[논문분석] Textless Unit-to-Unit training for Many-to-Many Multilingual Speech-to-Speech Translation
Hubert를 활용한 Unit Multilingual S2S translation
[Page, Paper, Code]
Minsu Kim∗, Jeongsoo Choi∗, Dahun Kim, Yong Man Ro
1. Abstract
This paper proposes a textless training method for many-to-many multilingual speech-to-speech translation that can also benefit the transfer of pre-trained knowledge to text-based systems, text-to-speech synthesis and text-to-speech translation. To this end, we represent multilingual speech with speech units that are the discretized representations of speech features derived from a self-supervised speech model. By treating the speech units as pseudo-text, we can focus on the linguistic content of the speech, which can be easily associated with both speech and text modalities at the phonetic level information. By setting both the inputs and outputs of our learning problem as speech units, we propose to train an encoder-decoder model in a many-tomany spoken language translation setting, namely Unit-to-Unit Translation (UTUT). Specifically, the encoder is conditioned on the source language token to correctly understand the input spoken language, while the decoder is conditioned on the target language token to generate the translated speech in the target language. Therefore, during the training, the model can build the knowledge of how languages are comprehended and how to relate them to different languages. Since speech units can be easily associated from both audio and text by quantization and phonemization respectively, the trained model can easily transferred to text-related tasks, even if it is trained in a textless manner. We demonstrate that the proposed UTUT model can be effectively utilized not only for Speech-to-Speech Translation (S2ST) but also for multilingual Text-to-Speech Synthesis (T2S) and Text-to-Speech Translation (T2ST), requiring only