는 n 차원의 unit vector를 받아서 실수를 출력하는 function → 상당히 많은 함수가 여기에 속함
그 F를 G식으로 근사가 가능하다는 정리
\[|G(x) - f(x)| < \epsilon \quad \text{for all } x \in I_n.\]data distribution F를 찾는것은 불가능 → 따라서 data Training을 통해 G를 근사로 구함
이를 통해 어떠한 continous한 함수이던 2-Layer MLP로 표현가능
이와 같이 MLP가 수학적인 근거를 세움
Why has MLP been primarily used until now?
둘 다 강력한 approximation Theorem 을 기반으로 함
오늘날 MLP가 더 많이 사용되는 이유
- \(χ_q,ψ_{pq}\) 함수의 Pathological Behavior (c.f. MLP’s parameters)
- 수학적으로나 계산적으로 비정상적이거나 예측하기 어려운 행동을 보일 수 있음
그럼에도 KAT가 가질 수 있는 장점 (→ 연속적이고 미분 가능한 함수에 대해 동작한다면)
- (학습할) 함수의 Symbolic Representation 가능성 (c.f. MLP’s connectionism) → 여러 plain의 결합
- 그로 인한 Interpretability → 각 파라미터 해석 용이
How to make curve
가장 간단한 방법 (n-th) Bezier Curve
0부터 1까지 time stamp에서 B(t)를 표현 → t 시점의 곡선의 위치 B(t)는 n+1개의 제어점 \(P_i\) 의 위치를 해당 시점에서 그들의 영향력인 \(b_{i,n}(t)\) (→ n에의해 정해지는 값)로 weighted sum
단점
- Locality의 부재 → 특정 부분만 바꾸기 힘듬, 모든 점들이 영향을 미치기 때문
- 큰 n을 요하는 복잡한 곡선은 계산이 어려움 → 비용 증가
B-spline r(t)은 이를 개선한 Bezier Curve의 일반화 버전
전체 제어점의 개수(n+1)와 , r(t) 계산에 쓸 제어점의 개수 (k) 분리
n은 곡선의 Granularity를 담당 (→ 많을 수록 더 복잡한 함수 설계)
k는 곡선의 Continuity(Smoothness)를 담당
Solve
논문에서 Pathological Behavior 를 해결한 방법
MLP가 width를 늘리는데 한계가 있어 depth를 늘려 Generalization을 이룬 것 처럼,
폭과 넓이를 늘리는 Generalization 수행
모든 모델의 가정은 True distribution을 알 수 없기 때문에 dataset을 통해 이를 근사할 수 있음을 가정
위 KAN 모델은 배워야 할 Activation Functions(단변수 함수)들이 continous 하다고 가정
하지만 위 함수들이 얼마나 복잡해야하는지는 정해지지 않음 → 학습, 해석 불가
저자들은 [n, 2n+1, 1] 구조를 벗어나면 해결 가능하다고 함.
