[논문분석] Gentron : Delving Deep into Diffusion Transformers for Image and Video Generation
U-Net 대신 transformer를 사용하는 DiT를 발전 시킨 모델 [Page , Paper]
Shoufa Chen, Mengmeng Xu, Jiawei Ren
1. Abstract
In this study, we explore Transformer-based diffusion models for image and video generation. Despite the domi- nance of Transformer architectures in various fields due to their flexibility and scalability, the visual generative domain primarily utilizes CNN-based U-Net architectures, particu- larly in diffusion-based models. We introduce GenTron, a family of Generative models employing Transformer-based diffusion, to address this gap. Our initial step was to adapt Diffusion Transformers (DiTs) from class to text condition- ing, a process involving thorough empirical exploration of the conditioning mechanism. We then scale GenTron from approximately 900M to over 3B parameters, observing significant improvements in visual quality. Furthermore, we extend GenTron to text-to-video generation, incorporating novel motion-free guidance to enhance video quality. In human evaluations against SDXL, GenTron achieves a 51.1% win rate in visual quality (with a 19.8% draw rate), and a 42.3% win rate in text alignment (with a 42.9% draw rate). GenTron also excels in the T2I-CompBench, under- scoring its strengths in compositional generation. We be- lieve this work will provide meaningful insights and serve as a valuable reference for future research. The website of GenTron is available1.
U-Net 대신 transformer를 사용하는 DiT를 발전 시킨 모델
2. Introduction
트랜스포머를 사용한 확산 모델
- 미리 정의된 하나의 클래스 임베딩 대신 오픈 월드의 자유 형식 텍스트 캡션에서 파생된 언어 임베딩을 활용함 → 제한된 class 한계 극복
- 트랜스포머 블록의 수와 숨겨진 차원 크기라는 두 가지 차원으로 GenTron을 확장 → parameter 수 증가
- a temporal self-attention layer into each transformer block를 추가함 → the motion-free guidance (MFG) 개념 도입
3. Related Work
3.1 Diffusion models for T2I and T2V generation.
효율적인 T2I 생성을 위해 잠재 확산 모델은 일반적으로
1) 이미지를 컴팩트한 잠재 공간에 매핑하는 a pre-trained Variational Autoencoder
2) a strength control을 통해 텍스트를 처리하는 cross-attention 모델링 conditioner
3) 이미지 특징을 처리하는 백본 네트워크인 U-Net
의 특징을 지님
3.2 Transformer-based Diffusion.
U-ViT [3]는 트랜스포머 블록을 U-net 아키텍처와 통합하여 모든 입력을 토큰으로 취급
DiT [41]는 더 단순하고 계층적이지 않은 트랜스포머 구조를 사용
MDT [20]와 MaskDiT [69]는 마스크 전략[22]을 통합하여 DiT의 트레이닝 효율성을 높임
Dolfin [64]은 레이아웃 생성을 위한 트랜스포머 기반 모델
PixArt- α[9]는 트랜스포머 기반 T2I 확산에서 유망한 결과, 고품질 데이터로 3단계의 디컴포지션 프로세스를 통해 학습, 훈련 효율성을 강조
Scalable Diffusion Models with Transformers : DIT
4. Method
4.1 Preliminaries
Diffusion models
- markov chain \(x_1, x_2 ,..., x_T\) where β1 , …βT are hyperparameters corresponding to the noise schedule.
- \[\text{where } \bar{\alpha}_t = \prod_{s=1}^{t} \alpha_s, \quad \alpha_t = 1 - \beta_t \text{ and } \sigma_t\]
Latent diffusion model architectures
4.2 Text-to-Image GenTron
DiT-XL/2를 기반
트랜스포머 기반 T2I 확산 모델을 철저히 조사 → 텍스트 컨디셔닝 접근 방식에 초점
GenTron을 30억 개 이상의 파라미터로 확장하여 트랜스포머 아키텍처 확장
4.2.1 From Class to Text Condition
T2I 확산 모델은 텍스트 입력에 의존하여 이미지 생성 과정을 조정
원시 텍스트를 텍스트 임베딩으로 변환하는 텍스트 인코더의 선택
임베딩을 확산 프로세스에 통합하는 방법
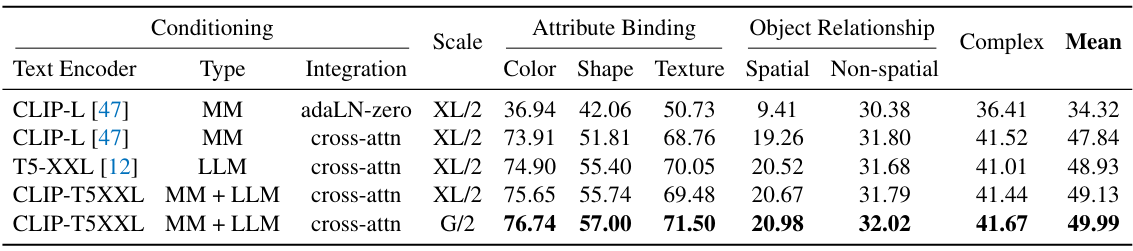
Text encoder model. 각각 고유한 강점과 한계를 지닌 다양한 언어 모델이 있음.
