[논문분석] Person in Place: Generating Associative Skeleton-Guidance Maps for Human-Object Interaction Image Editing
object에 매칭되는 person의 pose를 denoise한 이후, 생성된 skeleton pose를 가지고 image Editing (stable diffusion)
object image를 패치단위로 쪼개 해당 부분이 skeleton의 관절 부분과 얼마만큼의 관련성이 있는지를 GNN을 활용해 연산 (node : 관절, edge : 몸)
Abstract
Recently, there were remarkable advances in image editing tasks in various ways. Nevertheless, existing image editing models are not designed for Human-Object Interaction (HOI) image editing. One of these approaches (e.g. ControlNet) employs the skeleton guidance to offer precise representations of human, showing better results in HOI image editing. However, using conventional methods, manually creating HOI skeleton guidance is necessary. This paper proposes the object interactive diffuser with associative attention that considers both the interaction with objects and the joint graph structure, automating the generation of HOI skeleton guidance. Additionally, we propose the HOI loss with novel scaling parameter, demonstrating its effectiveness in generating skeletons that interact better. To evaluate generated object-interactive skeletons, we propose two metrics, top-N accuracy and skeleton probabilistic distance. Our framework integrates object interactive diffuser that generates object-interactive skeletons with previous methods, emonstrating the outstanding results in HOI image editing. Finally, we present potentials of our framework beyond HOI image editing, as applications to human-tohuman interaction, skeleton editing, and 3D mesh optimization.
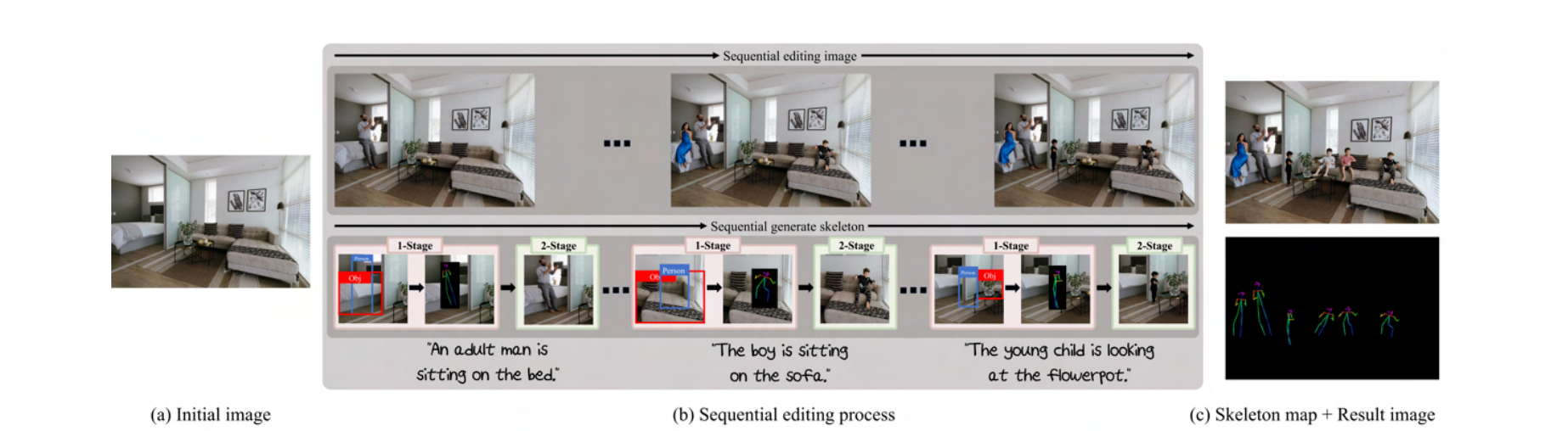
Figure 1. Human-object interaction (HOI) image editing using generated skeleton: We synthesize human interacting with objects for an initial image using the automated object-interactive diffuser. (a) an initial image to edit. (b) the sequential process of synthesizing human image with object-interactive skeletons using textual conditions. Given human bounding box and object bounding box our objectinteractive diffuser generate a skeleton interacting with the object. Then a skeleton guided image editing model edit the image with the generated skeleton. (c) a final result image with the skeleton map. Our method generates the high quality object interactive skeleton map, and it can easily plug in to the skeleton guided generative model for HOI image editing.
