[논문분석] DiffTalk: Crafting Diffusion Models for Generalized Audio-Driven Portraits Animation
audio signals + face images + landmarks → 통합으로 conditioning [Paper, Code]
Author: Shuai Shen, Wenliang Zhao, et al.
Talking head synthesis is a promising approach for the video production industry. Recently, a lot of effort has been devoted in this research area to improve the generation quality or enhance the model generalization. However, there are few works able to address both issues simultaneously, which is essential for practical applications. To this end, in this paper, we turn attention to the emerging powerful Latent Diffusion Models, and model the Talking head generation as an audio-driven temporally coherent denoising process (DiffTalk). More specifically, instead of employing audio signals as the single driving factor, we investigate the control mechanism of the talking face, and incorporate reference face images and landmarks as conditions for personality-aware generalized synthesis. In this way, the proposed DiffTalk is capable of producing high-quality talking head videos in synchronization with the source audio, and more importantly, it can be naturally generalized across different identities without further fine-tuning. Additionally, our DiffTalk can be gracefully tailored for higher-resolution synthesis with negligible extra computational cost. Extensive experiments show that the proposed DiffTalk efficiently synthesizes high-fidelity audio-driven talking head videos for generalized novel identities. For more video results, please refer to https://sstzal.github.io/DiffTalk/.
improve the generation quality or enhance the model generalization 동시에 이룬 논문
audio signals + face images + landmarks → 통합으로 conditioning
Talking head synthesis 는 최근 유망한 연구 분야
2d-GAN 기반 모델이 지금까지는 주요 했음 : audio-to-lip mapping 분야
단점:
- generator and a discriminator 두개 동시에 최적화 hard
- mode collapse에 약함
- 3d는 higher-quality, but generalize X
Generation quality and model generalization 두가지를 모두 이룬 논문이 지금까지 없음
