[논문분석] GraphMAE: Self-Supervised Masked Graph Autoencoders
Self-supervised learning을 통해 graph autoencoders 성능 개선
[Code, Paper]
ABSTRACT
Self-supervised learning (SSL) has been extensively explored in recent years. Particularly, generative SSL has seen emerging success in natural language processing and other AI fields, such as the wide adoption of BERT and GPT. Despite this, contrastive learning which heavily relies on structural data augmentation and complicated training strategies has been the dominant approach in graph SSL, while the progress of generative SSL on graphs, especially graph autoencoders (GAEs), has thus far not reached the potential as promised in other fields. In this paper, we identify and examine the issues that negatively impact the development of GAEs, including their reconstruction objective, training robustness, and error metric. We present a masked graph autoencoder GraphMAE1 that mitigates these issues for generative self-supervised graph pretraining. Instead of reconstructing graph structures, we propose to focus on feature reconstruction with both a masking strategy and scaled cosine error that benefit the robust training of GraphMAE. We conduct extensive experiments on 21 public datasets for three different graph learning tasks. The results manifest that GraphMAE—a simple graph autoencoder with careful designs—can consistently generate outperformance over both contrastive and generative state-of-the-art baselines. This study provides an understanding of graph autoencoders and demonstrates the potential of generative self-supervised pre-training on graphs.
Self-supervised learning (SSL) 많이 씀
지금까지 Graph SSL은 contrastive learning이 일반적,
구조적 data augmentation, 복잡한 training strategies에 의존
새로운 도전으로(GAE) graph autoencoders → 아직 성능 안나옴
GraphMAE로 GAE 성능 개선
reconstructing graph structures(그래프 구조 재구성) 대신 a masking strategy and scaled cosine error 사용(마스크, 코사인 에러)
Negative sampling : 생성하는 계산 복잡도와 효율적인 계산을 위한 별도의 방법 필요
Data Augmentation : 그래프를 생성하는 방법론에 따른 랜덤성
→ 실제로 생성된 Sample graph 들이 positive와 negative의 역할을 할 수 있는가 에 대한 의문
Architecture : Constrastive method의 early-stage에서 불안정한 학습
Introduction

GAE의 문제
- the structure information may be over-emphasized
- 이웃 간 topological closeness(위상적 밀접도) 증가를 위해 link reconstruction을 활용
- 따라서 기존 GAE는 일반적으로 링크 예측과 노드 클러스터링에는 우수, 노드 및 그래프 분류에는 낮은 성능
- feature reconstruction without corruption may not be robust
- feature reconstruction을 사용하는 GAE들은 여전히 기본적인 아키텍처(vanilla architecture)를 사용하여 trivial solutions을 학습할 위험이 있습
- Trivial solution은 기계 학습에서 모델이 의미 있는 학습을 하지 않고도 손쉽게 최소화할 수 있는 손실 함수의 해
- Vanilla는 아이스크림의 바닐라 맛에서 유래한 용어로, 기계 학습에서 가장 기본적이고 단순한 형태의 모델 아키텍처를 의미 복잡한 기법이나 개선된 구조 없이 기본적인 인코더와 디코더로만 구성된 GAE를 사용한다는 것을 의미
- the mean square error (MSE) can be sensitive and unstable
- 기존의 feature reconstruction GAE들은 추가적인 조치 없이 MSE를 손실 함수로 사용.