어떤 모델이 트랜스포머 기반 확산 방법에 가장 적합한지 테스트
Embedding integration
이번 연구에서는 adaptive layernorm and cross-attention 두 가지 임베딩 통합 방식에 초점
(1) adaptive layernorm(adaLN).
이 방법은 특징 채널의 정규화 파라미터로 조건부 임베딩을 통합. StyleGAN과 같은 조건 생성 모델링에서 널리 사용되는 adaLN은 클래스 조건을 관리하기 위해 DiT에서 표준 접근 방식으로 사용
(2) cross-attention
이미지 형상이 쿼리 역할을 하고 텍스트 임베딩이 키와 값 역할, attention메커니즘을 통해 이미지 기능과 텍스트 임베딩 간의 직접적인 상호작용
우리는 시간 임베딩을 별도로 모델링하기 위해 cross-attention과 함께 adaLN을 계속 사용
이러한 설계의 근본적인 근거는 모든 separately 위치에서 일관된 시간 임베딩이 adaLN의 글로벌 변조 기능의 이점을 누릴 수 있다는 믿음 때문
또한, 다음과 같이 풀링된 텍스트 임베딩을 시간 임베딩에 추가
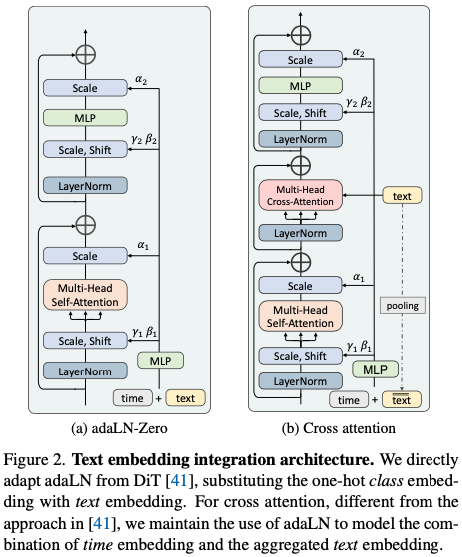
4.2.2 Scaling Up GenTron
트랜스포머 블록의 수(깊이), 패치 임베딩의 치수(폭), MLP의 숨겨진 치수(MLP-폭)라는 세 가지 중요한 측면을 확장하는 데 중점
4.3 Text-to-Video GenTron
GenTron을 T2I 프레임워크에서 T2V 프레임워크로 전환하는 과정에 대해 자세히 설명
4.3.1 GenTron-T2V Architecture
Transformer block with temporal self-attention.
