
[논문분석] FIT: Far-reaching Interleaved Transformers
efficient self-attention 와 adaptive computation을 갖춘 transformer-based 아키텍처 FIT [Page , Paper , Code]
William Peebles Saining Xie
Abstract
We present FIT: a transformer-based architecture with efficient self-attention and adaptive computation. Unlike original transformers, which operate on a single sequence of data tokens, we divide the data tokens into groups, with each group being a shorter sequence of tokens. We employ two types of transformer layers: local layers operate on data tokens within each group, while global layers operate on a smaller set of introduced latent tokens. These layers, comprising the same set of self-attention and feed-forward layers as standard transformers, are interleaved, and cross-attention is used to facilitate information exchange between data and latent tokens within the same group. The attention complexity is O(n2) locally 4 within each group of size n, but can reach O(L3 ) globally for sequence length of L. The efficiency can be further enhanced by relying more on global layers that perform adaptive computation using a smaller set of latent tokens. FIT is a versatile architecture and can function as an encoder, diffusion decoder, or au- toregressive decoder. We provide initial evidence demonstrating its effectiveness in high-resolution image understanding and generation tasks. Notably, FIT ex- hibits potential in performing end-to-end training on gigabit-scale data, such as 6400×6400 images, or 160K tokens (after patch tokenization), within a memory capacity of 16GB, without requiring specific optimizations or model parallelism. 1
저희는 efficient self-attention 와 adaptive computation을 갖춘 transformer-based 아키텍처 FIT
단일 데이터 토큰 시퀀스에서 작동하는 기존 트랜스포머와 달리, 데이터 토큰을 그룹으로 나누고 각 그룹은 더 짧은 토큰 시퀀스로 구성
로컬 레이어는 각 그룹 내의 데이터 토큰에서 작동하는 반면, 글로벌 레이어는 도입된 잠재 토큰의 더 작은 세트에서 작동하는 두 가지 유형의 트랜스포머 레이어를 사용
표준 트랜스포머와 동일한 셀프 어텐션 및 피드포워드 레이어 세트로 구성된 이러한 레이어는 인터리빙되며, 교차 어텐션은 데이터와 동일한 그룹 내 잠재 토큰 간의 정보 교환을 용이하게 하기 위해 사용
Introduction
self-attention 메커니즘을 사용 O(L2)의 복잡성을 가짐. 트랜스포머는 다양한 영역에서 성공을 거두었지만, 긴 시퀀스를 처리할 때 이차적 복잡성으로 인해 한계가 있음. 특히 짧은 시퀀스에서는 완전한 이차주의 메커니즘이 가장 효과적이고 일반적으로 사용
각 그룹 내에서는 quadratic attention을 활용하는 고대역폭 통신 채널을 사용할 수 있고, 그룹 간에는 의미 있는 압축을 통해 저대역폭 채널로 충분
-
자원 할당과 대역폭
특정 시스템, 특히 트랜스포머(Transformer)와 같은 딥러닝 모델에서 대역폭의 개념은 연산 자원 및 데이터 처리 속도와 밀접한 관계가 있습니다. 긴 시퀀스를 처리할 때 이차적 복잡성(O(L²))으로 인해 연산 자원과 메모리 소모가 급격히 증가합니다. 이러한 이유로 자원의 효율적 사용을 위해 대역폭 개념이 도입됩니다.
- 각 그룹 내에서 고대역폭 사용:
- 같은 그룹 내에서는 Quadratic Attention 메커니즘을 사용하여 고대역폭 채널을 통해 상세한 정보를 주고받습니다. 이는 복잡한 연산이 필요하지만, 높은 정확도를 보장합니다.
- 그룹 간에서 저대역폭 사용:
- 서로 다른 그룹 간에는 저대역폭 채널을 통해 압축된 정보를 주고받습니다. 이는 연산 자원과 메모리를 절약하면서도 중요한 정보를 교환할 수 있습니다.