Introduction
InstructPix2Pix : Text를 통해 image를 Editing
masking 을 활용해 원하는 부분 수정 하는 기술
Human-object interaction (HOI) 부분 → 퀄리티가 낮음
ControlNet : 다양한 condition을 다룰 수 있도록 함
논문에서 제안하는 방법은 2개의 stage로 나뉨
- generate object-interactive skeletons
- Control-Net : Image Editing (skeleton-guided image editing models)
Novel Associative Attention (A.A.) Module
딥러닝 모델에서 입력 간의 관계를 효과적으로 학습하기 위해 설계된 새로운 형태의 attention 메커니즘
associativity(관계성)을 파악하는데 중점을 둠
| 기존 Self-Attention | Novel Associative Attention | |
|---|---|---|
| 입력 관계 계산 | 모든 입력 쌍을 계산 | 선택적으로 중요한 관계 계산 |
| 계산 복잡도 | O(n2) (입력 길이에 비례) | O(nlogn) 또는 더 낮음 |
| 희소성 지원 | 없음 (Dense Attention) | 있음 (Sparse Attention) |
| 적용 사례 | 일반적인 NLP, CV 작업 | 대규모 데이터, 복잡한 관계 학습 |
입력 데이터: 텍스트 문장, 이미지 패치, 또는 그래프 노드에서 주로 사용
object conditioning : key, value
image conditioning + noise pose embedding : query
→ joint-wise features를 뽑아냄
Related Work
Image Editing
Skeleton Guided Image Generation
Human Object Interaction (HOI)
Attention Mechanism
Method
3 stage : feature extractor, object interactive diffuser, and skeleton guided image editing model
