
[논문분석] Imagen Video: High Definition Video Generation with Diffusion Models
task를 나눠 quality를 높히자
[Home, Paper]
Author: Google Research, Brain Team
Introduction
최신 동향 + 신기한 점
Diffusion models have also shown promise for video generation (Ho et al., 2022b) at moderate resolution. Yang et al. (2022) showed autoregressive generation with a RNN-based model with conditional diffusion ob- servations. The concurrent work of Singer et al. (2022) also applied text-to-video modelling with diffusion models, but built on a pretrained text-to-image model. Harvey et al. (2022) generates videos up to 25 minutes in length with video diffusion models, however the domain is restricted.
확산 모델은 중간 해상도에서 비디오 생성에 대한 가능성도 보여주었습니다(Ho et al., 2022b). Yang 등(2022)은 조건부 확산 연산이 포함된 RNN 기반 모델을 사용하여 자동 회귀적 생성을 보여주었습니다. Singer 등(2022)의 동시 연구에서도 확산 모델과 함께 텍스트-비디오 모델링을 적용했지만, 사전 학습된 텍스트-이미지 모델을 기반으로 했습니다. (2022)는 비디오 확산 모델을 사용하여 최대 25분 길이의 비디오를 생성하지만 도메인이 제한되어 있습니다.
Imagen video
The model consists of a frozen T5 text encoder (Raffel et al., 2020), a base video diffusion model, and interleaved spatial and temporal super-resolution diffusion models.
다음 4가지 관점 집중 분석
- the simplicity and effectiveness of cascaded diffusion video models
- the effectiveness of frozen encoder text conditioning and classifier-free guidance
- effectiveness of the v-prediction parameterization and the effectiveness of progressive distillation of guided diffusion models
- qualitative controllability
- 계단식 확산 비디오 모델의 단순성과 효율성
- 프로즌 인코더 텍스트 컨디셔닝 및 분류기 없는 안내의 효율성
- v-예측 파라미터화의 효과와 유도 확산 모델의 점진적 증류 효과
- 질적 제어 가능성
이렇게 생성된 저해상도 비디오는 그 다음에 여러 Temporal Super-Resolution (TSR)과 Spatial Super-Resolution (SSR) 모델에 의해 업샘플링.
이 과정을 거치면서, 비디오는 최종적으로 1280×768 해상도의 128 프레임 비디오로 변환되며, 이는 초당 24프레임의 속도로 재생
이렇게 생성된 비디오는 총 5.3초의 고해상도 비디오가 됨
diffusion model setting
We use a continuous time version of the cosine noise schedule
we parameterize our models in terms of the v-parameterization (Salimans & Ho, 2022), rather than predicting ε or x directly; see Section 2.4.
We use these conditional diffusion models for spatial and temporal super-resolution in our pipeline of diffusion models
We use the discrete time ancestral sampler or the deterministic DDIM sampler
3D U-Net 사용
cascaded diffusion video models
Cascaded Diffusion Models for High Fidelity Image Generation
It consists of 7 sub-models which perform text-conditional video generation, spatial super-resolution, and tem- poral super-resolution.
각 단계마다 점진적으로 video의 품질을 향상.
품질 좋은 video를 한번에 생성해 내는 것이 아니라 순차적으로, “diffusion model” 처럼 task를 나눠서 수행.
이를 통해 각 하위 모델들을 비교적 단순하게 유지
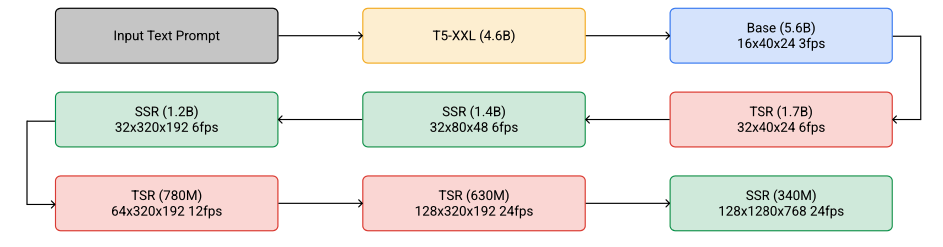
The cascaded sampling pipeline
Cascaded Diffusion Models can model very high dimensional problems while still keeping each sub-model relatively simple.