- 각 그룹 내에서 고대역폭 사용:
데이터 토큰을 그룹 또는 세그먼트로 나누는 이러한 접근 방식은 기존의 여러 연구에서 성공적으로 적용
그러나 로컬(그룹 내) 및 글로벌(그룹 간) 정보 처리를 조정하는 메커니즘은 아직 충분히 연구되지 않은 상태
이 논문에서는 로컬 및 글로벌 처리를 효율적으로 조정하는 메커니즘을 설계
먼저 각 그룹에 대해 작은 잠재 토큰 세트를 도입함으로써 달성
로컬/윈도우 주의로 데이터 토큰을 처리하기 위한 트랜스포머 레이어와 글로벌 주의로 잠재 토큰을 처리하기 위한 두 가지 유형의 트랜스포머 레이어를 추가로 interleave
cross-attention는 같은 그룹 내의 데이터 토큰과 잠재 토큰 간에 정보를 라우팅하는 데 사용
네트워크의 단일 포워드 패스에는 데이터 토큰과 잠재 토큰의 반복적인 업데이트가 포함되므로 로컬 및 글로벌 정보가 충분히 통합
Method : FIT, or FitTransformer
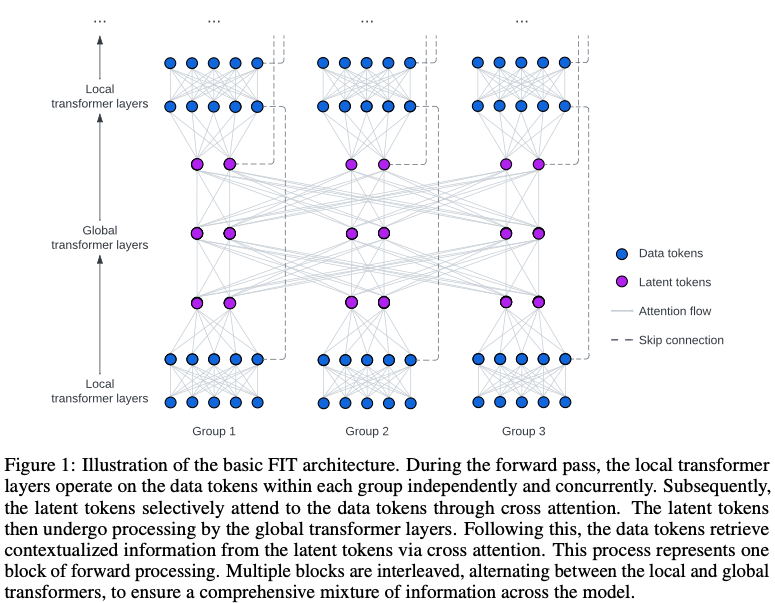
- 포워드 패스 동안 로컬 트랜스포머 레이어는 각 그룹 내의 데이터 토큰에 대해 독립적으로 동시에 작동
- 잠재 토큰은 cross-attention를 통해 데이터 토큰에 선택적으로 참석, 다음 잠재 토큰은 글로벌 트랜스포머 레이어에서 처리
- 데이터 토큰은 cross-attention를 통해 잠재 토큰에서 컨텍스트화된 정보를 검색
- 이 프로세스는 하나의 포워드 프로세싱 블록
- 여러 블록이 로컬 트랜스포머와 글로벌 트랜스포머를 번갈아 가며 인터리빙되어 모델 전체에 걸쳐 포괄적인 정보가 혼합
Group
transformer는 data token, positional encoding에서 동작 ( \(x ∈ R^{b×L×c}\), batch size, number of tokens, token dimension)
처리를 용이하게 하기 위해 데이터 토큰의 단일 그룹을 여러 그룹으로 나눔
\[\mathbb{R}^{b×t×n×c}\](배치 크기, 그룹 수, 그룹당 토큰 수, 토큰 차원) L = t × n
이미지의 경우, 이미지를 하위 이미지로 분할하고 각 하위 이미지를 별도의 그룹으로 처리
Data (local) tokens vs. latent (global) tokens
표준 트랜스포머에 사용되는 토큰에 해당하며 일반적으로 특정 데이터 요소와 연관, 트랜스포머 레이어를 통해 변환을 거친 후에도 데이터 토큰은 데이터의 특정 부분과의 연관성을 유지
잠재 토큰은 도입되는 작은 추가 토큰 집합으로, 처음에 기본 데이터에 직접 연결되지 않는 위치 임베딩으로 표현되는 경우가 많음, 그러나 포워드 패스가 진행되는 동안 잠재 토큰은 동적으로 정보를 집계하고 데이터의 특정 부분과 연결