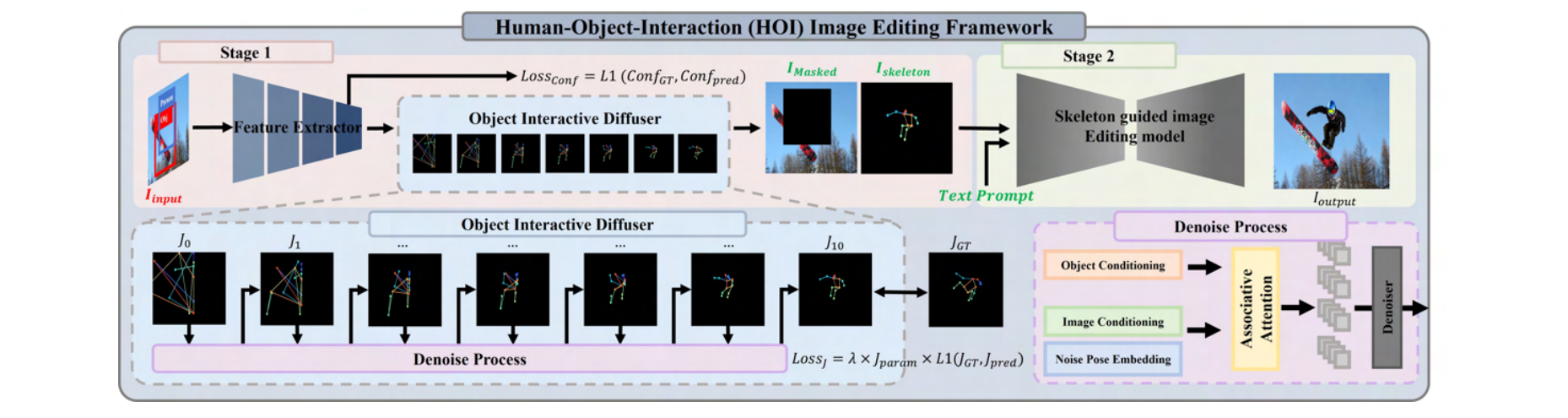
Feature Extraction
input image : \(I_{input} ∈ \mathbb{R}^{256×256×3}\)
- 사람을 Bounding box 처리 → 분석 대상 사람
object features : \(F_{Obj}∈\mathbb{R}^{8×8×1024}\)
- Pretrained third ResNet block’s feature maps 활용
- 공간적(spatial) 정보를 유지
- ROI Pooling(Region of Interest Pooling) → 특정 관심 영역만 집중적으로 처리
Image feature : \(F_{Obj}\)
- Pretrained Fourth ResNet block’s feature maps 활용
- MLP 활용 ⇒ Each joint confidence 출력
Object Interactive Diffuser
object-interactive skeleton generation
A.A. network를 통해 denoise embedding (기존 모듈과 다르게 GNN 사용)
joint 사이의 relationship을 표현
Objective Interactive Conditioning
\[I_{\text{condition}} = f(F_{\text{img}}) \in \mathbb{R}^{N_J \times N_E}\]f(·) is MLP network
image conditioning 은 이후 noise pose embedding 과 concat (NJ)
NJ is the number of joints and NE be the embedding dimension
\[\text{Obj}_{\text{condition}} = \text{Conv}(F_{\text{Obj}}) \in \mathbb{R}^{N_P \times N_E}\]Np be the dimension of pooled feature
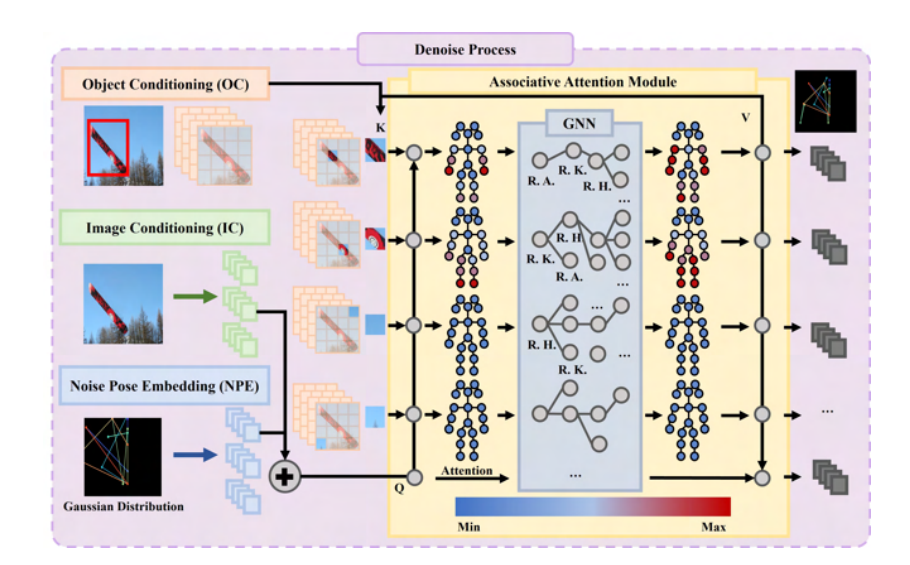
