
[논문분석] HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
일관성에 몰빵된 모델 → metric이 높게 나올 수 밖에 없는 구조
시간적 자기 주의 층(temporal self-attention layers)에 첫 번째 프레임의 로컬 윈도우(local window) 특징을 포함시키는 것
FrameInit (during inference not training) : 첫 번째 프레임의 특징을 복제하여 정적인 비디오로 만들고, 이 비디오의 저주파 성분을 추론 중, 레이아웃 지침으로 사용
Q&A
-
zτ 에서 저주파를 , ϵ 에서 고주파를 가져오는 이유
기존 이미지(zτ)를 저주파로 받아 베이스를 정의하고 역동성을 diffudion model(ϵ)에게 맡김
### zτ와 저주파 성분
- zτ의 정의: zτ는 초기 잠재 표현 z0에 τ단계의 추론 잡음을 추가한 것입니다.
- 저주파 성분의 역할: 저주파 성분은 비디오의 전반적인 구조와 느리게 움직이는 큰 부분을 나타냅니다.
- 프레임 초기화: z0는 정적인 비디오의 잠재 표현이므로, 이 표현에서 저주파 성분을 추출하면 비디오의 전반적인 레이아웃을 나타내는 안정적인 정보를 얻을 수 있습니다. 이는 비디오의 전반적인 형태와 구조를 유지하는 데 중요합니다.
### ϵ과 고주파 성분
- ϵ의 정의: ϵ은 추론 과정에서 사용되는 고주파 잡음입니다.
- 고주파 성분의 역할: 고주파 성분은 비디오의 세밀한 디테일과 빠르게 움직이는 객체를 나타냅니다.
- 디테일 보존: ϵ 에서 고주파 성분을 가져오면, 비디오의 세밀한 디테일과 빠르게 변화하는 정보를 유지할 수 있습니다. 이는 비디오의 시각적 품질을 높이고, 세부 사항을 잘 나타낼 수 있게 합니다.
이 과정을 통해 비디오의 전반적인 구조와 세밀한 디테일을 모두 잘 유지하며, 안정적이고 고품질의 비디오를 생성할 수 있습니다.
-
Training 과정이 아니라 inference 에서만 사용하는 이유? → 생성 속도가 많이 늦어짐
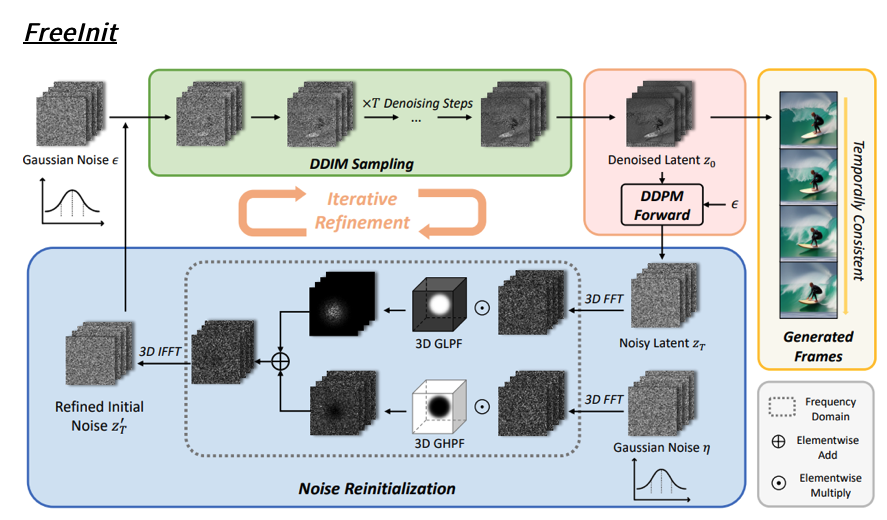
생성된 이미지를 다시 DDPM fowardpass를 거쳐 고주파,저주파를 추출 이를 반복
Abstract
Image-to-video (I2V) generation aims to use the initial frame (alongside a text prompt) to create a video sequence. A grand challenge in I2V genera- tion is to maintain visual consistency throughout the video: existing methods often struggle to pre- serve the integrity of the subject, background, and style from the first frame, as well as ensure a fluid and logical progression within the video narra- tive (cf. Figure 1). To mitigate these issues, we propose CONSISTI2V, a diffusion-based method to enhance visual consistency for I2V generation. Specifically, we introduce (1) spatiotemporal at- tention over the first frame to maintain spatial and motion consistency, (2) noise initialization from the low-frequency band of the first frame to en- hance layout consistency. These two approaches enable CONSISTI2V to generate highly consistent videos. We also extend the proposed approaches to show their potential to improve consistency in auto-regressive long video generation and cam- era motion control. To verify the effectiveness of our method, we propose I2V-Bench, a com- prehensive evaluation benchmark for I2V genera- tion. Our automatic and human evaluation results demonstrate the superiority of CONSISTI2V over existing methods.
이미지-투-비디오(I2V) 생성은 초기 프레임(텍스트 프롬프트와 함께)을 사용하여 비디오 시퀀스를 생성하는 것을 목표로 합니다. 기존 방식은 첫 프레임부터 피사체, 배경, 스타일의 일관성을 유지하고 비디오 내러티브 내에서 유동적이고 논리적인 진행을 보장하는 데 어려움을 겪는 경우가 많습니다(그림 1 참조). 이러한 문제를 완화하기 위해 유니티는 I2V 생성을 위한 시각적 일관성을 향상시키는 확산 기반 방법인 CONSISTI2V를 제안합니다. 구체적으로, (1) 공간 및 모션 일관성을 유지하기 위해 첫 번째 프레임에 대한 시공간적 어텐션을 도입하고, (2) 레이아웃 일관성을 강화하기 위해 첫 번째 프레임의 저주파 대역부터 노이즈 초기화를 수행합니다. 이 두 가지 접근 방식을 통해 CONSISTI2V는 매우 일관성 있는 비디오를 생성할 수 있습니다. 또한 제안된 접근법을 확장하여 자동 회귀형 긴 비디오 생성 및 캠 시대의 모션 제어에서 일관성을 개선할 수 있는 잠재력을 보여줍니다. 제안한 방법의 효과를 검증하기 위해 I2V 생성에 대한 종합적인 평가 벤치마크인 I2V-Bench를 제안합니다. 자동 및 수동 평가 결과를 통해 기존 방법보다 CONSISTI2V의 우수성을 입증합니다.