이를 통해 모델은 장기 메모리를 형성하고 데이터 토큰의 정보를 효과적으로 압축
Local transformer layers vs. global transformer layers
로컬과 글로벌 트랜스포머 레이어는 모두 표준 자기 관심 모듈과 피드포워드 네트워크로 구성되는 유사한 구조를 공유
Local
각 그룹 내의 데이터 토큰에 적용
데이터 토큰을 처리하여 지역화된 정보 처리를 가능하게 하고 그룹 내 토큰 간의 세밀한 관계를 포착
로컬 트랜스포머 레이어는 컨볼루션과 같은 다른 아키텍처 빌딩 블록으로 대체하거나 자체 주의를 제거하여 단순화함으로써 사용자 정의 가능
\[\mathbb{R}^{b×t×n×c}\]global
모든 그룹에서 잠재 토큰을 처리하는 역할
입력의 여러 부분 간의 글로벌 종속성과 장거리 관계를 포착
\[\mathbb{R^{b×t×m×d}}\]m ≪ n

The basic FIT architecture
위 그림과 알고리즘 수도코드 보고 이해
FIT 아키텍처는 다양한 설정에 따라 다른 기존 아키텍처와 유사해질 수 있음
- 단일 그룹 설정:
- 설정: 데이터 토큰에 대해 단일 그룹을 설정하면, FIT는 RIN(Recurrent Independent Neural) 아키텍처와 유사해집니다. 그러나 RIN은 많은 수의 토큰에 대해 전체 어텐션을 사용하지 않는데, 이는 계산 비용 때문입니다.
- 특화: 만약 단일 블록의 로컬→글로벌→로컬 레이어만 사용한다면, 이는 Perceiver IO 아키텍처와 유사해집니다.
- 각 데이터 토큰을 개별 그룹으로 설정:
- 설정: 데이터 토큰의 수와 그룹 수를 동일하게 설정하면, FIT는 표준 트랜스포머와 유사해집니다. 하지만 이 경우 추가적인 토큰당 네트워크는 필요하지 않을 수 있습니다.
- 로컬 트랜스포머 레이어를 표준 트랜스포머로 간주:
- 설정: 각 그룹 내의 데이터 토큰에 대해 작동하는 로컬 트랜스포머 레이어를 표준 트랜스포머로 보면, FIT는 표준 트랜스포머의 확장형으로 볼 수 있습니다.
- 특징: FIT는 로컬 세그먼트를 연결하고 문맥화된 피드백을 제공하는 추가적인 글로벌 트랜스포머 레이어를 도입하여 모델의 표현력을 향상시킵니다.
글로벌 트랜스포머 레이어와 적응형 토큰화
- 글로벌 트랜스포머 레이어: 잠재 토큰에서 작동하는 글로벌 트랜스포머 레이어를 표준 트랜스포머로 간주할 때, FIT는 학습된 적응형 토큰화를 도입하여 표준 트랜스포머를 확장한 것으로 볼 수 있습니다.
- 적응형 토큰화: 데이터 토큰을 요약하여 잠재 토큰으로 변환하는 과정입니다. 이는 이미 압축된 패치 임베딩을 잠재 토큰으로 요약할 수 있어, 더 효율적이고 컴팩트한 처리를 가능하게 합니다.
