
[논문분석] Scalable Diffusion Models with Transformers : DIT
transformer based Diffusion model. 유행의 시작
[Page , Paper , Code]
William Peebles Saining Xie
DiT에서 사용되는 adaLN의 경우에는 기존 Linear normalization 처럼 직접적으로 learnable하는 것이 아닌, timestep과 label의 embedding을 shift와 scale값으로 활용한다는 것
scale factor a의 초깃값을 zero로 두고 시작
Abstract
We explore a new class of diffusion models based on the transformer architecture. We train latent diffusion models of images, replacing the commonly-used U-Net backbone with a transformer that operates on latent patches. We analyze the scalability of our Diffusion Transformers (DiTs) through the lens of forward pass complexity as measured by Gflops. We find that DiTs with higher Gflops – through increased transformer depth/width or increased number of input tokens – consistently have lower FID. In addition to possessing good scalability properties, our largest DiT-XL/2 models outperform all prior diffusion models on the class-conditional ImageNet 512x512 and 256x256 benchmarks, achieving a state-of-the-art FID of 2.27 on the latter.
Introduction
transformers는 autoregressive models에서는 자주 사용됨. 하지만 generative modeling framework에서는 사용되지 않음
예로 diffusion model에서 U-net이 backbone으로 채택되어 사용되는 추세
확산 모델에서 아키텍처 선택의 중요성을 이해하고 미래 세대 모델링 연구를 위한 경험적 기준을 제공하는 것을 목표 → transformer에 방향성 제시
우리는 U-Net 유도 바이어스가 확산 모델의 성능에 중요하지 않으며, 트랜스포머와 같은 표준 설계로 쉽게 다시 배치할 수 있음을 보여줍니다.
-
U-Net의 유도 편향(Inductive Bias)
### 유도 편향(Inductive Bias)란?
유도 편향이란 모델이 학습 데이터 외의 새로운 데이터에 대해 일반화할 수 있도록 하는 가정이나 선호를 의미합니다. 이는 모델이 특정 방식으로 데이터를 처리하거나 해석하도록 유도하는 구조적 또는 알고리즘적 특징을 포함합니다. 유도 편향은 모델이 문제를 해결하는 데 도움이 되는 방향으로 데이터에서 학습하도록 돕습니다.
### U-Net의 유도 편향
U-Net은 주로 이미지 분할 작업에서 사용되는 딥러닝 모델로, 다음과 같은 구조적 특징을 가지고 있습니다:
- 합성곱 신경망(Convolutional Neural Network, CNN): U-Net은 여러 층의 CNN으로 구성되어 있으며, 이는 이미지의 국소적 특징을 잘 포착합니다.
- 다운샘플링과 업샘플링: U-Net은 이미지의 해상도를 줄여가며 특징을 추출한 후, 다시 해상도를 높여가며 원래 이미지 크기로 복원합니다. 이 과정에서 낮은 해상도에서 학습한 특징들을 결합하여 보다 정교한 출력을 만듭니다.
- 스킵 연결(Skip Connections): 다운샘플링 과정에서 잃어버린 공간적 정보를 보완하기 위해, 입력 이미지의 일부 정보를 업샘플링 과정에 직접 연결하여 사용합니다.
이러한 구조적 특성들은 U-Net이 이미지 분할 문제를 잘 해결할 수 있도록 돕는 유도 편향을 형성합니다. 구체적으로:
- 국소적 패턴 학습: 합성곱 층은 이미지의 작은 영역에서 중요한 특징을 학습할 수 있도록 유도합니다.
- 다중 해상도 학습: 다운샘플링과 업샘플링을 통해 다양한 해상도에서 특징을 추출하고 결합함으로써, 모델이 보다 복잡한 구조적 패턴을 학습할 수 있게 합니다.
- 정보 보존: 스킵 연결을 통해 중요한 공간적 정보를 보존하고, 이를 최종 출력에 활용할 수 있게 합니다.
### 문맥에서의 유도 편향
제시된 문장에서는 “U-Net inductive bias is not crucial to the performance of diffusion models”라고 언급하고 있습니다. 이는 U-Net의 구조적 특성이 확산 모델(Diffusion Model)의 성능에 필수적이지 않다는 의미입니다. 대신, 확산 모델은 트랜스포머와 같은 다른 표준 설계를 사용하여도 비슷한 성능을 발휘할 수 있다는 것을 시사합니다.
즉, 확산 모델이 U-Net의 구조적 편향에 의존하지 않고도 효과적으로 작동할 수 있음을 보여줌으로써, 확산 모델의 설계가 더 유연하고 다른 분야의 최신 기술과 훈련 방법을 쉽게 통합할 수 있는 가능성을 열어줍니다. 이는 모델의 확장성, 견고성 및 효율성을 높일 수 있는 기회를 제공합니다.
### 요약
U-Net의 유도 편향은 이미지 분할 작업에서 중요한 역할을 하지만, 확산 모델에서는 이러한 구조적 특성이 필수적이지 않음을 보여줍니다. 대신, 트랜스포머와 같은 표준 설계를 통해 확산 모델의 성능을 유지하면서도 다른 최신 기술을 통합할 수 있는 유연성을 갖추게 됩니다. 이는 다양한 연구 분야 간의 교차 연구 가능성을 확대하는 데 중요한 의미를 가집니다.