- MSE는 feature vector norms의 크기 변화와 curse of dimensionality로 인해 오토인코더 학습의 불안정성을 초래
- the decoder architectures are of little expressiveness
- 대부분의 GAE는 다층 퍼셉트론(MLP)을 디코더로 사용
- 언어 모델에서는 풍부한 의미를 담은 원-핫 벡터를 대상, 그래프에서는 정보량이 적은 특징 벡터를 대상 → 차이
- 따라서 단순한 디코더인 MLP는 인코더의 표현과 디코더의 목표 사이의 격차를 효과적으로 메우지 못할 수 있음
GraphMAE
- Masked feature reconstruction
- 기존 GAE가 그래프의 구조 재구성에 초점을 맞추는 것과 달리, GraphMAE는 마스킹된 노드의 피처를 재구성하는 데 집중
- 이는 컴퓨터 비전과 자연어 처리 분야에서 효과가 입증된 기법으로, 적절한 오류 설계를 통해 GAE의 성능을 크게 향상
- Scaled cosine error
- 기존 GAE는 주로 평균 제곱 오차(MSE)를 사용 → GraphMAE는 코사인 오류를 적용하여 노드 피처의 크기가 다양할 때도 효과적으로 학습
- 재구성 과정에서 쉬운 샘플과 어려운 샘플 간의 불균형을 해결하기 위해 스케일드 코사인 오류를 도입
- Re-mask decoding
- 인코더의 출력 중 마스크된 노드의 임베딩을 디코더에 전달하기 전에 다시 마스킹하는 전략을 사용
- 이전 GAE들이 주로 다층 퍼셉트론(MLP)을 디코더로 사용한 것과 달리, GraphMAE는 더 표현력 있는 그래프 신경망(GNN)을 디코더로 활용
Related work
self supervised methods은 contrastive 와 generative domains 으로 나눌 수 있음
Contrastive Self-Supervised Graph Learning
- Negative Sampling:
- 균일성을 추구하기 위해 부정 샘플링은 대부분의 대조적 방법에서 필수적
- 생성하는 계산 복잡도와 효율적인 계산을 위한 별도의 방법 필요
- 아키텍처(Architectures):
- 대조적 방법은 초기 학습 단계에서 불안정할 수 있으므로, 아키텍처 제약이 이러한 문제를 해결하는 데 중요
- 데이터 증강(Data Augmentation):
- 고품질의 유용한 데이터 증강은 대조적 학습의 성공에 핵심적인 역할
- 특징 기반 증강: 부분 마스킹, 셔플링 등을 포함
- 근접성 기반 증강: 확산, 변형 등을 사용
- 그래프 샘플링 기반 증강: 랜덤 워크, 균등 샘플링, 에고 네트워크 등을 포함
Generative Self-Supervised Graph Learning
Generative self-supervised learning은 입력 데이터의 누락된 부분을 복원하는 것을 목표
오토리그레시브(autoregressive)와 오토인코딩(autoencoding) 두 가지로 분류
Graph autoregressive models
결합 확률 분포를 조건부 확률의 곱으로 분해 (GraphRNN과 GCPN 등이 대표적인 예)
GPT-GNN은 그래프 생성을 학습 목표로 활용한 최근 시도입니다. 그러나 대부분의 그래프는 내재적인 순서가 없기 때문에 오토리그레시브 방법은 그래프에 적합하지 않음
Graph autoencoder (GAEs)
주어진 컨텍스트로부터 입력을 재구성, 디코딩 순서를 강제하지 않음
초기 연구로 GAE와 VGAE는 2-레이어 GCN을 인코더로 사용 → 링크 예측을 위해 내적(dot-product)을 사용
이후의 GAEs는 구조 재구성이나 구조와 특징 재구성의 조합을 목표 (MGAE, GALA, GATE)
그러나 마스킹 없이 구조나 특징을 재구성하는 기존 GAEs는 노드 및 그래프 분류 벤치마크에서 성능이 만족스럽지 않음
Attribute-Masking
- 그래프에서 일부 노드 또는 노드의 특징을 선택적으로 마스킹
- 마스킹된 그래프를 모델의 입력으로 사용
- 모델은 마스킹되지 않은 정보와 그래프 구조를 활용하여 마스킹된 특징을 예측하도록 학습
이러한 방법들은 최신의 대조적(self-contrastive) 학습 방법들에 비해 성능이 뒤처짐
하지만 아직 성능이 떨어짐
기존 그래프 오토인코더(GAE)의 결함 → MSE, 디코더 표현력 부족
노드 특징이 다양해서 처리하기 힘듬
단순 마스킹은 고차원의 정보를 이해하기 힘듬
| 측면 | 속성 마스킹(Attribute-Masking) | GraphMAE |
|---|---|---|
