
[논문분석] Conformer: Convolution-augmented Transformer for Speech Recognition
사람의 음성을 컴퓨터가 자동으로 인식하여 텍스트로 변환하는 ASR(Automatic Speech Recognition) 분야에서 Encoder 모델, Conformer를 제안
문장 전체 혹은 단어 간 관계에 특화된 Transformer
바로 옆에 있는 소리들의 관계, 즉 발음의 미세한 패턴에 특화된 CNN
두 모듈을 결합해 Global, Local 특징을 잘 보기 위한 방법
Abstract
Recently Transformer and Convolution neural network (CNN) based models have shown promising results in Automatic Speech Recognition (ASR), outperforming Recurrent neural networks (RNNs). Transformer models are good at capturing content-based global interactions, while CNNs exploit local features effectively. In this work, we achieve the best of both worlds by studying how to combine convolution neural networks and transformers to model both local and global dependencies of an audio sequence in a parameter-efficient way. To this regard, we propose the convolution-augmented transformer for speech recognition, named Conformer. Conformer significantly outperforms the previous Transformer and CNN based models achieving state-of-the-art accuracies. On the widely used LibriSpeech benchmark, our model achieves WER of 2.1%/4.3% without using a language model and 1.9%/3.9% with an external language model on test/testother. We also observe competitive performance of 2.7%/6.3% with a small model of only 10M parameters.
Index Terms: speech recognition, attention, convolutional neural networks, transformer, end-to-end
1. Introduction
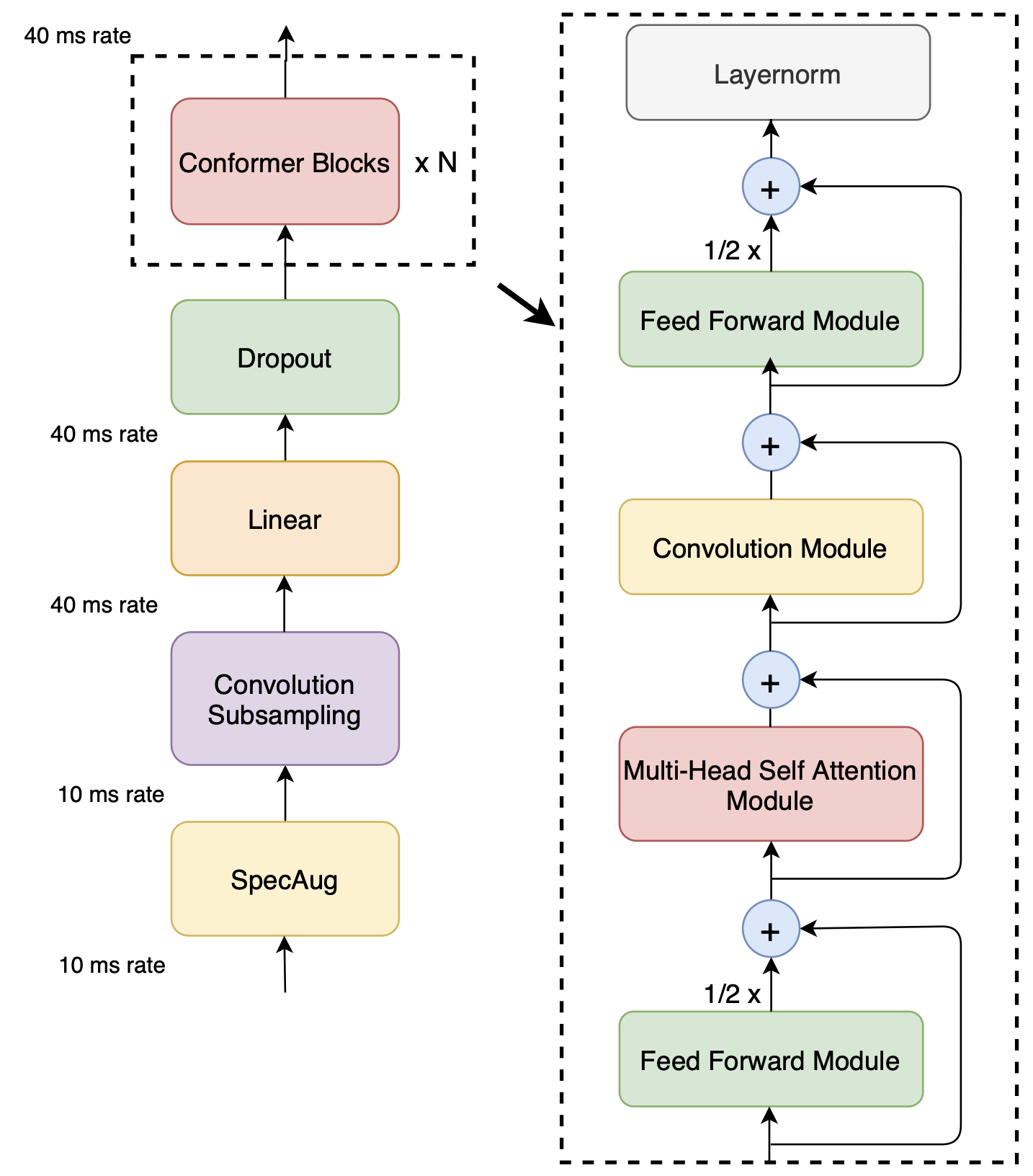
