
[논문분석] Diff2Lip: Audio Conditioned Diffusion Models for Lip-Synchronization
GAN을 활용한 sound guided video generation, clip의 latent space를 활용
[Code, Paper]
1. Abstract
The task of lip synchronization (lip-sync) seeks to match the lips of human faces with different audio. It has various applications in the film industry as well as for creating virtual avatars and for video conferencing. This is a challenging problem as one needs to simultaneously introduce detailed, realistic lip movements while preserving the identity, pose, emotions, and image quality. Many of the previous methods trying to solve this problem suffer from image quality degradation due to a lack of complete contextual information. In this paper, we present Diff2Lip, an audio-conditioned diffusion-based model which is able to do lip synchronization in-the-wild while preserving these qualities. We train our model on Voxceleb2, a video dataset containing in-the-wild talking face videos. Extensive studies show that our method outperforms popular methods like Wav2Lip and PC-AVS in Frechet inception distance (FID) ´ metric and Mean Opinion Scores (MOS) of the users. We show results on both reconstruction (same audio-video inputs) as well as cross (different audio-video inputs) settings on Voxceleb2 and LRW datasets. Video results and code can be accessed from our project page.
lip synchronization (lip-sync) with diffusion model
Voxceleb2로 모델을 훈련
2. Introduction
립싱크 초기 모델 : Video Rewrite
phonemes(음소)를 입모양과 mapping → video와 결합
예시
PC-AVS (음성의 내용, 머리 자세, 그리고 얼굴의 정체성 정보를 분리하여 처리)
GCAVT (음성 신호와 얼굴의 기하학적 정보를 결합, 다양한 얼굴 구조와 표정을 가진 영상을 생성)
두 모델은 각각 포즈와 표정을 분리, but identity, quality, border 성능 떨어짐