Associative Attention Network
- 쿼리(Q): $Q=I_{condition}+NPE$
- 키(K): $K=Obj_{condition}$
Adjacency Matrix : joint 간의 연결 구조 행렬 , \(A_{adj}∈R^{N_J×N_J}.\)
MSCOCO 데이터셋의 스켈레톤 구조
\[G(A) = A_{\text{adj}} \cdot A \cdot \mathcal{W} \in \mathbb{R}^{N_J \times N_P}\]- W는 학습 가능한 가중치 행렬, GNN이 관절 간의 정보를 학습
- G(A): Joint Embeddings
GNN은 관절 간의 연결성을 고려 → propagate
관절간의 연결을 graph로 표현하고 이를 GNN으로 연산
Associative Attention Computation
\[\mathcal{J} = \mathrm{softmax}(\mathcal{G}(A)) · V\]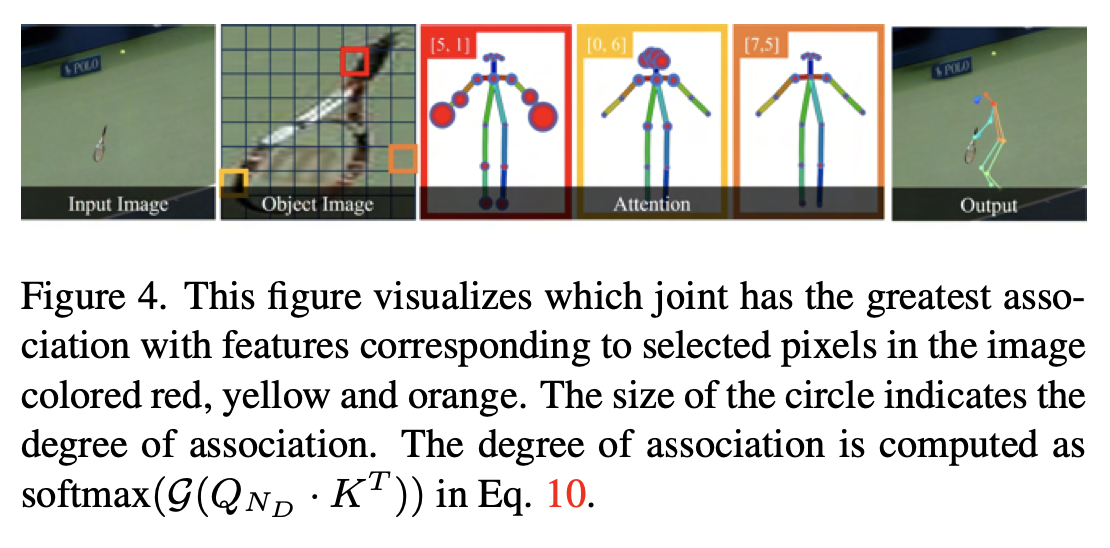
obj의 작은 patch 단위로 각 관절 node와의 연관성 (attention) 차이를 보임
Iterative Denoising Process
i-th denoising block
\[Q_i = I_{\text{condition}} + J_{i-1}\] \[A_i = Q_i \cdot K^T\] \[J_i = \text{softmax}(G(A_i)) \cdot V\]$N_D = 10$으로 선택
Skeleton Guided Image Editing
person bounding box가 mask 된 이미지 + 생성된 skeleton 사용
기존 Pretrained model 사용
Network Training
trained end-to-end
\[L_{\text{HOI}} = \lambda \times J_{\text{param}} \times L_{\text{joint}}^{\text{init}} + L_{\text{conf}}\]\(L_{\text{joint}}^{\text{init}}\) : L1 distance from GT joints