DiT는 기존의 컨볼루션 네트워크(예: ResNet)보다 시각 인식에 더 효과적으로 확장되는 것으로 입증된 비전 트랜스포머(ViT)를 따름
VAE의 잠재 공간 내에서 확산 모델이 훈련되는 잠재 확산 모델(LDM) 프레임워크 하에서 DiT 설계 공간을 구축하고 벤치마킹함으로써 U-Net 백본을 트랜스포머로 성공적으로 대체할 수 있음을 증명
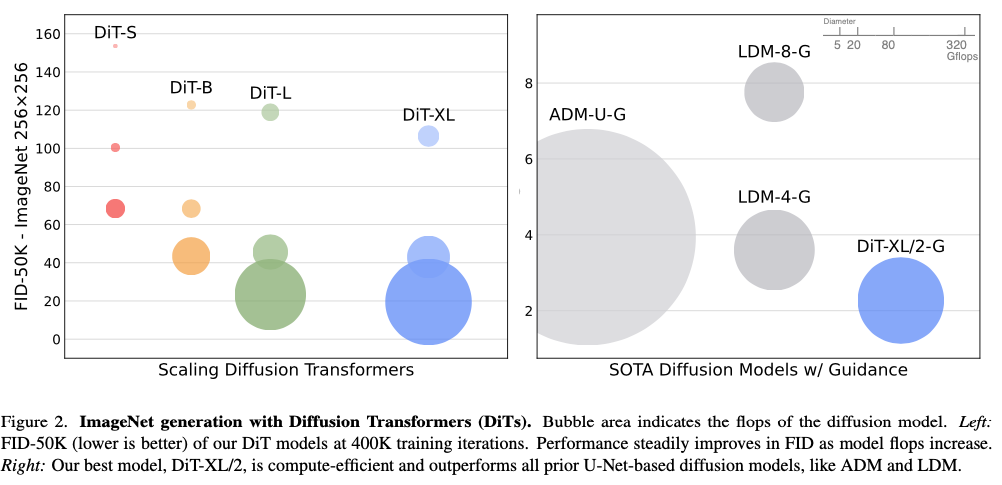
DIT는 학습을 진행할 수록 성능이 좋아짐, U-Net 보다 성능이 좋음
Related Work
Transformers
트랜스포머의 다양한 활용
- 픽셀 예측: 트랜스포머는 자기회귀적으로 픽셀을 예측하도록 훈련될 수 있습니다.
- 이산 코드북: 트랜스포머는 이산 코드북에서 자기회귀 모델과 마스크 생성 모델로 훈련됩니다.
- 자기회귀 모델: 최대 200억 개 파라미터까지 우수한 확장성을 보여줍니다.
- 마스크 생성 모델: 이산 코드북을 활용하여 데이터를 생성합니다.
비공간 데이터의 합성
- DDPMs에서의 활용: 트랜스포머는 확산 모델(DDPMs)에서도 비공간 데이터를 합성하는 데 사용됩니다.
- 예: CLIP 이미지 임베딩 생성: DALL·E 2와 같은 모델에서 트랜스포머는 CLIP 이미지 임베딩을 생성하는 데 활용됩니다.
확장성: 트랜스포머는 모델 크기, 훈련 계산량, 데이터 양이 증가할수록 성능이 향상되는 놀라운 확장성을 보여주었습니다.
도메인-특화 아키텍처 대체: 트랜스포머는 언어, 비전(영상), 강화 학습, 메타 학습 등 여러 분야에서 기존의 도메인-특화 아키텍처를 대체하고 있습니다.
normalization이란?
[딥러닝] 정규화? 표준화? Normalization? Standardization? Regularization?
Linear normalization은 데이터를 일정한 범위나 분포로 변환하여 모델의 학습을 도와주는 중요한 전처리 기법
이는 각 데이터 포인트를 개별적으로 정규화하는 대신, 레이어 내의 모든 뉴런에 대해 동일하게 정규화를 수행합니다.
Linear Normalization
\[x' = \frac{x - \min(x)}{\max(x) - \min(x)}\]- x는 원래의 데이터 값
- x′는 정규화된 값
Adaptive Layer Normalization (adaLN)
\[\hat{x}_i = \frac{x_i - \mu}{\sqrt{\sigma^2 + \epsilon}} \ \ \ \ \ , \ \ \ y_i = \gamma \hat{x}_i + \beta\]- \(x_i\) 는 레이어의 입력 값
- \(\hat{x}_i\) 는 정규화된 값
- μ는 입력 값의 평균
- σ는 입력 값의 표준 편차
- ϵ은 수치적 안정성을 위한 작은 값
-
γ와 β는 학습 가능한 파라미터
-
차이
Adaptive Layer Normalization (adaLN)이 Linear Normalization보다 갖는 장점은 다음과 같습니다:
- 동적 스케일링:
- Linear Normalization은 데이터를 고정된 범위 내에서 선형적으로 스케일링하며, 이는 모든 데이터셋이나 신경망 레이어에 적합하지 않을 수 있습니다.
- adaLN은 레이어의 통계값을 기반으로 데이터를 동적으로 스케일링하여 다양한 데이터 분포에 대한 유연성과 적응력을 제공합니다.
- 비정상 데이터 처리:
- Linear Normalization은 데이터 분포가 일정하다고 가정하지만, 이는 신경망의 다양한 레이어에서 항상 성립하지 않을 수 있습니다.
- adaLN은 다양한 레이어와 학습 반복에서 변화하는 데이터 분포에 적응할 수 있어 더 안정적인 성능을 제공합니다.
- 내부 공변량 변화 감소:
- Linear Normalization은 학습 중 레이어로 들어오는 입력의 분포가 변하는 내부 공변량 변화 문제를 해결하지 못합니다.
- adaLN은 입력을 평균과 분산으로 정규화하여 내부 공변량 변화를 줄여, 더 빠른 수렴과 안정적인 학습을 돕습니다.
- 학습 가능한 매개변수 (γ와 β):
- Linear Normalization은 학습 가능한 매개변수가 없어 정규화된 출력을 조정하는 데 유연성이 떨어집니다.
- adaLN은 학습 가능한 매개변수 (γ와 β)를 포함하여 정규화된 데이터의 스케일과 시프트를 조정할 수 있어 학습 과정 최적화에 추가적인 자유도를 제공합니다.
- 작은 배치 크기에 대한 견고성:
- Linear Normalization은 이상치나 작은 배치 크기에 민감할 수 있어 최적의 정규화가 어려울 수 있습니다.
- adaLN은 레이어별 통계값을 사용하여 정규화하므로 배치 크기의 변동과 이상치에 대해 더 견고하게 작동합니다.
전반적으로 Adaptive Layer Normalization은 특히 딥러닝 모델의 맥락에서 더 나은 성능과 안정성을 제공하는 보다 견고하고 유연한 정규화 방법입니다.