node와 function의 개수 규칙 확인
How to Learn Function ϕ
여러 plain들을 weighted sum 하는 것에 그림으로 나타남
Result
Deeper Layer를 쌓음으로써 ϕ가 Smooth 해졌다는 Theoretical한 보장은 없음
어느정도의 upperbound를 appendix C 에서 제공
empirical 하게 증명
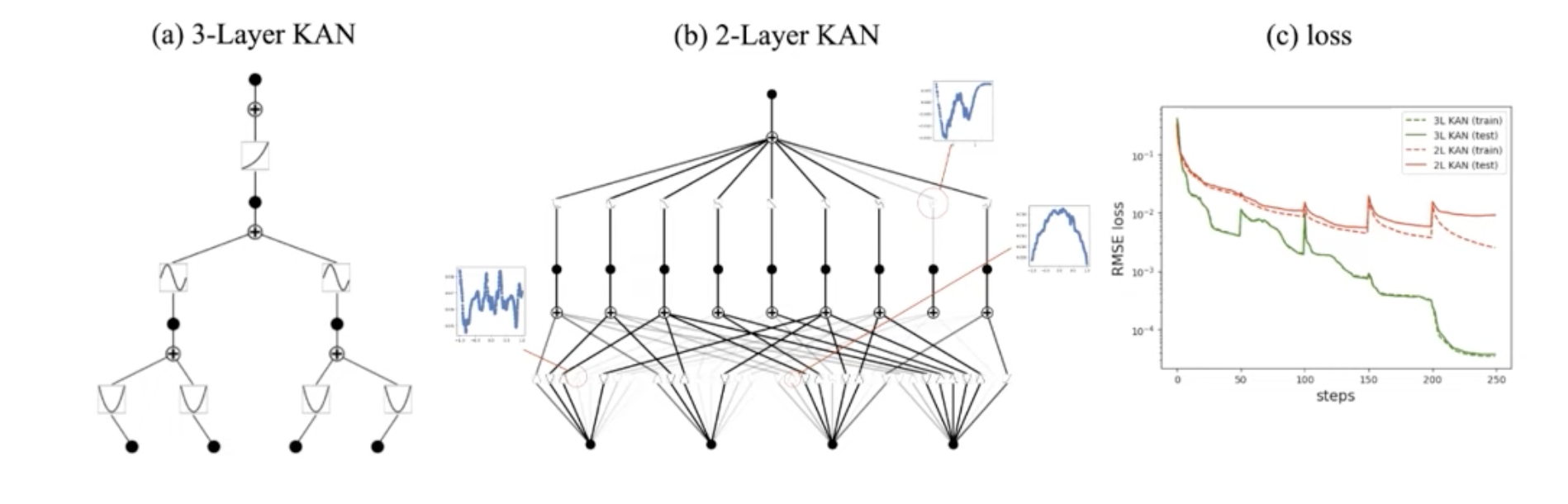
빨간색 : Original[4,9,1] loss
초록색 : KAN[4,2,1,1] loss
C Dependence on hyperparameters
We show the effects of hyperparamters on the f(x,y) = exp(sin(πx) + y2) case in Figure C.1. To get an interpretable graph, we want the number of active activation functions to be as small (ideally 3) as possible.
- (1) We need entropy penalty to reduce the number of active activation functions. Without entropy penalty, there are many duplicate functions.
- (2) Results can depend on random seeds. With some unlucky seed, the pruned network could be larger than needed.
- (3) The overall penalty strength λ effectively controls the sparsity.
- (4) The grid number G also has a subtle effect on interpretability. When G is too small, because each one of activation function is not very expressive, the network tends to use the ensembling strategy, making interpretation harder.
- (5) The piecewise polynomial order k only has a subtle effect on interpretability. However, it behaves a bit like the random seeds which do not display any visible pattern in this toy example.
Future Research
φ에 대한 수학적 최적화 방법론
- KAN은 Deeper/Wider Network가 φ의 Smoothness를 어느 정도 보장함을 증명함
- But, B-spline이 아닌 다른 방법으로 곡선 φ를 나타낼 수 있는 방법들에 대해 탐구해볼 필요가 있음 (Laguerre Polynomial, …)
최신 Architecture에 도입
- 오늘날 MLP는 그 자체로 사용되기 보단, Transformer와 같은 더 큰 Architecture의 Building Block임
- KAN을 효과적으로 도입하는 것을 넘어, 기존 Architecture와 다루고 있는 여러 특징들과 Framework들 (Ex. Scaling Laws, Transfer Learning, …)까지도 어떻게 확장할 것인가에 대해 탐구해볼 필요가 있음
Hardware적인 최적화 방법론
- GPU는 Matrix Multiplication에 엄청나게 최적화되어 있음
- 이러한 Modern Hardware에서의 KAN Efficiency를 높이기 위한 방법론들을 탐구해볼 필요가 있음