Extending the basic FIT for autoregressive modeling
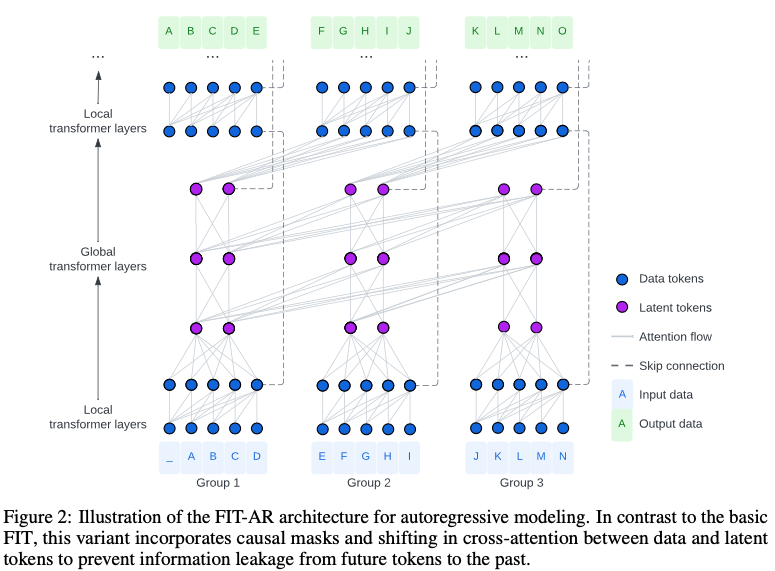
기본 FIT와 달리, 이 변형은 데이터와 잠재 토큰 간의 인과적 마스크와 교차 주의 이동을 통합하여 미래 토큰에서 과거 토큰으로 정보가 유출되는 것을 방지

자동 회귀 (언어) 모델링에서는 미래의 데이터 토큰에서 과거로의 정보 흐름을 막는 것이 중요
그룹내에서는 모두 접근 허용, 그룹 간에 인과 마스크를 부과하는 블록 단위 인과 마스크 통해 글로벌 트랜스포머 레이어에서 쉽게 달성
shifted latents between pushing and pulling information 개념 도입
- 구체적으로, i 번째 그룹의 데이터 토큰이 같은 그룹의 잠재 토큰에 정보를 푸시할 때 (i - 1)번째 그룹의 잠재토큰에서 정보를 가져옴
- 이러한 이동 메커니즘은 정보가 일관되고 인과적인 방식으로 흐르도록 보장하여 미래의 정보가 실수로 과거로 유출되는 것을 방지
- 이는 그림 2에 설명되어 있으며, FIT-AR 아키텍처를 훈련하기 위한 의사 코드는 알고리즘 2에 나와 있습니다. 추론 측면에서 모델은 여전히 한 번에 하나의 토큰을 자동 회귀적으로 디코딩하지만, FIT에 이전 데이터 토큰을 요약하는 잠재 토큰이 있으면 긴 시퀀스의 디코딩 속도를 크게 개선하는 동시에 메모리 사용량도 줄일 수 있음
Complexity and Efficiency Analysis
FIT는 표준 트랜스포머에 비해 두 가지 주목할 만한 효율성 향상을 제공
- 로컬 및 글로벌 주의가 인터리빙(번갈아 실행)되어 주의 계층의 복잡성을 크게 줄여 \(O(L^2)\) 의 이차적 복잡성에서 \(O(L^{4\over 3} )\) 의 최적 복잡성으로 개선합니다.
- 이 아키텍처는 적응형 계산(Adaptive Computation : 계산 자원을 상황에 맞게 효율적으로 사용하는 방법)을 가능하게 합니다. 로컬 트랜스포머 레이어의 처리를 더 작은 적응형 잠재 토큰 세트에서 작동하는 글로벌 트랜스포머 레이어로 오프로드함으로써 전체 계산 비용을 더욱 절감할 수 있습니다.
- 로컬 레이어에서 세밀한 정보 처리: 데이터 토큰 간의 세밀한 상호작용을 로컬 트랜스포머 레이어에서 처리합니다.
- 글로벌 레이어로 오프로드: 중요한 정보를 요약하여 잠재 토큰으로 전환한 후, 글로벌 트랜스포머 레이어에서 전역적인 문맥 정보를 처리합니다.