시간 컨볼루션 레이어와 시간 트랜스포머 블록을 모두 T2I U-Net에 추가하는 기존의 접근 방식과 달리, 우리의 방식은 가벼운 시간적 self-attention (TempSelfAttn) 레이어만 통합 , 각 transformer block에
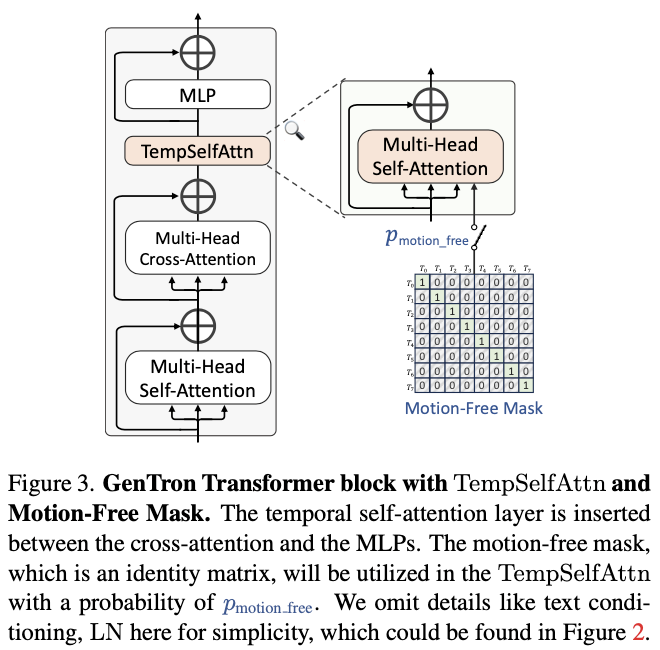
TempSelfAttn 레이어로 들어가기 전에 모양을 변경하여 수정한 다음, 통과한 후에는 원래의 형식으로 다시 모양을 변경
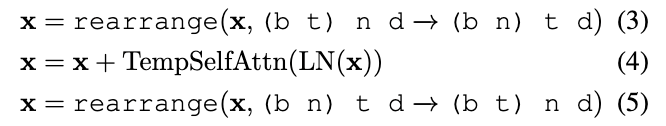
최근 연구에서 관찰한 결과와 일치하는 간단한 TempSelfAttn 레이어만으로도 모션을 캡처할 수 있다는 사실을 발견. 또한, 3.3.2절에서 설명할 시간적 모델링을 켜고 끄는 것은 TempSelfAttn을 사용하는 것만으로도 편리
Initialization
사전 훈련된 T2I 모델을 베이스로 사용하여 T2I와 T2V 모델 간의 공유 레이어를 초기화
또한 새로 추가된 TempSelfAttn 레이어의 경우 출력 프로젝트 레이어의 가중치와 바이어스를 0으로 초기화
이렇게 하면 T2V 미세 조정 단계가 시작될 때 이러한 레이어가 제로 출력을 생성하여 shortcut connection과 함께 identity 매핑으로 효과적으로 작동
4.3.2 Motion-Free Guidance
Challenges encountered
T2V diffusion model은 프레임당 시각적 품질이 T2I 모델보다 떨어짐
Problem analysis and insights
- 동영상 데이터의 특성: 동영상 데이터셋은 이미지 데이터셋에 비해 품질과 양 모두 부족, 모션 블러와 워터마크로 인해 손상
- Fine-tuning 방식: 동영상 fine-tuning 중 시간적 측면 최적화에 초점을 맞추면 공간적 시각적 품질이 의도치 않게 손상
Solution I: joint image-video training.
이미지-동영상 공동 학습 전략을 채택
Solution II: motion-free guidance.
motion-free attention mask를 사용하여 동영상 diffusion process에서 시간적 모델링을 비활성화
\[\tilde{\epsilon}_{\theta} = \epsilon_{\theta}(x_t, \emptyset, \emptyset)+ \lambda_T \cdot \left( \epsilon_{\theta}(x_t, c_T, c_M) - \epsilon_{\theta}(x_t, \emptyset, c_M) \right)+ \lambda_M \cdot \left( \epsilon_{\theta}(x_t, \emptyset, c_M) - \epsilon_{\theta}(x_t, \emptyset, \emptyset) \right)\]\(c_T\) , \(c_M\) : 텍스트 조건과 모션 조건
\(λ_T\) , \(λ_M\) : 텍스트와 모션의 guidance scale
\(λ_T=7.5\) 로 고정하고 \(λ_M∈[1.0,1.3]\) 에서 최고의 결과 나옴
Putting solutions together
학습 단계에서 모션이 생략되면 이미지-텍스트 쌍을 로드하고 이미지를 T−1번 반복하여 T개의 프레임을 생성
모션이 포함된 경우 동영상 클립을 로드하고 T개의 프레임을 추출
5. Experiments
5.1 Implementation Details
-
optimizer: AdamW (learinng rate = 10−4)
10−4
- T2I 모델
- multi-stage procedure
-
256×256에서 batch size 2048, 50만 step으로 학습
×
-
512×512에서 batch size 784, 30만 step으로 학습
×
-
- GPU 메모리 사용량을 최적화하기 위해 Fully Sharded Data Parallel (FSDP)와 activation checkpointing (AC)을 도입
- multi-stage procedure
- T2V 모델
- 동영상의 짧은 쪽이 512, FPS가 24가 되도록 전처리
- 128개의 동영상 클립을 batch로 사용
- 각 클립은 4 FPS로 캡처된 8개의 프레임으로 구성됨
5.2Main Results of GenTron-T2I