[논문분석] AV2AV: Direct Audio-Visual Speech to Audio-Visual Speech Translation with Unified Audio-Visual Speech Representation
처음 제안된 분야, Audio와 Video의 멀티모달 Translate 모델
[Page, Paper, Code]
School of Electrical Engineering, KAIST, South Korea
CVPR 2024 (Highlight)
1. Abstract
This paper proposes a novel direct Audio-Visual Speech to Audio-Visual Speech Translation (AV2AV) framework, where the input and output of the system are multimodal (i.e., audio and visual speech). With the proposed AV2AV, two key advantages can be brought: 1) We can perform real-like conversations with individuals worldwide in a virtual meeting by utilizing our own primary languages. In contrast to Speech-to-Speech Translation (A2A), which solely translates between audio modalities, the proposed AV2AV directly translates between audio-visual speech. This capability enhances the dialogue experience by presenting synchronized lip movements along with the translated speech. 2) We can improve the robustness of the spoken language translation system. By employing the complementary information of audio-visual speech, the system can effectively translate spoken language even in the presence of acoustic noise, showcasing robust perfor mance. To mitigate the problem of the absence of a parallel AV2AV translation dataset, we propose to train our spoken language translation system with the audio-only dataset of A2A. This is done by learning unified audio-visual speech representations through self-supervised learning in ad vance to train the translation system. Moreover, we propose an AV-Renderer that can generate raw audio and video in parallel. It is designed with zero-shot speaker modeling, thus the speaker in source audio-visual speech can be maintained at the target translated audio-visual speech. The effectiveness of AV2AV is evaluated with extensive ex periments in a many-to-many language translation setting.
이 백서에서는 시스템의 입력과 출력이 멀티모달(즉, 오디오와 시각적 음성)인 새로운 직접 오디오-비주얼 음성-음성 번역(AV2AV) 프레임워크를 제안합니다. 제안된 AV2AV를 사용하면 두 가지 주요 이점을 얻을 수 있습니다. 1) 가상 회의에서 전 세계 개인과 자신의 모국어를 활용하여 실제와 같은 대화를 수행할 수 있습니다. 오디오 양식 간에만 번역하는 A2A(음성 대 음성 번역)와 달리, 제안된 AV2AV는 오디오-시각적 음성 간을 직접 번역합니다. 이 기능은 번역된 음성과 함께 동기화된 입술 움직임을 보여줌으로써 대화 경험을 향상시킵니다. 2) 음성 언어 번역 시스템의 견고성을 향상시킬 수 있습니다. 시청각 음성의 상호 보완적인 정보를 활용하여 음향 소음이 있는 상황에서도 음성 언어를 효과적으로 번역하여 강력한 성능을 보여줄 수 있습니다. 병렬 AV2AV 번역 데이터 세트의 부재 문제를 완화하기 위해 A2A의 오디오 전용 데이터 세트로 음성 언어 번역 시스템을 훈련할 것을 제안합니다. 이는 번역 시스템을 훈련하기 위해 사전에 자기 지도 학습을 통해 통합된 시청각 음성 표현을 학습하는 방식으로 이루어집니다. 또한 원시 오디오와 비디오를 병렬로 생성할 수 있는 AV-Renderer를 제안합니다. 제로 샷 스피커 모델링으로 설계되어 소스 시청각 음성의 스피커를 번역된 시청각 음성에서 그대로 유지할 수 있습니다. AV2AV의 효과는 다대다 언어 번역 환경에서 광범위한 실험을 통해 평가됩니다. 데모 페이지는 choijeongsoo.github.io/av2av에서 확인할 수 있습니다.
2. Introduction
문제점
- Neural Machine Translation (NMT) 많이 발전함 하지만, NMT는 가상 회의나 대면 상호 작용에 원활하게 적용하는 데는 한계가 있음 텍스트 양식으로 작동 → 텍스트 입력이나 음성 인식을 위해 사람의 개입에 의존
→ 화상과 같은 환경에서 오디오와 비디오의 동시 번역이 필요할거다.
- 비디오와 음성의 싱크를 맞춰야 함 (기존에 A2A는 오디오 음성만 처리)
- 일관되지 않은 시각 정보는 (맥거크 효과) 음성에 부정적인 영향을 미칠 수 있으므로 오디오와 비주얼을 함께 고려하는 방식이 개발 필요
AV 음성 간의 번역 데이터가 부족 → NMT를 위한 텍스트 기반 데이터셋과 음성-텍스트 번역(A2T) 및 A2A를 위한 음성 기반 데이터셋은 비교적 풍부하지만, 공개적으로 사용 가능한 AV2AV 데이터셋 부족
해결책
사전 학습에 모달리티 드롭아웃이 포함 → 오디오와 시각 정보 동시에 입력 가능, 두 데이터셋을 동시에 사용 한다.