| 손실 함수 | 평균 제곱 오차(MSE) 사용 | 스케일드 코사인 오류(Scaled Cosine Error) 사용 |
| 디코더 구조 | MLP와 같은 단순한 디코더 사용 | 더 표현력 있는 GNN 디코더 사용 |
| 마스킹 전략 | 단순한 마스킹 및 재구성 | 재마스킹 디코딩으로 정보 누설 방지 |
| 모델의 견고성 | 입력 손상에 취약할 수 있음 | 노드 특징의 다양성과 노이즈에 견고함 |
| 성능 | 대조적 학습 방법에 비해 성능이 낮음 | 대조적 학습 방법과 동등 또는 우수한 성능 |
| 기존 GAE의 결함 해결 여부 | 일부만 해결 또는 미해결 | 주요 결함들을 식별하고 개선 |
THE GraphMAE Approach
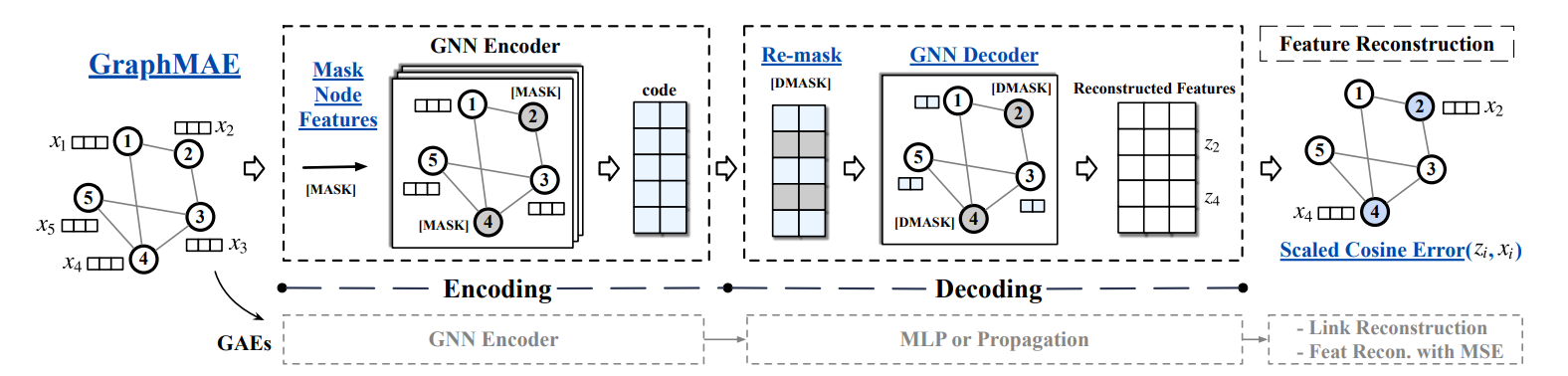
Figure 2: Illustration of GraphMAE and the comparison with GAE. We underline the key operations in GraphMAE. During pretraining, GraphMAE first masks input node features with a mask token [MASK]. The corrupted graph is encoded into code by a GNN encoder. In the decoding, GraphMAE re-masks the code of selected nodes with another token [DMASK], and then employs a GNN, e.g., GAT, GIN, as the decoder. The output of the decoder is used to reconstruct input node features of masked nodes, with the scaled cosine error as the criterion. Previous GAEs usually use a single-layer MLP or Laplacian matrix in the decoding and focus more on restoring graph structure.
The GAE Problem and GraphMAE
\[\mathcal{G} = (\mathcal{}V, 𝑨,𝑿)\]| V is the node set, 𝑁 = | V | is the number of nodes, \(𝑨 ∈ \{0, 1\}^{𝑁 ×𝑁}\) is the adjacency matrix, and \(𝑿 ∈ \mathbb{R}^{𝑁 ×𝑑}\) is the input node feature matrix |
H는 encoder 결과, G는 decoder 결과
기존 autoencoders 모델은 classification tasks, is relatively insignificant
The Design of GraphMAE
Q1: Feature reconstruction as the objective
GAE는 𝑨의 구조 또는 특징 𝑿 또는 둘 다의 재구성을 목표로 함
고전 GAS는 링크 예측과 그래프 클러스터링 작업에 초점 → 네트워크 임베딩에서 일반적으로 사용되는 목표인 𝑨의 재구성을 선택
최근에는 특징과 구조를 모두 재구성하는 복합적인 목표를 채택 → 아직 bad
훈련된 GNN distilled로부터 추출한 간단한 MLP가 노드 분류에서 고급 GNN과 비슷하게 작동
이러한 작업에서 feature에 따라서 GraphMAE가 분류에서 우수한 성능을 달성할 수 있도록 하기 위해 특징 재구성을 훈련 목표로 채택
structural proximity에 대한 explicit prediction은 GraphMAE의 the downstream classification tasks에 아무런 기여도 못함
Q2: Masked feature reconstruction
코드의 차원 크기(code dimension size)는 **잠재 표현의 차원 수를 의미
코드의 차원 크기가 입력의 차원 크기보다 클 경우, 오토인코더는 다음과 같은 문제점이 발생
“identity function” : 입력을 그대로 출력으로 복사, 코드의 차원이 입력보다 클 경우, 모델은 입력을 압축할 필요 없이 그대로 전달
so, 코드의 차원 크기를 입력보다 작게 설정하여 모델이 입력을 압축하고 중요한 정보만 보존하도록 유도
CV에서는 이미지 입력이 일반적으로 고차원적이기 때문에 상대적으로 심각한 문제가 안됨
하지만 그래프에서는 노드 특징 차원 크기가 일반적으로 매우 작기 때문에 강력한 특징 지향 GAE를 훈련하는 것이 매우 어렵습니다.