Figure 1: Conformer encoder model architecture. Conformer comprises of two macaron-like feed-forward layers with half-step residual connections sandwiching the multi-headed self- attention and convolution modules. This is followed by a post layernorm.

Figure 2: Convolution module. The convolution module contains a pointwise convolution with an expansion factor of 2 projecting the number of channels with a GLU activation layer, followed by a 1-D Depthwise convolution. The 1-D depthwise conv is followed by a Batchnorm and then a swish activation layer.
- Transformer (트랜스포머)
- 강점: ‘셀프 어텐션(self-attention)’ 메커니즘을 사용하여 문장 전체와 같이 멀리 떨어진 단어 간의 관계(long-range global context)를 효과적으로 파악합니다. 또한, 병렬 처리가 용이하여 훈련 속도가 빠릅니다.
- 한계: 전체적인 문맥을 보는 데는 뛰어나지만, 바로 옆에 있는 소리들의 미세한 관계나 국소적인 특징(fine-grained local feature patterns)을 잡아내는 데는 상대적으로 약합니다.
- CNN (합성곱 신경망)
- 강점: 이미지 분야에서 주로 사용되던 기술로, 작은 필터(local receptive field)를 이용해 데이터의 국소적인 정보(local information)를 포착하는 데 매우 뛰어납니다. 음성에서는 미세한 발음 패턴이나 음향적 특징을 잡아내는 데 효과적입니다.
- 한계: 국소적인 영역만 보기 때문에, 전체적인 문맥과 같은 전역적인 정보(global information)를 파악하려면 수많은 층을 쌓아야 해서 모델이 매우 깊고 커지는 단점이 있습니다.
- ContextNet 같은 모델이 이 문제를 해결하려 했지만, 전체 시퀀스를 단순히 평균 내는 방식이라 동적인 전역 문맥을 포착하는 데는 여전히 한계가 있었습니다.
이 두 모듈을 어떻게 결합할 것인가?
단순히 두 모델을 별도로 만들어 결과를 합치는 것(multi-branch)이 아니라, 하나의 통합된 모듈 안에서 두 기능이 시너지를 내도록 Conformer 블록 구조 제안
- 절반의 피드 포워드 모듈 (1/2 x Feed Forward Module): 입력된 데이터를 처리하고 확장합니다.
- 멀티헤드 자기 주의 모듈 (Multi-Head Self-Attention Module): (Transformer 역할) 데이터 전체를 보고 전역적인 문맥을 파악합니다.
- 컨볼루션 모듈 (Convolution Module): (CNN 역할) 바로 앞뒤의 데이터를 보고 국소적인 패턴을 추출합니다.
- 나머지 절반의 피드 포워드 모듈 (1/2 x Feed Forward Module): 처리된 정보들을 최종적으로 통합하고 정리합니다.