이를 위해 100개 이상의 언어가 포함된 약 7,000시간 분량의 다국어 AV 데이터셋으로 모델을 사전 학습시켜 다국어 훈련된 AV-HuBERT(mAV-HuBERT)를 도입
mAV-HuBERT에서 통합된 AV 음성 표현을 K-평균 클러스터링을 통해 이산화하여 AV 음성 단위를 산출
번역된 AV 음성 유닛에서 오디오 및 시각적 구성 요소를 렌더링하기 위해 동기화된 원시 음성 오디오와 말하는 얼굴 비디오를 동시에 생성할 수 있는 AV 음성 유닛 기반 AV-Renderer를 도입
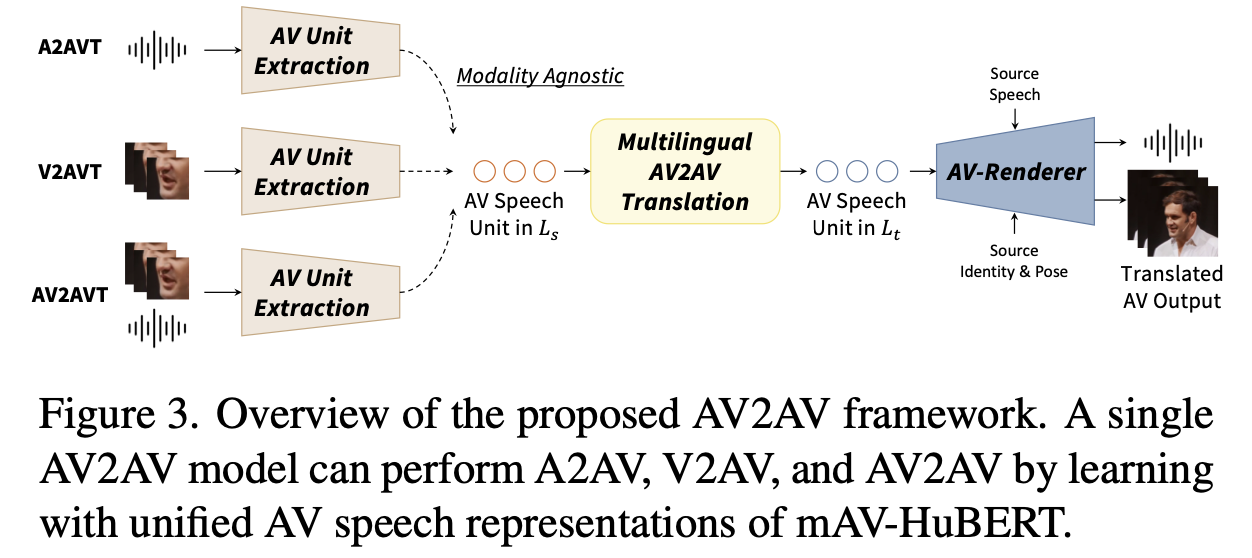
3. Proposed Method
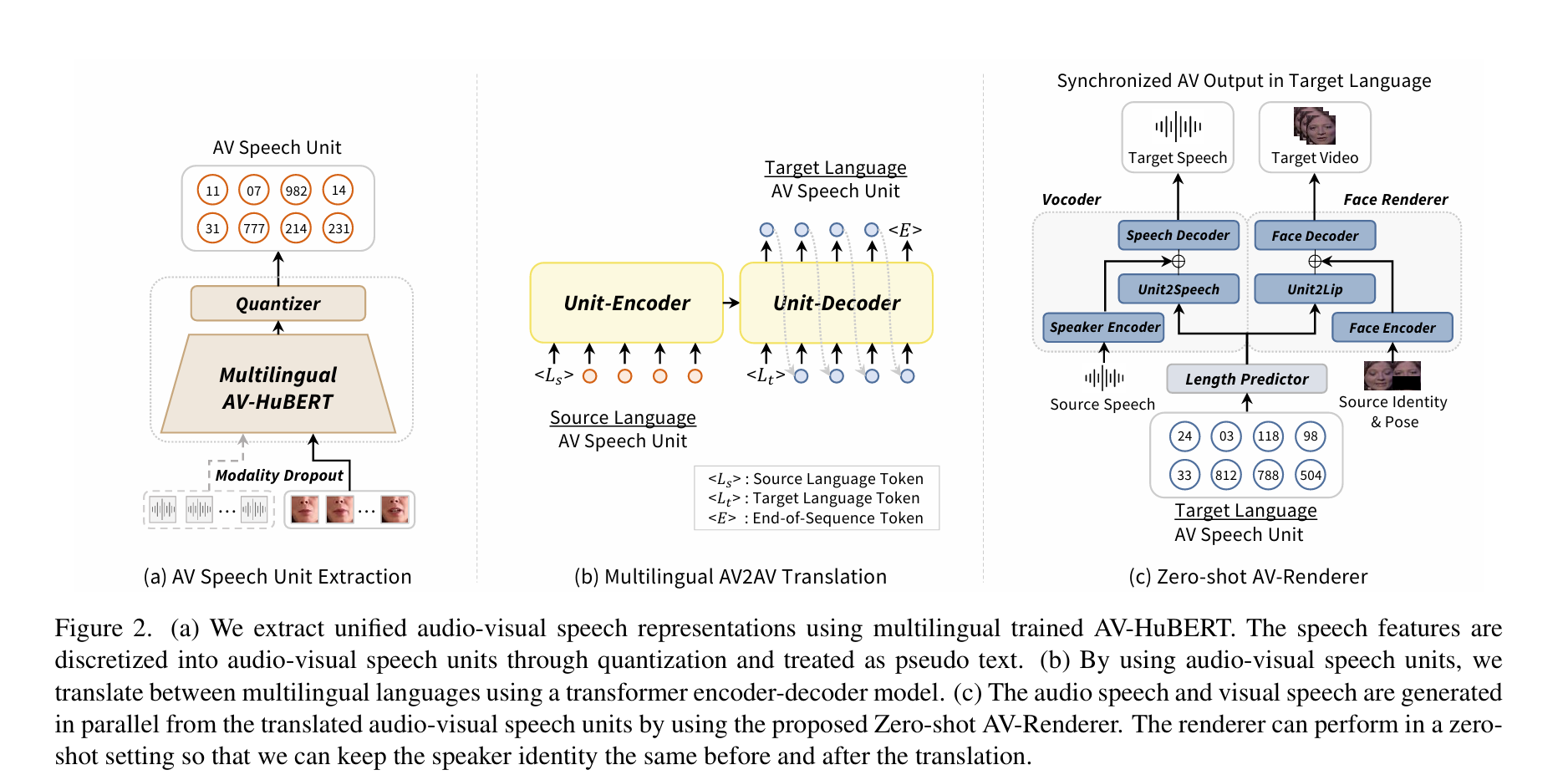
1) AV 음성 유닛으로 AV 입력에서 언어 콘텐츠를 추출
2) AV 음성 유닛을 사용하여 번역을 수행
3) 번역된 AV 음성 유닛에서 스피치를 화자 특성으로 제어할 수 있는 상태에서 합성
3.1 Unified Audio-Visual Speech Representations
AV2AV 시스템을 훈련하기 위해서는 기본적으로 AV 음성의 병렬 말뭉치가 필요
사용 가능한 ‘시청각에서 시청각으로’(AV2AV) 번역 데이터가 없기 때문에 병렬 AV2AV 데이터 설정에서 모델을 훈련하는 것은 불가능
AV-HuBERT가 입력 방식에 관계없이 통합된 AV 음성 표현을 추출할 수 있다는 최근 연구에서 영감을 얻음
해당 시각 입력이 제거된 오디오 전용 입력을 사용 음성 언어 번역 모델을 학습
다국어 시청각 데이터를 LRS2, LRS3, VoxCeleb2, mTEDx, AVSpeech를 결합하여 사전 학습하며, 총 약 100개 이상의 언어가 포함
양자화(즉, K-평균 클러스터링)를 통해 mAV-HuBERT의 통합된 AV 음성 표현을 이산화하고 AV 음성 단위를 얻음
mAV-HuBERT는 AV-HuBERT [52]와 유사한 모달리티 드롭아웃으로 훈련되므로 오디오 전용, 시각 전용, 시청각 등 다양한 입력 모달리티를 사용하여 AV 음성 단위를 안정적으로 얻을 수 있음
오디오 병렬 말뭉치 데이터셋을 사용하여 AV2AV 번역 모델을 훈련하는 동시에 비디오 입력도 같이
3.2 Multilingual Spoken Language Translation
12-layer unit-encoder and a 12-layer unit-decoder의 transformer 구조 사용
A2A(Action-to-Action) 방법을 적용하여 many-to-many spoken language translation을 수행
- 인코더는 소스 언어의 토큰 <\(L_s\)> 를 받아 해당 언어의 의미를 파악하며, 오디오-비주얼(AV) 음성 유닛 \(\mathbf{u}_s = \{ u_s^i \}^{T_s}_{i=s}\) 를 받음. \(T_s\)는 소스 유닛의 길이 의미
- 디코더는 타겟 언어의 토큰 <\(L_t\)>를 받아 번역할 언어를 결정하고, 이전 단계의 예측 결과를 바탕으로 Autogressive 방식으로 다음 타겟 언어의 AV 음성 유닛을 예측
손실 함수 : 타겟 언어의 각 음성 유닛을 소스 언어의 유닛과 이전에 예측한 결과들에 기반하여 예측한 확률의 로그값을 합한 것
\[\mathcal{L} = - \sum_{j=1}^{T_t} \log p\left(u_t^j \mid u_t^{<j}, \mathbf{u}_s \right),\]타겟 언어의 AV 음성 유닛 시퀀스 길이 \(T_t\)만큼 반복하여 손실을 계산함
\(u^t_j\) : 타겟 언어의 j-번째 AV 음성 유닛
\(u_t^{<j}\) : 타겟 언어의 j-번째 유닛 이전까지의 모든 예측 값 (타겟 언어 시퀀스의 이전 유닛들)
\(\mathbf{u}_s\) : 소스 언어의 AV 음성 유닛 (즉, 소스 언어로부터 추출한 음성 특징들)
\(p(u_t^j∣u_t^{<j},\mathbf{u}_s)\) : 주어진 소스 언어의 AV 음성 유닛 \(\mathbf{u}_s\)와 타겟 언어의 이전 음성 유닛 \(u_t^{<j}\) 가 주어졌을 때, 다음 j-번째 타겟 유닛 \(u_t^j\) 를 예측하는 확률
log : 로그 함수는 모델의 예측 확률에 로그를 취해 손실 값을 계산하는 데 사용. 로그를 취함으로써 손실 함수가 더 안정적으로 작동, 작은 확률 값에 대한 손실이 커짐.