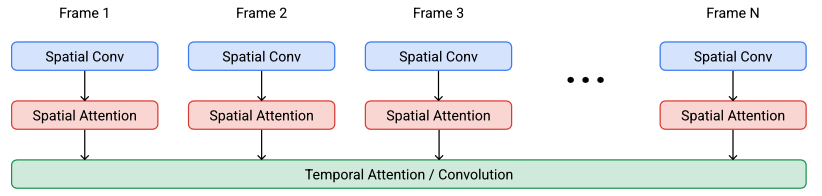
Video U-Net space-time separable block.
temporal Attention에서 모든 프레임을 같이 연산
각 프레임이 독립적으로 생성되는 것이 아닌 모든 프레임이 함께 생성된다는 것을 의미 → 각 프레임 간의 일관성이 유지되고 비디오 전체가 자연스럽게 보일 수 있음
the SSR models increase spatial resolution for all input frames, whereas the TSR models increase temporal resolution by filling in intermediate frames between input frames.
SSR : 프레임의 해상도(이미지 품질)를 높이는 역할
TSR : 프레임 사이에 중간 프레임을 채워 시간 해상도(프레임)를 높이는 역할
spatial upsampling before concatenation is performed using bilinear resizing, and temporal upsampling before concatenation is performed by repeating frames or by filling in blank frames.
the effectiveness of frozen encoder text conditioning
a frozen T5-XXL text encoder
T5-XXL은 텍스트 인코더의 한 종류로, 텍스트를 고차원 벡터 공간에 매핑하는 역할.
이 모델은 텍스트 간의 유사성 작업에 잘 작동하지만, 의미론적 검색 작업에는 그렇게 잘 작동하지 못함.
생성된 비디오와 텍스트 프롬프트 사이의 정렬에 중요 → encoder를 통해 생성된 벡터를 통해 정렬
Frozen : 모델 가중치가 고정되어있음을 나타냄
- T5-XXL 텍스트 인코더와 CLIP의 차이점
| T5-XXL | CLIP | |
|---|---|---|
| 목적과 활용 분야의 차이 | • 자연어 처리(NLP) 작업에 특화되어 있습니다. • 번역, 요약, 질의응답, 문법 교정 등 텍스트 기반의 작업에 활용됩니다. • 입력과 출력이 모두 텍스트입니다. |
• 멀티모달 학습을 위해 개발되었습니다. • 이미지와 텍스트 간의 관계를 학습하여 이미지 분류, 검색, 캡셔닝 등에 활용됩니다. • 이미지와 텍스트를 함께 처리합니다. |
| 구조적인 차이 | • 인코더-디코더 구조를 가집니다. • 전체적으로 트랜스포머 아키텍처를 활용하여 텍스트 생성 능력이 뛰어납니다. |
• 이중 인코더 구조를 가집니다. • 이미지 인코더와 텍스트 인코더가 각각 존재하며, 두 모달리티의 임베딩을 동일한 공간에 매핑합니다. |
| 학습 데이터의 차이 | • 주로 텍스트 데이터셋을 사용하여 사전 학습합니다. • 대규모의 웹 텍스트, 책, 위키피디아 등의 데이터를 활용합니다. |
• 이미지-텍스트 쌍 데이터셋을 사용합니다. • 웹에서 크롤링한 이미지와 그에 대한 캡션 또는 설명을 활용합니다. |
| 출력 결과의 차이 | • 텍스트 생성에 뛰어나며, 입력 텍스트에 대한 응답이나 변환된 텍스트를 출력합니다. | • 이미지와 텍스트의 유사도 점수를 계산하거나, 임베딩 벡터를 제공합니다. • 직접적인 텍스트 생성을 목표로 하지 않습니다. |
| 응용 분야의 차이 | • 자연어 이해와 생성이 필요한 모든 분야에 적용됩니다. • 챗봇, 문서 요약, 자동 번역 등. |
• 이미지와 텍스트를 연결하는 작업에 사용됩니다. • 이미지 검색, 이미지 분류, 제로샷 학습, 이미지 캡셔닝 등. |
- T5-XXL 텍스트 인코더는 거대한 트랜스포머 기반의 언어 모델로, 텍스트 입력과 텍스트 출력을 처리하며, 다양한 NLP 작업에 활용됩니다.
