
[논문분석] CONTEXTUAL ADAPTERS FOR PERSONALIZED SPEECH RECOGNITION IN NEURAL TRANSDUCERS
Abstract
Personal rare word recognition in end-to-end Automatic Speech Recognition (E2E ASR) models is a challenge due to the lack of training data. A standard way to address this issue is with shallow fusion methods at inference time. However, due to their dependence on external language models and the deterministic approach to weight boosting, their performance is limited. In this paper, we propose training neural contextual adapters for personalization in neural transducer based ASR models. Our approach can not only bias towards user-defined words, but also has the flexibility to work with pretrained ASR models. Using an in-house dataset, we demonstrate that contextual adapters can be applied to any general purpose pretrained ASR model to improve personalization. Our method outperforms shallow fusion, while retaining functionality of the pretrained models by not altering any of the model weights. We further show that the adapter style training is superior to full-fine-tuning of the ASR models on datasets with user-defined content. Index Terms— personalization, neural transducer, contextual biasing, e2e, contact name recognition
ASR에서 특정 전문 단어를 인식하는 것은 훈련 데이터의 부족으로 인해 어려운 task임
일반적으로 shallow fusion 방법을 많이 사용 → 외부 언어 모델에 대한 의존성과 가중치 증폭(weight boosting)에 대한 결정론적 접근 방식 때문에 성능이 제한적
본 논문에서는 neural contextual adapter 제안
1. INTRODUCTION
End to end ASR
context biasing 2가지 방법
- 훈련 후 외부 언어 모델(LM)을 통합하는 방법 : 이는 별도로 훈련된 LM을 기반으로 n-gram 유한 상태 트랜스듀서(FST)를 구성 → 사용자가 정의한 context의 점수를 높
- Shallow Fusion
- on-the-fly, OTF rescoring
장점 : ASR 모델에 적용이 용이
단점 : 가중치 설정에 따라 성능이 민감하게 변하며, 특정 단어를 과도하게 증폭시켜 오히려 전체 성능을 악화시킬 위험 존재
- 훈련 시점에 개인화된 컨텍스트를 통합하는 방법 : 인화된 정보를 ASR 모델의 훈련 과정에 직접 포함시켜 처음부터 함께 학습
- Neural Contextual Biasing
- Deep Personalized LM Fusion
모델 전체를 처음부터 다시 훈련해야 하므로 비용과 시간이 많이 필요
이미 잘 훈련된 기존 모델을 활용하지 못하는 비효율성
neural contextual adapter 장점
- 데이터 효율성: 적은 양의 데이터로도 훈련이 가능
- 비용 효율성: 훈련 시간이 86% 이상 단축되어 매우 빠르고 저렴
- 활용성: 이미 잘 만들어진 범용 ASR 모델에 쉽게 추가하여 사용
- 유연성: 목적에 따라 어댑터만 교체하면 연락처, 장치 이름 등 여러 도메인에 대응 가능
2. NEURAL TRANSDUCERS
처음 제안된 논문 : https://arxiv.org/abs/1211.3711
-
Encoder : 음성 프레임(x)을 입력받아 음향 정보를 vector로 변환합니다 (음향 모델 역할)
\[h_{\text{enc}}^t = \text{Encoder}(x_{0,t})\] -
Prediction Network : 전에 예측된 텍스트(y)를 입력받아 다음 단어 예측 정보를 vector로 변환 (언어 모델 역할)
\[h_{\text{pre}}^u = \text{PredictionNetwork}(y_{0,u-1})\] -
Joint Network : 인코더와 예측기의 두 표현을 결합하여 최종 출력 확률을 계산
최종 출력
\[P(y_u|t, u) = \text{softmax}(z_{t,u})\]Forward-backward algorithm
- 순방향 변수 (Forward Variable)
$\alpha(t, u)$ : 시간 t까지의 음성($x_{1..t}$)을 보고, 텍스트 u 길이($y _{1..u}$)까지 생성했을 확률, 특정 시점까지의 경로 확률을 누적하여 계산
- t: 음성 프레임의 시간 인덱스
- u: 출력 텍스트 토큰의 인덱스
- yu: u번째 출력 토큰
- ϕ: 아무것도 출력하지 않음을 의미하는 ‘blank’ 토큰
재귀적으로 계산
\[\alpha(t, u) = \alpha(t-1, u) \cdot P(\phi|t-1, u) + \alpha(t, u-1) \cdot P(y_u|t, u-1)\]- Blank 출력(앞쪽 항): (t−1,u) 상태에서 ‘blank’(ϕ)를 출력하여 (t, u)로 이동.