입력 데이터를 일부러 손상시키는 노이즈 제거 자동 인코더[41]는 the trivial solution을 없애기 위한 자연스러운 옵션
노드 \(\tilde{\mathcal{V}} ⊂ \mathcal{V}\) 의 하위 집합을 샘플링 → 각 피처를 마스크 토큰[MASK]으로 마스킹
학습 가능한 벡터 \(𝒙[𝑀 ] ∈ \mathbb{R} ^𝑑\) 로 각 피처를 마스킹
\[\tilde{x}_i = \begin{cases} x_{[M]}, & v_i \in \tilde{\mathcal{V}} \\ x_i, & v_i \notin \tilde{\mathcal{V}} \end{cases}\]GraphMAE의 목적 : 부분적으로 관측된 노드 신호 $\tilde𝑿$와 입력 인접 행렬 𝑨가 주어졌을 때 \(\mathcal{\tilde{V}}\)에서 노드의 마스크된 특징을 재구성하는 것
마스크된 노드를 얻기 위해 교체 없이 균일한 무작위 샘플링 전략을 적용
GNN에서 각 노드는 이웃 노드에 의존하여 자신의 특징을 향상 and 복원
균일한 분포를 가진 무작위 샘플링은 잠재적인 편향성을 방지하는 데 도움이 됨
BERT는 “마스크된” 단어를 항상 실제 [MASK] 토큰으로 대체하는 것이 아니라 작은 확률(예: 15% 이하)로 변경하지 않고 그대로 두거나 다른 임의의 토큰으로 대체
실험 결과, ‘변경하지 않고 그대로 두기’ 전략은 실제로 GraphMAE의 학습에 해를 끼치는 반면, ‘무작위 대체’ 방식은 더 높은 품질의 표현을 형성하는 데 도움이 됨
Q3: GNN decoder with re-mask decoding
GNN 디코더는 노드 자체가 아닌 노드 집합을 기반으로 한 노드의 입력 특징을 복구
그래프에서 디코더는 상대적으로 정보가 적은 다차원 노드 특징을 재구성