SynthesizingObama : video/identity-specific training, 새로운 인물에 적용하려면 추가적인 훈련이 필요, 일반화(generalization) 능력이 제한적
MakeItTalk : intermediate representations, 예를 들어 얼굴 landmarks를 추출하여 Lip-sync를 구현, 하지만 landmark estimation errors 존재 → 랜드마크 정확히 추출해야 함
Wav2Lip : 음성 기반 입술 동기화, Impainting task, 입술영역 마스킹 이를 오디오에 맞게 생성
좋은 lip-sync, 하지만 낮은 quality
AV-CAT : multistage pipeline, quality에 문제가 있음
본 논문 제안
Diff2Lip : inpainting task + Diffusion Model
input : Masked Input Frame, Reference Frame, Audio Frame
loss : Reconstruction Loss, Sync-Expert Loss, Sequential Adversarial Loss
입술 영역을 정확히 복원, Wav2Lip에서 사용된 손실 함수로, 음성과 입술 움직임의 동기화, 프레임 간 연속성을 보장
3. Related Works
3.1 Lip synchronization
-
Embedding-based head reconstruction
speech and identity features들을 결합 → 전체 head 합성
encoder-decoder style architecture
전체 얼굴을 생성하여 경계 불일치 문제 발생, 높은 시각적 품질을 제공하지만 리얼타임 처리에 한계가 있음
-
Intermediate Representation-based Methods
face landmarks or meshes 같은 sparse한 중간 표현을 조작하여 립싱크를 구현
수동으로 표현을 얻는 것이 비용이 많이 들고 자동 예측 시 오류가 발생할 수 있으며, 세부 사항 손실 우려가 있음
-
Personalized Methods
identity specific or even video-specific에 맞춰서 학습
높은 비디오 품질을 제공하지만, 특정 인물과 환경에 맞춰 모델을 재학습해야 하는 번거로움
-
Inpainting-based Methods
얼굴의 전체를 생성하는 대신, 음성에 의해 영향을 받는 입주변 얼굴 부분만 수정
이미지 경계 불일치 문제를 피할 수 있으며, 엔드투엔드 학습이 가능하고 정체성에 독립적
입술 색조 변화 등의 문제
3.2 Conditional Diffusion Models
Noise2Music : 텍스트 프롬프트만을 사용하여 음악을 생성할 수 있는 디퓨전 모델을 제안
4. Methods
4.1 Diffusion Models
기본 모델 사용
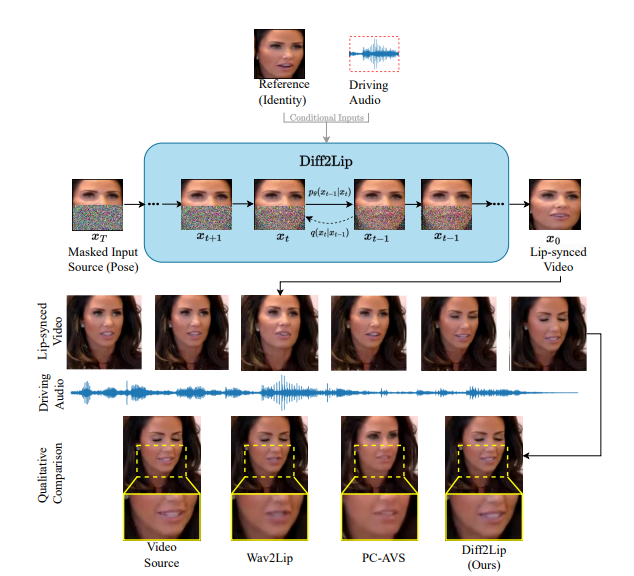
4.2 Proposed Approach
모델은 입 부분이 mask 된 이미지를 제공 받고 하부의 입을 생성해냄 (Inpainting)

4.2.1 Lip-Sync → Inpainting
- Input video frame ( \(v_s\) ): 원본 비디오의 각 프레임
- Masked video frame (\(x_{s,T}\)): 원본 프레임의 하부 얼굴을 마스킹한 상태