\(L_{\text{conf}}\) : L1 loss be- tween predicted confidences and GT confidences
\[J_{\text{param}} = \text{softmax} \left( \frac{1}{\text{dist}(J_{\text{GT}}, \text{center}(B_{\text{object}}))} \right)\]center(·) : computes the center of a bounding box
penalize loss and reward loss
객체 중심과 관절(GT joint) 간의 거리가 멀어질수록 손실을 증가, 가까워질수록 손실을 감소
dist(⋅,⋅): Euclidean Distance , 바운딩 박스의 중심과 관절 위치 간의 거리
이를 통해 객체 중심과 관절 간의 거리를 효과적으로 학습하도록 모델을 유도
$λ=10^4$ 사용
Experiments
Metrics
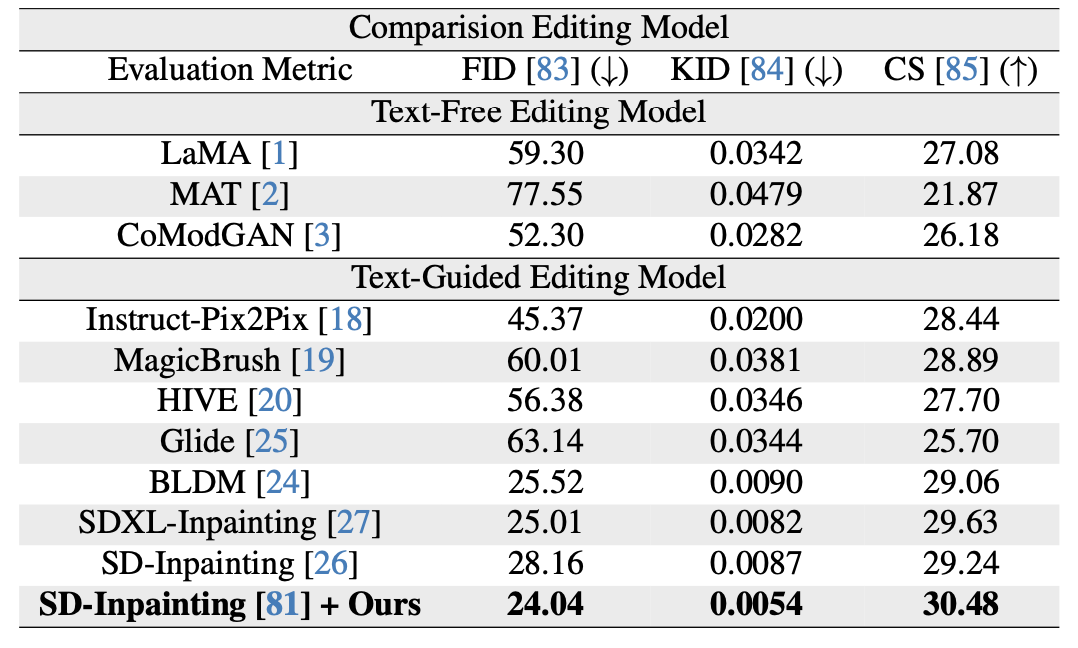
the quality of images
Fre`chet Inception distance (FID), Kernel Inception distance (KID ) and CLIP score (CS)
the quality of interaction
Skeleton Probability Distance (SPD)
IoU (Intersection over Union) + Softmax를 통한 정규화 + Jensen-Shannon Distance 계산
\[\mathcal{B}_P = \text{softmax}(\text{IoU}(\mathcal{B}_{\text{object}}, \mathcal{B}))\] \[\text{SPD}(\mathcal{B}, \hat{\mathcal{B}}; \mathcal{B}_{\text{object}}) = \text{dist}(\mathcal{B}_P, \hat{\mathcal{B}}_P)\]dataset
score

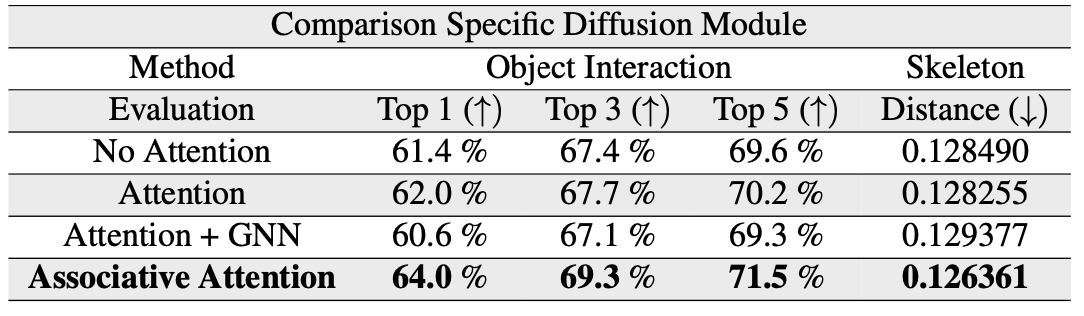
Ablation study