기존 GAE는 신경 디코더를 사용하지 않거나 표현력이 낮은 단순한 MLP를 사용해 디코딩하기 때문에 잠재 코드 𝑯가 입력 특징과 거의 동일
GraphMAE는 보다 표현력이 뛰어난 단일 계층 GNN을 디코더로 사용 → 결과적으로 인코더가 높은 수준의 잠재 코드를 학습하는 데 도움이 됨
\[\tilde{h}_i = \begin{cases} h_{[M]}, & v_i \in \tilde{\mathcal{V}} \\ h_i, & v_i \notin \tilde{\mathcal{V}}\end{cases}\]- \(\tilde{h}_i\)는 remasked된 코드 벡터를 의미
- \(h_{[M]}\)는 마스킹된 노드에 대해 사용되는 디코더 마스크 벡터
- \(v_i \in \tilde{\mathcal{V}}\)는 노드 vi가 마스킹된 노드들의 집합 \(\tilde{V}\)에 포함된 경우
- \({h}_i\) 는 마스킹되지 않은 노드의 원래 임베딩 벡터
GNN 디코더가 인접한 마스킹되지 않은 노드의 정보를 이용하여 마스킹된 노드의 피처를 재구성
Q4: Scaled cosine error as the criterion
기존 MSE 문제
- 민감성(Sensitivity): MSE는 벡터의 크기와 차원 수에 매우 민감, 특정 피처 차원의 극단값은 MSE 손실을 과적합 가능성이 있음
- 선택성 부족(Low Selectivity): MSE는 쉬운 샘플과 어려운 샘플을 구분하는 선택적 능력이 부족하여, 어려운 샘플에 충분히 집중하지 못함
확장된 cos error(Scaled Cosine Error, SCE) 제안
- 민감성 해결: 코사인 오차는 벡터의 크기나 차원 수의 영향을 받지 않도록 L2 정규화를 통해 벡터를 단위 구(sphere)에 매핑