Introduction
조건부 생성 기술은 생성된 비디오 콘텐츠를 정밀하게 제어하기에는 부족
“뒷마당에서 뛰는 개”라는 입력 텍스트가 주어지면 생성되는 동영상은 다양한 개 품종, 다양한 카메라 시야각, 다양한 배경 개체를 출력하는 등 다양할 수 있음
사용자는 텍스트 프롬프트를 신중하게 수정하여 더 많은 설명 형용사를 추가하거나 원하는 결과를 얻기 위해 여러 개의 동영상을 반복적으로 생성해야 할 수 있음
앞서 언급한 문제를 해결하기 위해 I2V 생성을 위한 시각적 일관성을 향상시킬 수 있는 간단하면서도 효과적인 프레임워크인 CONSISTI2V를 제안, 이 방법은 I2V 모델의 첫 번째 프레임 컨디셔닝 메커니즘을 개선하고 추론을 최적화하는 데 중점을 둡니다.
노이즈 초기화를 최적화하는 데 중점, 첫 번째 프레임과 매우 유사한 비디오를 제작하기 위해 모델의 공간 레이어에 크로스 프레임 어텐션 메커니즘을 적용하여 세밀한 공간적 첫 번째 프레임 컨디셔닝을 달성
생성된 비디오의 시간적 부드러움과 일관성을 보장하기 위해 시간적 레이어에 첫 번째 프레임 특징의 로컬 창을 포함시켜 주의 연산을 강화
추론 중에는 첫 번째 프레임 이미지의 저주파 성분을 활용하고 이를 초기 노이즈와 결합하여 레이아웃 가이드 역할을 하고 훈련과 추론 간의 노이즈 불일치를 제거하는 FrameInit을 제안
이러한 설계 최적화를 통합함으로써 이 모델은 매우 일관된 비디오를 생성하며, 자동 회귀식 긴 비디오 생성 및 카메라 모션 제어와 같은 다른 애플리케이션으로 쉽게 확장 가능

Methodology
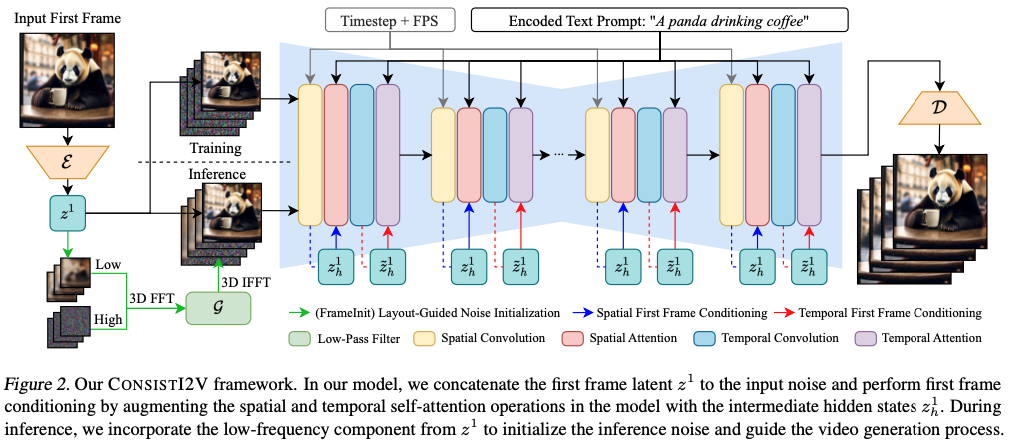
Image :
\[x^1 ∈ \mathbb{R}^{C×H×W}\], a text prompt : s
the goal of our model, generate an N frame video clip :
\[\hat{x} = {\hat{x}^1, \hat{x}^2, \hat{x}^3, ... \hat{x}^N } ∈ \mathbb{R}^{N×C×H×W}\]Preliminaries
Latent Diffusion Models (LDMs)
Model Architecture
U-Net Inflation for Video Generation
이 모델은 이미지 생성을 위해 U-Net 모델을 사용하는 텍스트-이미지(T2I) LDM을 기반
이 U-Net 모델에는 skip connection이 있는 일련의 공간 다운샘플링 및 업샘플링 블록이 포함되어 있습니다. 각 다운/업샘플링 블록은 spatial convolution과 spatial attention layers라는 두 가지 유형의 기본 블록으로 구성
모든 spatial convolution block과 특정 attention 해상도의 시간적 관심 블록 뒤에 1D temporal convolution block을 삽입하여 비디오 생성 작업과 호환되도록 합니다.
시간적 컨볼루션 및 주의 블록은 시간적 차원을 따라 컨볼루션 및 주의 연산이 작동한다는 점을 제외하면 공간적 컨볼루션 및 주의 블록과 완전히 동일한 아키텍처를 공유
시간적 레이어에서 위치 정보를 표현하기 위해 RoPE 임베딩을 통합하고, 노이즈 초기화를 위해 PYoCo 혼합 noise initialization를 사용합니다
First Frame Condition Injection
variational autoencoder (VAE)
\(z^1 = E(x^1) ∈ \mathbb{R}^{C'×H'×{W'}}\) , 조건부 신호로 Z1을 사용합니다.
이 신호를 모델에 주입하기 위해 첫 번째 프레임 노이즈 ε1을 z1로 직접 대체
\[\hat{ε} = {z^1, ε^2, ε^3, ..., ε^N } ∈ \mathbb{R}^{N×C'×H'×{W'}}\]Fine-Grained Spatial Feature Conditioning
LDM U-Net의 The spatial attention layer에는 각 프레임에서 독립적으로 작동하는 self-attention layer과 프레임과 인코딩된 텍스트 프롬프트 사이에서 작동하는 cross-attention layer이 포함되어 있습니다.