minimal fine-tuning steps on text inputs. By conducting comprehensive experiments encompassing various languages, we validate the efficacy of the proposed method across diverse multilingual tasks. Moreover, thanks to the many-to-many language training, we show that the UTUT can also perform language translations for novel language pairs that are not present during training as pairs, which has not well been explored in the previous literature.
다대다 다국어 음성-음성 번역을 위한 텍스트 없는 학습 방법을 제안
음성 유닛 사용해 encoder, decoder 훈련
음성 단위는 각각 quantization와 phonemization 를 통해 오디오와 텍스트 모두에서 학습 가능
훈련된 모델은 텍스트 관련 작업으로 쉽게 전환 가능
2. Introduction
we propose a textless many-to-many multilingual speech to-speech translation method, namely Unit-to-Unit Translation (UTUT).
Multilingual Quantizer 를 통해 오디오 압축 → latent space에서 처리 (translate)
최초의 textless S2ST
3. Proposed Method
\(x \in \mathbb{R}^{T \times C}\) 로 input을 생성 (T 는 speech 길이, C 는 채널)
we quantize the speech into speech units (\(u ∈ \mathbb{R}^S\) , S 는 speech units 길이 ) by clustering the extracted features from a self-supervised speech model
speech units 는 speech model subsamples 에 따라 다름
3.1 Speech Unit Extraction
spoken language에서 textless NLP technologies는 이미 좋은 성능을 가짐 (discretizing the input speech into speech units)
wav2vec2.0 [37] and HuBERT [35] 모델 활용
따라서 multilingual 집중
we can tokenize the multilingual speech into speech units with a fixed dictionary size.
음성과 텍스트 동시 학습 가능 ( easily transferred ), multimodalities
detail
VoxPopuli의 레이블이 없는 음성 데이터셋으로 학습된 multilingual HuBERT(mHuBERT)를 사용
16kHz와 1채널 오디오 x를 입력으로 받아 음성 특징에 임베드
결과 음성 특징은 50fps
K-평균 클러스터링을 사용하여 음성 특징을 단위로 정량화하고 단위의 순차적 반복을 제거하여 모델 학습을 위한 입력 및 출력 음성 단위 u를 생성
mHuBERT의 11번째 계층을 사용하여 음성 특징과 1,000개의 어휘 크기를 추출
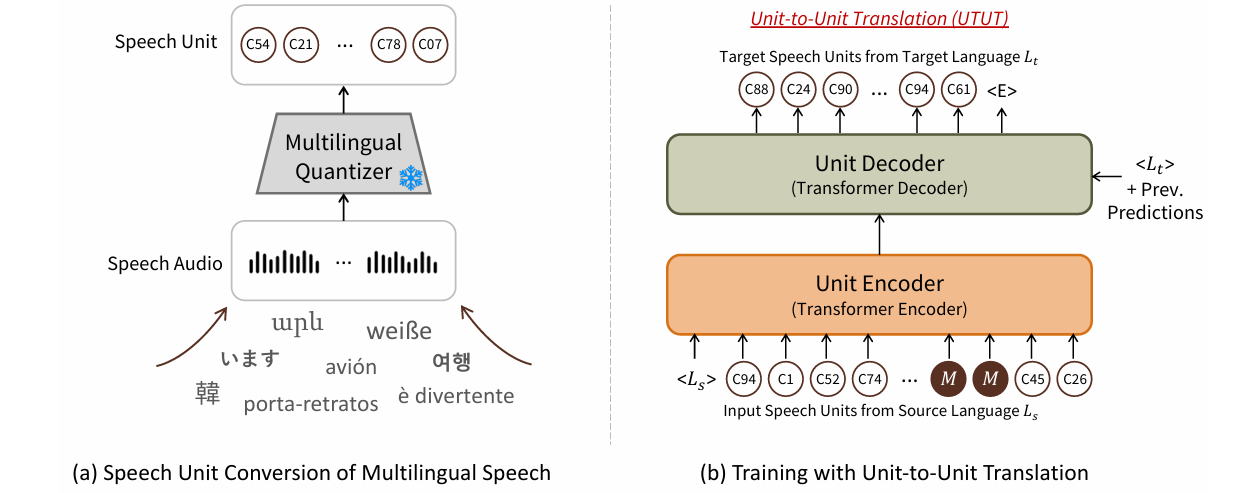
3.2 Unit-to-Unit Translation (UTUT)
a fixed size vocabulary를 받아 Translation
인코더가 입력되는 speech units의 언어를 알 수 있도록 소스 언어 토큰으로 unit encoder를 condition