Transformer Transducer보다 상대적으로 15%나 향상된 성능 (testother 데이터셋 기준)
3,000만(30M)개의 파라미터를 가진 중간 크기 Conformer 모델, 1억 3,900만(139M)개의 파라미터를 가진 이전 Transformer Transducer 모델보다도 더 좋은 성능
1,000만(10M)개의 파라미터만 가진 소형 모델조차도 비슷한 크기의 다른 모델들보다 훨씬 뛰어난 성능(WER 2.7%/6.3%)을 기록
가장 큰 모델(118M)은 언어 모델 없이도 2.1%/4.3%, 외부 언어 모델 사용 시 1.9%/3.9%라는 단어 오류율(WER)을 달성
2. Conformer Encoder
먼저 Convolution subsampling layer로 입력을 처리한 후 논문에서 제안한 Conformer block 으로 처리
다음 4개 layer로 Conformer block을 구성
a feed-forward module, a self-attention module, a convolution module, and a second feed-forward module
2.1. Multi-Headed Self-Attention Module

Figure 3: Multi-Headed self-attention module. We use multi-headed self-attention with relative positional embedding in a pre-norm residual unit.
- Transformer-XL에서 제안된 상대적 위치 인코딩(relative positional encoding) 방식을 사용
- Pre-norm 구조를 사용 : 어텐션 연산을 수행하기 전에 Layer Normalization을 먼저 적용 → 깊은 모델의 훈련을 안정화시키는 데 도움
2.2. Convolution Module
-
gating mechanism : pointwise convolution과 GLU(Gated Linear Unit)로 구성
pointwise convolution는 1x1 커널을 통해 해당 시점에 정보만을 활용 현재 상태를 계산 이후 GLU를 통해 반영 정도를 결정
\[GLU(x)=(xW+b)⊗σ(xV+c)\]Sigmoid 함수를 통해 입력의 반영 정도를 0~1 사이로 결정 (게이트 텐서)
-
1-D depthwise convolution
시간적/공간적 패턴을 추출 - 각 채널을 독립적으
(1, 입력_채널_수, 출력_채널_수)로 처리 -
Batchnorm
Conv modul은 여러 데이터에 걸쳐 나타나는 공통된 국소 패턴 을 찾는 것이 목표임으로, batch norm이 더 적합
배치 내의 여러 데이터(다양한 문장, 다양한 위치)에서 나타나는 동일한 특징(‘ㅏ’ 소리의 채널)의 통계치를 계산하여 정규화
2.3. Feed Forward Module

Figure 4: Feed forward module. The first linear layer uses an expansion factor of 4 and the second linear layer projects it back to the model dimension. We use swish activation and a pre-norm residual units in feed forward module.
두개 linear transformation과 사이에 activation
데이터를 강제로 좁은 차원으로 통과시키면, 모델은 정보 손실을 최소화하기 위해 가장 중요하고 유용한 특징(feature)만 남기는 방법을 학습
conformer는 Inverted Bottleneck를 채용좁게 → 넓게 → 좁게 (Narrow → Wide → Narrow)
확장 (d→4d) 후 프로젝션 (4d→d)
핵심 정보 압축 및 노이즈 필터링 뿐만 아니라 깊은 layer 학습에도 안정적
Pre-norm 방식
Swish Activation
\[f(x)=x⋅σ(βx),\ \ \mathrm{where}\ \ σ(x)=\frac{1}{1 + e^{-x}}\]σ는 시그모이드 함수, β는 학습 가능한 파라미터
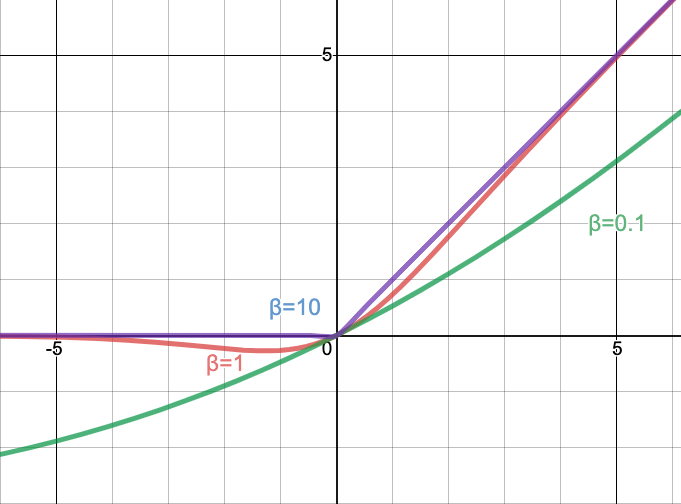
- 부드러운 곡선: ReLU처럼 0에서 갑자기 꺾이는 형태가 아니라 부드럽게 이어집니다. 이는 최적화 과정에서 더 안정적인 기울기 흐름을 돕습니다.