$i^{th}$ 프레임의 중간 숨겨진 상태 $z^i$가 주어지면, self-attention 연산은 $z^i$의 서로 다른 spatial positions 사이의 attention으로 공식화
기존 the self-attention operation
\[Q_s = W_s^Q z^i, \quad K_s = W_s^K z^i, \quad V_s = W_s^V z^i\] \[\text{Attention}(Q_s, K_s, V_s) = \text{Softmax}\left(\frac{Q_s K_s^\top}{\sqrt{d}}\right) V_s\]비디오의 시각적 일관성을 높이기 위해, 자체 주의 레이어의 키 및 값 벡터를 수정
\[Q_s = W_s^Q z^i, \quad K'_s = W_s^K [z^i, z^1], \quad V'_s = W_s^V [z^i, z^1]\]여기서 [-]는 concatenation operation을 나타내며, Ks′와 Vs′의 토큰 시퀀스 길이가 원래 Ks와 Vs에 비해 두 배가 되도록 함
이러한 방식으로 모든 프레임의 각 spatial position는 첫 프레임의 전체 정보에 접근하여 spatial attention layers에서 세분화된 특징 컨디셔닝을 수행 가능
첫번째 프레임 정보를 계속 가지고 갈 수 있도록 함
Window-based Temporal Feature Conditioning
비디오 데이터를 처리하기 위해 첫 번째 프레임의 특징을 효과적으로 활용하는 방법
시간적 자기 주의 층(temporal self-attention layers)에 첫 번째 프레임의 로컬 윈도우(local window) 특징을 포함시키는 것
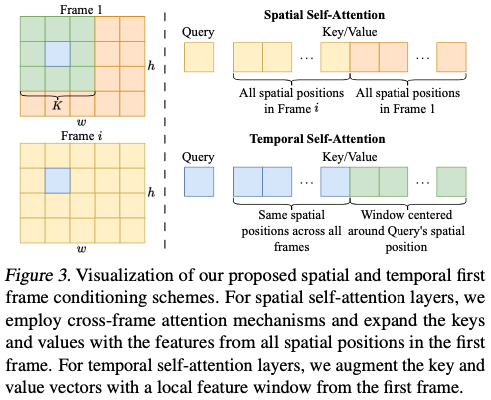
N : number of frames, C, H, W : the channel, height and width dimension of the hidden state tensor
높이와 너비 차원을 배치 차원으로 재구성
\[\mathrm{\bar{z}} ∈ \mathbb{R}^{(H ×W )×N ×C }\] \[Q_t = W_t^Q \tilde{z}, \quad K'_t = W_t^K [\tilde{z}, \tilde{z}^1], \quad V'_t = W_t^V [\tilde{z}, \tilde{z}^1],\]로컬 윈도우 특징 포함
첫 번째 프레임 특징 텐서 : \(Ẑ^1 ∈ R(H×W)×(K×K-1)×C\)
- 이 텐서는 각 h×w 위치가 첫 번째 프레임의 K×K 윈도우를 중심으로 한 특징을 포함하도록 구성됩니다.
- 첫 번째 프레임의 벡터가 이미 \(\bar{z}\) 에 포함되어 있으므로 \(\bar{z}^1\) 에는 포함되지 않습니다.
패딩
- 경계 값을 복제하여 패딩을 수행함으로써 모든 공간 위치가 완전한 윈도우를 가질 수 있도록 합니다.
연결:
- 키와 값 행렬의 시퀀스 길이를 늘리기 위해 \(\bar{z}\) 와 \(\bar{z}^1\) 을 연결합니다.
시각적 일관성을 위한 주의 메커니즘
이유:
- 비디오의 시각적 객체는 시간이 지남에 따라 다른 공간 위치로 이동할 수 있습니다.
- 쿼리 위치 주위에 추가적인 키와 값 윈도우를 포함하면, 시간적 자기 주의를 수행할 때 동일한 객체에 주의를 기울일 확률이 높아집니다.
실제 적용:
-
시간 복잡성을 제어하기 위해 K=3으로 설정합니다.
-
그림 이해
### 공간 자기 주의 (Spatial Self-Attention)
- 쿼리 (Query): 주어진 프레임 i 의 특정 위치에 대한 쿼리입니다.
- 키/값 (Key/Value):
- 모든 공간 위치에 대한 특징을 포함합니다.
- 프레임 i 와 첫 번째 프레임에서 모든 공간 위치의 특징을 사용합니다.
- 작동 방식: 공간 자기 주의 층에서는 교차 프레임 주의 메커니즘을 사용하여 첫 번째 프레임의 모든 공간 위치의 특징과 현재 프레임 ( i )의 모든 공간 위치의 특징을 결합합니다. 이렇게 하면 특정 프레임의 모든 공간 위치가 첫 번째 프레임의 전체 공간 정보를 참조할 수 있습니다.
### 시간 자기 주의 (Temporal Self-Attention)
- 쿼리 (Query): 주어진 프레임 i 의 특정 위치에 대한 쿼리입니다.
- 키/값 (Key/Value):
- 쿼리 위치를 중심으로 한 첫 번째 프레임의 로컬 윈도우의 특징을 포함합니다.
- 모든 프레임의 동일한 공간 위치에 대한 특징을 사용합니다.
- 작동 방식: 시간 자기 주의 층에서는 첫 번째 프레임의 로컬 윈도우 특징을 추가하여 키와 값 벡터를 확장합니다. 이 로컬 윈도우는 쿼리 위치를 중심으로 하여 첫 번째 프레임에서의 윈도우를 형성합니다. 이렇게 하면 시간적 자기 주의를 수행할 때, 동일한 객체를 추적할 가능성이 높아집니다.
### 설명 요약
- 공간 자기 주의: 모든 프레임의 모든 공간 위치 정보를 사용하여, 현재 프레임의 모든 위치가 첫 번째 프레임의 전체 공간 정보를 참조할 수 있게 합니다.
- 시간 자기 주의: 첫 번째 프레임의 로컬 윈도우 특징을 포함하여, 동일한 객체를 시간적으로 추적할 수 있게 합니다.
이 방법을 통해 모델은 비디오 프레임 간의 일관성을 유지하며, 시간적 및 공간적 특징을 효과적으로 통합할 수 있습니다.