- 토큰 출력(뒤쪽 항): (t,u−1) 상태에서 다음 토큰(yu)을 출력하여 (t, u)로 이동.
- 역방향 변수 (Backward Variable)
$\beta(t, u)$ : $(t, u)$ 상태에서 시작하여, 나머지 음성($x_{ t..T}$)을 보고 나머지 텍스트($y_{ u+1..U
}$)를 모두 생성할 확률
- Blank 출력(앞쪽 항): (t,u) 상태에서 ‘blank’(ϕ)를 출력하고, (t+1,u) 상태에서 나머지를 생성할 확률.
- 토큰 출력(뒤쪽 항): (t,u) 상태에서 다음 토큰(yu+1)을 출력하고, (t,u+1) 상태에서 나머지를 생성할 확률.
- RNN-T loss
| 전체 시퀀스(y)가 나올 확률 P(y | x)는 순방향 변수와 역방향 변수의 곱으로 표현 |
최종적으로 훈련에 사용되는 손실 함수는 이 확률에 음의 로그(negative log)를 취한 값
\[P(y|x) = \sum_{\pi \in B^{-1}(y)} P(\pi|x)\]π는 가능한 모든 정렬 경로를, $B^{-1}(y)$는 정답 텍스트 y에 해당하는 모든 정렬 경로의 집합
최종 loss function
\[L_{\text{RNN-T}} = -\ln P(y|x)\]3. CONTEXTUAL ADAPTERS
Catalog Encoder, Biasing Adapters 2가지로 구성
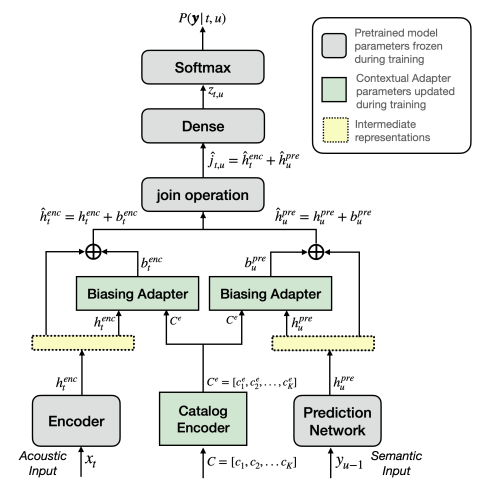
Fig. 1: Contextual Adapters. A personalized neural transducer with the proposed contextual adapters (Enc-Pred Query).