- 음수 값을 허용: ReLU는 음수 입력을 모두 0으로 만들지만, Swish는 작은 음수 값을 허용합니다. 이 덕분에 정보 손실이 줄어들어 표현력이 더 풍부해집니다.
- 비단조성(Non-monotonic): 입력값이 증가할 때 함수값이 항상 증가하지만은 않는 특이한 형태를 가집니다. 이러한 유연성이 모델의 표현력을 높여 더 복잡한 함수를 학습하는 데 도움이 됩니다.
2.4. Conformer Block
2개 Feed Forward Module, FFN 그 사이에 MHSA, Conv
Macaron-Net의 구조에 영감을 받아 FFN이 두 모듈을 감싸도록 설계
실험적으로 vanilla style block 보다 Macaron style model이 더 높은 성능을 보임
다양한 결합 방식 중 셀프 어텐션 모듈 뒤에 컨볼루션 모듈을 쌓는(stacked after) 현재의 순서가 음성 인식에서 가장 좋은 성능을 보인다는 것을 발견
-
Feed Forward Module
\[\tilde{x}_i = x_i + \frac{1}{2} \text{FFN}(x_i)\] -
MHSA
\[x'_i = \tilde{x}_i + \text{MHSA}(\tilde{x}_i)\] -
Conv
\[x''_i = x'_i + \text{Conv}(x'_i)\] -
Feed Forward Module
\[y_i = \text{Layernorm}(x''_i + \frac{1}{2} \text{FFN}(x''_i))\]
3. Experiments
3.1. Data
LibriSpeech 사용
80 채널 필터뱅크(filterbanks)를 사용
25ms window으로 음성을 분석하되, 10ms씩 stride하며 특징을 추출
Data Augmentation
- 기법: SpecAugment를 적용했습니다.
- 주파수 마스킹: 주파수 축에서 특정 대역(최대 27개 채널)을 가림 (가수 목소리의 일부 톤이 바뀌거나 잡음이 낀 효과)
- 시간 마스킹: 시간 축에서 특정 구간(최대 10개)을 가림. (중간에 말이 잠시 끊기거나 ‘어…’ 하는 구간이 있는 효과) 이때, 가려지는 시간 마스크의 최대 길이는 전체 발화 길이의 5%(pS=0.05)를 넘지 않도록 제한
3.2. Conformer Transducer
Model Configuration (실험적으로 가장 좋은 성능을 내는 조합으로 결정)
- Small: 1,000만 (10M) 파라미터
- Medium: 3,000만 (30M) 파라미터
- Large: 1억 1,800만 (118M) 파라미터
디코더: 모든 모델에서 예측된 소리 특징을 최종적인 텍스트로 변환하는 디코더는 단일 레이어 LSTM을 사용
Regularization
- 드롭아웃 (Dropout): Conformer의 모든 잔차 연결(residual unit) 블록에 0.1(Pdrop=0.1)의 비율로 적용했습니다.
- 변동 노이즈 (Variational Noise): 모델에 무작위적인 노이즈를 추가하는 또 다른 규제 기법입니다.
- L2 규제: 모든 학습 가능한 가중치에
1e-6의 작은 가중치를 부여하여 가중치 값이 너무 커지지 않도록 제한했습니다. (Weight Decay라고도 합니다.)
Training Method
- 최적화기 (Optimizer): Adam을 사용했으며, 파라미터는
β1=0.9,β2=0.98,ε=10^-9로 설정 - 학습률 스케줄 (Learning Rate Schedule): Transformer에서 제안된 학습률 스케줄을 사용
- Warm-up: 처음 10,000 스텝 동안은 학습률을 점진적으로 증가
- Peak Rate: 학습률이 최고점에 도달한 후에는 특정 공식(
0.05 / sqrt(d),d는 모델 차원)에 따라 점차 감소
External Language Model, LM
- 구조: 4096 크기의 3레이어 LSTM 모델.