Inference-time Layout-Guided Noise Initialization
이미지 확산 모델의 기존 문헌에서는 일반적인 확산 노이즈 스케줄이 훈련 중에 확산 노이즈에 정보 누출을 일으켜 추론 중에 샘플링된 랜덤 가우스 노이즈와 일치하지 않기 때문에 훈련과 추론 사이에 노이즈 초기화 격차가 존재한다는 사실을 확인
-
자세한 예시
• 따라서 lowest frequency information(long-wavelength) 들이 학습할 때 남아있게 된다. → 완전한 noise로부터 시작하지 않음. 하지만 inference 시에는 pure한 noise (평균 0, 가우시안 1)로부터 시작한다. 이는 모델이 중간 밝기의 이미지를 생성하도록 제약한다. 최신 샘플러들은 모든 timesteps를 거치며 샘플링 하지 않음(non-markovian). DDIM, PNDM과 같은 경우 샘플링 프로세스가 마지막 타임스텝에서 시작하지 않아 더욱 심한 문제가 발생.
Common Diffusion Noise Schedules and Sample Steps are Flawed 논문 리뷰
비디오 생성 영역에서 이러한 초기화 격차는 FreeInit(Wu et al., 2023c)에 의해 추가로 연구되었으며, 정보 유출은 주로 시공간적 주파수 분해 후 비디오의 저주파 성분에서 발생하며 이 저주파 성분을 초기 추론 노이즈에 추가하면 생성된 비디오의 품질이 크게 향상된다는 것을 보여주었습니다.
FreeInit: Bridging Initialization Gap in Video Diffusion Models

그림 4와 같이 시공간적 주파수 분해 후 VAE 잠상에서 디코딩된 비디오를 시각화
비디오의 고주파 성분은 빠르게 움직이는 물체와 비디오의 미세한 디테일을 포착하는 반면, 저주파 성분은 천천히 움직이는 부분에 해당하며 각 프레임의 전체적인 레이아웃을 나타냅니다.
FrameInit (during inference not training)
- 목적:
- 첫 번째 프레임의 특징을 복제하여 정적인 비디오로 만들고, 이 비디오의 저주파 성분을 추론 중에 조잡한 레이아웃 지침으로 사용합니다.
- 구현:
- 정적인 비디오의 잠재 표현 z0와 추론 잡음 ϵ이 주어졌을 때, τ 단계의 추론 잡음을 정적인 비디오에 추가하여 zτ를 얻습니다.
- 그런 다음, zτ의 저주파 성분을 추출하고 ϵ과 혼합합니다.
수식
-
저주파 성분 추출:
\[\mathcal{F}^{\text{low}}_{z_r} = \text{FFT\_3D}(z_r) \odot \mathcal{G}(D_0),\] -
고주파 성분 추출:
\[\mathcal{F}^{\text{high}}_{\epsilon} = \text{FFT\_3D}(\epsilon) \odot (1 - \mathcal{G}(D_0)),\] -
혼합 및 역변환:
\[\epsilon' = \text{IFFT\_3D}(\mathcal{F}^{\text{low}}_{z_r} + \mathcal{F}^{\text{high}}_{\epsilon}),\]여기서 IFFT_3D는 3차원 역 이산 푸리에 변환을 나타냅니다. 수정된 잡음 ϵ′은 정적인 비디오로부터 저주파 정보를 포함하며, 이는 이후의 잡음 제거에 사용됩니다.
결과 및 추가 응용
- 안정성 향상:
- FrameInit을 구현하면 생성된 비디오의 안정성이 크게 향상되어 비디오 품질과 일관성이 개선됩니다.
- 추가 응용:
- FrameInit은 모델에 두 가지 추가 응용을 가능하게 합니다:
- 자기회귀적 긴 비디오 생성
- 카메라 모션 제어
- FrameInit은 모델에 두 가지 추가 응용을 가능하게 합니다:
-
zτ에서 저주파를 , ϵ에서 고주파를 가져오는 이유
### zτ와 저주파 성분
- zτ의 정의: zτ는 초기 잠재 표현 z0에 τ단계의 추론 잡음을 추가한 것입니다.
- 저주파 성분의 역할: 저주파 성분은 비디오의 전반적인 구조와 느리게 움직이는 큰 부분을 나타냅니다.
- 프레임 초기화: z0는 정적인 비디오의 잠재 표현이므로, 이 표현에서 저주파 성분을 추출하면 비디오의 전반적인 레이아웃을 나타내는 안정적인 정보를 얻을 수 있습니다. 이는 비디오의 전반적인 형태와 구조를 유지하는 데 중요합니다.
### ϵ과 고주파 성분
- ϵ의 정의: ϵ은 추론 과정에서 사용되는 고주파 잡음입니다.
- 고주파 성분의 역할: 고주파 성분은 비디오의 세밀한 디테일과 빠르게 움직이는 객체를 나타냅니다.
- 디테일 보존: ϵ 에서 고주파 성분을 가져오면, 비디오의 세밀한 디테일과 빠르게 변화하는 정보를 유지할 수 있습니다. 이는 비디오의 시각적 품질을 높이고, 세부 사항을 잘 나타낼 수 있게 합니다.
### 이유 요약
- 저주파 성분을 τ에서 가져오는 이유:
- zτ는 정적인 비디오의 초기 잠재 표현 z0에 추론 잡음을 추가한 것입니다.
- 저주파 성분은 비디오의 전반적인 레이아웃과 구조를 나타내며, 이는 비디오의 안정성과 일관성을 유지하는 데 중요합니다.
- 고주파 성분을 ϵ에서 가져오는 이유:
- ϵ은 추론 과정에서 사용되는 잡음이며, 고주파 성분은 비디오의 세밀한 디테일과 빠르게 변화하는 부분을 나타냅니다.
- 고주파 성분을 통해 비디오의 시각적 품질과 디테일을 유지할 수 있습니다.
### 전체 프로세스
- \(z_0\)에서 \(z_\tau\) 생성: 초기 잠재 표현 \(z_0\)에 \(\tau\) 단계의 추론 잡음을 추가하여 \(z_\tau\)를 만듭니다.
- 저주파 성분 추출: \(z_\tau\)에서 저주파 성분 \(\mathcal{F}^{\text{low}}*{z*\tau}\)를 추출합니다.
- 고주파 성분 추출: \(\epsilon\)에서 고주파 성분 \(\mathcal{F}^{\text{high}}_{\epsilon}\)를 추출합니다.