본 논문에서는 the talking head synthesis를 시간적으로 일관된 audio-driven denoising process를 활용해 해결
audio signals + face images + landmarks → 통합으로 conditioning
이 방법은 head generation을 쉽게 컨트롤 할 수 있고 일반화 할 수 있다.
Latent space에서 동작
3.1 Audio-driven Talking Head Synthesis
2d based GAN
- Makelttalk: 개인화된 헤드 모션 모델링을 위해 스피커 인식 오디오 인코더 도입
- Wav2Lip : Lip-Sync expert 사용하여 입술-음성 동기화 향상
- GAN 학습의 불안정성
- 모드 붕괴 문제
- 높은 해상도로 확장하기 어려움
3d based GAN
- 3D Morphable Models (3DMM): 얼굴의 파라메트릭 제어를 제공
- Neural Radiance Fields (NeRF): 3D 인식 말하는 얼굴 합성에 새로운 해결책 제시
- 대부분 특정 인물에 대해 학습되어야 함
- 일반화가 어려움
3.2 Latent Diffusion Models (LDMs)
- DM의 학습 및 추론 과정을 압축된 저차원 잠재 공간(latent space)으로 전환.
- 효율적인 계산을 가능하게 함.
다양한 분야에 넓게 활용됨
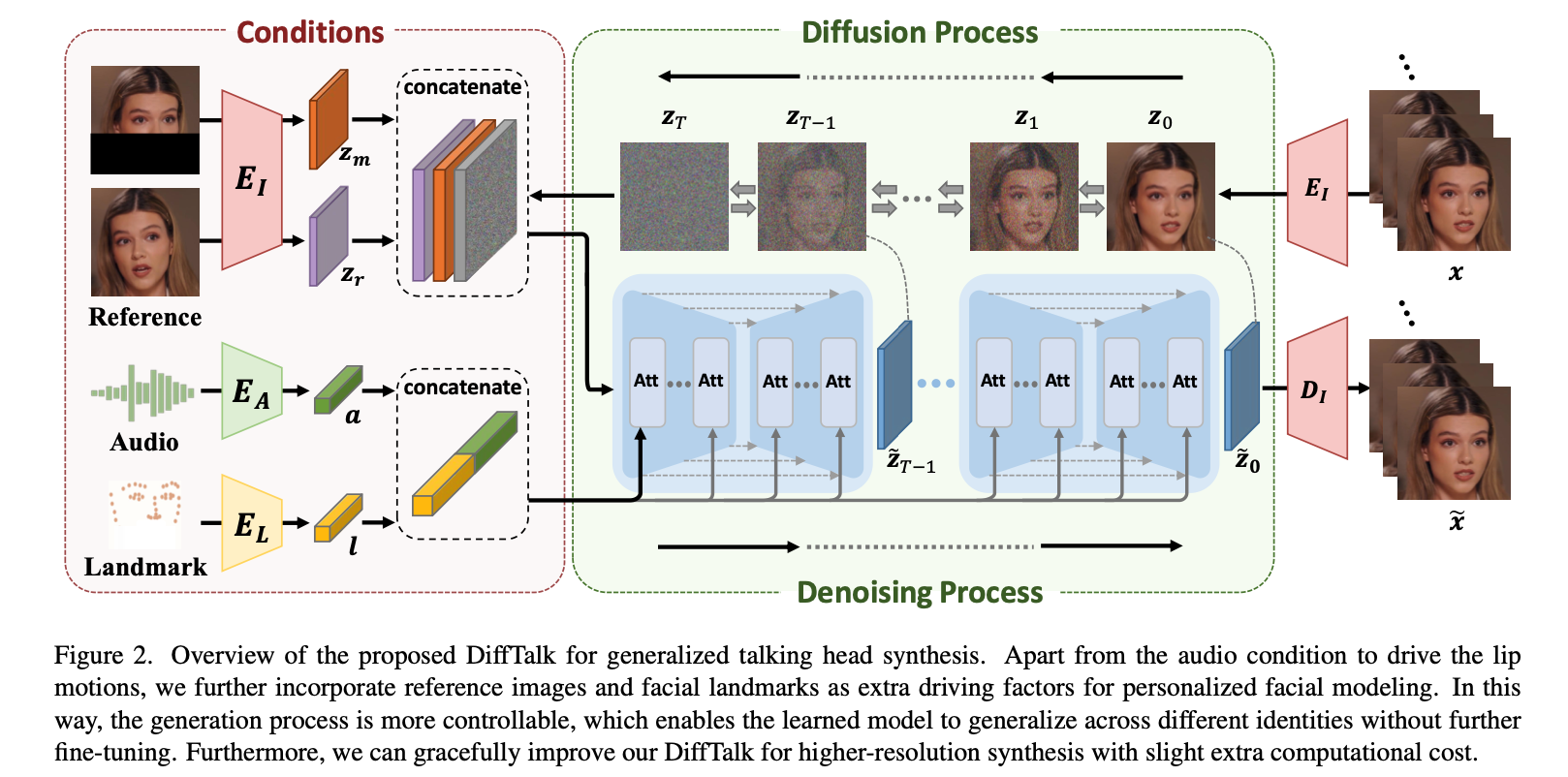
4.1 Overview
- Audio-driven Temporally Coherent Denoising Process:
- 오디오 기반 시간적 일관성을 갖춘 노이즈 제거 과정으로 말하는 얼굴 합성을 모델링.
- Smooth Audio Features:
- 부드러운 오디오 특징을 조건으로 도입해 안정적인 얼굴 움직임을 모델링.
4.1.1 Personalized Facial Modeling
additional condition
- Reference Face Images
- Facial Landmarks
장점
- 얼굴 생성 과정을 더 제어 가능하게 만듦.
- 추가적인 미세 조정(fine-tuning) 없이도 다양한 정체성(identity)으로 일반화 가능.
4.2 Conditional Diffusion Model for Talking Head
4.2.1 Latent Diffusion Models (LDMs)
잘 학습된 image encoder \(E_I\) and decoder \(D_I\) , frozen 으로 사용
- the input face image : \(x ∈ \mathbb{R}^{H×W×3}\)
- a latent space : \(z_0 = E_I(x) ∈ \mathbb{R}^{h×w×3}\), where \(H/h = W/w = f\)
- H, W : the height and width of the original image
- f : the downsampling factor.
- \(\mathcal{M}\) : denoising network
- \(\mathcal{T}\) : the reverse process of a Markov Chain of length
- \(\tilde{z}_0\) : The final denoised result
- \(\tilde{x} = D_I(\tilde{z}_0)\) : upsampled to the pixel space with the pre-trained image decoder
- \(\tilde{x} \in \mathbb{R}^{H \times W \times 3}\) : the reconstructed face image
basic condition : 오디오 신호는 모델의 denoising process을 guide하는 기본 조건으로 사용
audio-to-lip translation : 오디오 신호를 기반으로 입술 움직임을 정확하게 모델링
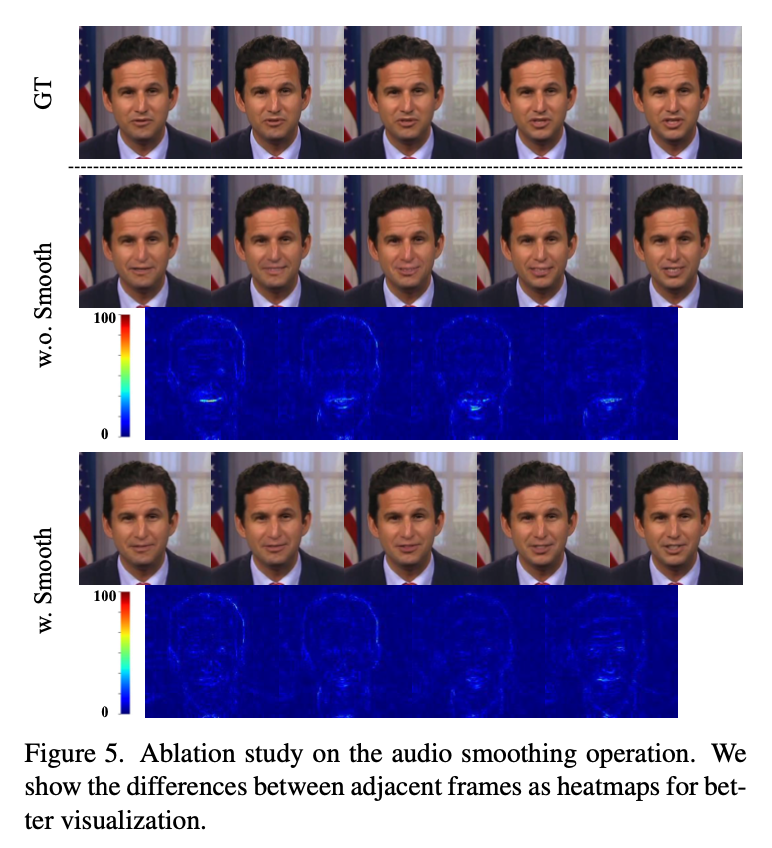
4.2.2 Smooth Audio Feature Extraction
시간적 일관성을 더 잘 통합하기 위해 오디오 인코더에 두 단계의 스무딩(smoothing) 작업을 적용.