- CLIP의 텍스트 인코더는 이미지와 텍스트를 동일한 임베딩 공간에 매핑하기 위해 설계된 모델로, 멀티모달 작업에 특화되어 있습니다.
text conditioning 이 중요한 이유
text embedding은 text를 고차원 벡터로 변환하는 방법
텍스트 간의 유사성을 측정하거나 텍스트를 다른 형식으로 변환하는데 사용
Text prompt와 생성된 비디오 사이의 정렬을 돕습니다. 얼마나 잘 일치하는지 결정
Our base video model, which is the first model in the pipeline that generates data at the lowest frame count and spatial resolution, uses temporal attention to mix information across time.
The cascaded sampling pipeline
in base model
시간적 주의(Temporal Attention):
이 기법은 기본 모델에서 사용되며, 비디오의 장기적인 시간 종속성을 모델링하는 데 도움
시간적 주의는 각 시점에서 가장 중요한 정보를 선택하고, 이 정보를 기반으로 비디오의 각 프레임을 생성
이를 통해 모델은 시간에 따른 패턴과 변화를 학습하고, 이를 비디오 생성에 반영
long term temporal dependencies : 각 프레임 사이의 관계를 이해하고 모델링
maintain local temporal consistency during upsampling in the SSR and TSR
\[TemporalAttention(Q, K, V, T) = softmax({Q{T^TT\over ||T||}K^T\over\sqrt{d_k}})\]Temporal Attention for Language Models
in SSR and TSR
시간적 합성곱(Temporal Convolutions):
이 기법은 SSR 및 TSR 모델에서 사용되며, 업샘플링 과정에서 지역적인 시간 일관성을 유지하는 데 도움
시간적 합성곱은 연속된 프레임 간의 관계를 고려하여 각 프레임을 생성
이를 통해 모델은 업샘플링 과정에서도 비디오의 시간적 일관성을 유지
lowers memory and computation costs → 고차원 데이터이기에 더 중요 (CNN 계산이 더 빠름)
An Empirical Evaluation of Generic Convolutional and Recurrent…
초기 실험에서 저자들은 SSR과 TSR 모델에서 temporal convolution 대신 temporal attention을 사용할 때 상당한 개선을 찾지 못했음.
저자들은 모델에 대한 컨디셔닝 입력에 이미 상당한 양의 시간적 상관 관계가 존재하기 때문이라고 가정
본 논문의 모델은 또한 spatial attention과 spatial convolution을 사용
Base model과 처음 두 개의 SSR 모델에는 spatial convolution 외에도 spatial attention이 있음
이것이 샘플 충실도를 향상시키는 것으로 나타남.
그러나 더 높은 해상도로 이동함에 따라 fully convolutional 아키텍처로 전환하여 1280×768 해상도 데이터를 생성하기 위해 메모리 및 컴퓨팅 비용을 최소화
파이프라인에서 가장 높은 해상도의 SSR 모델은 학습 시 메모리 효율성을 위해 임의의 저해상도 spatial crop에 대해 학습된 fully convolutional model이며, 저자들은 샘플링 시 모델이 전체 해상도로 쉽게 일반화됨을 발견
For memory efficiency, our spatial and temporal super-resolution models use temporal convolutions instead of attention, and our models at the highest spatial resolution do not have spatial attention.
메모리 효율성을 위해 공간 및 시간 초해상도 모델은 attention 대신 temporal convolutions을 사용하며, 최고 공간 해상도 모델에는 spatial attention이 없음
V-prediction ()
-
V-prediction parameterization
V-prediction parameterization은 확산 모델의 학습 목적 함수 중 하나입니다. 확산 모델은 원본 이미지를 점차적으로 노이즈로 변환하는 과정을 역전파하여 이미지를 생성하는 방법입니다. V-prediction parameterization은 원본 이미지와 노이즈의 가중 평균을 목표로 하여, 확산 과정에서 발생할 수 있는 색상 이동을 줄이고 안정적인 학습을 가능하게 합니다¹². V-prediction parameterization은 다음과 같은 수식으로 정의됩니다³:
\[v_t = \sqrt{\frac{\alpha_t}{1-\alpha_t}} x_0 + \sqrt{\frac{1-\alpha_t}{\alpha_t}} \epsilon_t\]여기서 \(\mathbf{x}_0\)은 원본 이미지, \(\epsilon_t\)은 노이즈, \(\alpha_t\)는 확산 계수입니다. V-prediction parameterization은 eps-prediction parameterization과 비교하여 비디오 생성과 같은 시간적인 연속성이 중요한 문제에 더 적합합니다⁴. V-prediction parameterization을 사용한 확산 모델의 예시로는 Progressive Distillation for Fast Sampling of Diffusion Models와 Three Stable Diffusion Training Losses: x0, epsilon, and v-prediction이 있습니다.
시간에 대한 의존성 줄이기 → 각 시간 단계에서 독립적으로 작동 → 병렬처리 효율적인 계산
-
ε-prediction parameterization
# \(\hat{x}_θ(\mathbf{z}_t) = (\mathbf{z}_t − σ_tε_θ(\mathbf{z}_t))/α_t\)
train $ε_θ$ using a mean squared error in ε space with t sampled according to a cosine schedule
-
둘 차이
v-parameterization과 ε-parameterization은 모두 확산 기반 모델에서 중요한 역할을 하지만, 이들의 접근 방식과 초점에는 분명한 차이가 있습니다. 이들 두 방식은 확산 과정에서 노이즈를 다루는 방법과 예측하는 구조가 다르며, 각각의 특성에 따라 모델의 성능과 안정성에 영향을 미칩니다.
\(\epsilon\)-Parameterization
ε-parameterization은 기존 확산 모델에서 널리 사용되는 방식으로, 모델이 각 단계에서 원본 데이터 \(x\)에 추가된 노이즈 \(\epsilon\)를 직접 예측하는 구조입니다. 이 방식은 주로 다음과 같은 형태로 표현됩니다:
여기서 \(x_t\)는 시간 \(t\)에서의 노이즈가 추가된 데이터를 의미하고, 모델은 이 \(x_t\)로부터 원래 이미지로 노이즈를 추가하기 전의 상태를 예측하려고 시도합니다. 이 방식은 모델이 직접적으로 노이즈를 예측하고, 이 노이즈를 제거하는 방향으로 이미지를 점차 복원해 나가는 방식입니다.
v-Parameterization
반면, v-parameterization은 노이즈를 다루는 또 다른 접근 방식으로, 노이즈와 데이터 간의 관계를 다르게 표현합니다. v-parameterization에서는 \(v_t\)라는 새로운 변수를 사용하며, 이는 다음과 같이 정의됩니다:
이 방식은 노이즈 \(\epsilon\)와 데이터 \(x\) 사이의 선형 조합을 사용하여 새로운 표현 \(v_t\)를 생성합니다. 이 표현은 시간에 따라 조절되는 계수 \(\alpha_t\)와 \(\sigma_t\)에 의해 조절됩니다. v-parameterization의 주요 이점은 고해상도 이미지에서 발생할 수 있는 색상 이동(color shifting)과 같은 아티팩트를 줄이면서도, 모델이 더 안정적으로 학습할 수 있도록 돕는 것입니다.
주요 차이점
- 노이즈와 데이터의 처리:
ε-parameterization은 노이즈를 직접적으로 예측하는 반면,v-parameterization은 노이즈와 데이터의 조합을 통해 새로운 변수를 생성하여 이를 예측합니다. - 수치적 안정성:
v-parameterization은 특히 고해상도에서 수치적 안정성을 제공하는 반면,ε-parameterization은 일반적인 확산 과정에서 사용됩니다. -
응용 분야의 적합성: 각각의 파라미터화 방식은 다른 유형의 문제와 환경에 더 적합할 수 있으며, 특히
v-parameterization은 고해상도 및 색상 중요도가 높은 응용 분야에서 유리할 수 있습니다.각 방식은 특정 상황과 요구에 따라 선택되어야 하며, 모델의 성능과 안정성을 최대화하는 데 기여합니다.
v - parameterization은 diffusion process 전반에 걸쳐 수치적 안정성에 특히 유용하여 모델의 progressive distillation을 가능하게 한다. 파이프라인에서 높은 해상도로 작동하는 모델의 경우
v - parameterization가 고해상도 diffusion model에서 발생하는 color shifting 아티팩트를 피하고 동영상 생성 시 ϵ prediction을 사용할 때 나타나는 일시적인 color shifting을 피한다. v - parameterization를 사용하면 샘플 품질 지표를 더 빠르게 수렴할 수 있다는 이점도 있다.
이는 샘플링 단계를 줄이면서도 모델의 안정성을 유지하는 데 중요한 역할을 합니다. 이러한 parameterization에서, 우리는 잠재 변수의 속도를 추정하려고 시도합니다. 이 속도는 신호 대 잡음비(SNR) 단계에 대한 상대적인 속도로 표현됩니다
Progressive Distillation for Fast Sampling of Diffusion Models
progressive distillation
- 식 전개
So, s a weighted reconstruction loss in x-space와 동일함
\(w(λ_t) = \mathrm{exp}(λ_t)\) , \(λ_t = \mathrm{log}[α^2_t /σ^2_t]\) (log signal-to-noise ratio)
하지만, \(α^2_t /σ^2_t\) 의 경우 destillation이 진행됨에 따라 점점 낮은 log signal-to-noise ratio를 가지게 됨 : 즉 노이즈화 되는 과정을 나타냄
하지만, 단계가 줄어들면 문제가 발생
\(\hat{\mathbf{x}}_θ(\mathbf{z}_t)= {1 \over \alpha_t}(\mathbf{z}_t−σ_t\hat{ε}_θ(\mathbf{z}_t))\) 다음 식에서 \(\alpha_t \to 0\) 가 되면서, \(\epsilon\) 의 작은 변화가 x 에 더 크게 작용
초기 실수의 영향이 더 중요해짐
극단적으로 갔을 때 ε-prediction 은 x-prediction를 나타낼 수 없게됨 (위의 식 등호 성립 안함)
따라서 기존 ε-prediction 과 다른 방법 제안
- Predicting x directly.
- Predicting both x and ε, via separate output channels \(\{\tilde{\mathbf{x}}_θ(\mathbf{z}_t),\tilde{ε}_θ(\mathbf{z}_t)\}\) of the neural net-work, and then merging the predictions via \(\hat{\mathbf{x}} = σ^2_t \tilde{\mathbf{x}}(\mathbf{z}_t ) + α_t (\mathbf{z}_t − σ_t \tilde{ε}(\mathbf{z}_t ))\), thus smoothly interpolating between predicting x directly and predicting via ε.
- Predicting \(v ≡ αtε − σtx, which gives xˆ = αtzt − σtvˆθ(zt)\), as we show in Appendix D.
원래의 모델을 훈련시키는 데는 잘 작동하지만, 증류(distillation)에는 적합하지 않은 표준 사양에 대해 설명하고 있습니다. 원래의 확산 모델을 훈련시키고 증류를 시작할 때, 모델은 다양한 신호 대 잡음비에서 평가되지만, 증류가 진행됨에 따라 점점 더 낮은 신호 대 잡음비에서 평가됩니다. 신호 대 잡음비가 0으로 갈수록, 신경망 출력의 작은 변화의 효과가 x-공간에서의 암시된 예측에 점점 더 증폭됩니다.(잡음이 더 많아짐) 이는 많은 단계를 거칠 때는 크게 문제가 되지 않지만, 샘플링 단계 수를 줄이면서 점점 더 중요해집니다. 결국, 증류를 단일 샘플링 단계까지 모두 내려가면, 모델에 대한 입력은 순수한 잡음만이며, 이는 신호 대 잡음비가 0, 즉 αt = 0, σt = 1에 해당합니다. 이 극단적인 상황에서, ϵ-예측과 x-예측 사이의 연결이 완전히 끊어집니다. 관찰된 데이터 zt = 는 더 이상 x에 대한 정보를 제공하지 않으며, 예측 ˆθ(zt)는 더 이상 암시적으로 x를 예측하지 않습니다. 우리의 재구성 손실 (방정식 9)을 살펴보면, 가중치 함수 w(λt)는 이 신호 대 잡음비에서 재구성 손실에 대해 0의 가중치를 부여합니다.
CONDITIONING AUGMENTATION
노이즈를 추가해서 변화에 강해지도록 학습
병렬 훈련은 여러 모델을 동시에 훈련하는 방법으로, 훈련 시간을 크게 단축시키고 모델의 성능을 향상시키는 데 도움이 됩니다. 이는 각 모델이 독립적으로 훈련되며, 각 모델의 훈련이 서로에게 영향을 주지 않기 때문입니다
이 문장에서는 병렬 훈련이 캐스케이드 내의 다양한 모델 간의 ‘도메인 갭(domain gap)’에 대한 민감도를 줄이는 데 도움이 된다고 설명하고 있습니다1. 도메인 갭은 한 단계의 출력과 다음 단계의 훈련 입력 사이의 차이를 의미합니다1. 이 차이는 모델의 성능을 저하시킬 수 있으며, 이를 줄이는 것이 중요합니다1.
샘플링 시간에는 고정된 신호 대 노이즈 비율(signal-to-noise ratio)(예: 3 또는 5)을 사용합니다.
VIDEO-IMAGE JOINT TRAINING
개별 이미지를 단일 프레임 비디오로 취급
We achieve this by packing individual independent images into a sequence of the same length as a video, and bypass the temporal convolution residual blocks by masking out their computation path. : 비디오의 시퀀스 길이와 동일하게 각각의 독립적인 이미지를 패킹 , residual block과 convolution 계산 진행
Masking 사용 더 다양성 확보
image와 video의 공동 학습이 품질 향상에 도움이 됨 → 기존에 잘 돌아가는 image model을 활용하는게 좋다.
image에서 video로 transfer가 일어나면서 자연스럽게 video dynamic을 생성
CLASSIFIER FREE GUIDANCE
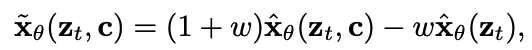
LARGE GUIDANCE WEIGHTS
large guidance weights는 모델이 훈련 데이터에 과적합 되었음을 나타낼 수 있으며 입력데이터의 작은 변화가 출력에 큰 변화를 일으키게 되어 불안정할 수 있다.
기존 방법
이를 막기위해 clipping 방법을 사용해 np.clip(x, -1, 1) 입력의 범위를 제한
np.clip(x, -s, s) / s → dynamic thresholding 방법을 이용한 clipping
논문에서 제안된 방법
oscillating guidance
w oscillate between a high and a low guidance weight at each alternating sampling step
일정 범위 내의 초기 단계에서는 high weight를 사용하다가, 이후 각 sampling step 마다 교대로 weight를 high와 low로 번갈아 적용
dynamic한 learning rate를 생각해봤을 때 초기에 강한 가중치로 빠르게 수렴 이후 점점 값을 낮춰가며 global한 optimal minima로 수렴하는 것과 유사
local minina인 mode를 탈출하는데도 도움이 됨
하지만, 80×48 spatial resolution 에서는 더 안좋은 결과를 보이기에 기본 모델과 처음 두 SR 모델에만 oscillating guidance를 적용
이유를 생각해보면 step이 진행될 수록 더 고품질의 정밀한 데이터가 출력되는데 큰 oscillating guidance가 더 안좋게 작용될 수 있다고 생각됨
PROGRESSIVE DISTILLATION WITH GUIDANCE AND STOCHASTIC SAMPLERS
우리가 봤던 논문
증류 개념이 처음 나온 논문
Progressive Distillation for Fast Sampling of Diffusion Models
distillation : an N-step DDIM sampler is distilled to a new model with N/2-steps.
반으로 줄여나가는 step
기존 diffusion model의 단점인 sampling 속도 문제를 해결
한번에 계산할 수 있는 식으로 만들어주는 과정
본 논문에서 사용한 모델 : two-stage distillation approach to distill a DDIM sampler (Song et al., 2020) with classifier- free guidance
sampling 단계를 축소 → 이를 통해 각 step당 8개의 sampling으로 축소됨
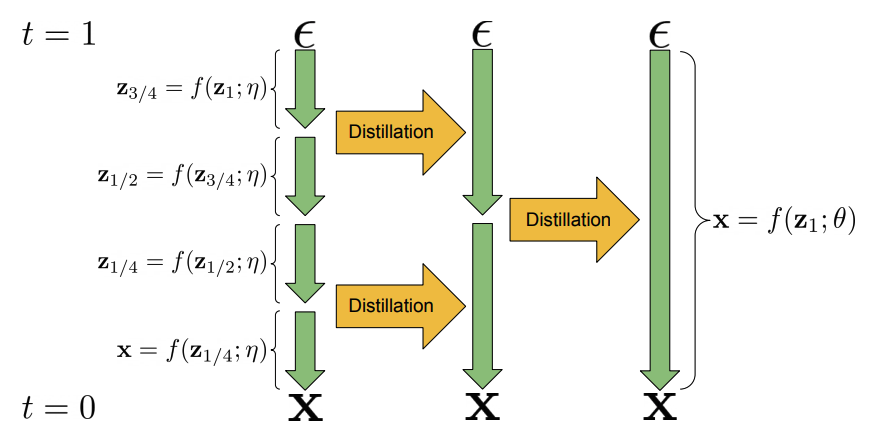
step을 반으로 줄인 모델을(학생) 기존 모델(교사)에 복사본으로 초기화 → 기존 모델(교사)의 DDIM sampling 2단계가 step을 반으로 줄인 모델(학생)의 1단계와 같도록 학습.

\(t', t''\) : (1번째 교사 step, 2번째 교사 step)
\(\tilde{x}\) : target , 2개의 step을 하나로 줄였을 때 결과, 마지막 학생의 예측값
blog - Progressive Distillation for Fast Sampling of Diffusion Models
하지만 distillation 방법이 probability flow ODE에 대해 좋은 디퓨전 모델의 성능을 transfer하기 좋은 방법이긴 하지만, 결국 디퓨전 모델의 생성에 의존해야한다는 점 때문에 학습 속도가 현저히 느려지게 된다는 bottleneck에서 벗어날 수 없다.
위와 같은 progressive distillation에서 좀더 발전되어 consistency distillation을 사용한 논문이 consistency models
EXPERIMENTS
Dataset
We train our models on a combination of an internal dataset consisting of 14 million video-text pairs and 60 million image-text pairs, and the publicly available LAION-400M image-text dataset.
평가지표
FID
FVD
CLIP Score
1) scaling up the number of parameters in our model
2) changing the parameterization of our model
3) distilling our models so that they are fast to sample from.
좋은점
3D 구조의 이해
애니메이션 스타일 소화
scaling up the parameter count of the video U-Net → 좋은 결과 (기존 논문과 반대되는 결과)
v-parameterization이 더 좋더라
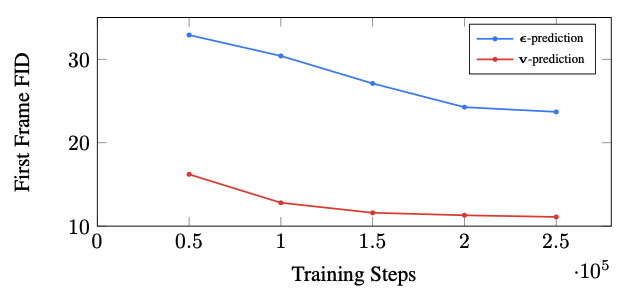
clip 점수
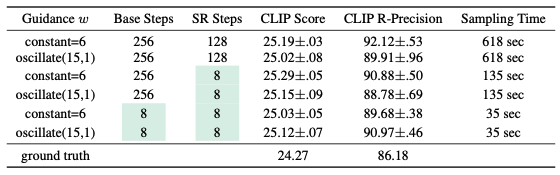
문제 한계
노골적이고 폭력적인 콘텐츠의 상당 부분을 걸러낼 수 있는 것으로 나타났지만, 여전히 사회적 편견과 고정관념이 존재하여 이를 감지하고 필터링하기는 어렵습니다.
Imagen Video와 고정된 T5-XXL 텍스트 인코더는 문제가 있는 데이터에 대해 학습되었습니다