mTEDx 및 VoxPopuli로 구축된 대규모 A2A 병렬 데이터셋으로 AV2AV 언어 번역 모델을 훈련
9개 언어로 구성된 약 12,000시간 분량이며 (번역 방향을 반대로 하면 데이터 양이 두 배)
3.3 Zero-shot Audio-Visual Renderer
Length Predictor
오디오와 비디오의 동기화 작업 → 공통 지속 시간 모델링
TTS와 마찬가지로 하나의 분류기가 있는 두 개의 1D 컨볼루션 레이어로 구성
로그 영역에서 각 단위의 예측과 기준값 간의 평균 제곱 오차 손실로 훈련
번역된 AV 음성 단위는 보코더와 얼굴 렌더러를 통과하기 전에 예측된 지속 시간만큼 반복
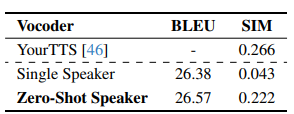
Vocoder
보코더는 기본적으로 음성 유닛 기반의 HiFiGAN을 활용한 선행 연구를 따르며, 선행 연구들이 단일 화자 음성만 지원하기 때문에 모델에 제로 샷 스피커 모델링 기능을 추가로 추가
다중 화자 TTS [96]와 유사하게 사전 학습된 스피커 검증[95] 모델을 화자 인코더로 활용하여 화자 임베딩을 추출
Mel-spectrogram을 사용하여 d-벡터로 알려진 단일 스피커 임베딩을 생성
d-벡터(단일 스피커 임베딩을 생성)는 임베딩 레이어(즉, Unit2Speech972(c))에 의해 임베딩되는 AV 음성 유닛의 모든 임베딩 피처에 연결
연결된 피처는 HiFi-GAN [92]과 아키텍처 및 훈련 목표가 동일한 음성 디코더에 공급되어 파형을 생성
Face Renderer
얼굴 렌더러의 경우, 마우스 오디오 기반 얼굴 합성 모델인 Wav2Lip[27]을 가져와 AV 음성 장치를 입력으로 작동하도록 수정
4. Experiment
4.1. Dataset
- m-AVHuBERT 훈련:
- 7,011 시간의 다중 언어 AV 데이터를 사용하며, LRS2, LRS3, VoxCeleb2, mTEDx, AVspeech 데이터를 결합하여 훈련
- AV2AV 언어 번역 모델 훈련:
- 12,000 시간 분량의 A2A 평행 데이터 사용.
