[논문분석] Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation
Wav2vec + animatediff - Talking Face generation [Code, Paper]
Abstract
The field of portrait image animation, driven by speech audio input, has experienced significant advancements in the generation of realistic and dynamic portraits. This research delves into the complexities of synchronizing facial movements and creating visually appealing, temporally consistent animations within the framework of diffusion-based methodologies. Moving away from traditional paradigms that rely on parametric models for intermediate facial representations, our innovative approach embraces the end-to-end diffusion paradigm and introduces a hierarchical audio-driven visual synthesis module to enhance the precision of alignment between audio inputs and visual outputs, encompassing lip, expression, and pose motion. Our proposed network architecture seamlessly integrates diffusion-based generative models, a UNet-based denoiser, temporal alignment techniques, and a reference network. The proposed hierarchical audio-driven visual synthesis offers adaptive control over expression and pose diversity, enabling more effective personalization tailored to different identities. Through a comprehensive evaluation that incorporates both qualitative and quantitative analyses, our approach demonstrates obvious enhancements in image and video quality, lip synchronization precision, and motion diversity. Further visualization and access to the source code can be found at: https://fudan-generative-vision.github.io/hallo.
end-to-end diffusion paradigm + hierarchical audio-driven visual synthesis
visual outputs, encompassing lip, expression, and pose motion 등을 제어
1. Introduction
- 오디오 입력에 따른 입술 움직임, 표정, 머리 포즈의 조율
- 시각적으로 매력적이고 시간적 일관성을 유지하는 고품질 애니메이션
audio and visual features를 연결짓기 위해 cross-attention mechanisms 도입
adaptive weighting으로 합침
2. Related Work
2.1 Diffusion-Based Video Generation
생략
2.2 Facial Representation Learning
identity-related 된 얼굴 생김새와 non-identity-related인 lip 움직임을 분리
Explicit methods 종종 얼굴의 랜드마크를 사용 → 입, 눈, 코, 턱선과 같은 중요한 영역을 localization으로 표현 → expressive capabilities and the precision of reconstructions의 한계
implicit methods → 잠재공간 활용 → accurate and effective disentanglement 해결해야함
2.3 Portrait Image Animation
LipSyncExpert : 얼굴 동작에 큰 기여 모델 → diffusion 모델로 확장 다양한 모델이 나옴
VASA-1 and EMO → AniTalker
3. Methodology
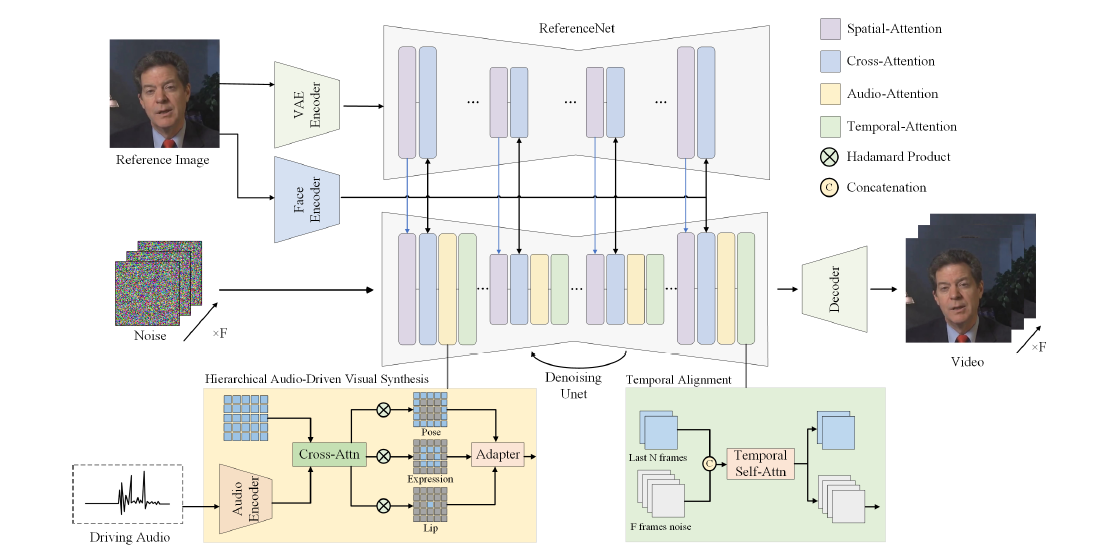
Figure 2: The overview of the proposed pipeline. Specifically, we integrates a reference image containing a portrait with corresponding audio input to drive portrait animation. Optional visual synthesis weights can be used to balance lip, expression, and pose weights. ReferenceNet encodes global visual texture information for consistent and controllable character animation. Face and audio encoders generate high-fidelity portrait identity features and encode audio as motion information respectively. The module of hierarchical audio-driven visual synthesis establishes relationships between audio and visual components (lips, expression, pose), with a UNet denoiser used in the diffusion process.