- 훈련 데이터: LibriSpeech의 텍스트 말뭉치와 960시간 음성 데이터의 텍스트(transcript)를 모두 합쳐 훈련.
- 토큰화: 1,000개의 WPM(Word Piece Model)을 사용.
- 결합 방식: 얕은 융합(Shallow Fusion) 방식을 사용. 이는 음성 모델의 예측 점수와 언어 모델의 예측 점수를 가중치 합으로 결합하는 간단한 방식.
- LM 가중치(λ): 두 모델의 점수를 어떤 비율로 합칠지 결정하는 가중치
λ는 개발 세트(dev-set)에서 가장 좋은 성능을 내는 값을 그리드 서치(grid search)를 통해 찾음
Lingvo 툴킷을 사용하여 구현
3.3. Results on LibriSpeech
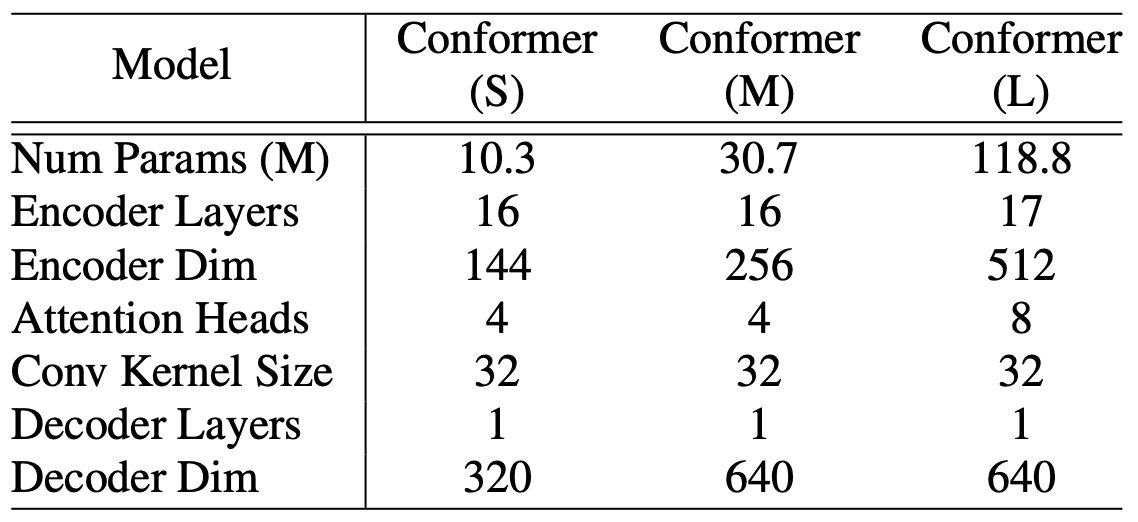
Table 1: Model hyper-parameters for Conformer S, M, and L models, found via sweeping different combinations and choosing the best performing models within the parameter limits.
![Table 2: Comparison of Conformer with recent published models. Our model shows improvements consistently over various model parameter size constraints. At 10.3M parameters, our model is 0.7% better on testother when compared to contemporary work, ContextNet(S) [10]. At 30.7M model parameters our model already significantly outperforms the previous published state of the art results of Transformer Transducer [7] with 139M parameters.](/assets/Images/2025-07-04-Conformer/image%206.png)
Table 2: Comparison of Conformer with recent published models. Our model shows improvements consistently over various model parameter size constraints. At 10.3M parameters, our model is 0.7% better on testother when compared to contemporary work, ContextNet(S) [10]. At 30.7M model parameters our model already significantly outperforms the previous published state of the art results of Transformer Transducer [7] with 139M parameters.