- 19개 언어를 포함하는 다국어 데이터셋은 Voxpopuli와 mTEDx를 통해 구성.
- 다대다 언어 번역 설정에서 훈련된 후, LRS3-T와 MuAViC 평가 데이터셋에서 파인튜닝을 진행
- LRS3-T는 LRS3 데이터셋에서 파생된 AV2A 데이터로, 영어-스페인어, 영어-프랑스어 번역 방향을 포함.
- MuAViC는 TED 및 TEDx의 AV2T 데이터로부터 파생된 음성-텍스트 번역 데이터
- 목표 텍스트만 제공되므로 사전 훈련된 VITS 모델을 사용하여 타겟 음성을 생성
- 4개의 영어와 4개의 타 언어(스페인어, 프랑스어, 포르투갈어, 이탈리아어)로 구성된 번역 쌍 데이터를 사용하여 훈련, 총 2,356시간의 데이터 사용.
- Vocoder 훈련:
- LRS3와 mTEDx 데이터를 사용하여 음성 합성 모델인 Vocoder를 훈련
- 얼굴 렌더링:
- 얼굴 렌더링 모델을 훈련하기 위해 LRS3 데이터셋을 사용
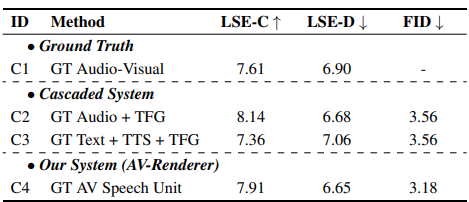
4.2. Evaluation Metrics
- 번역 품질 평가:
- BLEU 점수를 사용하여 평가.
- 오디오를 텍스트로 변환하기 위해 사전 훈련된 ASR(자동 음성 인식) 모델을 사용하여 번역 품질을 측정.
- 비디오 생성 품질 평가:
- Fréchet Inception Distance (FID): 시각적 품질 평가.
- LSE-C 및 LSE-D: 오디오-비디오 동기화 평가.
- Mean Opinion Score (MOS) 테스트:
- 각 모달리티(오디오, 비디오)의 자연스러움과 비디오의 현실성을 평가.
4.3. Implementation Details
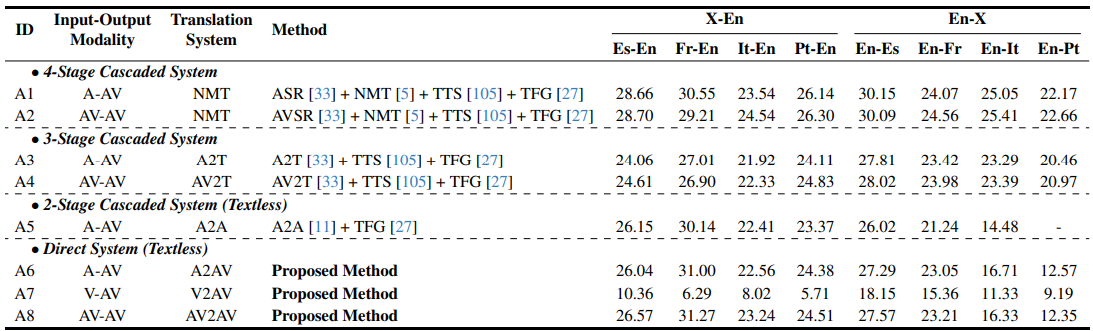
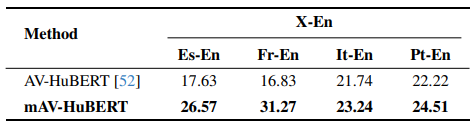
Table 2. Translation quality (ASR-BLEU) comparison with baseline systems for X-En and En-X directions on MuAViC. Methods (A1,A2, A3, A4) use the same model for X-En, and 4 different models for En-X directional translations. The methods (A5, A6, A7, A8) use a single model for all 8 directional translations. A2A method does not have a vocoder to generate Portuguese speech.