
[스터디] Understanding Convolutions on Graphs
Graph를 처리할 수 있는 Convolution Network [Page]
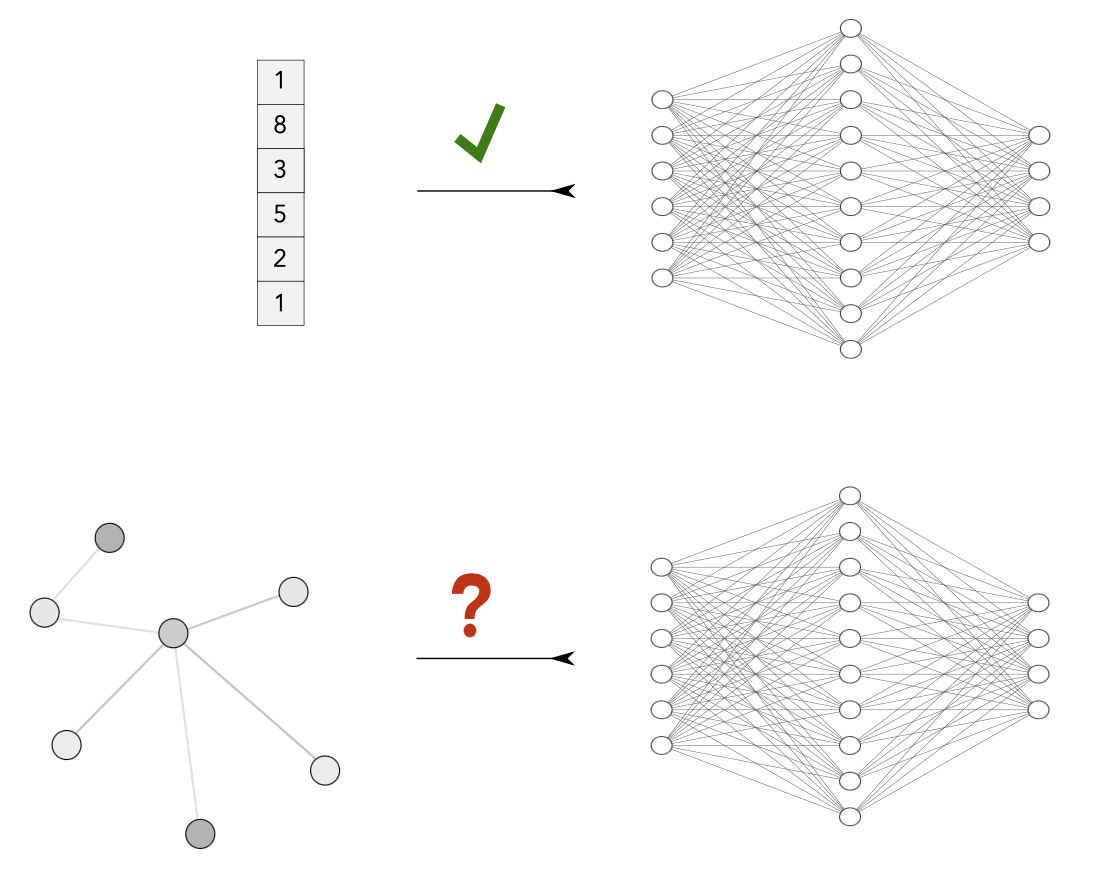
신경망은 전통적으로 문장, 이미지, 동영상과 같은 고정 크기 및/또는 규칙적인 구조의 입력에 대해 작동하는 데 사용
그래프 구조의 데이터를 정교하게 처리할 수 없음
따라서 graph 만의 구조 필요
개발된 2가지 방법 중 random-walk methods 보다 GNN 더 많이 씀 : 기본 시스템을 더 잘 모델링할 수 있는 고유한 유연성 때문에
컴퓨팅의 어려움을 설명하고, 그래프 신경망의 기원과 설계를 설명하며, 최근 가장 인기 있는 GNN 변형을 살펴볼 것입니다. 특히 이러한 변형 중 상당수가 유사한 빌딩 블록으로 구성되어 있다는 것을 알게 될 것
The Challenges of Computation on Graphs
Lack of Consistent Structure
노드 및 연결의 정도 등이 매번 다름 → 그래프를 계산할 수 있는 형식으로 표현하는 것은 그리 간단한 일이 아니며, 최종적으로 선택되는 표현은 실제 문제에 따라 크게 달라지는 경우가 많
Node-Order Equivariance
그래프에는 노드 사이에 고유한 순서가 없는 경우가 많음 (고정된 위치의 픽셀을 가지는 이미지와 다름)
Scalability
그래프의 크기는 매우 커질 수 있음 (ex: 페이스북)
대부분 자연적으로 발생하는 그래프는 ‘sparse’ 함 → 선형적
Problem Setting and Notation
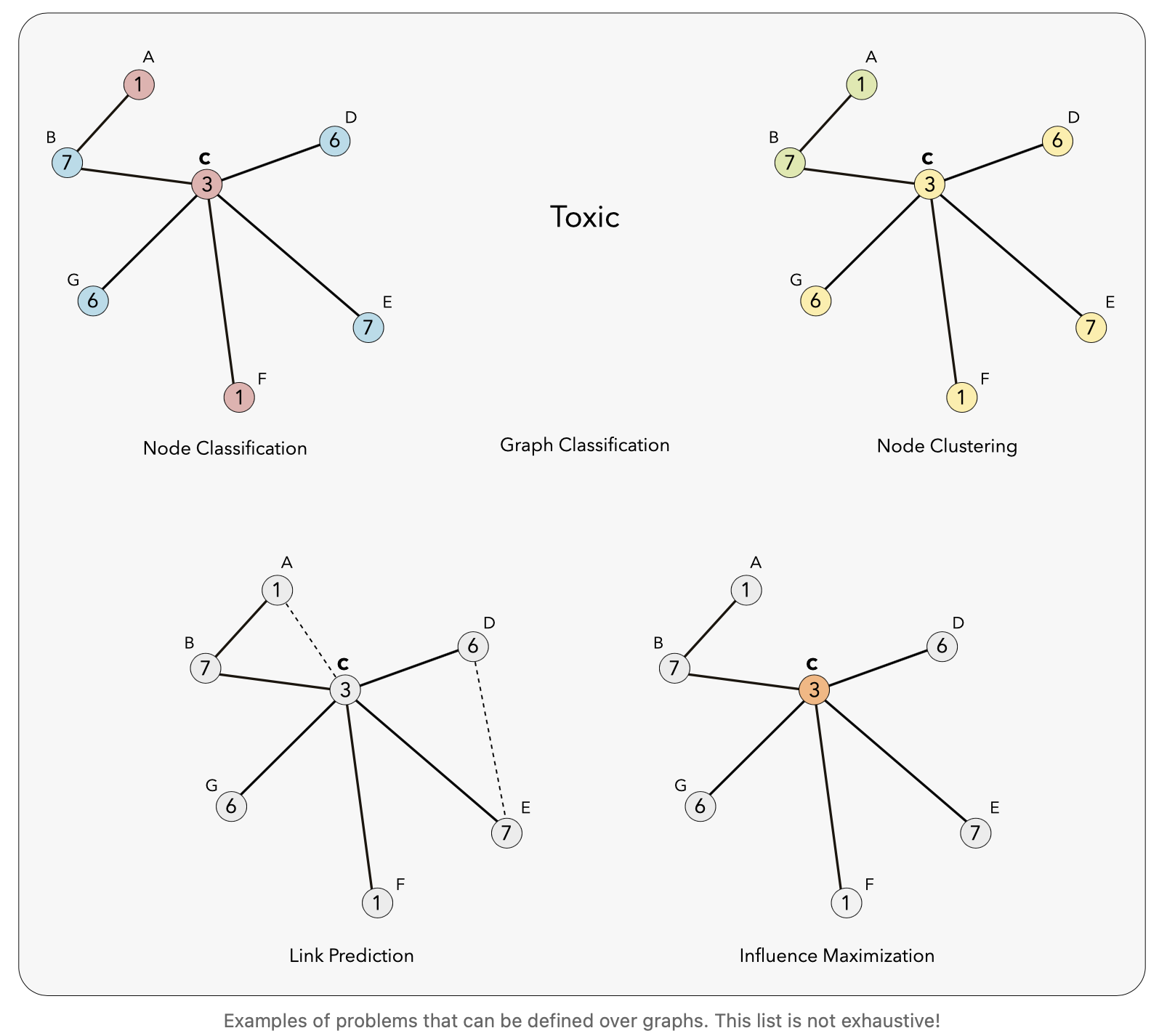
그래프를 쓰면 좋은 문제
- Node Classification: Classifying individual nodes.
- Graph Classification: Classifying entire graphs.
- Node Clustering: Grouping together similar nodes based on connectivity.
- Link Prediction: Predicting missing links.
- Influence Maximization: Identifying influential nodes.
기존에는 node representation learning : 개별 노드를 고정된 크기의 실수값 벡터(‘표현’ 또는 ‘임베딩’이라고 함)에 매핑하는 학습을 사용
일반적으로 GNN은 반복적인 프로세스를 통해 노드 표현을 계산 \(h_v^{(k)}\) : k 번째 v 노드 , 각 반복은 표준 신경망의 ‘레이어’에 해당하는 것으로 생각
그래프 G를 노드 집합 V와 이를 연결하는 에지 집합 E로 정의하겠습니다. 노드는 입력의 일부로 개별 특징을 가질 수 있습니다. 노드 v∈V에 대한 개별 특징을 \(x_v\) 로 표시, 방향 없는 그래프 먼저 생각해보자
Extending Convolutions to Graphs
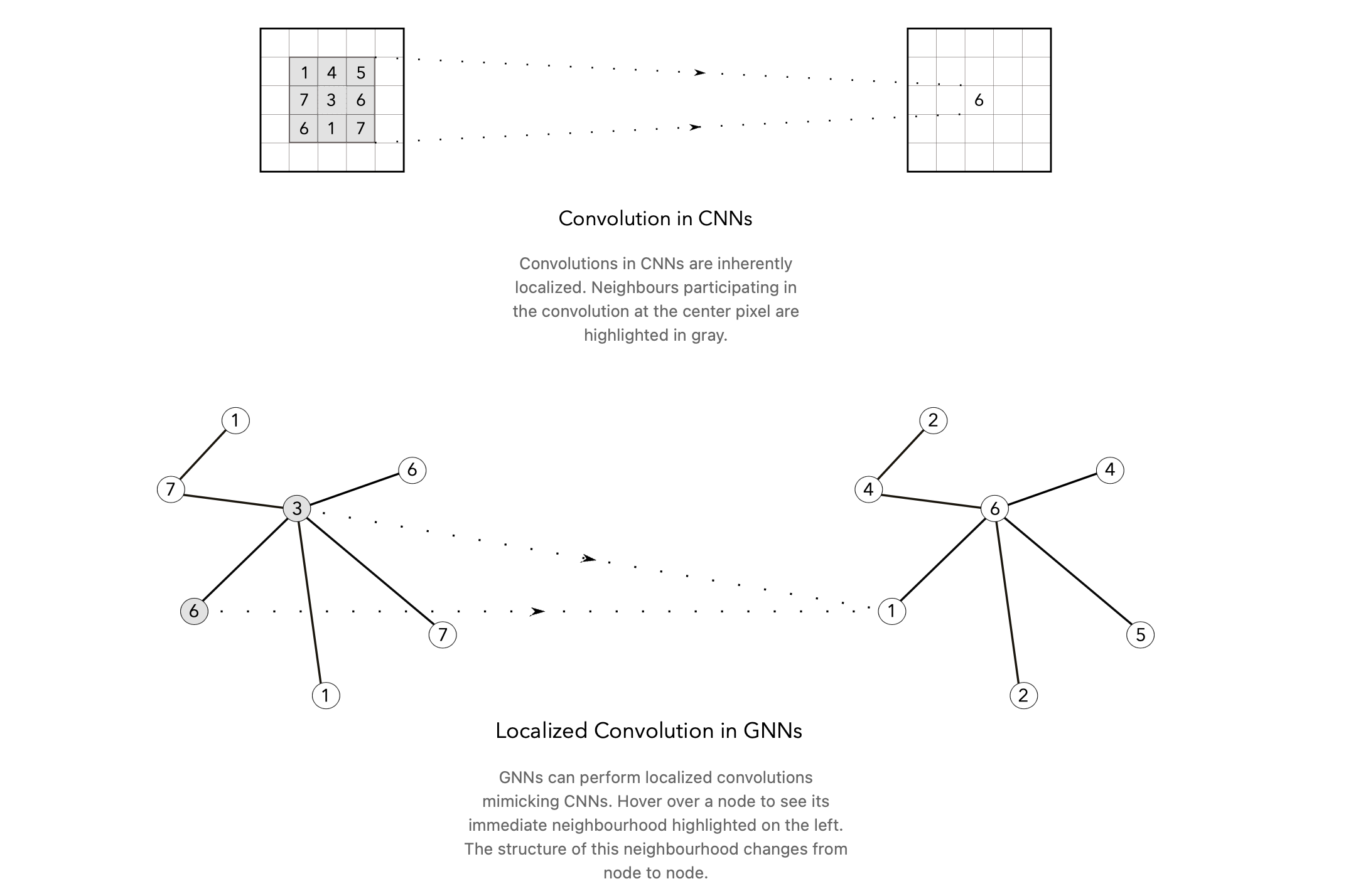
이미지는 픽셀이 고정되어있어 절대적인 위치에 의존함.
GNN은 CNN을 모방한 지역화된 컨볼루션을 수행
노드의 구조에 따라 다른 convolution 연산 수행
Polynomial Filters on Graphs
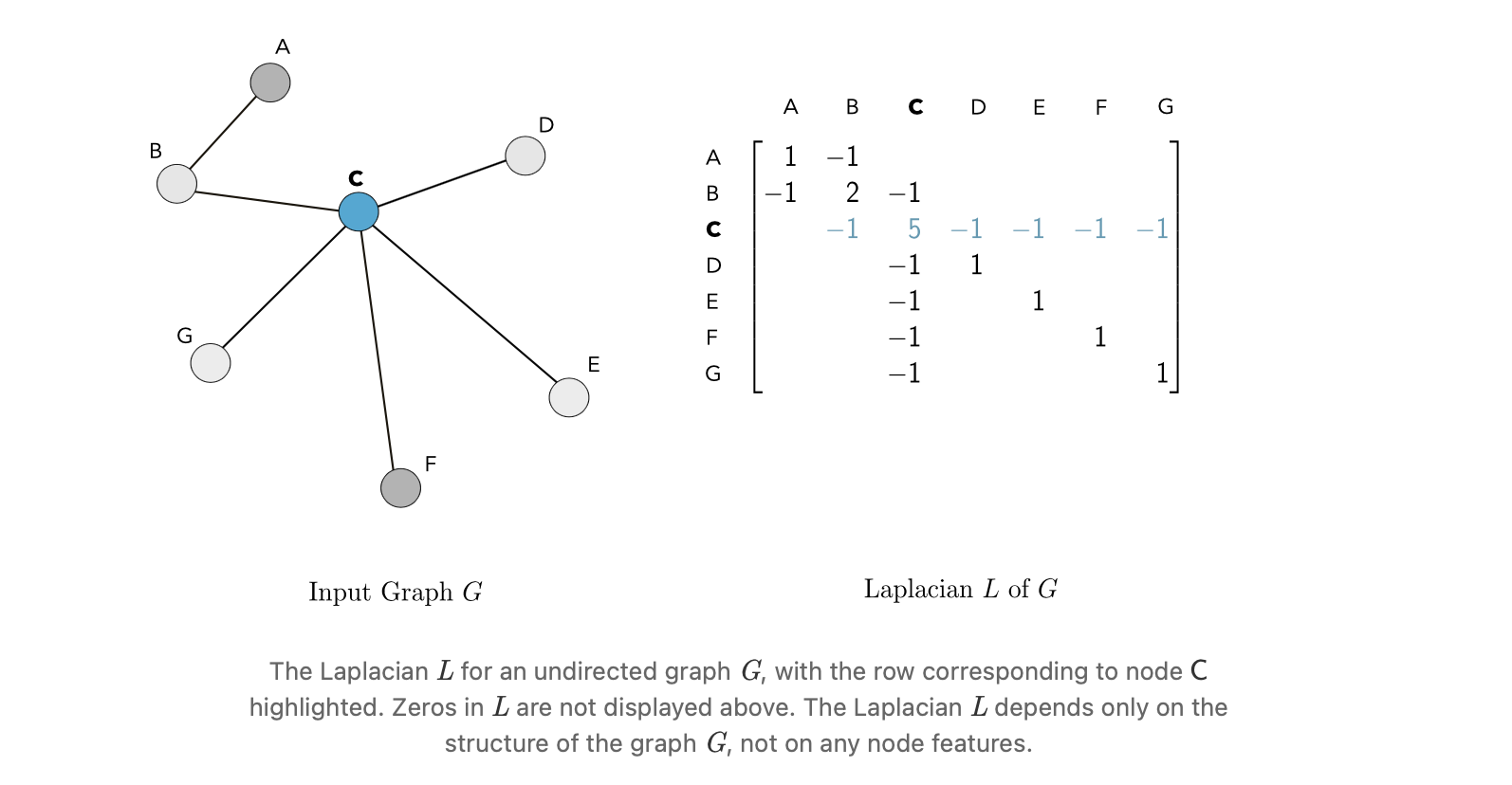
The Graph Laplacian
그래프 G , adjacency matrix → diagonal degree matrix D 만들 수 있음
\(v\) : 자신 노드, \(u\) : 자신의 이웃 노드
\[D_v = \sum_u A_{vu} \ \ ,\ \ L=D-A\]이를 통해 라플라시안을 구할 수 있음 → 의미 뒤에서 살펴봄
Polynomials of the Laplacian
\[p_w(L) = w_0 I_n + w_1 L + w_2 L^2 + \cdots + w_d L^d = \sum_{i=0}^{d} w_i L^i.\]vector of coefficients $w=[w0,…,wd]$ 로 표현될 수 있음. 차수가 낮을 수록 저주파, 높을 수록 고주파
\(w\)\(p_w(L)\) 은 n X n matrix
이러한 다항식은 CNN의 ‘필터’에 해당하는 것으로 생각할 수 있으며, 계수 w는 ‘필터’의 가중치로 간주
L 자체가 모든 노드들의 이웃 관계 + 나 자신을 설명. L을 Polynomial 로 설정함으로써 범위를 확장
ex) 제곱의 경우, 현재 노드에서 L을 통해 이웃을 계산 → 한번 더 L을 계산하면서 이웃의 이웃 노드를 활용
\[x' = p_w(L)\ x\]-
예시
\(w_1 = 1\ \ ,\ \ other = 0\) 일 때
\[x'_v = (Lx)_v = L_v x\]
컨볼루션의 다항식 차수 d가 컨볼루션에 미치는 영향
다항식 필터의 차수 d가 클수록 더 멀리 떨어진 노드까지 영향을 미치며, d가 필터의 국소화 정도를 완전히 결정함을 의미 → 저주파 고주파
ChebNet
Chebyshev polynomials 활용
\[p_w(L) = \sum_{i=1}^{d} w_i T_i(\tilde{L})\]\(T_i\) 는 첫번째 종류의 the degree-Chebyshev polynomial
\(\tilde{L}\) 은 L의 최대 고유값을 사용하여 정의된 정규화된 라플라스시안
\[\tilde{L} = \frac{2L}{\lambda_{\text{max}}(L)} - I_n.\]Polynomial Filters are Node-Order Equivariant
입력 순서에 따라 결과가 바뀌면 안된다 → graph는 순서가 없기 때문 matrix의 위치에 따라 바뀌면 안돼
- 등변성 입증
-
임의의 노드 순서 가정:
그래프의 n개 노드에 대해 임의의 노드 순서를 가정합니다. 다른 모든 노드 순서는 이 원래 노드 순서의 순열로 생각
\[PP^T=P^TP=I_n\]여기서 P 는 순열 행렬로 항상 직교 행렬임.
-
노드 순서 등변성:
\[f(Px)=Pf(x)\]함수 f가 모든 순열 P에 대해 노드 순서 등변적이라면 다음을 만족
-
변환:
\[x→Px\ \ ,\ \ L→PLP^T \ \ ,\ \ L^i→PL^iP^T\]순열 P를 사용하여 새로운 노드 순서로 전환할 때, 아래의 양들은 다음과 같이 변환
-
다항 필터의 경우:
\(f(x)=p_w(L)x\) 인 다항 필터의 경우 다음을 확인
\[f(Px) = \sum_{i=0}^{d} w_i (P L^i P^T)(P x)\]
-
Embedding Computation
x 입력으로 시작 → 여러개(k)의 층을 지나면서 자체적인 가중치 w 로 계산됨
서로 다른 노드에 대해 동일한 필터 가중치를 재사용 → Convolutional Neural Networks (CNNs)에서 그리드 전체에 걸쳐 컨볼루션 필터의 가중치를 재사용하는 방식과 유사