- Audio frame (\(a_s\)$): 각 비디오 프레임에 대응하는 오디오 정보 →입술 구조에 대한 정보를 제공
- Random reference frame (\(x_r\)): 동일 비디오 내에서 무작위로 선택된 다른 프레임(입력 프레임과는 다름) → 소스의 정체성과 자세(pose)에 대한 정보를 제공
- M : 얼굴 하부 masking , a binary mask
- \[η ∈ \mathcal{N} (0,I)\]
- subscript T는 completely 노이즈가 추가된 프레임
reverse diffusion process를 통해 마스킹된 비디오 프레임 \(x_{s,T}\)과 오디오 프레임 \(a_s\), 참조 프레임 \(x_r\)을 입력으로 받아 원본 비디오 프레임 \(v_s\)를 복원
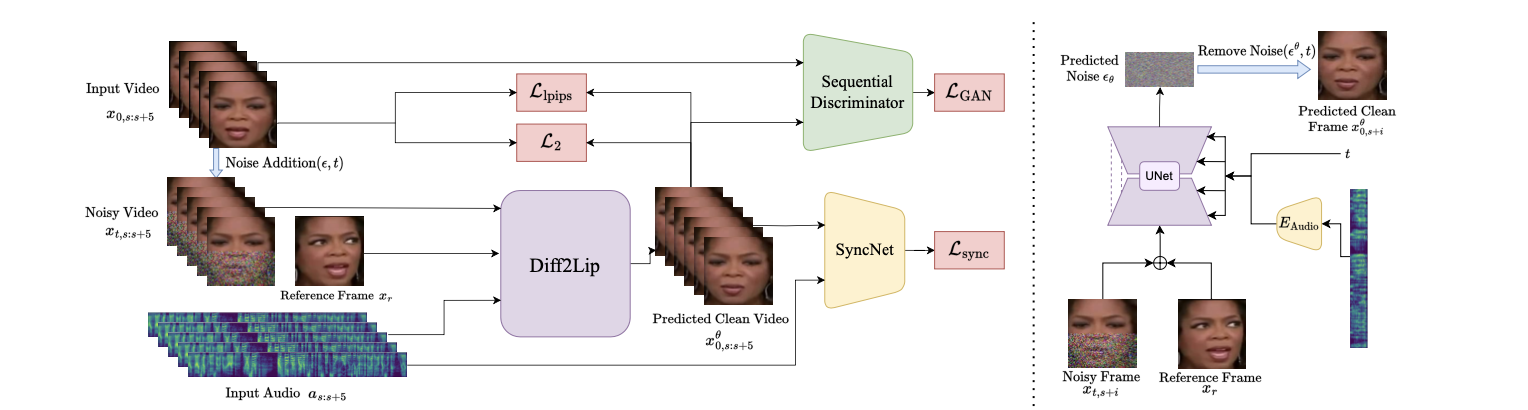
4.2.2 Diffusion model training
Conditional model \(\epsilon_\theta(xs,t, as, xr, t)\)으로 학습
균일하게 샘플링된 시간 스텝 t를 사용
추가된 노이즈 ϵ을 예측 하도록 학습. 아래는 Loss
Random reference frame (\(x_r\))은 입력 프레임과 concat해서 입력으로 제공
Audio frame (\(a_s\))은 group normalization를 통해 조건부 정보로 주입
UNet based network : residual blocks + attention blocks
마스킹되지 않은 입력 프레임과 참조 프레임에서 컨텍스트 정보를 추출
4.2.3 Audio encoder
audio는 trainable한 인코더를 거쳐 conditional embedding으로 들어감
4.3 Additional Losses
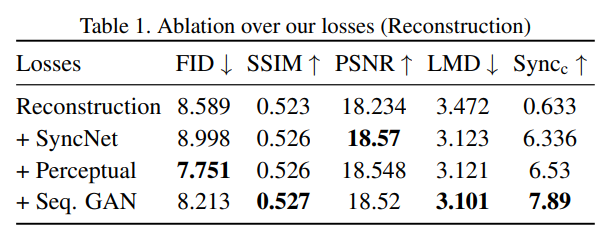
모델을 L_simple 손실 함수만으로 훈련했을 때, 마스크된 하부 얼굴 영역의 이미지 품질은 좋았지만 입술 동기화(lip-sync)가 제대로 이루어지지 않는다는 문제가 발생
- L2 손실: 디노이즈된 이미지의 정확성 향상
-
SyncNet 손실: 오디오와 비디오의 입술 동기화 강화
\[L_{\text{sync}} = \mathbb{E}_{x_{0,s,t}, \epsilon} \left[ \text{SyncNet}(x_{\theta}^{0,s:s+5}, a_{s:s+5}) \right]\]- \(x_θ^{0,s:s+5}\): 생성된 비디오의 특정 시점 s부터 s+5까지의 연속된 프레임.
- \(a_{s:s+5}\): 해당 시점의 오디오 샘플.
- \(\text{SyncNet}(\cdot)\): SyncNet 모델이 두 입력 간의 동기화 점수를 반환하는 함수.
-
LPIPS 손실: 생성된 이미지의 지각적 유사성 유지
- GAN 손실: 프레임 간 시간적 일관성 및 현실감 향상
최종 loss
\[L = L_{\text{simple}} + \lambda_{L2} L_{2} + \lambda_{\text{sync}} L_{\text{sync}} + \lambda_{\text{lpips}} L_{\text{lpips}} + \lambda_{\text{GAN}} L_{\text{GAN}}\]4.4 Limitations of approaches that predict in noisy space