- 효율적인 자원 사용: 적은 수의 잠재 토큰을 통해 중요한 정보를 집중적으로 처리함으로써, 전체 연산 비용을 줄이고 효율성을 높입니다.
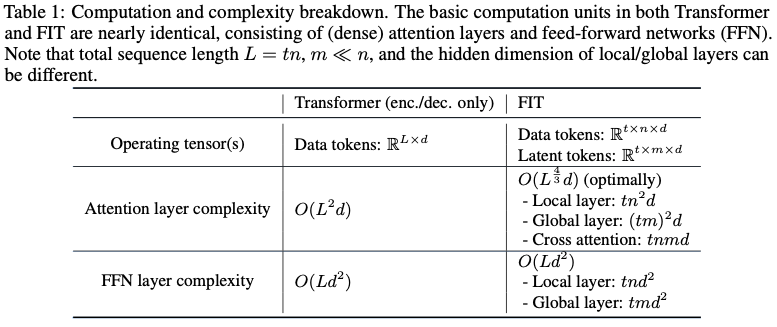
제안된 아키텍처의 이러한 효율성 개선은 계산 효율성을 유지하면서 긴 시퀀스를 처리하는 데 매우 적합합니다. 표 1은 표준 트랜스포머와 FIT의 계산 비용을 세분화한 것입니다.
주의 연산에 대한 자세한 계산 복잡성 분석은 부록 B에서 확인할 수 있습니다.
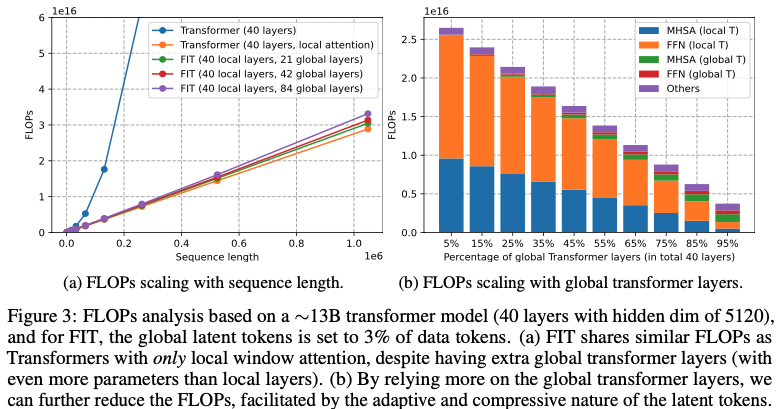
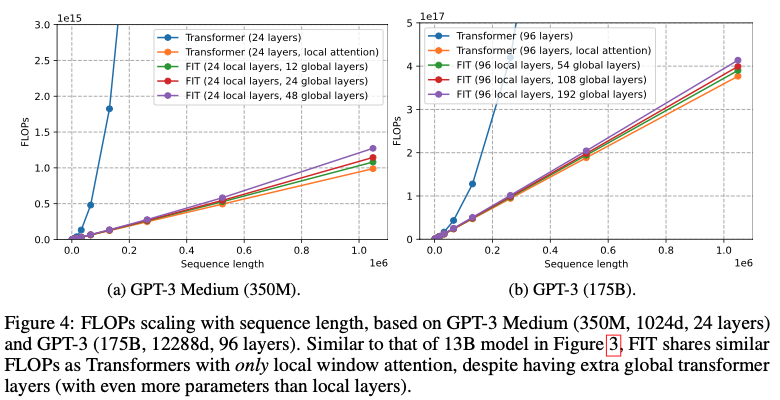
130억 개의 매개변수가 있는 디코더 전용 트랜스포머 모델의 FLOP(부동 소수점 연산) 분석에 초점을 맞춘 사례 연구
숨겨진 차원이 5120인 40개의 레이어로 구성됩니다(데이터 및 잠재 토큰 모두). 그룹/창 크기는 모든 시퀀스 길이에 대해 고정값인 2048로 설정되어 있어 이론적 주의 복잡도는 O(L2)입니다. 그러나 그룹당 64개의 잠재 토큰을 사용하면 글로벌 어텐션은 데이터 토큰의 약 3%에 대해 작동
그림 4a에서 표준 트랜스포머의 전체 주의력을 윈도우/그룹 주의력으로 대체하면 긴 시퀀스의 FLOP을 크게 줄일 수 있음을 확인
그러나 이 시나리오에서는 그룹 간에 글로벌 상호 작용이 없습니다. FIT를 사용하면 글로벌 트랜스포머 레이어를 통합하여 그룹 간 상호 작용을 가능하게 합니다. 특히, 잠복 토큰 세트가 줄어든 덕분에 시퀀스 길이가 100만 토큰인 경우에도 글로벌 트랜스포머 레이어에 필요한 추가 FLOP이 상대적으로 최소화됩니다. 또한 그림 4b는 로컬 레이어의 계산이 글로벌 레이어에 비해 훨씬 더 계산 비용이 많이 든다는 것을 보여줍니다
계산을 로컬 레이어에서 글로벌 레이어로 확장하면 FLOP을 더 줄일 수 있습니다. 더 작은 350M 모델과 더 큰 175B 모델에 대한 유사한 분석은 부록 C에서 확인할 수 있습니다.