→ 유닛 디코더는 target language token을 condition하여 sequence-to-sequence로 target speech unit 생성
(1) Architecture :
transformer 기본 형태 사용 : 12개의 transformer encoder, 12개의 transformer decoder layer
encoder : source 언어 토큰
decoder : target 언어 토큰
이전 예측을 입력으로 받음
encoder attention에서 인코딩된 speech units이 들어가 target 언어로 번역
(2) Learning :
S2ST pair dataset 사용, → \(x_s\) and \(x_t\)
s represents the speech data from source language $L_s$
t represents that of the target language $L_t$
Loss
\[\arg\max_{\theta} \sum_{i} \log p(u_{t}^{i} | u_{t}^{<i}, u_s, L_s, L_t; \theta)\]θ is themodel parameter
\(u_t^{<i}\) is the previous predictions before the step $i$.
인코더는 모든 En-to-X 방향 번역 데이터 쌍으로부터 영어(En)에 대한 지식을 습득
디코더는 마찬가지로 모든 X-to-End 데이터 쌍(X는 다국어를 나타냄)으로부터 En을 학습
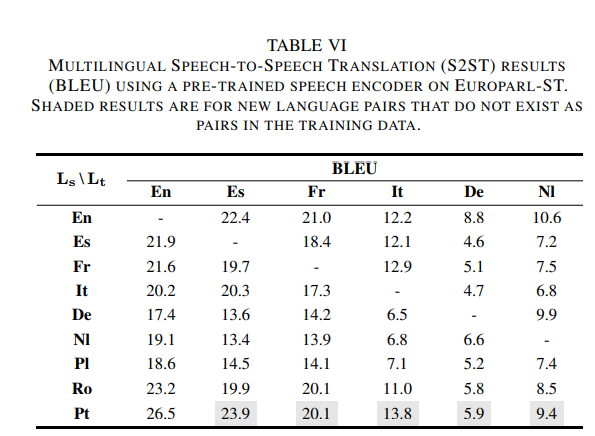
따라서 학습 데이터에 Pt-Espair가 포함되어 있지 않더라도 다른 데이터 쌍(예: Pt-X 및 X-Es)을 사용하여 Pt를 Es로 변환하는 방법을 학습
번역 방향 2가지로 활용
무작위 마스킹 기법 사용 : span lengths는 Poisson distribution(λ=10)에서 가져오고 스팬에 해당하는 프레임은 마스크 토큰 M으로 대체
training detail
-
500k steps with a peak learning rate of 0.003
-
warm up steps of 10k
-
Adam optimizer and linear learning rate decay scheduling
-
Each batch is constructed of up to 1,024 source and target tokens
-
All experiments are performed with Fairseq library
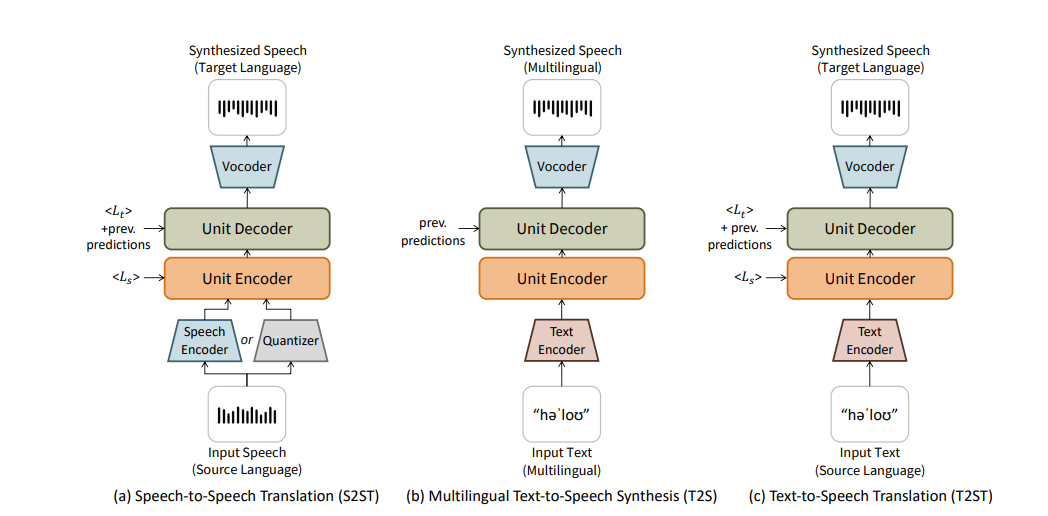
(3) DownstreamTasks
음성 단위는 불연속적이며 주로 언어 정보를 포함
음성과 텍스트 모두 음성 단위의 학습된 잠재 공간으로 쉽게 전송 가능함
음성 대 음성 번역(S2ST), 다국어 텍스트 대 음성 합성(T2S), 텍스트 대 음성 번역(T2ST)에 대해 제안한 UTUT가 효과적
음성 신호 혹은 텍스트 모두 hubert를 통해 임베딩 → 이후 유닛 기반 HiFi-GAN 보코더를 활용
4. Experimental Setup
Multilingual Dataset
19 language
4.1 Speech to Speech translation
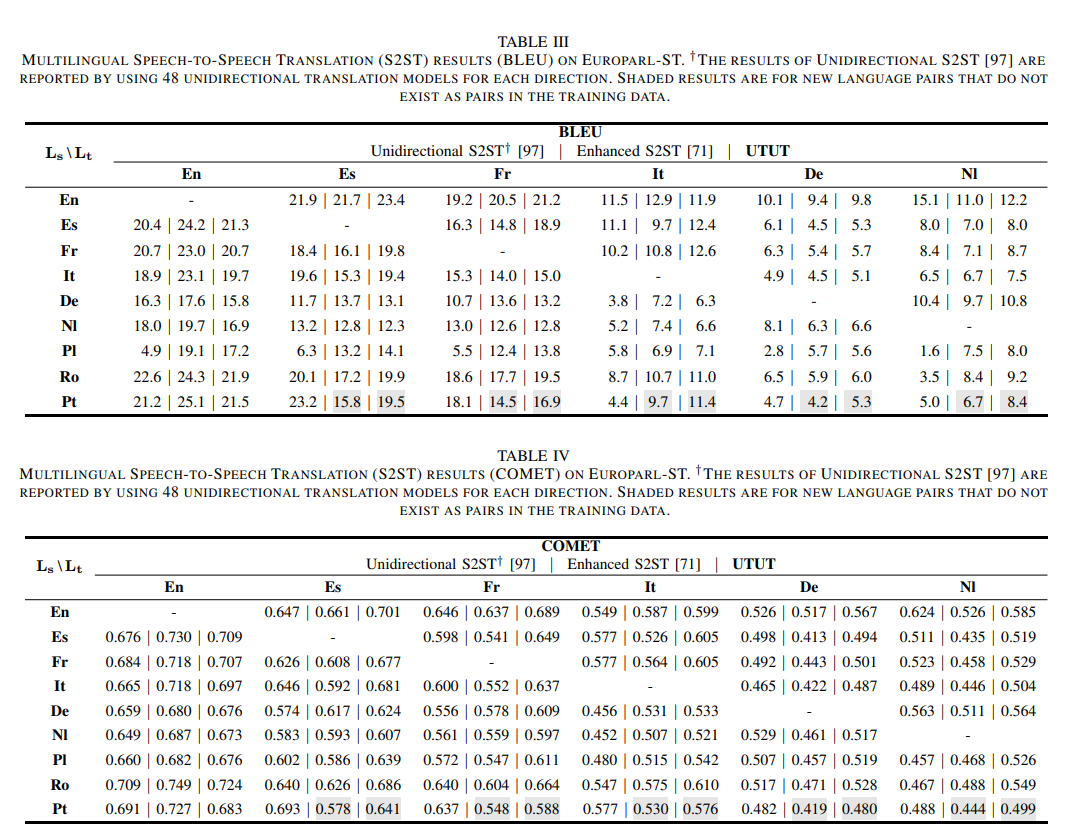
UTUT 모델은 48개의 언어쌍 중 32개에서 기존 유니디렉셔널 모델과 비교하여 더 나은 성능을 보여주었으며, 훨씬 적은 데이터로도 그 성능을 달성
Pt-X (포르투갈어에서 다른 언어로 번역)에서는 Pt-En(포르투갈어-영어) 데이터만 사용했으며, X-It(다른 언어에서 이탈리아어) 번역의 경우 21배 적은 데이터를 사용하여 학습
이는 다-대-다 학습이 하나의 언어쌍을 넘어서 다른 언어쌍 간 상호 학습을 가능하게 함
데이터의 절감 효과
5. Ablation Study