diffusion model은 노이즈를 직접 예측하거나, 노이즈가 제거된 이미지 자체를 예측
→ 노이즈 공간에서 작업
문제점
- 이미지 공간에서 직접적인 손실 함수를 사용할 수 없음
- 이미지 품질을 평가하거나 입술 동기화를 측정하는 등의 손실 함수(예: L2 손실, LPIPS 손실 등)
- 추정 이미지의 품질 저하
- 노이즈 공간에서 복원된 결과물은 품질이 떨어질 수 있음
- 특히, 높은 노이즈 단계(시간 단계 t가 클 때)에서는 더 많은 정보 손실이 발생
4.4.1 3가지 접근 방식
-
직접적인 디노이즈된 이미지 (\(x_0\)) 예측
장점
- 이미지 공간에서 바로 복원되므로, 다양한 손실 함수(L2, LPIPS 등)를 직접 적용 가능
- 최종 이미지 품질을 높이는 방향 설계 가능
단점
- 직접 x0를 예측하는 모델은 이미지 품질이 저하되는 경향 → 노이즈를 추가하는 모델의 과정과 직접적인 연결이 부족하기 때문 (이건 오히려 noise 예측 모델이 더 좋음)
- 입술 동기화와 같은 정밀한 작업에서도 성능이 저하
-
역 확산 과정 사용 sampling process
\(x_t\)로부터 \(x_0\)를 복원
장점
- Diffusion 모델의 핵심 메커니즘(샘플링 과정) 유지 → 이미지 품질 향상
- 다양한 손실 함수(LPIPS, GAN 등)를 \(x_0\)에 적용
단점
- 샘플링 과정이 반복적이고 시간이 많이 소모
- T 단계의 확산 과정 전체를 복원해야 하므로, 실시간 애플리케이션에서는 비효율적
-
직접 \(x_θ^0(x_t,t)\) 예측
장점
- 샘플링 과정을 생략할 수 있어 계산 효율적
- \(x_0\)를 직접 복원하지 않으면서도, 노이즈 공간과 이미지 공간을 모두 활용
단점
- t가 클 때, \(x_θ^0(x_t,t)\)가 여전히 노이즈가 많은 상태로 계산
- 초기 복원 단계에서 품질이 떨어질 가능성있음
보통 Diffusion model이 3번째 방법을 주로 사용
5. Experiments
Datasets
VoxCeleb2, LRW
- 훈련: VoxCeleb2의 훈련 분할만 사용, 전체 데이터셋이 아닌 각 비디오의 첫 발화만 사용 (총 145K 비디오)
- 테스트: VoxCeleb2의 테스트 세트 4911 발화와 LRW의 25K 비디오 사용
Implementation Details
전처리
- 비디오 프레임 속도: 25 fps.
- 오디오 샘플링 속도: 16kHz.
- 비디오 해상도: 224×224 → 얼굴 크롭 후 128×128로 리사이즈.
- 하부 얼굴을 가우시안 노이즈로 마스킹 후 모델 입력.
- 오디오 입력: 16kHz로 샘플링 후 윈도우 사이즈 800, 홉 사이즈 200의 멜-스펙트로그램 생성 (크기 16×80).
모델 학습
- 기반 코드: guided-diffusion repository 사용.
- 하드웨어: NVIDIA RTXA6000 GPU 8개 사용, 학습 시간 약 4일.
- 디퓨전 단계: 훈련 시 T = 1000 단계, 추론 시 DDIM 샘플링 25 단계 사용 (VoxCeleb2 비디오 하나당 평균 4.67초 소요).
Comparison Methods
- Wav2Lip [35]
- 특징: 인페인팅 스타일의 방법으로 SyncNet 전문가 손실을 사용하여 좋은 입술 동기화 구현.
- PC-AVS [58]
- 특징: 정체성과 자세 제어에 중점을 둔 헤드 재구성 방법.
- 평가 방식:
- 두 방법 모두 공개된 사전 학습 모델을 사용하여 모든 데이터셋에 대해 평가.