- 학습 안정성: 이로 인해 학습 안정성이 향상
- \(\mathcal{L}_{SCE}\): Scaled Cosine Error (SCE) 손실 함수
-
Ṽ : 마스킹된 노드 집합 Ṽ의 크기 - Ṽ: 마스킹된 노드들의 집합
- vi: 그래프의 각 노드 i
- xi: 원본 특징 벡터 (노드 vi의 원본 특징)
- zi: 복원된 특징 벡터 (노드 vi의 복원된 특징)
- \(x_i^Tz_i\): 원본 특징 벡터 xi와 복원된 특징 벡터 zi의 내적
- \(‖x_i‖\): 원본 특징 벡터 xi의 L2 노름
- \(‖z_i‖\): 복원된 특징 벡터 zi의 L2 노름
- \(\gamma\): 스케일링 팩터, SCE의 선택성을 조정하는 매개변수 (\(\gamma\) ≥ 1)
Training and Inference
- 입력 그래프가 주어지면 특정 비율의 노드를 무작위로 선택하고 해당 노드의 특징을 [MASK] 토큰으로 대체
- 부분적으로 마스킹된 이 그래프를 인코더에 공급하여 인코딩된 노드 표현을 생성
- 디코딩하는 동안 이전에 선택한 노드를 다시 마스킹하여 해당 노드의 특징을 [DMASK] 토큰으로 대체
- 디코더를 remask된 그래프에 적용하여 제안된 스케일 코사인 오차를 사용하여 원래 노드 피처를 재구성
다운스트림 애플리케이션의 경우, 인코더는 추론 단계에서 마스킹 없이 입력 그래프에 적용
생성된 노드 임베딩은 노드 분류, 그래프 분류 등 다양한 그래프 학습 작업에 사용
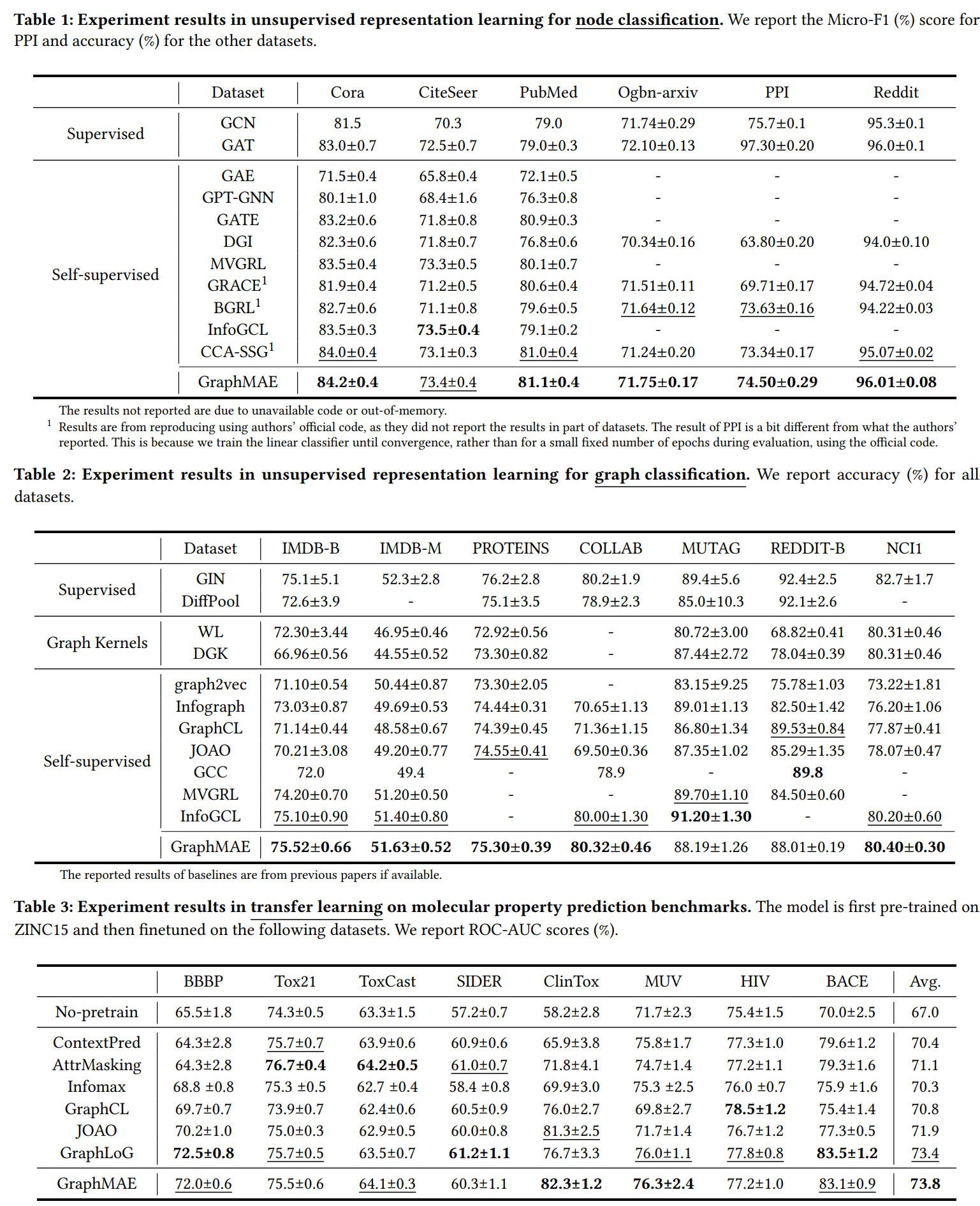
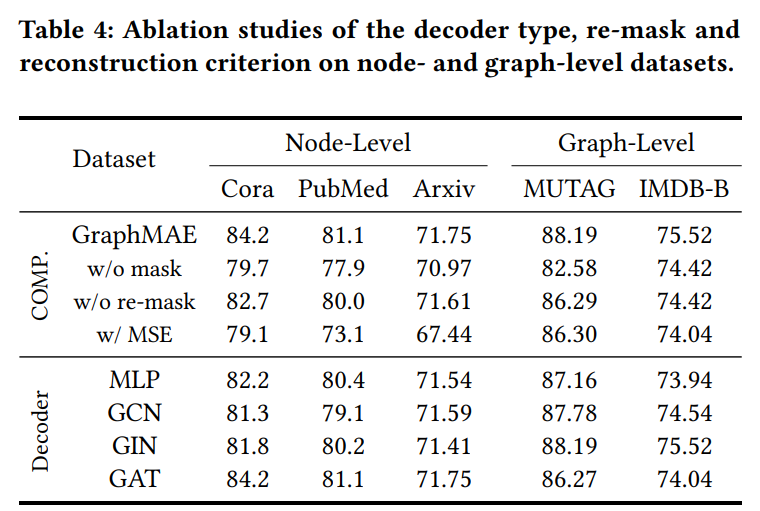
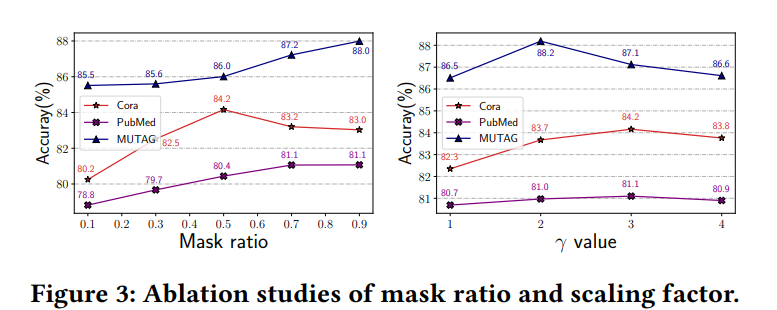
EXPERIMENTS