
[논문분석] E2E Segmenter: Joint Segmenting and Decoding for Long-Form ASR
[paper]
VAD(Voice Activity Detector)와 Streaming End-to-end (E2E) models for ASR을 통합해 성능 향상
Abstract
Improving the performance of end-to-end ASR models on long utterances ranging from minutes to hours is an ongoing challenge in speech recognition. A common solution is to segment the audio in advance using a separate voice activity detector (VAD) that decides segment boundary locations based purely on acoustic speech/non-speech information. VAD segmenters, however, may be sub-optimal for real-world speech where, e.g., a complete sentence that should be taken as a whole may contain hesitations in the middle (“set an alarm for… 5 o’clock”). We propose to replace the VAD with an end-to-end ASR model capable of predicting segment boundaries in a streaming fashion, allowing the segmentation decision to be conditioned not only on better acoustic features but also on semantic features from the decoded text with negligible extra computation. In experiments on real world long-form audio (YouTube) with lengths of up to 30 minutes long, we demonstrate 8.5% relative WER improvement and 250 ms reduction in median endof-segment latency compared to the VAD baseline on a stateof-the-art Conformer RNN-T model. Index Terms: speech recognition, speech segmentation, decoding algorithms, beam search
1. Introduction
문제점
짧은 발화에 대해서 높은 성능을 보이지만, 긴 발화에 대해서는 성능이 떨어짐
- deletion error : ASR 모델이 음성에서 실제로 발화된 단어를 인식하지 못하고 누락시키는 현상
왜 긴 음성에서 더 크게 발생할까?
- Context Loss and Attention Drift : 전체 문맥의 흐름을 놓치는 경우
- Error Accumulation : auto-regressive 방식에서 에러가 누적
- Repetitive Patterns and Omission : filler(무의식적으로 사용하는, 의미 없는 단어나 소리) 로 인해 반복 패턴을 학습하면서, 중요한 내용임에도 불구하고 불필요한 반복으로 오인하여 생략
- Memory Limitations and Lack of State Reset : RNN 계열 모델은 내부적인 ‘상태(state)’를 가지고 정보를 기억하는데, 입력이 너무 길어지면 이 상태가 오래되고 불필요한 정보로 가득 차버려 성능이 저하
→ 따라서 VAD나 E2E Segmenter를 통해 audio를 분할 각각을 독립적으로 처리
기존 해결책 및 한계
현재 VAD는 latency가 높음
긴 침묵을 기다려야 함으로
segmentation error가 큼
의미를 파악하지 않고 오직 오디오만 듣고 segment를 판단함으로
음성: “Shaq… dunks—game over!” (샤크… 덩크는—게임 끝!)
S1: shaq dunks game over (샤크 덩크 게임 끝) → 정답
S2: shaq dunks game over (샤크 덩크 게임 끝) → 오디오만 가지고 segment를 판단
제안하는 방법
“E2E Segmenter”: 별도의 VAD를 사용하는 대신, ASR과 구간 분할 예측을 하나의 모델에서 동시에 수행하는 엔드투엔드 모델을 제안
이 모델은 음향 정보뿐만 아니라 디코딩된 텍스트의 의미론적 정보까지 활용하여 더 정확하게 구간을 나눔
- 정답 데이터가 없는 구간 분할 문제를 해결하기 위해, 망설임과 단어 시간 정보를 모델링하여 구간 분할 레이블을 생성하는 새로운 주석(annotation) 기법을 제안
- RNN-T 아키텍처에 새로운 joint layer를 도입하여, 단어 예측 성능을 저하시키지 않으면서 독립적으로 구간 종료 토큰을 예측
2. Method
기존 방식처럼 별도의 VAD를 사용하지 않고, ASR 모델의 디코더가 직접 문장의 끝을 의미하는 특별한 <eos>(end-of-segment) 토큰을 예측하도록 학습
모델이 <eos> 토큰을 높은 확신으로 예측하면, 이를 ‘구간 경계 신호’로 간주하여 오디오 분할을 수행
2.1. End-of-segment joint layer
모델 구조에 대한 제안

Figure 1: RNN-T with additional joint layer for emitting the end-of-segment posterior.