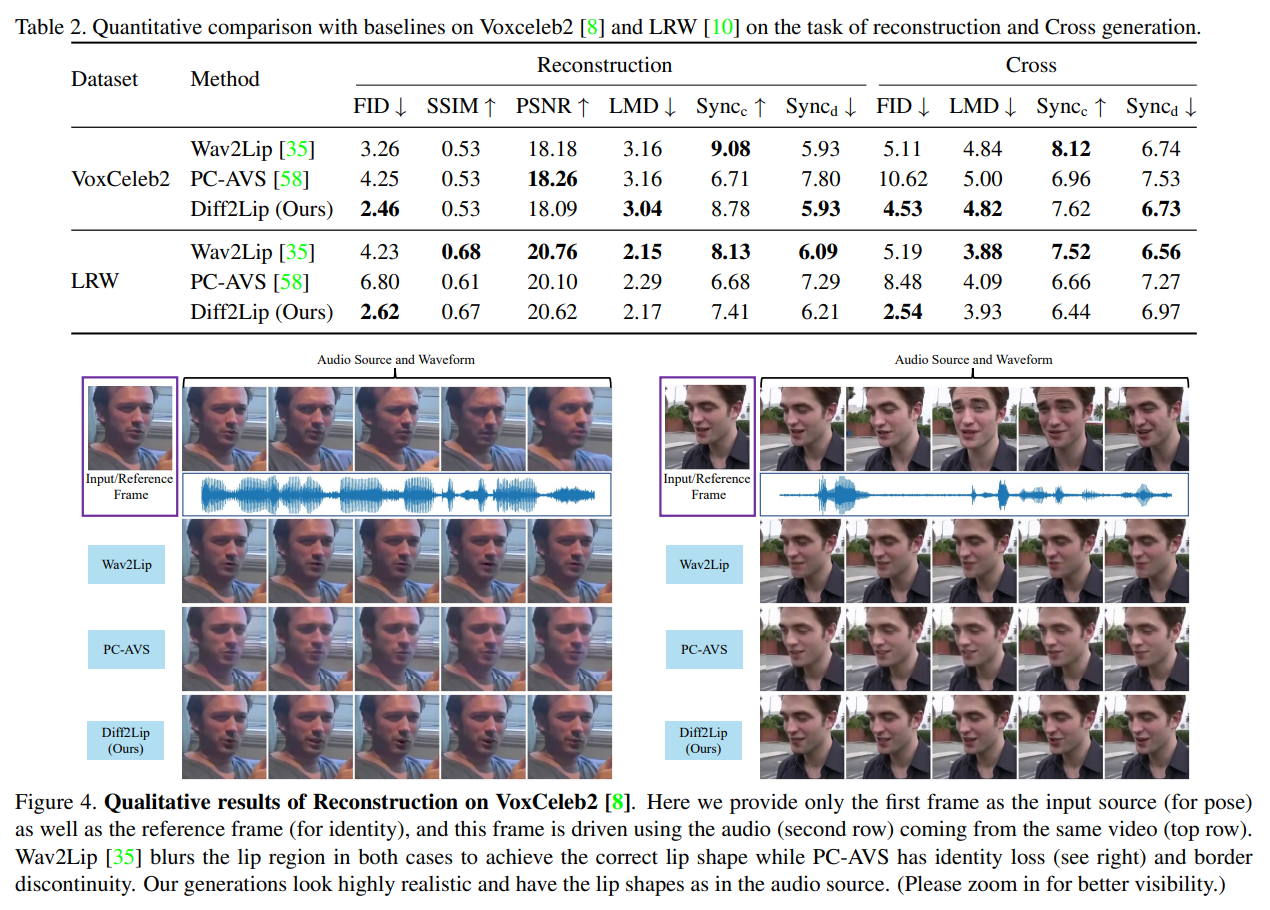
Quantitative Evaluation
평가지표
- 시각적 품질: FID [18], SSIM [53], PSNR.
- FID: 생성된 이미지의 “실제성”을 측정.
- SSIM, PSNR: 픽셀 단위의 이미지 유사성 측정.
- 동기화 품질: LMD [5], Sync_c, Sync_d [9].
- LMD: 프레임 간 입술 랜드마크 거리 측정.
- Sync_c: SyncNet의 신뢰도 점수.
- Sync_d: SyncNet의 비디오와 오디오 표현 간 평균 거리.
Qualitative Evaluation
- 비주얼 비교:
- PC-AVS: 소스 비디오의 정체성을 잃고 경계 불연속성 문제 발생.
- Wav2Lip: 좋은 입술 동기화는 이루어지지만 입술 영역이 흐릿하게 생성.
- Diff2Lip: 고품질의 입술 영역 생성, 자연스러운 입술 움직임 및 정확한 동기화 유지.
- 사용자 연구 (User Study):
- 참여자: 15명.
- 평가 항목: 시각적 품질, 입술 동기화 품질, 전반적 품질 (1-5점).
- 결과: Diff2Lip이 모든 카테고리에서 다른 방법들을 능가.
Ablation Study