3.1. Catalog Encoder
Catalog list , $C = [c_1, c_2, \dots, c_K]$를 인코딩 → Catalog 각 개체 당 하나의 인코딩 표현 혹은 entity embedding 생성 (사용자 카탈로그 K개, 임베딩 크기가 D → $C_e \in \mathbb{R}^{K \times D}$ 출력)
- 각 개체를 sub-word tokenizer을 활용해 word-piece으로 분할 $c_i$
- embedding lookup와 BiLSTM 계층을 차례로 통과
-
BiLSTM의 최종 상태는 명명된 개체(named entity)의 임베딩으로 전달 $C_e$
\[C_e = [ce_1, ce_2 \dots ce_K]\]
- 카탈로그 개체가 항상 관련성이 있는 것은 아님 → 날씨 도메인의 발화는 연락처 이름에 대한 편향을 주는 어댑터가 필요 없을 수 있음 →
<no bias>토큰을 카탈로그에 도입
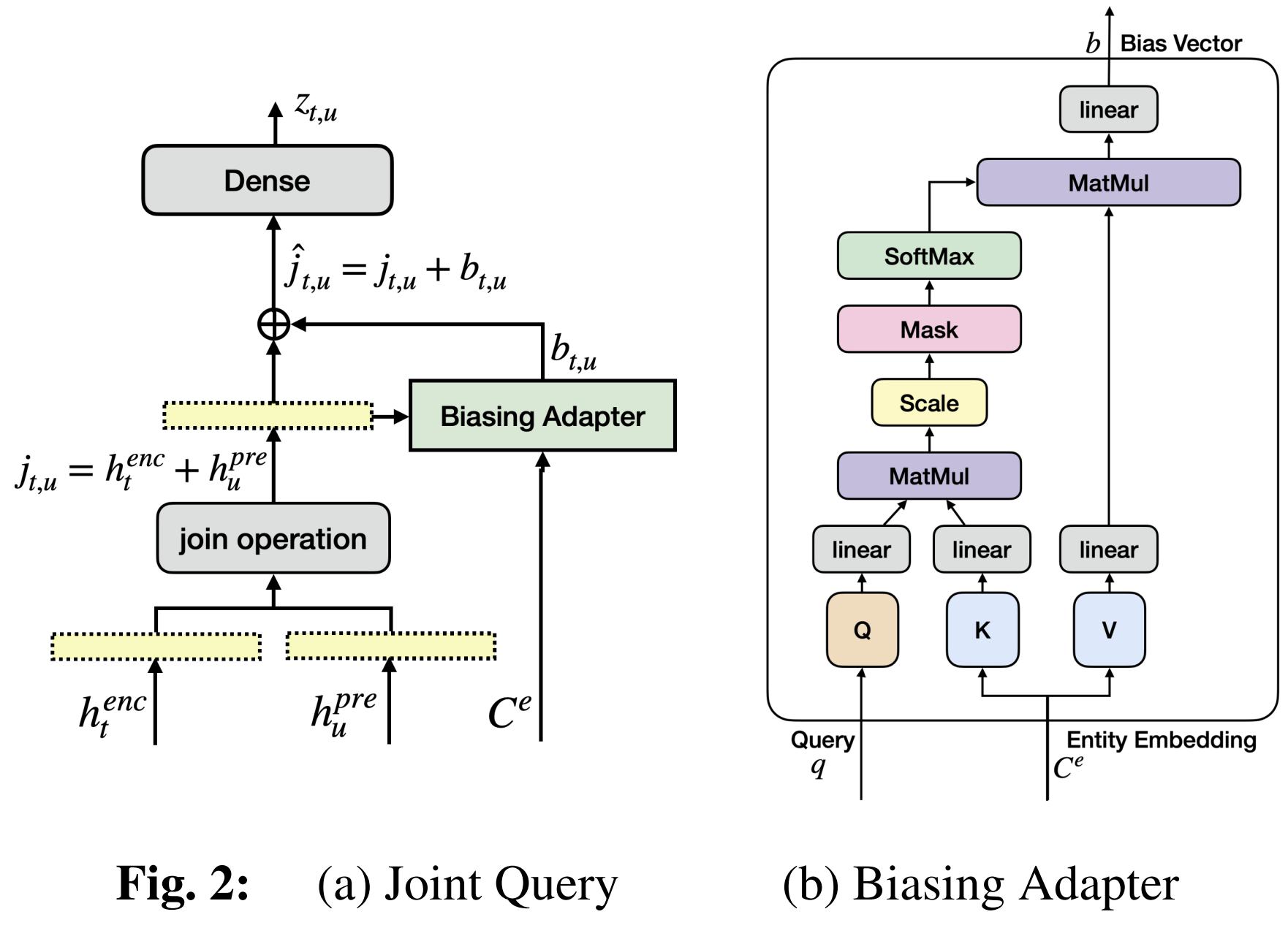
3.2. Biasing Adapters
Bias information 을 통합하여 Neural transducer의 중간 표현을 조정
Cross-attention based bias adapter 제안
\[\alpha_i = \text{Softmax}_i \left( \frac{W_k C_e \cdot W_q q}{\sqrt{d}} \right)\]Attention-score는 linear projection을 통해 얻은 value embedding의 가중 합을 계산하는 데 사용
이를 biasing vector 라고 함 → pretrained Neural transducer의 중간 표현을 업데이트하는데 사용
\[b = \sum_{i}^{K} \alpha_i W_v ce_i\]element-wise addition(⊕로 표기)을 통해 업데이트 수행
(1) 인코더 쿼리 변형:
\[b_{\text{enc}}^t = \text{BA}_{\text{enc}}(h_{\text{enc}}^t, C_e); \quad \hat{h}_{\text{enc}}^t = h_{\text{enc}}^t \oplus b_{\text{enc}}^t\](2) 예측기 쿼리 변형:
\[b_{\text{pre}}^u = \text{BA}_{\text{pre}}(h_{\text{pre}}^u, C_e); \quad \hat{h}_{\text{pre}}^u = h_{\text{pre}}^u \oplus b_{\text{pre}}^u\](4) 조인트 쿼리 변형:
\[b_{t,u} = \text{BA}_{\text{joint}}(j_{t,u}, C_e); \quad \hat{j}_{t,u} = j_{t,u}\]3.3. Adapter Style Training
대한 사전 훈련 모델의 가중치는 고정(frozen)시키고, 작고 새로운 어댑터 모듈만 훈련
3.4. 다중 카탈로그 유형 처리 (Handling Multiple Catalog Types)
연락처, 장치, 장소 등 다양한 종류의 힌트 목록을 동시에 처리하는 방법
- 이름’, ‘장소’ 등 힌트의 종류를 구별하는 학습 가능한 ‘유형 임베딩(type embedding)’을 도입
- 최종 힌트 벡터는 단어 자체의 임베딩과 단어 종류의 임베딩을 결합(concatenate)하여 생성합니다.
상황에 맞게 특정 유형의 힌트에 더 주목하도록 학습
4. EXPERIMENTS
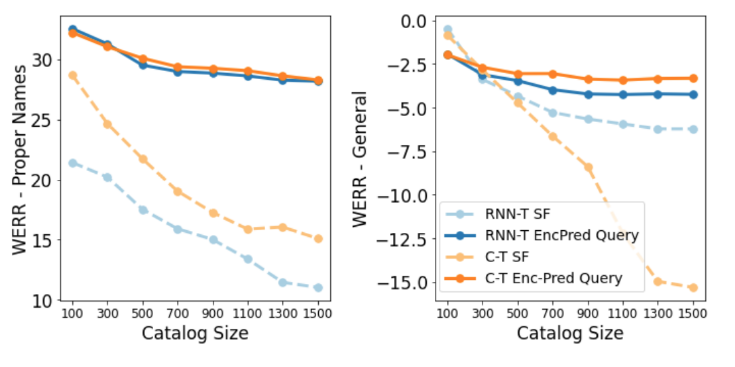
Fig. 3: WERR vs. Catalog Size. Figure showing the WERR on General and Proper Names set for our approach (EncPred Query) vs. SF, as catalogs increase in size.
- 훈련 데이터:
- 사전 훈련용: 11.4만 시간 분량의 일반 음성 비서 데이터.
- 어댑터 훈련용: 약 290시간 분량의 데이터 (개인화된 희귀 단어가 포함된 ‘특정’ 데이터와 ‘일반’ 데이터를 1.5:1 비율로 섞음).
- 평가 데이터:
- 일반(General) 테스트셋: 75시간 분량.
- 특정(Specific) 테스트셋: 20시간 분량 (개인화된 단어 포함).
- 평가 지표:
- WERR (Word Error Rate Reduction): 단어 오류율 감소. 높을수록 좋음.
- NE-WERR (Named Entity WERR): 이름, 장소 등 특정 개체에 대한 단어 오류율 감소. 높을수록 좋음.
비교 모델
- Baseline: 사전 훈련된 RNN-T 및 C-T 모델.
- Baseline + SF: 사전 훈련 모델에 ‘얕은 융합(Shallow Fusion)’을 적용한 모델.
- 제안 모델: 사전 훈련 모델에 ‘컨텍스추얼 어댑터’를 적용한 모델.