기존 RNN-T 모델의 Joint Layer에 <eos> 예측 기능을 추가하면, 원래의 단어 예측 성능(WER)이 저하되는 문제 발생
이 문제를 해결하기 위해, 단어 예측용 Joint Layer와 <eos> 예측용 Joint Layer를 분리한 이중(dual) 레이어 구조를 제안
두 작업이 서로 간섭하지 않고 독립적으로 수행
\[P (<eos>|\mathrm{x}_1, · · · , \mathrm{x}_t, y_1, · · · , y_u)\]$\mathrm{x}_ i$ 는 i번째 오디오 프레임이고 $y_ i$ 는 빔에서 i번째로 디코딩된 토큰
Transfer Learning 방법을 사용해 end-of-segment joint layer 생성
2.2. End-of-segment annotation
학습 데이터 생성 제안
![Figure 2: Example of
<eos>를 어디에 넣어야 할지에 대한 정답 데이터가 없기 때문에, 비싸고 비일관적인 사람의 수작업 대신 규칙 기반(heuristic)의 자동 레이블링 방식을 사용 (weak supervision 방법)
- 긴 침묵(1.2초 이상)이 있거나 발화가 끝나면
<eos>를 삽입 - “음…” 같은 필러(filler)나 “헤이이”처럼 길게 끈 단어 뒤의 침묵은 문장이 끝나지 않은 망설임으로 간주하여
<eos>를 삽입하지 않음
2.3. FastEmit training
속도 향상 방법 제안
![Table 1: Rules and exceptions for inserting
Table 1: Rules and exceptions for inserting
- VAD처럼 긴 침묵이 끝날 때까지 기다리지 않고, 가능한 한 빨리
<eos>를 예측하여 지연 시간을 줄이는 것 - 이를 위해 FastEmit 정규화 기법을 학습에 적용하여, 모델이 최소한의 정보만으로도 확신이 생기면 즉시
<eos>토큰을 출력하도록 유도
FastEmit regularization term [paper]
기존 방법은 정확도에 초점 → 예측 시간이 중요하지 않음
예를 들어, “Hello”라는 음성을 듣고 모델이 [h, e, l, l, o]를 예측해야 할 때,
- 느린 예측:
[blank, blank, blank, **h**], [**e**], [**l**], [blank, **l**], [**o**] - 빠른 예측:
[**h**], [**e**], [**l**], [**l**], [**o**]
두 가지 경로 모두 최종 결과는 “Hello”로 동일하므로, 기존 학습 방식에서는 두 경로에 동일한 점수
이 때문에 모델은 굳이 서둘러서 예측할 필요 없이, 충분한 음성을 듣고 “느긋하게” 예측하는 경향이 생김
latency penalty term을 loss function에 추가 → 예측을 늦게 하는 ‘느린’ 경로에 페널티를 부과
\[P'(π|x) = P(π|x) * exp(-λ * N_blanks(π))\] \[\mathrm{FastEmit}\ \mathrm{Loss} = -log( Σ P'(π|x) ) = -log( Σ [ P(π|x) * exp(-λ * N_{blanks}(π)) ] )\]λ (람다): 페널티의 강도를 조절하는 하이퍼파라미터입니다.
각 경로(π)의 확률을 계산할 때, 해당 경로에 포함된 blank 토큰의 수($N_{blanks}$)만큼 지수적으로 페널티
3. Setup
3.1. Dataset
- 테스트셋:
YT_LONG,YT_SHORT(실제 유튜브 데이터) - 훈련셋: 구글 트래픽 (음성 검색, 유튜브 등) 약 3억 개 발화, 40만 시간 분량
- 특징: 훈련용 유튜브 데이터는 20초 내외로 사전 분할, 다양한 데이터 증강 기법 적용
3.2. Model
- 구조: Conformer 기반 스트리밍 RNN-T
- 인코더: 12-layer streaming Conformer
- 파라미터: 총 1억 4천만 개 (제안된
<eos>Joint Layer는 100만 개 미만) - 학습: RNN-T + MWER 손실, FastEmit 정규화(가중치 5e-3) 사용