- 동적 스케일링:
Diffusion Transformers
Diffusion formulation
Diffusion Formulation
Diffusion model은 실제 데이터 \(x_0\)에 점진적으로 noise를 적용하는 forward process를 가정한다.
\[q(x_t \mid x_0) = \mathcal{N}(x_t; \sqrt{\bar{\alpha}_t} x_0, (1 - \bar{\alpha}_t) \mathbf{I})\]Reparameterization trick을 적용하면 다음과 같이 샘플링할 수 있다.
\[x_t = \sqrt{\bar{\alpha}_t} x_0 + \sqrt{1 - \bar{\alpha}_t} \epsilon_t, \quad \epsilon_t \sim \mathcal{N}(0, \mathbf{I})\]Diffusion model은 forward process를 반전시키는 reverse process를 학습한다.
\[p_{\theta}(x_{t-1} \mid x_t) = \mathcal{N}(x_{t-1}; \mu_{\theta}(x_t), \Sigma_{\theta}(x_t))\]여기서 신경망은 \(p_{\theta}\)의 통계들을 예측하는 데 사용된다. Reverse process 모델은 log-likelihood의 변동(VLB)으로 학습되며, 이는 다음과 같이 줄일 수 있다.
\[\mathcal{L}(\theta) = -p(x_0 \mid x_1) + \sum_t D_{\text{KL}} \left( q^*(x_{t-1} \mid x_t, x_0) \parallel p_{\theta}(x_{t-1} \mid x_t) \right)\]\(q^*\)와 \(p_{\theta}\)는 모두 가우시안이기 때문에 \(D_{\text{KL}}\)은 두 분포의 평균과 공분산으로 평가할 수 있다. \(\mu_{\theta}\)를 noise 예측 네트워크 \(\epsilon_{\theta}\)로 다시 parameterize하면 예측된 noise \(\epsilon_{\theta}(x_t)\)와 샘플링된 ground-truth Gaussian noise \(\epsilon_t\) 사이의 단순한 MSE 제공 오차를 사용하여 모델을 학습할 수 있다.
\[\mathcal{L}{\text{simple}}(\theta) = \| \epsilon{\theta}(x_t) - \epsilon_t \|_2^2\]그러나 학습된 reverse process 공분산 \(\Sigma_{\theta}\)를 diffusion model로 학습하려면 전체 \(D_{\text{KL}}\) 함을 최적화해야 한다. 저자들은 ADM의 접근 방식을 따른다. \(\mathcal{L}{\text{simple}}\)로 \(\epsilon{\theta}\)를 학습하고 전체 \(\Sigma_{\theta}\)를 학습한다. \(p_{\theta}\)가 학습된 후 \(t_{\text{max}}\)에서 \(x_{t-1} \sim p_{\theta}(x_{t-1} \mid x_t)\)를 샘플링하여 새 이미지를 샘플링할 수 있다.
Classifier-free Guidance
Conditional diffusion model은 클래스 레이블 c와 같은 추가 정보를 입력으로 사용한다. 이 경우 reverse process는 \(p_{\theta}(x_{t-1} \mid x_t, c)\)가 되며, 여기서 \(\epsilon_{\theta}\)와 \(\Sigma_{\theta}\)는 c로 컨디셔닝된다. 이 설정에서 classifier-free guidance를 사용하여 샘플링 절차가 \(\log p(c \mid x)\)가 높은 x를 찾도록 장려할 수 있다. 베이즈 정리에 따라
\[\log p(c \mid x) \propto \log p(x \mid c) - \log p(x)\]이고, 따라서
\[\nabla_x \log p(c \mid x) \propto \nabla_x \log p(x \mid c) - \nabla_x \log p(x) \]이다. Diffusion model의 출력을 score function으로 해석하면 DDPM 샘플링 절차는 다음과 같이 \(p(x \mid c)\)가 높은 샘플 x로 유도할 수 있다.
\[\hat{\epsilon}{\theta}(x_t, c) = \epsilon{\theta}(x_t) + s \cdot \nabla_x \log p(x \mid c) \propto \epsilon_{\theta}(x_t) + s \cdot (\epsilon_{\theta}(x_t, c) - \epsilon_{\theta}(x_t, \varnothing))\]여기서 s > 1은 guidance의 척도를 나타낸다. \(c = \varnothing\)로 diffusion model을 평가하는 것은 학습 중에 c를 임의로 삭제하고 학습된 “null” 임베딩 \(\varnothing\)으로 대체하여 수행된다. Classifier-free guidance는 일반 샘플링 기술에 비해 상당히 선호된 샘플을 생성하는 것으로 널리 알려져 있으며 이러한 추세는 DiT 모델에도 적용된다.
Latent diffusion models.
(1) 학습된 인코더 E를 사용하여 이미지를 더 작은 공간 표현으로 압축하는 자동 인코더를 학습
(2) 이미지 x의 확산 모델 대신 표현 z = E(x)의 확산 모델을 학습합니다(E는 고정됨)
(3) 확산 모델에서 표현 z를 샘플링한 다음 학습된 디코더 x = D(z)를 사용하여 이미지로 디코딩
- ADM: Pixel Space Diffusion Model인 ADM(Adaptive Diffusion Model)은 픽셀 수준에서 작동하며, 계산 복잡도가 높습니다.
-
LDMs: Latent Diffusion Models는 잠재 공간에서 작동하여 더 적은 계산 리소스를 사용하면서도 높은 성능을 유지합니다.
-
Gflops (Giga Floating-point Operations Per Second)
Gflops는 “Giga Floating-point Operations Per Second”의 약자로, 초당 수행할 수 있는 수십억 개의 부동 소수점 연산의 수를 의미합니다. 이는 컴퓨터나 딥러닝 모델의 성능을 측정하는 데 자주 사용되는 단위입니다. 1 Gflops는 초당 10억 개의 부동 소수점 연산을 수행할 수 있음을 나타냅니다.