3.2. Hierarchical Audio-Driven Visual Synthesis.
t as \(z^{(s)}_ t\)로 표현
Face Embedding
기존에는 clip을 사용해 .visual feature encoding 사용
본 논문에서는 자체적 face encoder 사용
Audio Embedding
wav2vec 사용
12 layers of the wav2vec network를 연결 (audio embeddings를 모두 concatenation)
풍부한 semantic information를 위해
Sequential audio data에 대한 맥락적인 영향을 고려, S frames에 대한 5초만큼의 audio segment를 추출
wav2vec embedding에 추가적으로 3개의 simple linear layers를 거치도록 하면, 다음과 같은 S frames에 대한 audio feature set을 얻음 → 실제 코드에서 자세하게 확인
Hierarchical Audio-Visual Cross Attention
lips, expressions, poses를 따로 연산 → feature maps → adaptive weighting을 통해 fuse
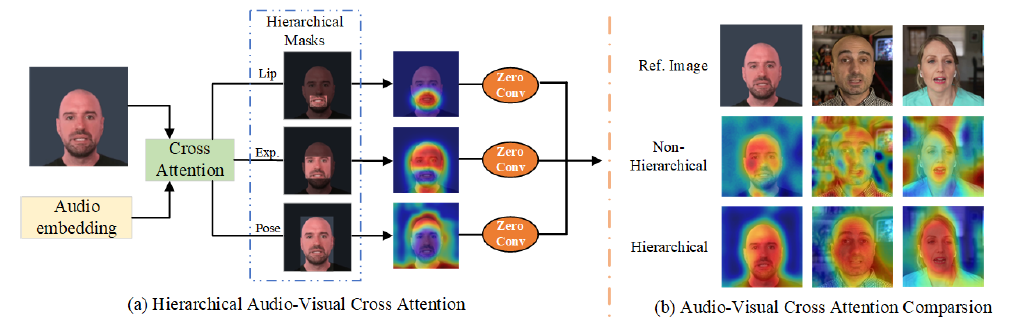
MediaPipe toolbox를 통해 lip과 expression 각각에 대한 landmark set 구함
\[M_{\text{lip}}, M_{\text{exp}}, M_{\text{pose}} \in \{0, 1\}^{H_z \times W_z}\] \[Y_{\text{lip}}, Y_{\text{exp}} \in \{0, 1\}^{H_z \times W_z}\]bounding box masks
lip, expression 그리고 pose에 대응되는 region의 mask
\[\begin{align} M_{\text{lip}} &= Y_{\text{lip}}, \\ M_{\text{exp}} &= (1 - M_{\text{lip}}) ⊙ Y_{\text{exp}}, \\ M_{\text{pose}} &= 1 - M_{\text{exp}}, \end{align}\]⊙ Hadamard product
cross-attention mechanism
image의 t-step latent representation는 Q, audiomotion motion feature는 K와 V
\[o_t^{(s)} = \text{CrossAttn}(z_t^{(s)}, c_{\text{audio}}^{(s)})\]resize three masks to different scale to match the latent shape
\[\begin{align} b_t^{(s)} &= o_t^{(s)} \circ M_{\text{pose}}, \\ f_t^{(s)} &= o_t^{(s)} \circ M_{\text{exp}}, \\ l_t^{(s)} &= o_t^{(s)} \circ M_{\text{lip}}. \end{align}\]output을 mask와 element-wise multiplication
3.3 Network Architecture
Diffusion Backbone
Stable Diffusion 1.5
Text conditioning에서 audio motion conditioning으로 교체
ReferenceNet
Backbone Stable Dffusion과 동일한 구조
특정 layers에서 나타나는 feature maps는 backbone의 feature maps와 유사한 성질을 보임
이러한 spatial resolution이 같고 잠재적으로 유사한 의미를 담은 feature를 backbone에 통합해주는 것은 portraits와 backgrounds의 시각적 texture information과 같은 퀄리티 증진에 기여
모델이 학습되는 동안, video clip의 첫 번째 frame이 reference image로 활용
Temporal Alignment
2개 base image를 noise에 concat해서 input으로 구성
이 manipulation은 video frames의 temporal sequence elements를 process하는 다수의 self-attention blocks를 통해 진행
3.4. Training and Inference
- reference image and target video frame pairs를 통해 individual video frames 생성 14 frames are extracted for input data facial image encoder와 함께 VAE encoder및 decoder 파라미터는 고정 facial video clip에서 임의의 프레임을 참조 프레임으로 선택 + 대상 이미지와 동일한 비디오에서 다른 프레임을 선택
- reference images, input audio, and target video data 를 활용 video sequences 생성 모델의 시간적 일관성과 부드러움을 개선하기 위해 모션 모듈이 도입 → aminatediff에서 제안 비디오 클립의 한 프레임이 무작위로 참조 이미지로 선택 비디오 클립의 마지막 2프레임을 다음 클립의 초기 k 프레임으로 활용
시각적으로 일관된 긴 동영상을 제작하기 위해 이전 동영상의 마지막 2프레임을 활용
(1) In the first training phase, individual video frames are generated by utilizing reference image and target video frame pairs. The parameters of VAE encoder and decoder, along with the facial image encoder, are fixed, while allowing the weights of the spatial cross-attention modules of ReferenceNet and denoising UNet to be optimized to improve single-frame generation capability. Video clips containing 14 frames are extracted for input data, with a random frame from the facial video clip chosen as the reference frame and another frame from the same video as the target image. (2) In the second training phase, video sequences are trained using reference images, input audio, and target video data. The spatial modules of ReferenceNet and denoising UNet remain static, focusing on enhancing video sequence generation capability. This phase predominantly focuses on training hierarchical audio-visual cross-attention to establish the relationship between audio as motion guidance and the visual information of lip, expression, and pose. Additionally, motion modules are introduced to improve model temporal coherence and smoothness, initialized with pre-existing weights from AnimateDiff [11]. One frame from a video clip is randomly selected as the reference image during this phase. Inference. During the inference stage, the network takes a single reference image and driving audio as input, producing a video sequence that animates the reference image based on the corresponding audio. To produce visually consistent long videos, we utilize the last 2 frames of the previous video clip as the initial k frames of the next clip, enabling incremental inference for video clip generation.
(1) 첫 번째 훈련 단계에서는 참조 이미지와 목표 비디오 프레임 쌍을 활용하여 개별 비디오 프레임을 생성합니다. 얼굴 이미지 인코더와 함께 VAE 인코더 및 디코더의 파라미터는 고정되어 있으며, 단일 프레임 생성 기능을 향상시키기 위해 참조넷의 공간 교차 주의 모듈과 노이즈 제거 UNet의 가중치를 최적화할 수 있습니다. 입력 데이터로 14개의 프레임을 포함하는 비디오 클립을 추출하고, 얼굴 비디오 클립에서 임의의 프레임을 참조 프레임으로 선택하고 대상 이미지와 동일한 비디오에서 다른 프레임을 선택합니다. (2) 두 번째 훈련 단계에서는 참조 이미지, 입력 오디오 및 대상 비디오 데이터를 사용하여 비디오 시퀀스를 훈련합니다. 참조넷의 공간 모듈과 노이즈 제거 UNet은 정적으로 유지되며, 비디오 시퀀스 생성 기능을 향상시키는 데 중점을 둡니다. 이 단계에서는 주로 모션 가이드로서의 오디오와 입술, 표정, 포즈 등의 시각 정보 간의 관계를 설정하기 위한 계층적 오디오-시각 교차 주의 훈련에 중점을 둡니다. 또한 모델의 시간적 일관성과 부드러움을 개선하기 위해 모션 모듈이 도입되며, AnimateDiff [11]의 기존 가중치로 초기화됩니다. 이 단계에서는 비디오 클립의 한 프레임이 무작위로 참조 이미지로 선택됩니다. 추론. 추론 단계에서 네트워크는 하나의 기준 이미지와 구동 오디오를 입력으로 받아 해당 오디오를 기반으로 기준 이미지를 애니메이션하는 비디오 시퀀스를 생성합니다. 시각적으로 일관된 긴 비디오를 생성하기 위해 이전 비디오 클립의 마지막 2프레임을 다음 클립의 초기 k 프레임으로 활용하여 비디오 클립 생성을 위한 증분 추론을 가능하게 합니다.
4. Experiment
4.1. Experimental Setups
Implementation Details
30,000개의 training step로 구성되었으며, 배치 크기는 4, 비디오 크기는 512 × 512로 설정
Animatediff : 0.05 dropout
Datasets
HDTF (190 clips, 8.42 hours) and additional Internet-sourced data (2019 clips, 155.90 hours).
data cleaning 거침 (excluding videos with scene changes, significant camera movements, excessive facial motion, and fully side-facing shots)
inference : 15 frames at a resolution of 512 × 512.
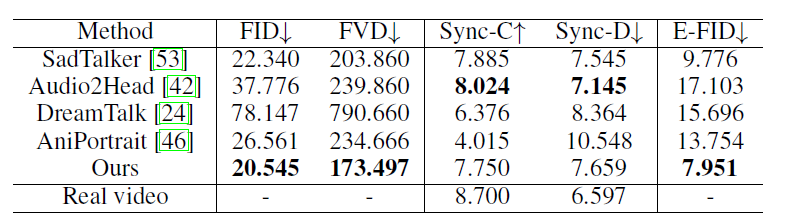
Comparison on HDTF Dataset
Comparison on CelebV Dataset
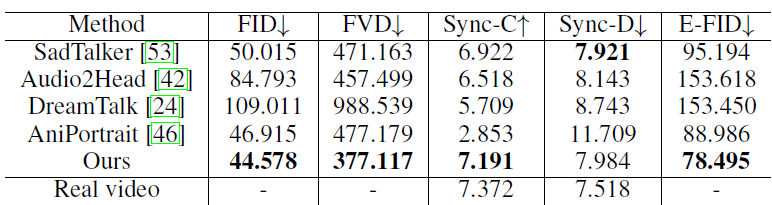
Comparison on the Proposed “Wild” Dataset
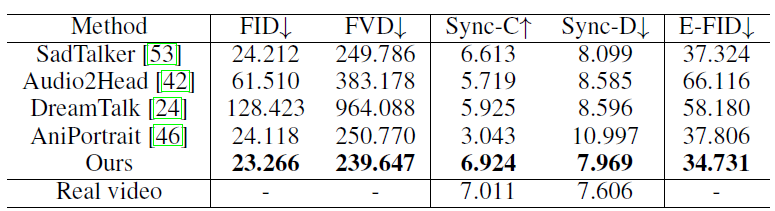
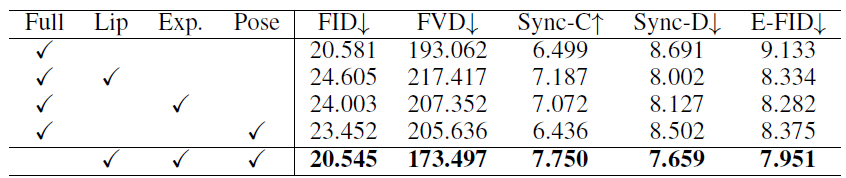
Ablation study