3.3. Beam search
- 빔 크기: 8
- 가지치기(Pruning) 기준: 최상위 가설보다 점수가 5 이상 낮으면 후보에서 제거
- 최대 세그먼트 길이: 65초 (이후 강제 분할)
3.4. Voice activity detector
- 역할: 비교 실험을 위한 베이스라인 모델로만 사용됨
- 작동: 0.2초의 연속된 침묵을 감지하면 강제로 구간 분할 신호 전송
- 실험 조건: 제안 모델(E2E Segmenter) 실험 시에는 이 VAD 기능 끔
4. Results
평가 지표
- WER: 단어 오류율 (품질)
- EOS50, EOS75: 구간 종료 지연 시간 (속도)
- # Segment: 평균 분할 개수
- # State: 빔 서치 효율성 (계산량)
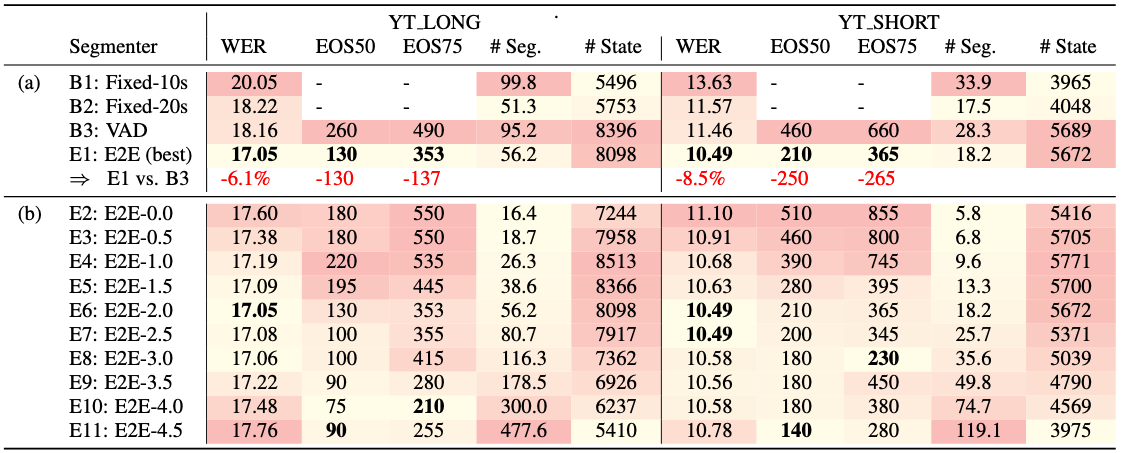
Table 3: (a) Main results. (b) End-of-segment threshold ablation study. Naming convention is E2E-{eos threshold value}
4.1. Main results
- 제안 모델(E2E Segmenter)이 기존 VAD 기반 모델보다 성능 우수.
- WER: 6.1% ~ 8.5% 상대적 개선.
- 지연 시간: 130ms ~ 265ms 단축.
- 핵심: 분할 ‘개수’보다 분할의 ‘정확성’이 더 중요함을 시사.
4.2. threshold ablation study
<eos>임계값은 공격성(속도)과 정확성(오류) 사이의 트레이드오프를 조절.- 최적의 WER을 보이는 임계값은 2.0으로 설정함.
4.3. Utterance length dependence
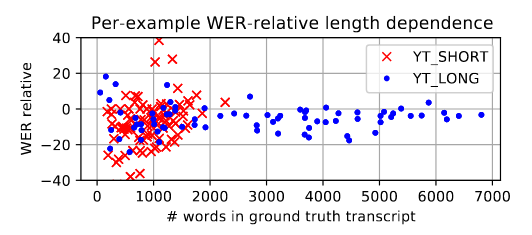
Figure 3: Per-example WER-relative of E2E (E1) to VAD (B3) segmenters versus utterance length. Lower is better.
- 성능 개선 효과는 발화 길이에 상관없이 일관되게 나타남.
- 매우 긴 음성뿐만 아니라 중간 길이 음성에도 효과적임을 의미.
4.4. Results with frame filtering
- 프레임 필터링(계산량 절약 기술) 적용 시, 음향 정보 감소로 인해 전반적인 WER은 상승함.
- 하지만 필터링 환경에서도 여전히 E2E Segmenter가 VAD보다 우수함 (WER 3.1% 개선, 지연 시간 120ms 단축).
- 결론: 자원이 제한된 환경에서는 품질과 계산 효율성 간의 트레이드오프가 필요함.
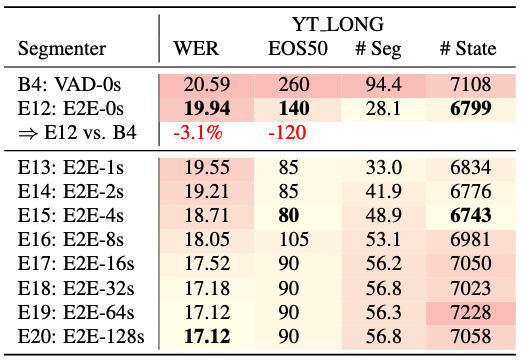
Table 4: Segmenting with frame filtering for YT LONG. YT SHORT results are similar and not displayed for brevity. Naming convention is {segmenter}-{margin length}
5. Conclusion
Our work presents a way to improve streaming long-form audio decoding by replacing the VAD-based segmenter with an E2E model. We proposed an E2E architecture that predicts segment boundaries and provided an automatic end-of-segment data annotation strategy required for learning that task in an end-to-end fashion. Our results demonstrate significant WER and end-ofsegment latency improvements compared to a VAD baseline on a long-form YouTube captioning task.