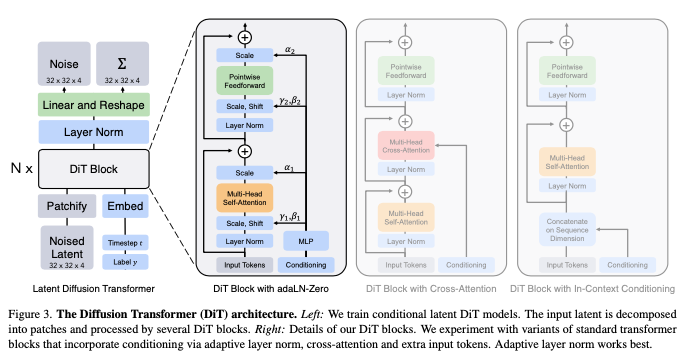
Diffusion Transformer Design Space
Patchify
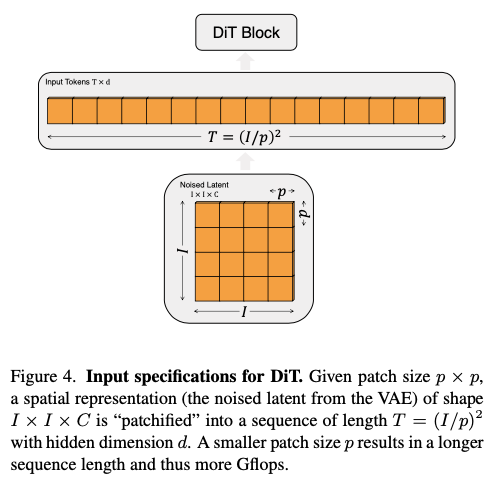
- 입력 형태:
- 예를 들어, 256 × 256 × 3 이미지의 경우, 입력 z의 형태는 32 × 32 × 4입니다.
- Patchify 작업:
- Patchify는 공간적 입력을 시퀀스 형태의 T 개의 토큰으로 변환합니다. 각 토큰의 차원은 d입니다.
- 이를 위해 입력의 각 패치를 선형 임베딩하여 토큰으로 변환합니다.
- 포지셔널 임베딩:
- Patchify 후, 표준 ViT의 주파수 기반 포지셔널 임베딩(사인-코사인 버전)을 모든 입력 토큰에 적용합니다.
- 토큰 수 TT:
- Patchify에 의해 생성되는 토큰 수 T는 패치 크기 하이퍼파라미터 p에 의해 결정됩니다.
- p를 반으로 줄이면 T는 4배가 되며, 이는 총 트랜스포머 Gflops를 최소 4배 증가시킵니다.
- p를 변경해도 모델의 파라미터 수에는 의미 있는 영향을 미치지 않습니다.
- 디자인 스페이스:
- DiT 디자인 스페이스에 p=2,4,8을 추가합니다.
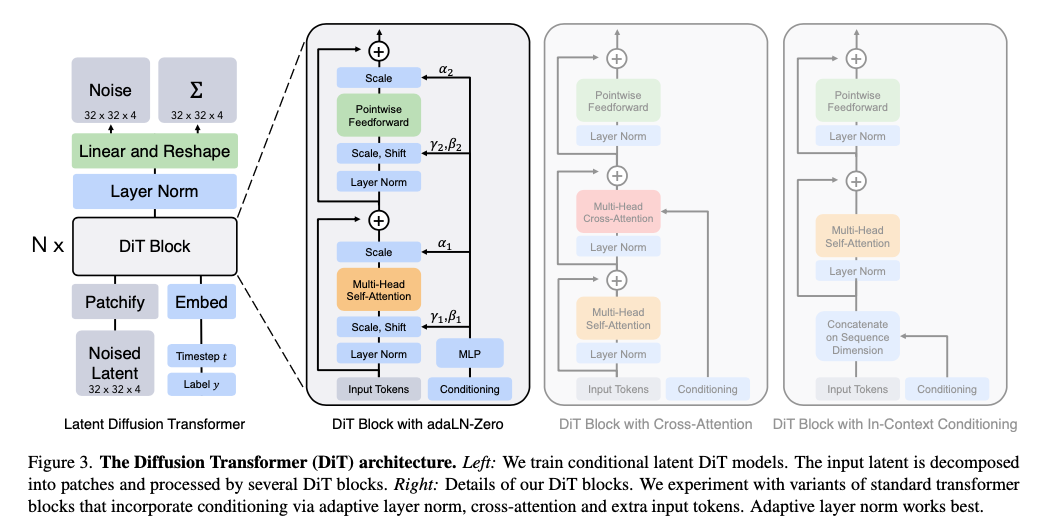
DiT block design
조건부 입력을 다르게 처리하는 네 가지 변형 트랜스포머 블록
- In-context Conditioning:
- t 와 c 의 벡터 임베딩을 입력 시퀀스에 두 개의 추가 토큰으로 단순히 추가합니다. 이는 ViTs의 cls 토큰과 유사하며, 표준 ViT 블록을 수정 없이 사용할 수 있습니다. 최종 블록 이후 조건부 토큰을 시퀀스에서 제거합니다.
- 이 접근 방식은 모델에 새로운 Gflops를 거의 추가하지 않습니다.
- Cross-attention Block:
- t 와 c 의 임베딩을 이미지 토큰 시퀀스와 별도로 길이 2의 시퀀스로 연결합니다. 트랜스포머 블록은 멀티-헤드 셀프 어텐션 블록 다음에 추가 멀티-헤드 크로스-어텐션 레이어를 포함하도록 수정됩니다.
- 크로스 어텐션은 모델에 가장 많은 Gflops를 추가하며, 약 15%의 오버헤드를 가집니다.
- Adaptive Layer Norm (adaLN) Block:
- GANs와 U-Net 백본을 사용하는 확산 모델에서 널리 사용되는 적응형 정규화 레이어를 따라, 표준 레이어 노름 레이어를 적응형 레이어 노름으로 대체합니다. 각 토큰에 동일한 기능을 적용하는 유일한 조건부 메커니즘입니다.
- adaLN은 세 가지 블록 디자인 중 가장 적은 Gflops를 추가하며, 따라서 가장 계산 효율적입니다.
- adaLN-Zero Block:
- 이전 연구에서 각 잔차 블록을 ID 함수로 초기화하는 것이 유익하다는 것을 발견했습니다. 예를 들어, 최종 배치 노름 스케일 팩터 \(\gamma\) 를 0으로 초기화하는 것은 대규모 훈련을 가속화합니다. Diffusion U-Net 모델은 각 블록의 최종 컨볼루션 레이어를 0으로 초기화합니다.
- adaLN DiT 블록의 수정으로, 각 블록의 잔차 연결 이전에 차원별 스케일링 매개변수 \(\alpha\) 를 추가로 회귀합니다.
위의 네 가지 블록 디자인(In-context, Cross-attention, Adaptive Layer Norm, adaLN-Zero)을 DiT 디자인 스페이스에 포함합니다.
adaLN-Zero Block 설명
adaLN-Zero 블록은 이전의 ResNet 연구에서 발견된 잔차 블록 초기화 방법을 활용하는 DiT(Diffusion Transformer) 블록의 변형입니다. 이 블록은 모델 훈련의 효율성을 높이기 위해 설계되었습니다.
기본 아이디어
- Identity Function 초기화: 이전 ResNet 연구에 따르면, 각 잔차 블록을 ID 함수(Identity Function)로 초기화하는 것이 유익하다는 것을 발견했습니다.
- 예를 들어, Goyal et al.의 연구에서는 각 블록의 최종 배치 노름 스케일 팩터 ( \gamma )를 0으로 초기화하면 대규모 지도 학습 훈련이 가속화된다는 것을 보여주었습니다.
- Diffusion U-Net 모델에서도 유사한 초기화 전략을 사용하여 각 블록의 최종 컨볼루션 레이어를 잔차 연결 이전에 0으로 초기화합니다.
adaLN-Zero 블록의 설계
- 기존의 adaLN 블록:
- adaLN 블록에서는 표준 레이어 노름을 적응형 레이어 노름(adaptive layer norm)으로 대체하여, 차원별 스케일(γ)과 시프트(β) 파라미터를 조건부 정보(t와 c의 임베딩 벡터 합)로부터 회귀합니다.
- adaLN-Zero 블록의 추가 요소:
- 차원별 스케일링 파라미터 α 추가: 잔차 연결 이전에 차원별 스케일링 파라미터 α를 추가로 회귀합니다.
- α 초기화: MLP(다층 퍼셉트론)를 통해 모든 α의 출력을 0 벡터로 초기화합니다. 이렇게 하면 전체 DiT 블록이 ID 함수로 초기화됩니다.
- 파라미터 초기화: 이 초기화 방법을 통해 모델 훈련 초기 단계에서 안정적인 학습이 가능합니다.
- 계산 효율성:
- Gflops 추가 없음: 기본 adaLN 블록과 마찬가지로 adaLN-Zero 블록은 모델에 새로운 Gflops를 거의 추가하지 않습니다. 이는 모델의 계산 효율성을 유지하면서도 훈련 효율성을 높이는 데 도움이 됩니다.
요약
- Identity Function 초기화: 잔차 블록을 ID 함수로 초기화하는 것은 모델 훈련의 초기 단계에서 안정성을 높이고 학습을 가속화합니다.
- α 파라미터 회귀: 잔차 연결 이전에 추가로 차원별 스케일링 파라미터 α를 회귀합니다.
- 계산 효율성 유지: adaLN-Zero 블록은 기본 adaLN 블록과 마찬가지로 Gflops를 거의 추가하지 않으므로 계산 효율성을 유지합니다.
adaLN-Zero 블록은 모델 훈련 초기 단계에서 안정성을 높이고 학습을 가속화하는 동시에, 계산 자원의 효율성을 유지하는 데 중점을 둔 설계입니다.
기존 LayerNorm의 경우, channel 단위로 normalization을 진행하고, learnable parameters인 shift와 scale를 활용했다.
그러나, DiT에서 사용되는 adaLN의 경우에는 직접적으로 learnable하는 것이 아닌, timestep과 label의 embedding을 shift와 scale값으로 활용한다는 것이다!
잔차 블록을 항등 함수(identity function)로 초기화하면 훈련이 가속화되는 이유는 주로 신경망의 안정성과 기울기 흐름에 긍정적인 영향을 미치기 때문입니다
- 구조 및 학습 방법:
- γ와 β 파라미터 회귀: adaLN 블록과 마찬가지로 γ와 β 파라미터를 임베딩 벡터의 합으로부터 회귀합니다.
- α 파라미터 추가: 잔차 연결 이전에 적용되는 추가적인 스케일링 파라미터 α도 회귀하여 학습합니다. 이는 잔차 블록의 출력을 스케일링하는 역할을 합니다.
- 잔차 블록 초기화: 각 잔차 블록을 항등 함수로 초기화하여 초기 훈련 단계에서 안정적이고 빠른 수렴을 도모합니다.
- 잔차 초기화 부분은 DiT Block with adaLN-Zero 블록 내의 Multi-Head Self-Attention과 Pointwise Feedforward 후에 위치한 스케일링 파라미터 α1과 α2에 해당
-
residual block 초기화란?
스케일 파라미터 α를 0으로 초기화하면, 각 레이어의 출력이 0이 되어 입력값이 잔차 연결을 통해 그대로 전달됩니다. 이는 초기 학습 단계에서 모델이 항등 함수처럼 작동하도록 만들어 안정적인 학습을 도와줍니다. 단순히 파라미터를 곱해주는 것뿐만 아니라, 이를 적절히 초기화함으로써 이러한 효과를 얻을 수 있습니다.
### 항등 함수 초기화의 효과:
- 안정적인 학습: 초기 학습 단계에서 모델이 큰 변화를 일으키지 않고 안정적으로 학습할 수 있도록 도와줍니다.
- 기울기 소실 문제 완화: 초기에는 기울기가 안정적으로 전달되어 기울기 소실 문제를 줄입니다.
- 훈련 속도 향상: 안정적인 학습 덕분에 모델이 더 빠르게 수렴할 수 있습니다.
우리가 이전에 읽었던 controlnet 논문에서 zero-convolution 개념과 동일
그렇다면 adaLN-Zero는 무엇인가!? 아래에 순차적으로 설명해보겠다.
1. adaLN은 각 2개의 shift와 scale factor가 필요했다. 즉 총 4개의 embedding vector가 MLP로 출력되는 것이다.
-
그러나 adaLN-Zero는 scale factor a를 추가하여서 총 6개의 output이 나오도록 모델 구조를 설계하였다.
-
또한 이 scale factor a의 초깃값을 zero로 두고 시작하기 때문에, adaLN-Zero라고 이름이 붙였다.
(Zero로 시작하는 이유는, Goyal et al. 논문의 연구를 참고했다고 언급하고 있다.)
또한 a가 0이기 때문에 input_tokens 값만 살아남게 되므로, 논문에서 언급하는 것처럼, 처음 DiT block은 identity function이다.
모델 크기
DiT 블록의 시퀀스를 N 개 적용하고, 각 블록은 숨겨진 차원 크기 d 에서 작동합니다. 표준 트랜스포머 설정을 사용하여 N , d , 어텐션 헤드를 공동으로 스케일링합니다. 네 가지 설정(DiT-S, DiT-B, DiT-L, DiT-XL)을 사용하여 모델 크기와 flop 할당을 측정합니다. Table 1에서 설정의 세부 사항을 제공합니다.
트랜스포머 디코더
최종 DiT 블록 이후, 이미지 토큰 시퀀스를 출력 노이즈 예측 및 대각 공분산 예측으로 디코딩해야 합니다. 이 두 출력은 원래 공간 입력과 동일한 형태를 가집니다. 표준 선형 디코더를 사용하여 최종 레이어 노름(adaLN을 사용하는 경우 적응형) 및 각 토큰을 \(p \times p \times 2C\) 텐서로 선형 디코딩합니다. 마지막으로, 디코딩된 토큰을 원래 공간 레이아웃으로 재배치하여 예측된 노이즈와 공분산을 얻습니다.
마지막은 Transformer Decoder이다.
굉장히 쉬운 내용이다.
LayerNorm 적용하고, linear와 reshape을 적용한 다음에 각 patch size (pxp)마다 기존 channel size의 2배가 되는 output을 출력한다.
따라서 output은 위에서 보는 것처럼, 예측된 noise 값과 covariance 값이다.
그 이후, VAE decoder에 noise 값을 넣어서 실제 이미지를 생성한다.
여기서 추가적으로, 왜 covariance를 생성하는지 한번 얘기해볼까 한다.
사실 이 내용은, DiT 이전에 classifier-guidance에 소개된 ADM과 연관이 있다.
ADM의 경우 DDPM 처럼 noise간의 차이만 loss로 이용한 것이 아니라, 분산도 학습을 진행했다.
또한 분산에 대한 loss로 vlb_loss를 활용한다. (VLB: variational lower bound)
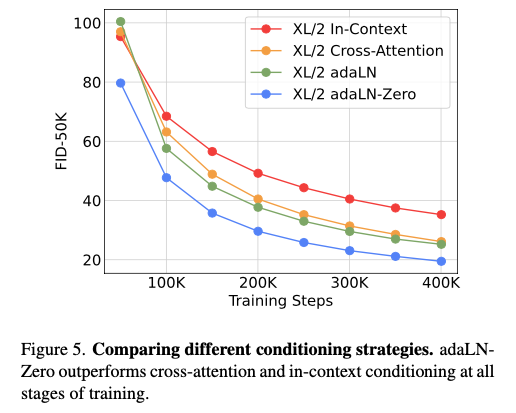
자세한 내용은 위의 이미지를 참고하면 좋다!
(또는 Improved Denoising Diffusion Probabilistic Models 논문 참고)
결론
완전한 DiT 디자인 스페이스는 패치 크기, 트랜스포머 블록 아키텍처 및 모델 크기를 포함합니다.

Code
-
TimestepEmbedder
class TimestepEmbedder(nn.Module): """ Embeds scalar timesteps into vector representations. """ def __init__(self, hidden_size, frequency_embedding_size=256): super().__init__() self.mlp = nn.Sequential( nn.Linear(frequency_embedding_size, hidden_size, bias=True), nn.SiLU(), nn.Linear(hidden_size, hidden_size, bias=True), ) self.frequency_embedding_size = frequency_embedding_size @staticmethod def timestep_embedding(t, dim, max_period=10000): """ Create sinusoidal timestep embeddings. :param t: a 1-D Tensor of N indices, one per batch element. These may be fractional. :param dim: the dimension of the output. :param max_period: controls the minimum frequency of the embeddings. :return: an (N, D) Tensor of positional embeddings. """ # https://github.com/openai/glide-text2im/blob/main/glide_text2im/nn.py half = dim // 2 freqs = torch.exp( -math.log(max_period) * torch.arange(start=0, end=half, dtype=torch.float32) / half ).to(device=t.device) args = t[:, None].float() * freqs[None] embedding = torch.cat([torch.cos(args), torch.sin(args)], dim=-1) if dim % 2: embedding = torch.cat([embedding, torch.zeros_like(embedding[:, :1])], dim=-1) return embedding def forward(self, t): t_freq = self.timestep_embedding(t, self.frequency_embedding_size) t_emb = self.mlp(t_freq) return t_emb코드에서
timestep_embedding이후에 MLP(Multi-Layer Perceptron)를 거치는 이유를 설명해드리겠습니다.### 코드 개요
주어진 코드에서
TimestepEmbedder클래스는 스칼라 형태의 timestep을 벡터 형태의 표현으로 임베딩하는 역할을 합니다. 이 클래스는 두 가지 주요 구성 요소로 나뉩니다:- Sinusoidal Timestep Embedding: 주어진 timestep을 주기적(sinusoidal) 함수를 사용하여 고차원 벡터로 변환합니다.
- MLP: 생성된 주기적 임베딩을 다층 퍼셉트론을 통해 추가적으로 처리합니다.
### 각 단계의 역할
- Sinusoidal Timestep Embedding:
- 함수
timestep_embedding은 주어진 timestep ( t )을 sinusoidal 함수를 이용해 고차원 벡터로 변환합니다. 이 임베딩은 주로 transformer와 같은 모델에서 사용되며, 시간 또는 위치 정보를 효과적으로 인코딩하는 데 사용됩니다. - 여기서 주파수 ( \text{freqs} )는 다양한 주기를 가지는 sin과 cos 함수를 통해 timestep을 다양한 주기로 인코딩합니다. 이는 시간 또는 위치 정보를 효과적으로 캡처하기 위한 것입니다.
- 함수
- MLP:
- Sinusoidal 임베딩 후, 벡터는 MLP에 전달됩니다. MLP는 두 개의 선형 변환과 SiLU (Sigmoid Linear Unit) 활성화 함수로 구성됩니다.
- 이유:
- 복잡한 변환 학습: 주기적 함수로 변환된 임베딩은 고정된 주파수를 가지지만, MLP를 통해 더욱 복잡하고 비선형적인 변환을 학습할 수 있습니다. 이는 모델이 timestep에 대해 더 복잡한 패턴을 학습할 수 있게 합니다.
- 유연성: MLP는 가중치 학습을 통해 데이터에 맞게 조정될 수 있습니다. 이는 timestep 임베딩이 단순한 주기적 패턴을 넘어서 데이터의 특성에 맞는 임베딩으로 변환될 수 있게 합니다.
- 표현력 증가: MLP를 통해 입력 임베딩의 표현력을 증가시켜 모델의 성능을 향상시킬 수 있습니다.
### 종합
timestep_embedding이후 MLP를 거치는 이유는 주기적 함수를 통해 생성된 기본 임베딩을 더 복잡하고 유연하게 변환하기 위함입니다. 이를 통해 모델이 timestep에 대한 더 풍부한 표현을 학습할 수 있으며, 이는 궁극적으로 모델의 성능 향상에 기여할 수 있습니다. -
LabelEmbedder
class LabelEmbedder(nn.Module): """ Embeds class labels into vector representations. Also handles label dropout for classifier-free guidance. """ def __init__(self, num_classes, hidden_size, dropout_prob): super().__init__() use_cfg_embedding = dropout_prob > 0 self.embedding_table = nn.Embedding(num_classes + use_cfg_embedding, hidden_size) self.num_classes = num_classes self.dropout_prob = dropout_prob def token_drop(self, labels, force_drop_ids=None): """ Drops labels to enable classifier-free guidance. """ if force_drop_ids is None: drop_ids = torch.rand(labels.shape[0], device=labels.device) < self.dropout_prob else: drop_ids = force_drop_ids == 1 labels = torch.where(drop_ids, self.num_classes, labels) return labels def forward(self, labels, train, force_drop_ids=None): use_dropout = self.dropout_prob > 0 if (train and use_dropout) or (force_drop_ids is not None): labels = self.token_drop(labels, force_drop_ids) embeddings = self.embedding_table(labels) return embeddings주어진 코드에서
LabelEmbedder클래스는 레이블을 벡터 표현으로 임베딩하는 역할을 합니다. 이 클래스는 특히 classifier-free guidance를 위한 레이블 드롭아웃도 처리합니다. 이와 달리,TimestepEmbedder에서는 timestep 임베딩 후 MLP를 통과합니다. 이제 레이블 임베딩에서는 MLP를 사용하지 않는 이유를 설명하겠습니다.###
LabelEmbedder설명- Embedding Table:
nn.Embedding을 사용하여 각 레이블을 고정된 크기의 벡터로 매핑합니다. 임베딩 테이블은 레이블마다 하나의 고차원 벡터를 할당합니다.
- Label Dropout:
token_drop메서드는 classifier-free guidance를 위해 레이블을 드롭하는 역할을 합니다. 드롭된 레이블은 특별한 “null” 레이블로 대체됩니다.- 레이블 드롭아웃을 통해 모델이 특정 레이블 없이도 작동할 수 있도록 합니다. 이는 레이블에 대한 의존성을 줄이고 모델의 일반화 능력을 높입니다.
### Label 임베딩에서 MLP를 사용하지 않는 이유
- 단순한 임베딩 요구사항:
- 레이블 임베딩은 각 레이블에 대해 고정된 벡터를 할당하는 작업입니다. 이는 주로 분류 문제에서 각 클래스가 고유한 벡터를 가지도록 하기 위함입니다.
- 레이블 임베딩은 레이블 간의 관계나 시간적 변화를 표현할 필요가 없기 때문에 단순히 고정된 임베딩 벡터만으로 충분합니다.
- 고정된 의미:
- 레이블은 고정된 의미를 가지며, 이는 학습 과정에서 변하지 않습니다. 따라서 레이블 임베딩은 단순히 고유한 벡터를 할당하는 것으로 충분합니다.
- 레이블 임베딩 벡터는 학습 과정에서 업데이트되지만, 임베딩 자체는 각 레이블의 고유한 표현을 유지합니다.
- 복잡한 변환 불필요:
- 레이블 임베딩의 목적은 레이블을 고차원 벡터로 변환하는 것이므로, 추가적인 복잡한 변환(Multi-Layer Perceptron)은 필요하지 않습니다.
- 레이블 간의 관계나 패턴을 학습하는 것이 아니라, 고유한 벡터로 변환하는 것이 목적이기 때문에 MLP를 거치지 않아도 됩니다.
### 종합
모델 구조를 보면 Label embedding이후 time embedding을 순차적으로 진행 따라서 두개를 합친후 MLP로 고차원 변환
- Embedding Table:
DET block
class DiTBlock(nn.Module):
"""
A DiT block with adaptive layer norm zero (adaLN-Zero) conditioning.
"""
def __init__(self, hidden_size, num_heads, mlp_ratio=4.0, **block_kwargs):
super().__init__()
self.norm1 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
self.attn = Attention(hidden_size, num_heads=num_heads, qkv_bias=True, **block_kwargs)
self.norm2 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
mlp_hidden_dim = int(hidden_size * mlp_ratio)
approx_gelu = lambda: nn.GELU(approximate="tanh")
self.mlp = Mlp(in_features=hidden_size, hidden_features=mlp_hidden_dim, act_layer=approx_gelu, drop=0)
self.adaLN_modulation = nn.Sequential(
nn.SiLU(),
nn.Linear(hidden_size, 6 * hidden_size, bias=True)
)
def forward(self, x, c):
shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.adaLN_modulation(c).chunk(6, dim=1)
x = x + gate_msa.unsqueeze(1) * self.attn(modulate(self.norm1(x), shift_msa, scale_msa))
x = x + gate_mlp.unsqueeze(1) * self.mlp(modulate(self.norm2(x), shift_mlp, scale_mlp))
return x
-
FinalLayer
class FinalLayer(nn.Module): """ The final layer of DiT. """ def __init__(self, hidden_size, patch_size, out_channels): super().__init__() self.norm_final = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6) self.linear = nn.Linear(hidden_size, patch_size * patch_size * out_channels, bias=True) self.adaLN_modulation = nn.Sequential( nn.SiLU(), nn.Linear(hidden_size, 2 * hidden_size, bias=True) ) def forward(self, x, c): shift, scale = self.adaLN_modulation(c).chunk(2, dim=1) x = modulate(self.norm_final(x), shift, scale) x = self.linear(x) return x
DiT
class DiT(nn.Module):
"""
Diffusion model with a Transformer backbone.
"""
def __init__(
self,
input_size=32,
patch_size=2,
in_channels=4,
hidden_size=1152,
depth=28,
num_heads=16,
mlp_ratio=4.0,
class_dropout_prob=0.1,
num_classes=1000,
learn_sigma=True,
):
super().__init__()
self.learn_sigma = learn_sigma
self.in_channels = in_channels
self.out_channels = in_channels * 2 if learn_sigma else in_channels
self.patch_size = patch_size
self.num_heads = num_heads
self.x_embedder = PatchEmbed(input_size, patch_size, in_channels, hidden_size, bias=True)
self.t_embedder = TimestepEmbedder(hidden_size)
self.y_embedder = LabelEmbedder(num_classes, hidden_size, class_dropout_prob)
num_patches = self.x_embedder.num_patches
# Will use fixed sin-cos embedding:
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches, hidden_size), requires_grad=False)
self.blocks = nn.ModuleList([
DiTBlock(hidden_size, num_heads, mlp_ratio=mlp_ratio) for _ in range(depth)
])
self.final_layer = FinalLayer(hidden_size, patch_size, self.out_channels)
self.initialize_weights()
def initialize_weights(self):
# Initialize transformer layers:
def _basic_init(module):
if isinstance(module, nn.Linear):
torch.nn.init.xavier_uniform_(module.weight)
if module.bias is not None:
nn.init.constant_(module.bias, 0)
self.apply(_basic_init)
# Initialize (and freeze) pos_embed by sin-cos embedding:
pos_embed = get_2d_sincos_pos_embed(self.pos_embed.shape[-1], int(self.x_embedder.num_patches ** 0.5))
self.pos_embed.data.copy_(torch.from_numpy(pos_embed).float().unsqueeze(0))
# Initialize patch_embed like nn.Linear (instead of nn.Conv2d):
w = self.x_embedder.proj.weight.data
nn.init.xavier_uniform_(w.view([w.shape[0], -1]))
nn.init.constant_(self.x_embedder.proj.bias, 0)
# Initialize label embedding table:
nn.init.normal_(self.y_embedder.embedding_table.weight, std=0.02)
# Initialize timestep embedding MLP:
nn.init.normal_(self.t_embedder.mlp[0].weight, std=0.02)
nn.init.normal_(self.t_embedder.mlp[2].weight, std=0.02)
# Zero-out adaLN modulation layers in DiT blocks:
for block in self.blocks:
nn.init.constant_(block.adaLN_modulation[-1].weight, 0)
nn.init.constant_(block.adaLN_modulation[-1].bias, 0)
# Zero-out output layers:
nn.init.constant_(self.final_layer.adaLN_modulation[-1].weight, 0)
nn.init.constant_(self.final_layer.adaLN_modulation[-1].bias, 0)
nn.init.constant_(self.final_layer.linear.weight, 0)
nn.init.constant_(self.final_layer.linear.bias, 0)
def unpatchify(self, x):
"""
x: (N, T, patch_size**2 * C)
imgs: (N, H, W, C)
"""
c = self.out_channels
p = self.x_embedder.patch_size[0]
h = w = int(x.shape[1] ** 0.5)
assert h * w == x.shape[1]
x = x.reshape(shape=(x.shape[0], h, w, p, p, c))
x = torch.einsum('nhwpqc->nchpwq', x)
imgs = x.reshape(shape=(x.shape[0], c, h * p, h * p))
return imgs
def forward(self, x, t, y):
"""
Forward pass of DiT.
x: (N, C, H, W) tensor of spatial inputs (images or latent representations of images)
t: (N,) tensor of diffusion timesteps
y: (N,) tensor of class labels
"""
x = self.x_embedder(x) + self.pos_embed # (N, T, D), where T = H * W / patch_size ** 2
t = self.t_embedder(t) # (N, D)
y = self.y_embedder(y, self.training) # (N, D)
c = t + y # (N, D)
for block in self.blocks:
x = block(x, c) # (N, T, D)
x = self.final_layer(x, c) # (N, T, patch_size ** 2 * out_channels)
x = self.unpatchify(x) # (N, out_channels, H, W)
return x
def forward_with_cfg(self, x, t, y, cfg_scale):
"""
Forward pass of DiT, but also batches the unconditional forward pass for classifier-free guidance.
"""
# https://github.com/openai/glide-text2im/blob/main/notebooks/text2im.ipynb
half = x[: len(x) // 2]
combined = torch.cat([half, half], dim=0)
model_out = self.forward(combined, t, y)
# For exact reproducibility reasons, we apply classifier-free guidance on only
# three channels by default. The standard approach to cfg applies it to all channels.
# This can be done by uncommenting the following line and commenting-out the line following that.
# eps, rest = model_out[:, :self.in_channels], model_out[:, self.in_channels:]
eps, rest = model_out[:, :3], model_out[:, 3:]
cond_eps, uncond_eps = torch.split(eps, len(eps) // 2, dim=0)
half_eps = uncond_eps + cfg_scale * (cond_eps - uncond_eps)
eps = torch.cat([half_eps, half_eps], dim=0)
return torch.cat([eps, rest], dim=1)