- 혼합 및 역변환: 저주파 성분과 고주파 성분을 합치고, 이를 3D IFFT를 사용하여 공간 도메인으로 변환하여 최종 수정된 잡음 \(\epsilon\)을 생성합니다.
이 과정을 통해 비디오의 전반적인 구조와 세밀한 디테일을 모두 잘 유지하며, 안정적이고 고품질의 비디오를 생성할 수 있습니다.
-
Training 과정이 아니라 inference 에서만 사용하는 이유?
생성된 이미지를 다시 DDPM fowardpass를 거쳐 고주파,저주파를 추출 이를 반복
I2V-Bench
기존 동영상 생성 벤치마크인 UCF-101(Soomro 외, 2012) 및 MSR-VTT(Xu 외, 2016)는 동영상 해상도, 다양성 및 미적 매력 면에서 부족
이러한 격차를 해소하기 위해 엄격한 해상도 및 미적 기준에 따라 평가된 2,950개의 고품질 YouTube 동영상으로 구성된 I2V-Bench 평가 데이터 세트를 소개
이러한 동영상을 풍경, 스포츠, 동물, 인물 등 16개의 카테고리로 분류
Evaluation Metrics (1) 시각 품질
입력 프롬프트와 관계없이 비디오 출력의 지각 품질을 평가
피사체와 배경의 일관성, 시간적 깜박임, 모션의 부드러움, 동적 정도를 측정
(2) 시각적 일관성
사용자가 제공한 텍스트 프롬프트에 대한 동영상의 적합성을 평가
오브젝트 일관성, 장면 일관성 및 전반적인 동영상-텍스트 일관성을 측정
Experiments
Implementation Details
base T2I model : Stable Diffusion 2.1-base dataset : WebVid-10M (Bain et al., 2021) dataset
**16 frames spatial resolution of 256 × 256 a frame interval between 1 ≤ v ≤ 5 - > FPS control a batch size of 192 a learning rate of 5e-5 for 170k steps
첫 번째 프레임을 이미지 입력으로 사용하고 학습하는 동안 이후 15개 프레임의 노이즈를 제거하는 방법을 학습
0.1의 확률로 입력 텍스트 프롬프트를 무작위로 드롭하여 classifier-free guidance 학습
inference : DDIM , 50 steps and classifier-free guidance with a guidance scale of w = 7.5
FrameInit : τ = 850 and D0 = 0.25 for inference noise initialization.
Quantitative Evaluation
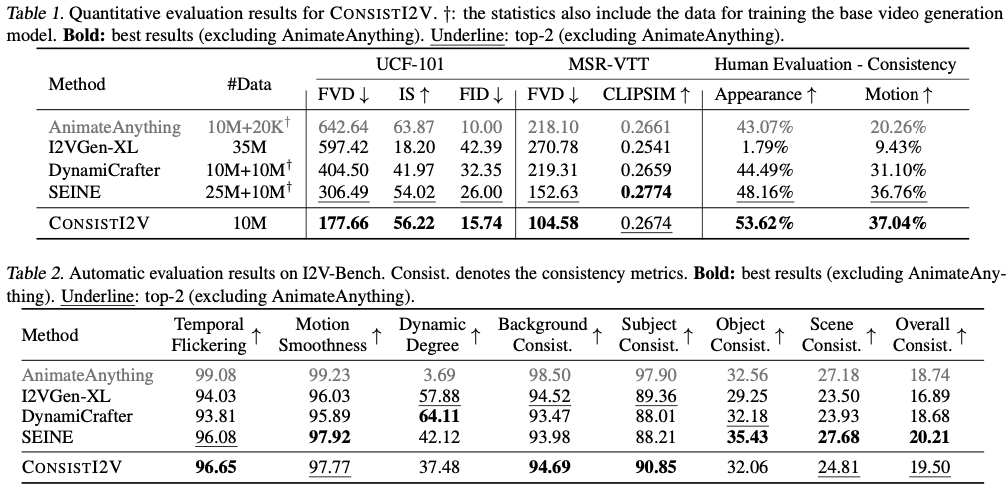
UCF-101 & MSR-VTT
AnimateAnything이 더 나은 IS와 FID를 달성하는 반면, 생성된 비디오는 대부분 정적에 가깝기 때문에(시각화는 그림 5 참조), 시각화에 심각한 제한이 있음을 관찰할 수 있습니다.
우리 모델은 모든 지표에서 다른 기준 모델보다 훨씬 뛰어난 성능을 보이지만, 결과는 SEINE보다 약간 낮은 MSR-VTT의 CLIPSIM을 제외하고는 모든 지표에서 훨씬 뛰어납니다. LaVie(Wang et al., 2023d)에서 초기화된 SEINE은 Vimeo25M, WebVid-10M 및 추가 비공개 데이터 세트를 포함한 더 크고 우수한 품질의 훈련 데이터 세트의 이점을 누리고 있습니다. 반면, CONSISTI2V는 T2I 모델에서 직접 초기화되고 WebVid-10M으로만 훈련되어 이 방법의 효율성을 보여줍니다.
I2V-Bench
AnimateAnything이 모든 모델 중에서 가장 우수한 모션 부드러움과 외형 일관성을 달성하는 것을 관찰할 수 있습니다. 그러나 모션 크기가 큰 동영상을 생성하는 데는 크게 부족하여 3.69의 낮은 동적 정도 값을 기록
반면, 저희 모델은 모션 크기와 비디오 품질 간의 균형을 더 잘 맞추고, 모션 품질(흔들림이 적고 부드러움이 좋음)과 시각적 일관성(배경/피사체 일관성이 높음) 측면에서 AnimateAnything을 제외한 다른 모든 기준 모델보다 우수한 성능을 보이며, 전체적으로 비디오와 텍스트의 일관성 측면에서 경쟁력 있는 결과를 달성
Human Evaluation
전체적인 모양과 움직임의 일관성이 가장 좋은 동영상을 식별하는 것
13명의 참가자로부터 총 1061개의 응답을 수집하여 표 1의 오른쪽에 결과를 표시했습니다. 결과에서 알 수 있듯이, 저희 모델은 두 가지 지표에서 모두 1위를 차지했으며, SEINE과 비슷한 수준의 모션 일관성을 달성하고 다른 모든 기준 모델보다 훨씬 높은 외형 일관성을 달성
Qualitative Evaluation
(1) DynamiCrafter와 SEINE의 “아이스크림” 사례에서 볼 수 있는 것처럼 비디오 중간에 피사체 외관이 갑자기 바뀌는 경우, (2) DynamiCrafter의 “자전거” 사례에서 볼 수 있는 것처럼 백그라운드 불일치, (3) 다음과 같은 부자연스러운 물체 움직임이 포함될 수 있습니다. “개 수영” 사례(DynamiCrafter) 및 “항아리 속 토네이도” 사례(SEINE), (4) AnimateAnything에서 생성된 대부분의 동영상에서 재생되지 않는 최소한의 움직임 또는 부재. 반면, CONSISTI2V는 입력된 첫 번째 프레임과 일관되게 일치하는 하위 프레임이 있는 동영상을 생성합니다. 또한, 생성된 동영상은 보다 자연스럽고 논리적인 움직임을 보여주기 때문에 갑작스러운 변화를 피할 수 있어 외형과 움직임의 일관성이 향상됩니다.