-
GPT
제공된 그림과 설명은 다른 트랜스포머 모델에서 시퀀스 길이와 글로벌 트랜스포머 레이어 추가가 연산 효율성에 미치는 영향을 중심으로 FLOPs(초당 부동 소수점 연산) 확장을 분석한 내용을 강조합니다.
### 그림과 설명에서의 주요 포인트:
- 모델 비교:
- 분석에는 표준 트랜스포머와 다양한 크기와 구성의 “FIT” (Flexible Intermediate Tokens) 모델의 비교가 포함됩니다.
- FIT 모델은 로컬 어텐션 레이어와 소수의 글로벌 어텐션 레이어의 조합으로 설계되었습니다.
- 시퀀스 길이에 따른 FLOPs 확장 (그림 3a 및 4a):
- 350M 및 175B 파라미터 모델 모두에서 전체 어텐션을 윈도우/그룹 어텐션으로 대체하면 긴 시퀀스의 FLOPs가 크게 줄어듭니다.
- FIT 모델은 그룹 간 상호작용을 위한 글로벌 트랜스포머 레이어를 추가해도, 오직 로컬 어텐션만 사용하는 표준 트랜스포머와 유사한 FLOPs를 유지합니다.
- 이는 글로벌 트랜스포머 레이어가 감소된 세트의 잠재 토큰에서 작동하여 추가적인 연산 부하를 최소화하기 때문입니다.
- 글로벌 트랜스포머 레이어에 따른 FLOPs 확장 (그림 3b 및 4b):
- 세부 분석은 로컬 레이어가 글로벌 레이어에 비해 더 많은 연산 비용이 든다는 것을 보여줍니다.
- 글로벌 레이어의 비율을 증가시키면 전체 FLOPs가 줄어들 수 있습니다.
- 이는 잠재 토큰의 적응적이고 압축적인 특성 덕분에 글로벌 레이어가 상호작용을 더 효율적으로 관리할 수 있기 때문입니다.
### 시사점:
- 효율성: FIT 모델에 글로벌 트랜스포머 레이어를 포함하면 로컬 레이어의 연산 부담을 줄여 효율성이 향상됩니다.
- 확장성: FIT 모델은 긴 시퀀스 길이에 대해 FLOPs를 크게 증가시키지 않고 확장 가능성을 보여줍니다. 이는 잠재 토큰에서의 전략적인 글로벌 어텐션 사용 덕분입니다.
### 결론:
하이브리드 어텐션 메커니즘을 갖춘 FIT 모델은 특히 긴 시퀀스에 대해 트랜스포머의 연산 복잡성을 관리하는 유망한 접근법을 제공합니다. 이들은 로컬 및 글로벌 어텐션 레이어의 균형을 맞춰 FLOPs를 최적화하고 다양한 모델 크기에서도 효율성을 유지합니다.