ContextNet : Conformer(S, 10.3M)는 ContextNet(S, 10.8M)보다 testother에서 0.7% 더 좋은 성능
Transformer Transducer : Conformer(M, 30.7M) 모델이, 파라미터 수가 4배 이상 많은 Transformer Transducer(139M) 모델보다도 모든 면에서 훨씬 뛰어난 성능
3.4. Ablation Studies
3.4.1. Conformer Block vs. Transformer Block
![Table 3: Disentangling Conformer. Starting from a Conformer block, we remove its features and move towards a vanilla Transformer block: (1) replacing SWISH with ReLU; (2) removing the convolution sub-block; (3) replacing the Macaron-style FFN pairs with a single FFN; (4) replacing self-attention with relative positional embedding [20] with a vanilla self-attention layer [6]. All ablation study results are evaluated without the external LM.](/assets/Images/2025-07-04-Conformer/image%207.png)
Table 3: Disentangling Conformer. Starting from a Conformer block, we remove its features and move towards a vanilla Transformer block: (1) replacing SWISH with ReLU; (2) removing the convolution sub-block; (3) replacing the Macaron-style FFN pairs with a single FFN; (4) replacing self-attention with relative positional embedding [20] with a vanilla self-attention layer [6]. All ablation study results are evaluated without the external LM.
- Conformer 원본: 기준 성능 (오류율 2.1%/4.3%)
- Swish 활성화 함수 → ReLU로 변경: 성능이 약간 하락합니다. (2.0%/4.5%) 이는 Swish가 더 빠르고 효과적인 학습에 기여했음을 의미합니다.
- 컨볼루션(Convolution) 블록 제거: 성능이 가장 크게 하락합니다. (2.1%/4.9%) 이것이 Conformer의 가장 중요하고 핵심적인 기능임을 증명합니다.
- 마카롱(Macaron) FFN → 단일 FFN으로 변경: 성능이 추가로 하락합니다. (2.1%/5.0%) 이는 두 개의 FFN이 하나보다 더 효과적임을 보여줍니다.
- 상대적 위치 임베딩 제거: 최종적으로 일반적인 Transformer와 유사해지면서 성능이 가장 많이 하락합니다. (2.4%/5.6%)
3.4.2. Combinations of Convolution and Transformer Modules
![Table 4: Ablation study of Conformer Attention Convolution Blocks. Varying the combination of the convolution block with the multi-headed self attention: (1) Conformer architecture; (2) Using Lightweight convolutions instead of depthwise convolution in the convolution block in Conformer; (3) Convolution before multi-headed self attention; (4) Convolution and MHSA in parallel with their output concatenated [17].](/assets/Images/2025-07-04-Conformer/image%208.png)
Table 4: Ablation study of Conformer Attention Convolution Blocks. Varying the combination of the convolution block with the multi-headed self attention: (1) Conformer architecture; (2) Using Lightweight convolutions instead of depthwise convolution in the convolution block in Conformer; (3) Convolution before multi-headed self attention; (4) Convolution and MHSA in parallel with their output concatenated [17].
- Conformer 원본 (어텐션 → 컨볼루션 순서): 기준 성능
- 컨볼루션을 어텐션 앞으로 배치: 성능이 약간 하락했습니다.
- 두 모듈을 병렬로 연결 후 결과 합치기: Conformer 원본보다 성능이 더 나빠졌습니다.
- 컨볼루션 모듈의 종류 변경 (Depthwise → Lightweight): 특히
dev-other데이터셋에서 성능이 크게 하락했습니다.
3.4.3. Macaron Feed Forward Modules
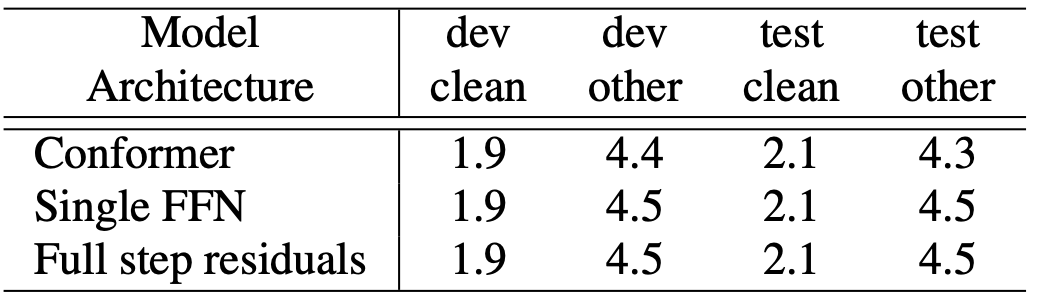
Table 5: Ablation study of Macaron-net Feed Forward modules. Ablating the differences between the Conformer feed forward module with that of a single FFN used in Transformer models: (1) Conformer; (2) Conformer with full-step residuals in Feed forward modules; (3) replacing the Macaron-style FFN pair with a single FFN.