Ablation Studies
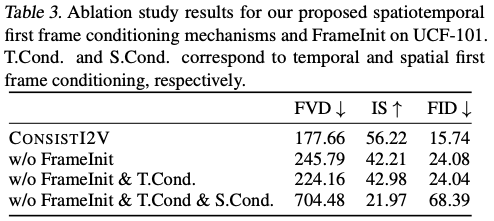
설계 선택의 효과를 검증하기 위해 프레임 초기화, 시간적 첫 프레임 컨디셔닝 및 공간적 첫 프레임 컨디셔닝을 반복적으로 비활성화하여 UCF-101에 대한 제거 연구를 수행
Effectiveness of FrameInit
경험적 관찰에 따르면 FrameInit은 출력 비디오를 안정화시키고 갑작스러운 모양과 움직임 변화를 줄일 수 있습니다. 그림 6에서 볼 수 있듯이, 우리 모델은 FrameInit을 활성화하지 않아도 여전히 합리적인 결과를 생성할 수 있지만, 출력 비디오는 갑작스러운 물체의 움직임과 흐릿한 프레임(두 번째 줄의 마지막 프레임)을 렌더링할 가능성이 더 높습니다. 이는 보다 자연스러운 움직임과 고품질 프레임을 생성하는 데 있어 FrameInit의 효과를 강조합니다.

Spatiotemporal First Frame Conditioning
제안된 공간 및 시간적 첫 번째 프레임 컨디셔닝 메커니즘을 모델에 적용한 후 성능이 크게 향상되었음을 반영합니다.
temporal 첫 번째 프레임 컨디셔닝을 제거하면 세 가지 정량적 지표의 성능이 전반적으로 향상되지만, 실제로는 spatial 컨디셔닝만 사용하면 그림 6의 세 번째 줄의 마지막 두 프레임에서 볼 수 있듯이 지터링 동작과 더 큰 물체 왜곡이 종종 발생하는 것으로 나타났습니다.
spatial 및 temporal 첫 번째 프레임 컨디셔닝을 모두 제거하면 모델은 입력된 첫 번째 프레임의 모양을 유지하는 기능을 잃게 됩니다.
-
지터링 동작이란?
“Jittering motion”은 비디오나 애니메이션에서 객체의 위치가 미세하게 흔들리는 것을 의미합니다. 이는 의도적일 수도 있고, 비의도적일 수도 있습니다. 아래는 이 개념에 대한 자세한 설명입니다.
### Jittering Motion의 정의
- 비의도적 Jittering:
- 원인: 카메라 흔들림, 프레임 간의 미세한 차이, 센서 노이즈, 압축 아티팩트 등으로 인해 발생합니다.
- 결과: 비디오에서 객체의 위치가 불규칙하게 미세하게 이동하여 시각적으로 불안정하거나 떨리는 효과를 초래합니다.
- 의도적 Jittering:
- 목적: 애니메이션이나 그래픽 디자인에서 자연스러운 움직임을 모방하거나 특정 효과를 내기 위해 사용됩니다.
- 방법: 객체의 위치를 일정한 패턴이나 무작위 방식으로 미세하게 이동시켜, 생동감이나 현실감을 부여합니다.
### Jittering Motion의 예시
- 비의도적 Jittering:
- 비디오 촬영 중 카메라 흔들림: 손으로 들고 촬영한 비디오에서 흔히 발생합니다.
- 애니메이션 프레임 간의 미세한 불일치: 프레임 간에 객체의 위치가 약간씩 다를 때 나타납니다.
- 의도적 Jittering:
- 애니메이션 효과: 캐릭터나 객체의 움직임을 더 자연스럽게 보이게 하기 위해 미세한 흔들림을 추가합니다.
- 그래픽 디자인: 특정 스타일이나 느낌을 주기 위해 의도적으로 흔들림을 추가합니다.
### Jittering Motion의 영향
- 긍정적 영향:
- 현실감 증가: 미세한 흔들림이 더 자연스럽고 현실감 있는 느낌을 줄 수 있습니다.
- 생동감 부여: 정적인 장면에 약간의 움직임을 추가하여 더 생동감 있게 보이도록 할 수 있습니다.
- 부정적 영향:
- 시각적 불안정성: 비의도적 흔들림은 시청자에게 불안정하고 거슬리는 느낌을 줄 수 있습니다.
- 품질 저하: 비디오나 애니메이션의 품질을 떨어뜨리는 요인이 될 수 있습니다.
### 해결 방법
비의도적 jittering을 해결하기 위해서는 다음과 같은 방법들이 사용됩니다:
- 비디오 안정화 소프트웨어: 촬영 후 비디오에서 jittering을 제거하는 소프트웨어를 사용하여 프레임 간의 불일치를 보정합니다.
- 하드웨어 안정화: 촬영 중 카메라 흔들림을 줄이기 위해 짐벌(gimbal)이나 삼각대(tripod)를 사용합니다.
- 후처리 필터: 비디오 편집 소프트웨어에서 jittering을 줄이기 위한 필터를 적용합니다.