- 모델 비교:
Experiments
우리는 제안한 아키텍처를 세 가지 작업에서 평가
- object365에서 Pix2Seq 객체 감지를 통한 고해상도 이미지 이해
- 512×512 또는 1024×1024 해상도의 이미지넷에서 픽셀 기반 노이즈 제거 확산 모델을 통한 고해상도 이미지 생성
- 이미지넷-64×64에서 픽셀 기반 자동 회귀 이미지 생성
High-resolution image understanding using Pix2Seq
-
Pix2Seq
Pix2Seq는 이미지 조건부 언어 모델링 프레임워크를 사용하여 객체 감지, 세그먼트, 키포인트 감지 등 다양한 비전 작업
이미지 인코더를 사용하여 의미 있는 시각적 특징을 추출하고 언어 디코더를 사용하여 경계 상자 좌표 및 클래스 레이블과 같은 객체 설명을 생성합니다. 여기서는 일반적으로 사용되는 비전 트랜스포머(ViT) 인코더[17]와 함께 FIT를 평가합니다. Pix2Seq은 유도 편향이 낮기 때문에 objects365[43]와 같은 대규모 데이터 세트에 대한 사전 학습을 통해 이점을 얻을 수 있습니다. 따라서 [8]과 유사한 설정을 따르고 사전 학습 음의 로그 가능성(Nll)을 사용하여 다양한 인코더의 성능을 평가합니다.
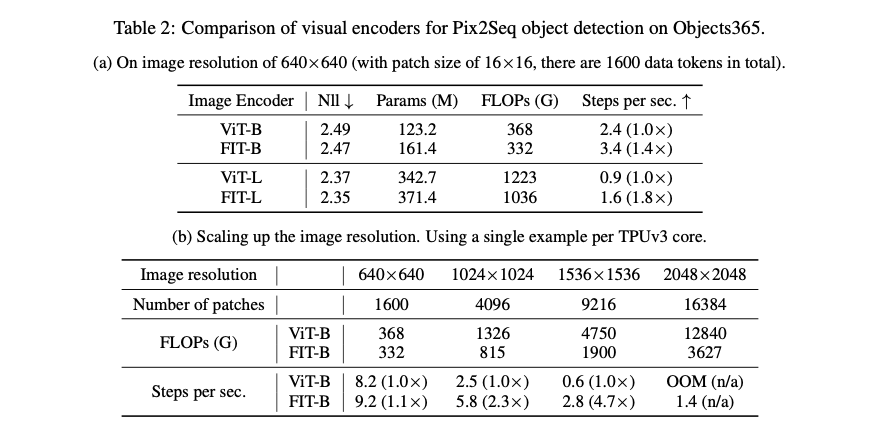
몇 개의 추가 글로벌 레이어를 통합함으로써 FIT가 훈련 중 초당 단계를 증가시킬 뿐만 아니라 손실도 감소시키는 것을 관찰할 수 있습니다. 또한 이미지 해상도를 높이면 속도 향상은 더욱 두드러집니다.
특히, 특별한 최적화나 모델 병렬 처리 없이도 TPUv3에서 3억 개 이상의 FIT 모델을 훈련하여6400×6400×3×8비트(∼1GB)의 원시 입력 데이터를 포함하는 6400×6400 해상도 이미지를 처리할 수 있습니다. 이미지가 16×16 패치로 토큰화되므로 결과 입력은 160K 토큰으로 구성됩니다.
