
[논문분석] Fast Context-Biasing for CTC and Transducer ASR models with CTC-based Word Spotter
Abstract
Accurate recognition of rare and new words remains a pressing problem for contextualized Automatic Speech Recognition (ASR) systems. Most context-biasing methods involve modification of the ASR model or the beam-search decoding algorithm, complicating model reuse and slowing down inference. This work presents a new approach to fast context-biasing with CTC-based Word Spotter (CTC-WS) for CTC and Transducer (RNN-T) ASR models. The proposed method matches CTC log-probabilities against a compact context graph to detect potential context-biasing candidates. The valid candidates then replace their greedy recognition counterparts in corresponding frame intervals. A Hybrid Transducer-CTC model enables the CTC-WS application for the Transducer model. The results demonstrate a significant acceleration of the context-biasing recognition with a simultaneous improvement in F-score and WER compared to baseline methods. The proposed method is publicly available in the NVIDIA NeMo toolkit1.
Index Terms: Context-biasing ASR, CTC, RNN-T
1. Introduction
CB 분야 설명
Deep fusion : 전체 단어 혹은 context trie에 cross-attention 을 적용 기존 asr 모델과 결합
shallow fusion : 디코딩만 수정, WFST, beam-search decoding, re-scored
SpeechLM : LLM의 프롬포트로 context-biasing list를 먹임
shallow fusion은 beam search 사용 따라서 고려해야 할 가설이 많아지면 디코딩(텍스트 변환) 속도가 크게 느려짐
Context-Biasing 이라도, 모델의 예측은 학습 데이터에 편향이 생기고 드물거나 새로운 단어는 예측조차 못 할 수 있음
CTC-based Word Spotter called CTC-WS 모델 제안
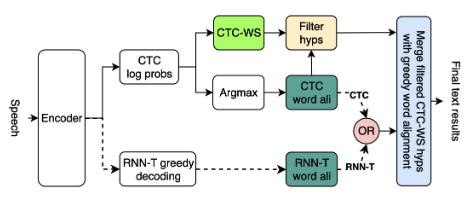
Figure 1: The proposed context-biasing method.
decoding CTC log-probabilities : 각 시간대별 문자 확률표를 보고 최종 문장을 만드는 과정
확률 값(0~1 사이)을 그대로 곱하면 숫자가 너무 작아져서 컴퓨터가 계산하기 어려움 → 로그(log)를 취한 값 → 곱셈이 덧셈으로 바뀌어 값의 범위가 안정적
context graph를 생성해 빠르게 단어와 정확도롤 확인
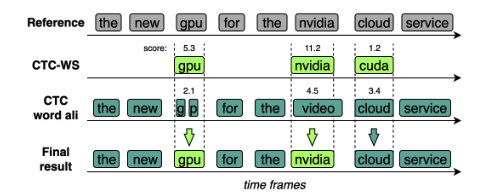
Figure 2: A context-biasing example for a CTC model.
해당 방법은 False Positive 발생 가능함(예: “클라우드”를 찾아달라고 했는데, 비슷한 발음인 “크다”를 “클라우드”로 잘못 인식)
- A 결과: CTC-WS가 찾아낸 ‘중요 단어’ 후보들
- B 결과: 일반적인 CTC 모델이 내놓은 기본 인식 결과
두 결과를 비교 → CTC-WS가 찾아낸 후보의 점수가 더 높을 때만 최종 결과로 채택
A Hybrid Transducer-CTC model 사용
Transducer (RNN-T)에 context-biasing을 적용하기 힘든 점
CTC-WS는 CTC 출력 부분을 활용하여 중요 단어를 빠르게 찾아내고, 그 결과를 최종 Transducer 결과와 병합
2. Methods
2.1. CTC-based Word Spotter
prefix-tree + CTC transition topology 와 결합 → context graph 생성
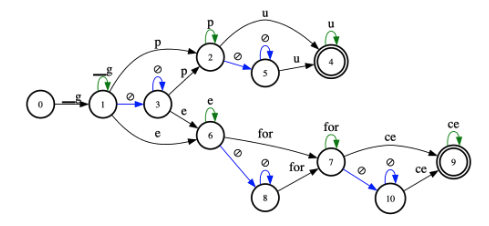
Figure 3: Context graph – a composition of a prefix tree with CTC transition topology generated for words “gpu” and “geforce”. Blue and green arcs denote blank (∅) transitions and self-loops for non-blank tokens, respectively.
- ASR model tokenizer로 단어 분할
- log-probabilities (logprobs) 계산
- context graph decoding
- 오디오의 어느 지점에서든 새로운 단어 인식을 시작할 수 있도록 매 타임 프레임마다 루트 노드에 새로운 빈 가설(empty hypothesis)을 추가
- 가설들은 비-공백(non-blank) 토큰을 통과할 때 로그 도메인에서 문맥 편향 가중치(cbw)를 더하여 추가적인 보상을 받음
hypotheses beam, state prunings을 통해 탐색 공간을 줄임 (알고리즘 1의 24번째 줄)
공백 건너뛰기(blank skipping) 기술을 사용
만약 현재 가설이 비어있고(문맥 그래프의 루트 상태에서) 공백 출력의 확률이 공백 임계값($β_{thr}$)보다 크면, 이 타임 프레임을 건너뜁니다(7번째 줄)
비-공백 임계값($γ _{thr
}$)을 사용하여 비-공백 토큰에도 적용 가능(11번째 줄)
Require: Context graph CG, CTC logprobs L = {l0, l1, …, lT −1}, blank threshold βthr, non-blank threshold γthr, context-biasing weight cbw, CTC alignment weight ctcw, beam threshold beamthr, HYP – hypotheses class with current CG state, accumulated score, start/end time frames.
1: A = {} ▷ list of active hyps
2: C = {} ▷ list of current hyps
3: SH = {} ▷ list of spotted hyps
4: for t = 0 to T − 1 do
5: Add HYP(state = CG.root, start f rame = t) in A
6: for hyp in A do
7: if hyp is empty and lt[blank] > βthr then
8: continue
9: end if
10: for token in hyp.state.next tokens do
11: if hyp is empty and lt[token] < γthr then
12: continue
13: end if
14: new hyp = HYP(state = hyp.state)
15: new hyp.start f rame = hyp.start f rame
16: new hyp.score = hyp.score + lt[token] + cbw
17: if new hyp.state.is end of word then
18: new hyp.end f rame = t
19: Add new hyp in SH
20: end if
21: Add new hyp in C
22: end for
23: end for
24: A = beam and state prunings(C, beamthr)
25: C = {}
26:end for
27:best cb candidats = find best hyps(SH)
28:ctc word ali = get ctc word alignment(L, ctcw)
29:return merge(ctc word ali, best cb candidats)
2.2. Hybrid Transducer-CTC model
유 인코더(shared encoder)와 함께 CTC 및 Transducer 디코더를 사용하며, 두 개의 손실 함수(loss function)로 함께 훈련된 하이브리드 모드의 ASR 모델(하이브리드 Transducer-CTC)이 필요
최종 CTC-WS 결과가 그리디(greedy) Transducer 디코딩 결과와 병합
3. Experimental Setup
3.1. ASR model
Hybrid Transducer-CTC based on FastConformer encoder architecture
https://arxiv.org/pdf/2305.05084
3.2 dataset
train : a composite data set of about 20k hours of English speech and a BPE tokenizer with 1024 tokens
test : NVIDIA 키노트 발표에서 데이터를 수집, 컴퓨터 과학 및 공학 분야, 고유한 용어와 제품명
manual transcriptions은 NeMo Text Normalization를 사용하여 정규화
남아있는 비-텍스트(non-text) 문자들은 제거
그 후 모든 오디오 파일은 CTC 분절 방법에 의해 2초에서 35초 사이의 길이로 분할
잘못 정렬된 분절 문제를 해결하기 위해, 저희는 기본 ASR 모델을 사용하여 그리디 CTC 디코딩으로 얻은 결과에서 높은 단어 에러율(WER >= 80%)을 보이는 분절들을 제거
GTC 데이터 세트는 3시간 분량의 개발(dev) 세트와 7시간 분량의 테스트(test) 세트로 구성
3.3. Context-biasing list
context-biasing list 만들기
baseline ASR model이 recognition problems 을 겪는 단어 위주로 선별
greedy CTC / recognition accuracy <= 50%, length >= 3 characters
짧은 단어 제외
nvidia, geforce, omniverse, tensor core, gpu, cpu 등 100개의 고유한 단어 및 구문으로 구성된 리스트를 얻었으며, 이들은 개발(dev) 세트와 테스트 세트에서 각각 739회, 2149회 등장
Abbreviation (약어) : GPU 와 같이 한 글자씩 따로 발음하는 경우(g, p, u)도 정답으로 처리
Compound Word (복합어) : wordninja라는 라이브러리를 사용, 통계적인 방법을 이용해 가장 그럴듯한 기본 단어들(tensor와 rt)로 분리
3.4. Metrics
F-score = (2 ∗ P recision ∗ Recall/(P recision + Recall))
WER
전체 디코딩 과정(문맥 편향 포함)에 소요되는 시간을 측정
3.5. Baseline context-biasing methods
비교 대상
Greedy Decoding
Shallow Fusion : pyctcdecode(CTC 모델을 위한 라이브러리), Icefall(Transducer 모델을 위한 라이브러리) 사용
Beam Size : 5 → 경험적으로 ‘속도’와 ‘정확도’ 사이의 가장 합리적인 지점
3.6. CTC-based Word Spotter
context-biasing weight $cb_w = 3.0$
CTC 정렬 가중치 ctcw = 0.5
공백 임계값 βthr = log(0.80)
비-공백 임계값 γthr = log(0.001)
빔 임계값 beamthr = 7.0.
4. Results
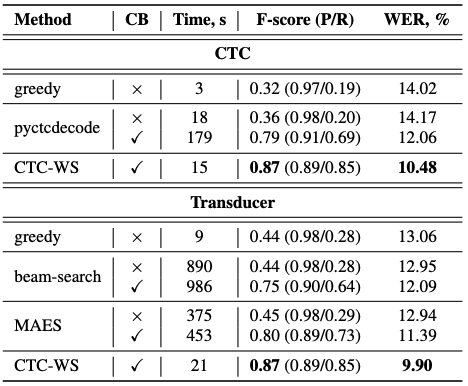
Table 1: CTC and Transducer decoding results on the GTC test set. CB stands for the presence of context-biasing. Time is overall decoding time without encoder. P is Precision. R is Recall.
Pyctcdecode를 이용한 문맥 편향 방식에 비해 디코딩 속도에서 상당한 우위를 보이면서도 인식 정확도(F-점수 및 WER)에서 가장 큰 개선
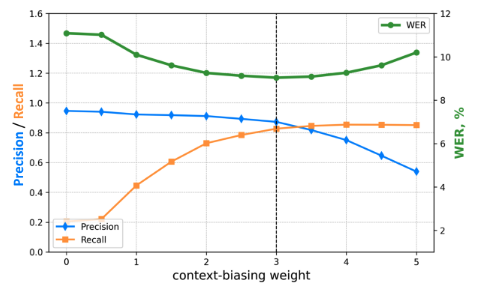
Figure 4: Precision, Recall, and WER depending on contextbiasing weight parameter for the CTC model with CTC-WS and fixed ctcw = 0.5 for the GTC test set.
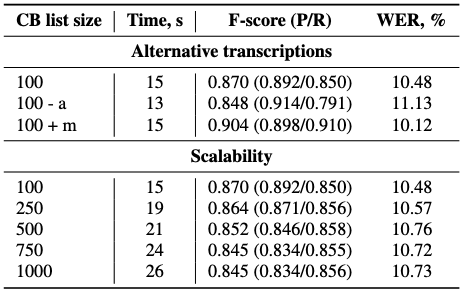
Table 2: Performance of the proposed CTC-WS method for CTC model depending on alternative transcriptions and the size of the cotext-biasing list. Here, “-a” and “+m” mean no automatic and adding manual alternative transcriptions.