### 요약
Jittering motion은 비디오나 애니메이션에서 객체의 위치가 미세하게 흔들리는 현상을 의미하며, 의도적일 수도 있고 비의도적일 수도 있습니다. 비의도적 jittering은 시각적 품질을 저하시키며, 이를 해결하기 위해 다양한 소프트웨어 및 하드웨어 기술이 사용됩니다. 반면, 의도적 jittering은 더 자연스럽고 생동감 있는 효과를 주기 위해 활용됩니다.
- 비의도적 Jittering:
More Applications

자율회귀(long autoregressive) 비디오 생성
- 기존 방법의 문제점:
- 이미지 애니메이션 모델을 사용하여 비디오를 생성할 때, 이전 비디오의 마지막 프레임을 재사용하여 다음 비디오를 생성합니다.
- 그러나 이 방식은 시간이 지남에 따라 이전 비디오 클립의 아티팩트(왜곡)가 누적되어 결과적으로 최적의 결과를 얻지 못할 수 있습니다.
- FrameInit의 역할:
- 각 비디오 청크(chunk)의 생성을 가이드하기 위해 FrameInit을 사용하면 자율회귀 비디오 생성 과정의 안정성이 향상됩니다.
- FrameInit은 첫 번째 프레임의 저주파 성분을 이용하여 비디오의 전반적인 레이아웃을 안정화하고, 고주파 성분을 추가하여 디테일을 유지합니다.
- 이를 통해 전체 비디오의 시각적 일관성이 유지되며, 누적된 아티팩트를 최소화할 수 있습니다.
카메라 모션 제어 (Camera Motion Control)
- FrameInit을 사용한 추론:
- FrameInit을 추론 과정에 사용할 때, 정적인 첫 번째 프레임 비디오 대신 합성된 카메라 모션을 사용할 수 있습니다.
- 예를 들어, 카메라 팬(panning)을 시뮬레이션하기 위해 첫 번째 프레임의 공간적 크롭(spatial crops)을 생성하고, 한쪽에서 다른 쪽으로 점진적으로 이동할 수 있습니다.
- 예시:
- FrameInit 매개변수를 \(\tau = 750\)과 \(D_0 = 0.5\)로 설정하고 합성된 카메라 모션을 레이아웃 가이드로 사용합니다.
- 이를 통해 생성된 비디오에서 카메라 팬 및 줌 인/줌 아웃 효과를 달성할 수 있습니다.
- 그림 7에서 보여주듯이, 이러한 설정을 통해 카메라 모션을 효과적으로 제어할 수 있습니다.
요약
- Autoregressive Long Video Generation: 이전 비디오 프레임의 아티팩트 누적 문제를 해결하기 위해 FrameInit을 사용하여 각 비디오 청크의 생성을 안정화하고, 시각적 일관성을 유지합니다.
- Camera Motion Control: FrameInit을 이용해 정적인 첫 번째 프레임 대신 합성된 카메라 모션을 사용하여 다양한 카메라 효과(팬, 줌 인/줌 아웃 등)를 구현할 수 있습니다.
단점
하지만 이 모델은 경우에 따라 동작이 느려지는 경우도 있습니다.
Appendix
Additional Implementation Details
Model Architecture
CONSISTI2V의 temporal layers는 spatial counterparts와 동일한 아키텍처를 공유
temporal convolution blocks의 경우, 시간 및 공간 높이와 너비 차원을 따라 커널 크기가 (3, 1, 1)인 two temporal convolution layers가 포함된 residual blocks을 생성합니다. → T = 3
temporal attention blocks 에는 하나의 temporal self-attention layer와, 시간적 기능과 인코딩된 텍스트 프롬프트 사이에서 작동하는 하나의 cross-attention layer가 포함되어 있습니다.
각 시간적 계층에 학습 가능한 가중치 γ를 추가하여 공간적 및 시간적 출력을 결합
\[\mathbf{z}_{\text{out}} = \gamma \mathbf{z}_{\text{spatial}} + (1 - \gamma) \mathbf{z}_{\text{temporal}}, \quad \gamma \in [0, 1],\]훈련 초기에 시간적 레이어가 아무런 영향을 미치지 않도록 모든 γ = 1로 초기화
Correlated Noise Initialization
이 방법은 비디오의 연속된 프레임들이 종종 비슷한 시각적 특징을 공유한다는 사실을 활용하여 초기화 과정에서의 잡음을 효과적으로 사용하기 위해 고안
기존 방법의 문제점
- 기존의 I2V(이미지에서 비디오) 생성 모델: 각 프레임의 잡음을 독립적이고 동일한 분포(i.i.d. Gaussian noises)로 초기화하는 경향이 있습니다.
- 연속된 프레임 간의 상관관계 무시: 이 접근법은 연속된 프레임 사이의 상관관계를 무시하게 되어 최적의 결과를 얻지 못할 수 있습니다.
제안된 방법: Correlated Noise Initialization
- 목적: 비디오의 인접한 프레임들이 종종 비슷한 시각적 특징을 공유한다는 선험 정보를 효과적으로 활용하는 것입니다.
- 사용된 기법: PYCoCo(Ge et al., 2023)에서 제안된 혼합 잡음 초기화(mixed noise prior)를 사용합니다.
공유된 잡음 (\(ϵ_{shared}\)):
\[\epsilon_{\text{shared}} \sim \mathcal{N}\left(0, \frac{\alpha^2}{1 + \alpha^2} \mathbf{I}\right)\]독립 잡음 (\(ϵ_{ind}^i\)):
\[\epsilon_{\text{ind}}^i \sim \mathcal{N}\left(0, \frac{1}{1 + \alpha^2} \mathbf{I}\right)\] \[\epsilon^i = \epsilon_{\text{shared}} + \epsilon_{\text{ind}}^i\]매개변수 (α)
- α는 공유된 잡음과 독립적인 잡음의 강도를 조절하는 매개변수입니다.
- 실험에서 α=1.5로 설정하여 사용되었습니다.
학습 안정성: 상관된 잡음 초기화는 학습을 안정화하고, 기울기 폭발(exploding gradients)을 방지하며, 빠른 수렴을 돕습니다.
시간적 주의 계층의 위치 임베딩 (Positional Embeddings in Temporal Attention Layers)
- 기법 사용: Wang et al. (2023d)와 Su et al. (2024)의 방법을 따라, 회전 위치 임베딩(Rotary Positional Embeddings, RoPE)을 시간적 주의 계층에 도입합니다.