Pixel-based end-to-end diffusion modeling
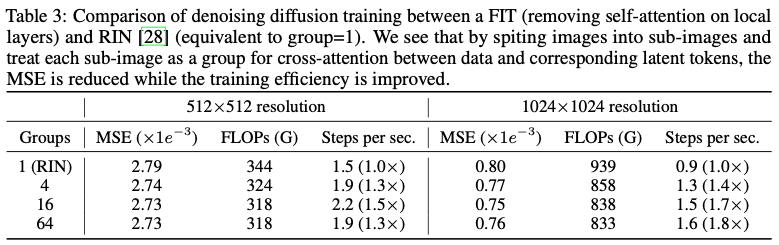
RIN은 단일 토큰 그룹과 로컬 레이어에 대한 자체 주의가 없는 기본 FIT 아키텍처의 특정 인스턴스로 볼 수 있음
RIN은 확산 모델에 최적화되어 있기 때문에 추가 그룹을 통합하여 FIT와 RIN을 직접 비교
Pixel-based image autoregressive modeling
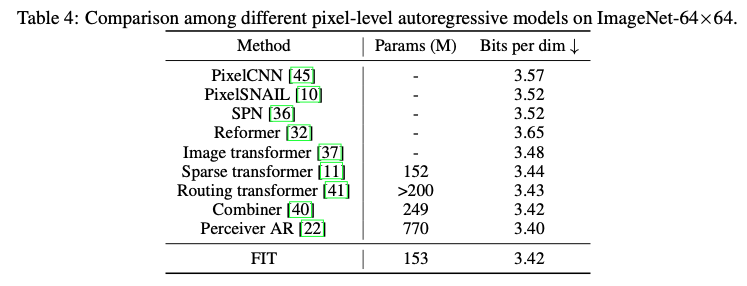
자동 회귀 방식으로 픽셀을 개별 토큰으로 직접 모델링하는 방법은 긴 시퀀스 길이(예: 64x64 이미지의 경우 12,288개의 데이터 토큰)와 로컬 및 글로벌 종속성을 모두 캡처해야 하는 문제로 인해 어려움.
저희 접근 방식에서는 픽셀을 로컬에서 8×8 패치로 그룹화하여 그룹당 192개의 데이터 토큰을 생성, 그룹당 32개의 잠재 토큰을 활용
데이터 토큰에는 512d를, 잠재 토큰에는 768d를 사용하며 레이어 구성은 L(8)G(2)L(8)G(2)L(8)G(2)L(8)
Ablation study
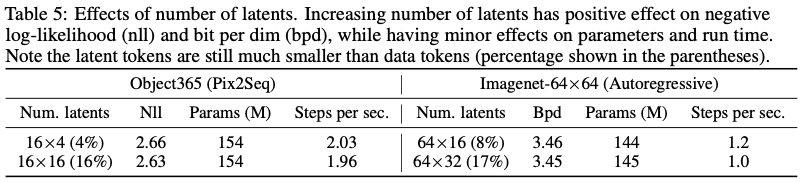
더 많은 수의 레이턴트를 활용할 때의 효과
흥미롭게도, 로컬 레이어가 계산에 더 많이 기여하는 경우 레이턴트 수를 늘린다고 해서 반드시 파라미터나 학습 시간(초당 단계)이 크게 증가하지는 않는다는 것을 관찰 가능
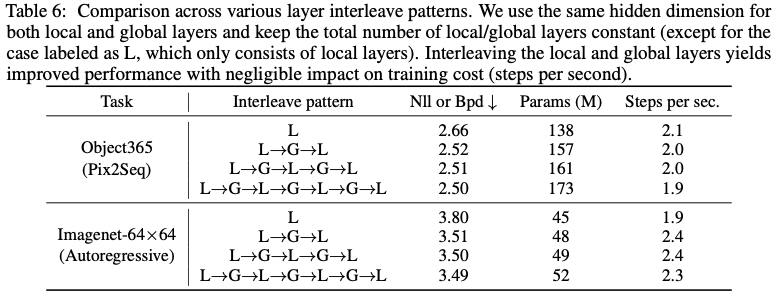
로컬 레이어와 글로벌 레이어의 수를 일정하게 유지하면서 다양한 레이어 인터리빙 패턴을 조사하고 있으며(로컬 레이어만 존재하는 경우, 원래 로컬 및 글로벌 레이어에 해당), 두 유형의 레이어에 대해 동일한 숨겨진 차원을 사용하고 있습니다. 특히 로컬 레이어와 글로벌 레이어를 혼합하는 것이 거의 동일한 훈련 효율을 유지하면서 최적의 결과를 얻기 위해 매우 중요하다는 것을 관찰했습니다(TPUv3에서 초당 단계로 측정).