- Conformer 원본: 두 개의 FFN, 1/2 가중치 잔차 연결(half-step residuals)
- Full-step residuals: 잔차 연결 가중치를 1/2이 아닌 1로 변경 → 성능 하락
- 단일 FFN: FFN을 하나만 사용 → 성능 하락
3.4.4. Number of Attention Heads
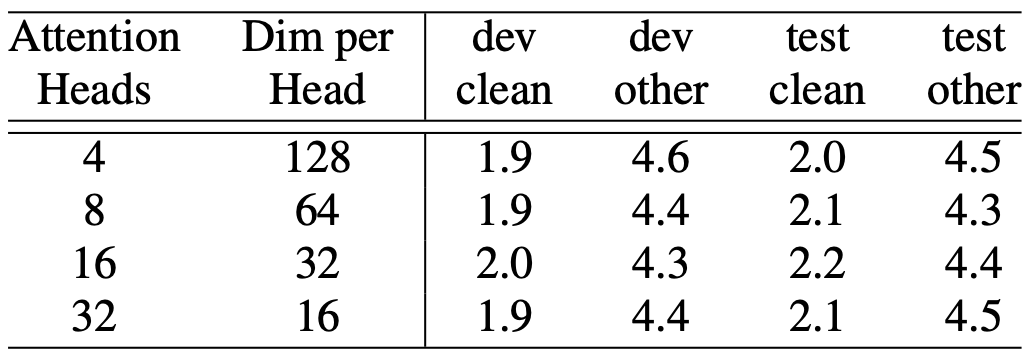
Table 6: Ablation study on the attention heads in multi-headed self attention.
- 헤드의 수를 16개까지 늘렸을 때 성능이 향상되었으나, 그 이상(32개)으로 늘리면 오히려 성능이 약간 저하되거나 정체
3.4.5. Convolution Kernel Sizes
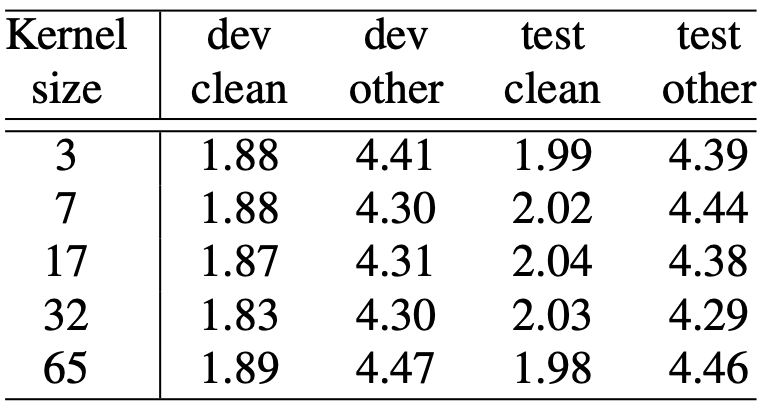
Table 7: Ablation study on depthwise convolution kernel sizes.
- 커널 크기가 커질수록 성능이 향상되다가 17과 32에서 정점을 찍고, 65에서는 오히려 성능이 나빠짐
- 너무 좁게 보는 것(3, 7)보다는 적당히 넓게(17, 32) 보는 것이 국소적 특징을 포착하는 데 가장 효과적이며, 너무 과도하게 넓게 보는 것(65)은 불필요한 정보까지 포함하여 성능에 해가 될 수 있음
- 커널 크기 32가 가장 좋은 성능
4. Conclusion
In this work, we introduced Conformer, an architecture that integrates components from CNNs and Transformers for end-to-end speech recognition. We studied the importance of each component, and demonstrated that the inclusion of convolution modules is critical to the performance of the Conformer model. The model exhibits better accuracy with fewer parameters than previous work on the LibriSpeech dataset, and achieves a new state-of-the-art performance at 1.9%/3.9% for test/testother.