- 목적: 프레임 위치 정보를 나타내기 위해.
- 적용 방법:
- 시간적 첫 번째 프레임 조건화 방법에 RoPE 임베딩을 적용합니다.
- 특정 프레임의 공간 위치 \((h, w)\)에서 쿼리 벡터가 주어지면, 첫 번째 프레임의 특징이 있는 \(\tilde{z}^1_h\)에서 키/값 토큰을 동일한 각도로 회전시킵니다.
- 이는 이 특징 윈도우가 첫 번째 프레임에서 왔음을 나타냅니다.
FPS 제어 (FPS Control)
- 기법 사용: Xing et al. (2023)의 방법을 따라, 모델에 FPS 조절을 위한 조건 신호로 학습 중 샘플링 프레임 간격을 사용합니다.
- 적용 방법:
- 주어진 훈련 비디오에서, 1에서 5 사이의 프레임 간격을 무작위로 선택하여 16개의 프레임을 샘플링합니다.
- 이 프레임 간격 값을 타임스텝 임베딩을 인코딩하는 것과 동일한 방법으로 모델에 입력합니다.
- 정수 프레임 간격 값을 사인파 임베딩으로 변환한 후, 두 개의 선형 계층을 통해 전달하여 타임스텝 임베딩과 동일한 차원을 가지는 벡터 임베딩을 생성합니다.
- 그런 다음 프레임 간격 임베딩과 타임스텝 임베딩을 더한 후, 결합된 임베딩을 U-Net 블록에 전달합니다.
- 학습 시작 시, 프레임 간격 임베딩의 두 번째 선형 계층을 0으로 초기화하여 프레임 간격 임베딩이 0 벡터가 되도록 합니다.
Training Paradigms
기존 I2V 생성 모델
- 기존 방법:
- 공동 비디오-이미지 학습 (Joint Video-Image Training):
- 비디오-텍스트와 이미지-텍스트 데이터를 교차적으로(interleaving) 학습하여 모델을 훈련.
- 대표적으로 Ho et al., 2022b의 방법이 사용됨.
- 다단계 학습 전략 (Multi-Stage Training Strategies):
- 서로 다른 유형의 데이터를 사용하여 다양한 모델 구성 요소를 반복적으로 사전 훈련(pretrain).
- 공동 비디오-이미지 학습 (Joint Video-Image Training):
제안된 모델의 이점
- 명시적 조건화 메커니즘 (Explicit Conditioning Mechanism):
- 공간 및 시간 자기 주의 계층에서의 조건화 메커니즘을 통해 첫 번째 프레임의 시각적 단서를 효과적으로 활용.
- 이로 인해 비디오 확산 모델(video diffusion model)이 고품질 프레임을 생성하는 난이도를 낮춤.
- 첫 번째 프레임의 시각적 정보를 활용하여 이후 프레임을 생성함으로써, 일관성 있고 고품질의 비디오 프레임을 얻을 수 있음.
- LDM VAE 특징 직접 사용 (Direct Use of LDM VAE Features):
- LDM VAE (Latent Diffusion Model Variational Autoencoder) 특징을 조건 신호로 직접 사용.
- 다른 특징 모달리티(e.g., CLIP 이미지 임베딩)를 위해 추가적인 어댑터 층을 훈련할 필요가 없음.
- 다른 방법들이 종종 별도의 단계에서 어댑터 층을 훈련하는 것과 달리, 제안된 모델은 이러한 추가 단계를 피함.
단일 단계에서의 학습 (Single-Stage Training)
- 학습 과정:
- 단일 비디오-텍스트 데이터셋을 사용하여 모델을 하나의 단계에서 훈련.
- 모든 파라미터를 학습 중에 미세 조정(finetune).
- 이는 모델 학습을 단순화하고, 효율성을 높이며, 추가적인 학습 단계가 필요하지 않음을 의미.
요약
제안된 모델은 기존의 I2V 생성 모델에 비해 두 가지 주요 이점을 제공합니다:
- 명시적 조건화 메커니즘을 통해 첫 번째 프레임의 시각적 단서를 효과적으로 활용하여 고품질의 프레임을 생성.
- LDM VAE 특징을 조건 신호로 직접 사용하여 추가적인 어댑터 층을 훈련할 필요 없이 모델을 단순화.
이러한 접근 방식을 통해 제안된 모델은 단일 비디오-텍스트 데이터셋을 사용하여 하나의 단계에서 효율적으로 훈련될 수 있습니다. 이로 인해 학습 과정이 단순해지고, 더 나은 성능과 일관성을 갖춘 비디오를 생성할 수 있습니다.
Limitations
- 학습 데이터셋의 문제점:
- WebVid-10M 데이터셋:
- 주로 저해상도 비디오로 구성되어 있습니다.
- 모든 비디오에 고정된 위치에 워터마크가 포함되어 있습니다.
- 영향:
- 생성된 비디오도 워터마크로 인해 손상될 가능성이 높습니다.
- 현재는 비교적 저해상도의 비디오만 생성할 수 있습니다.
- WebVid-10M 데이터셋:
- 제한된 움직임:
- FrameInit의 안정성 향상:
- FrameInit은 생성된 비디오의 안정성을 향상시킵니다.
- 문제점:
- 모델이 가끔 제한된 움직임 크기를 가진 비디오를 생성하여, 비디오 내용에서 피사체의 움직임이 제한될 수 있습니다.
- FrameInit의 안정성 향상:
- 공간 첫 프레임 조건화 방법의 문제:
- 공간 U-Net 층 튜닝 필요:
- 학습 중에 공간 U-Net 층을 튜닝해야 합니다.
- 영향:
- 모델이 개인화된 텍스트-이미지(T2I) 생성 모델에 직접 적응하는 능력을 제한합니다.
- 학습 비용이 증가합니다.
- 공간 U-Net 층 튜닝 필요:
- 기본 T2I 생성 모델의 일반적인 제한 사항:
- Stable Diffusion 모델과의 공통 한계:
- 사람 얼굴을 정확하게 렌더링하지 못함.
- 판독 가능한 텍스트를 정확히 생성하지 못함.
- Stable Diffusion 모델과의 공통 한계: