
[논문분석] IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Image generaion에서 다양한 Condition을 위한 Finetuning 방법 [Page, Paper] , Code
Abstract
Recent years have witnessed the strong power of large text-to-image diffusion models for the impressive generative capability to create high-fidelity images. However, it is very tricky to generate desired images using only text prompt as it often involves complex prompt engineering. An alternative to text prompt is image prompt, as the saying goes: “an image is worth a thousand words”. Although existing methods of direct fine-tuning from pretrained models are effective, they require large computing resources and are not compatible with other base models, text prompt, and structural controls. In this paper, we present IP-Adapter, an effective and lightweight adapter to achieve image prompt capability for the pretrained text-to-image diffusion models. The key design of our IP-Adapter is decoupled cross-attention mechanism that separates cross-attention layers for text features and image features. Despite the simplicity of our method, an IP-Adapter with only 22M parameters can achieve comparable or even better performance to a fully fine-tuned image prompt model. As we freeze the pretrained diffusion model, the proposed IP-Adapter can be generalized not only to other custom models fine-tuned from the same base model, but also to controllable generation using existing controllable tools. With the benefit of the decoupled cross-attention strategy, the image prompt can also work well with the text prompt to achieve multimodal image generation. The project page is available at https://ip-adapter.github.io.
최근 몇 년 동안 대규모 텍스트-이미지 확산 모델의 강력한 성능으로 고충실도 이미지를 생성할 수 있는 인상적인 생성 기능을 목격했습니다. 그러나 텍스트 프롬프트만 사용하여 원하는 이미지를 생성하는 것은 복잡한 프롬프트 엔지니어링을 수반하는 경우가 많기 때문에 매우 까다롭습니다. 텍스트 프롬프트의 대안으로 이미지 프롬프트가 있습니다: “이미지는 천 마디 말의 가치가 있다”는 말이 있습니다. 사전 학습된 모델에서 직접 미세 조정하는 기존의 방법은 효과적이지만 대규모 컴퓨팅 리소스가 필요하고 다른 기본 모델, 텍스트 프롬프트 및 구조적 제어와 호환되지 않습니다. 이 백서에서는 사전 학습된 텍스트-이미지 확산 모델을 위한 이미지 프롬프트 기능을 달성하기 위한 효과적이고 가벼운 어댑터인 IP-Adapter를 소개합니다. IP-Adapter의 핵심 설계는 텍스트 특징과 이미지 특징에 대한 교차 주의 레이어를 분리하는 분리형 교차 주의 메커니즘입니다. 이 방식은 매우 단순하지만, 2200만 개의 파라미터만 있는 IP-Adapter는 완전히 미세 조정된 이미지 프롬프트 모델과 비슷하거나 더 나은 성능을 달성할 수 있습니다. 사전 학습된 확산 모델을 고정하기 때문에 제안된 IP-Adapter는 동일한 기본 모델에서 미세 조정된 다른 맞춤형 모델뿐만 아니라 기존의 제어 가능한 도구를 사용하여 제어 가능한 생성에도 일반화할 수 있습니다. 분리된 교차 주의 전략의 이점을 통해 이미지 프롬프트는 텍스트 프롬프트와 함께 작동하여 멀티모달 이미지 생성을 달성할 수도 있습니다. 프로젝트 페이지는 다음 주소에서 확인할 수 있습니다.
Introduction
기존 모델 한계
text의 경우 좋은 prompt를 만들기 어려움. complex prompt engineering 필요.
또한 복잡한 장면이나 개념을 표현하는 데 어려움
-
이미지 임베딩에 직접 텍스트 조건부 확산 모델을 미세 조정하여 이미지 프롬프트 기능을 구현
첫째, 텍스트를 사용하여 이미지를 생성하는 원래의 기능이 제거되며, 이러한 미세 조정에는 많은 컴퓨팅 리소스가 필요한 경우가 많습니다.
둘째, 미세 조정된 모델은 일반적으로 이미지 프롬프트 기능을 동일한 텍스트-이미지 기본 모델에서 파생된 다른 사용자 지정 모델로 직접 전송할 수 없기 때문에 재사용할 수 없습니다.
새로운 모델은 컨트롤넷[9]과 같은 기존의 구조적 제어 도구와 호환되지 않는 경우가 많아 다운스트림 애플리케이션에 상당한 문제를 야기합니다. 미세 조정의 단점 때문입니다,
-
텍스트 인코더를 이미지 인코더로 대체하는 방법
처음에는 이미지 프롬프트만 지원되므로 사용자가 텍스트와 이미지 프롬프트를 동시에 사용하여 이미지를 만들 수 없습니다. 또한 이미지 인코더를 미세 조정하는 것만으로는 이미지 품질을 보장하기에 충분하지 않으며 일반화 문제가 발생할 수 있습니다.
본 논문은 원본 텍스트-이미지 모델을 수정하지 않고도 이미지 프롬프트 기능을 구현
기존 연구 과정
- CLIP 이미지 인코더에서 추출한 이미지 특징을 학습 가능한 네트워크에 의해 새로운 특징에 매핑
- 텍스트 특징과 연결
- 원본 텍스트 피처를 대체하여 병합된 피처는 확산 모델의 UNet에 공급되어 이미지 생성을 안내
→ 이러한 어댑터는 이미지 프롬프트를 사용할 수 있지만, 생성된 이미지는 프롬프트 이미지에 부분적으로만 충실함. 미세 조정된 이미지 프롬프트 모델보다 더 나쁠 때가 많음
분석
저자는 앞서 언급한 방법의 주요 문제점은 텍스트-이미지 diffusion model의 cross attention 모듈에 있다고 주장
cross attention layer의 key와 value의 projection weights는 텍스트 특징을 적용하도록 학습
결과적으로 이미지 특징과 텍스트 특징을 cross attention layer에 병합하면 이미지 특징과 텍스트 특징의 정렬만 이루어지지만, 이는 일부 이미지 고유의 정보를 놓칠 가능성이 있고 결국에는 결국에는 참조 이미지로 coarse-grained controllable generation(예: 이미지 스타일)만 이루어짐
따라서 본 논문에 IP-Adapter는 텍스트 기능과 이미지 기능에 대해 분리된 교차 주의 메커니즘을 채택
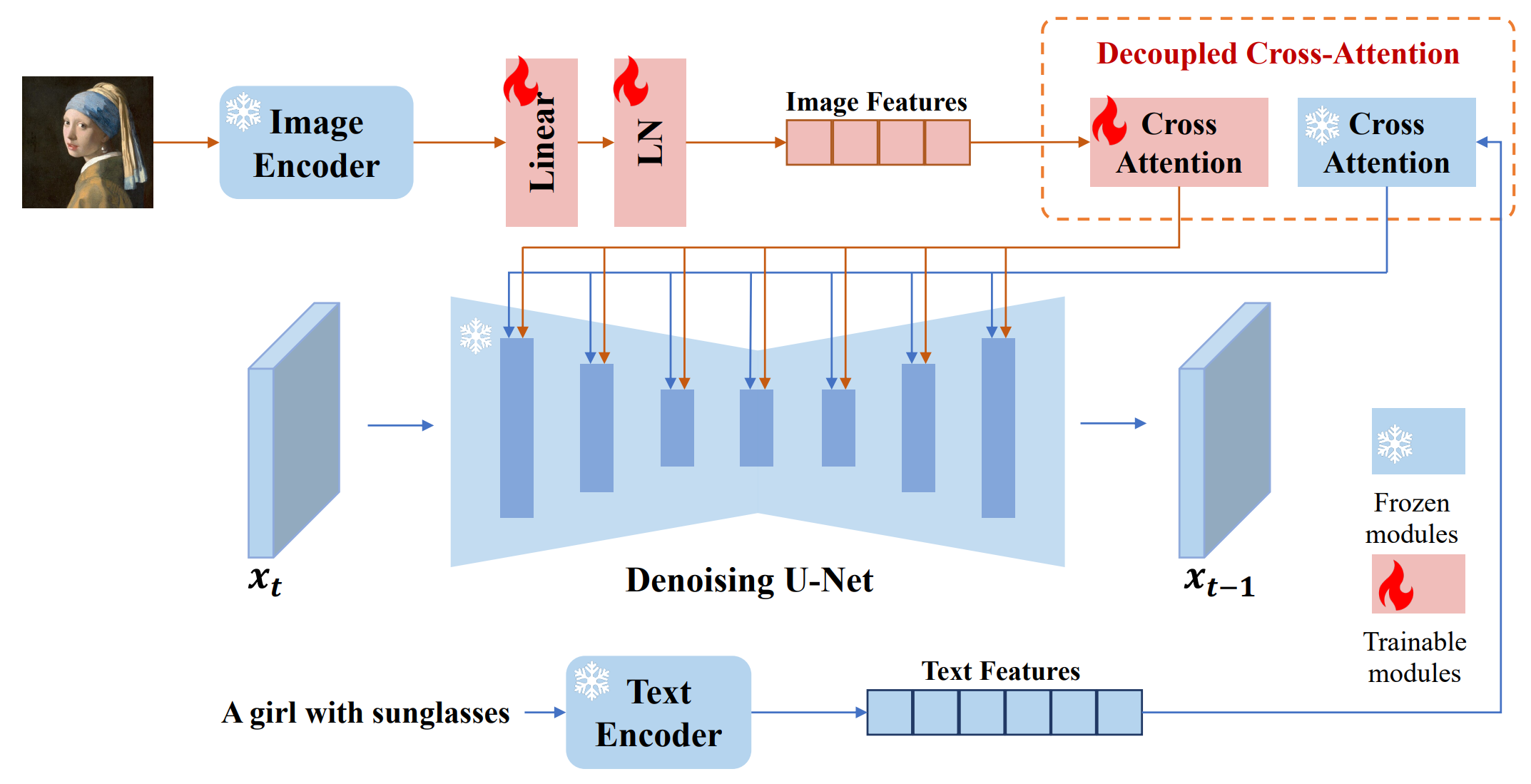
Method
Prelimiaries
sampling
\[L_{\text{simple}} = \mathbb{E}_{x_0, \epsilon \sim \mathcal{N}(0, \mathbf{I}), c, t} \left\| \epsilon - \epsilon_\theta (x_t, c, t) \right\|^2\]classifier free guidence
\[\hat{\epsilon}_\theta(x_t, c, t) = w \epsilon_\theta(x_t, c, t) + (1 - w) \epsilon_\theta(x_t, t),\]Image Prompt Adapter
새로 추가된 교차 주의 레이어에 이미지 특징을 임베드하는 분리된 교차 주의 전략을 제시
이미지 프롬프트에서 이미지 특징을 추출하는 이미지 인코더와 이미지 특징을 사전 학습된 텍스트-이미지 확산 모델에 임베드하기 위한 분리된 교차 주의가 적용된 모듈의 두 부분으로 구성
Image Encoder
사전 학습된 CLIP 이미지 인코더 모델을 사용하여 이미지 프롬프트에서 이미지 특징을 추출
이미지 캡션과 잘 정렬되고 이미지의 풍부한 콘텐츠와 스타일을 표현할 수 있는 CLIP 이미지 인코더의 글로벌 이미지 임베딩을 활용
글로벌 이미지 임베딩을 효과적으로 분해하기 위해 훈련 가능한 작은 projection네트워크를 사용하여 이미지 임베딩을 길이 N(이 연구에서는 N = 4 사용)의 특징 시퀀스로 투영하고 이미지 특징의 차원은 사전 훈련된 확산 모델에서 텍스트 특징의 차원과 동일
Decoupled Cross-Attention
\[Z' = \text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{QK^\top}{\sqrt{d}}\right)V,\]두 개 condition 가져와서
\[Z'' = \text{Attention}(Q, K', V') = \text{Softmax}\left(\frac{QK'^\top}{\sqrt{d}}\right)V',\]더함
\[Z^{\text{new}} = \text{Softmax}\left(\frac{Q K^\top}{\sqrt{d}}\right) V + \text{Softmax}\left(\frac{Q (K')^\top}{\sqrt{d}}\right) V',\]Training and Inference
\[L_{\text{simple}} = \mathbb{E}_{x_0, \epsilon, c_t, c_i, t} \left\| \epsilon - \epsilon_\theta (x_t, c_t, c_i, t) \right\|^2 \] \[\hat{\epsilon}_\theta(x_t, c_t, c_i, t) = w \epsilon_\theta(x_t, c_t, c_i, t) + (1 - w) \epsilon_\theta(x_t, c_t, t) \] \[Z^{\text{new}} = \text{Attention}(Q, K, V) + \lambda \cdot \text{Attention}(Q, K', V')\]Experiment
Training Data
LAION-2B and COYO-700M
Implementation Details
SD v\(1.5^2\) and OpenCLIP ViT-H/1

이후 코드를 활용해 Scene Graph를 받아 Image 생성하는 프로젝트 진행 예정