Adapter
- 전체 모델 파라미터의 1.5% 미만(<50만개)을 차지하는 매우 가벼운 구조.
- 훈련 시 힌트 목록(카탈로그)의 최대 크기는 300개로 제한.
결과
- 성능: 제안한 ‘어댑터’ 방식이 모든 경우에서 기본 모델과 얕은 융합(SF)보다 뛰어난 성능
- 상보성: ‘어댑터’와 ‘얕은 융합(SF)’을 함께 사용했을 때 특정 단어 인식률(NE-WERR)이 가장 높게 나타나, 두 기술이 상호 보완적
- 카탈로그 크기 영향: 힌트 목록(카탈로그)의 크기가 커져도 ‘어댑터’ 방식은 얕은 융합(SF)보다 성능 저하가 적어 더 안정적
학습
- 미세 조정(Fine-tuning)과의 비교: 모델 전체를 미세 조정하는 것보다 ‘어댑터’만 훈련하는 방식이 월등히 뛰어난 성능을 보임. 전체를 훈련시키면 치명적 망각(catastrophic forgetting) 현상이 발생
<no bias>토큰의 중요성: 이 토큰을 제거하자 일반 발화에 대한 오류율이 급증, 즉, 모델이 언제 힌트를 사용하지 말아야 할지 배우는 데<no bias>토큰이 필수적임을 의미- 다중 카탈로그 처리: 제안한 ‘유형 임베딩(Type Embedding)’을 통해, 하나의 어댑터로도 이름, 장소, 장치 등 여러 종류의 힌트를 효과적으로 구분하고 처리할 수 있음을 입증
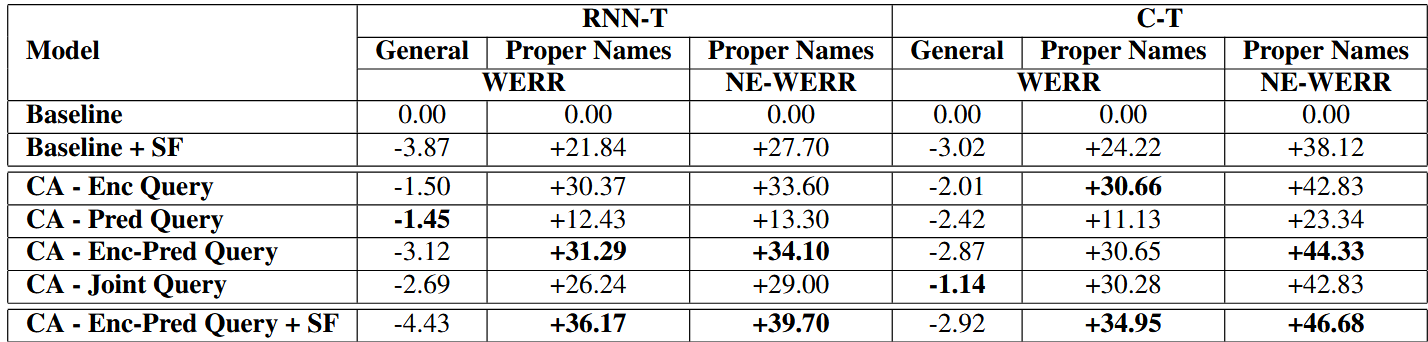
Table 1: Results. Relative change in WER (WERR), and proper name NE-WER (NE-WERR) over vanilla RNN-T and C-T models for, a) Shallow Fusion, b) Contextual Adapter (CA) variants of RNN-T and C-T models, c) Combination of Shallow Fusion with the Enc-Pred query. Note that SF weights are selected based on a hyperparameter search for each model with SF. Best results highlighted in bold.

Table 2: Adapter-style training vs. Full fine-tuning. Impact of freezing vs. unfreezing the base RNN-T parameters on WERR for General and Proper Names Test set compared to baseline model.
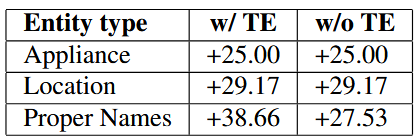
Table 4: Multiple Catalogs. NE-WERR for different types with and without type embedding (TE).