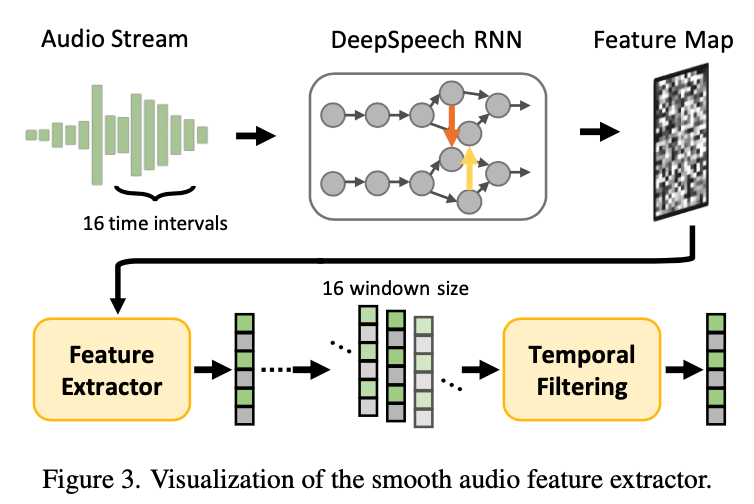
reorganize the raw audio signal
- 16ms 겹치는 시간 윈도우로 오디오 신호를 분할 (20ms 오디오 클립에 해당)
- 각 윈도우는 해당 비디오 프레임을 중심으로 구성
Audio feature extraction
- DeepSpeech (RNN 기반)를 사용하여 프레임별 오디오 특징 맵 F 추출
Temporal Filtering
- learnable temporal filtering 도입
- 인접 오디오 특징 시퀀스 \([F_{i−w},⋯,F_i,⋯,F_{i+w}]\) 를 입력으로 받음 ( \(w=8\) )
- Self-Attention 기반 학습을 통해 최종 부드럽게 스무딩된 오디오 특징을 \(a∈\mathbb{R}^{D_A}\) 로 계산.
- $D_A$: 오디오 특징 차원
bridge the modality gap between the audio signals and the visual information
스무딩된 오디오 특징을 condition으로 사용 → 시간적 일관성을 고려한 얼굴 동작 모델링을 개선
\[L_A := \mathbb{E}_{z, \epsilon \sim \mathcal{N}(0,1), a, t} \left[ \left\| \epsilon - \mathcal{M}(z_t, t, a) \right\|_2^2 \right].\]4.2.3 Identity-Preserving Model Generalization
audio-to-lip translation + source image의 Identity Information을 유지하면서 general한 모델 구축
Identity Information
- Face Appearance
- Head Pose
- Image Background
Reference Mechanism
Reference image (\(x_r\)):
- 소스 아이덴티티의 임의 얼굴 이미지 선택
- 60 프레임 이상 떨어진 이미지를 선택해 training shortcuts 방지
- 제한: 참조 이미지와 대상 이미지의 포즈는 다름
- 참조 이미지 인코딩 : \(z_r=D_I(x_r)∈\mathbb{R}^{h×w×3}\)
pose estimate problem (\(x_m\)) :
- 마스킹된 타겟 이미지 (\(x_m\))를 사용하여 포즈 정보를 제공
- 입 주변은 완전히 마스킹되어 네트워크가 입술 움직임을 보지 못하게 함
- 마스킹된 이미지 인코딩 : \(z_m=D_I(x_m)∈\mathbb{R}^{h×w×3}\)
Facial Landmark
- 랜드마크 특징 (\(l\)): MLP 기반 인코더 $$E_L$를 통해 인코딩
- \(l∈\mathbb{R}^{D_L}, D_L\): 랜드마크 특징 차원.
- 마우스 영역(masked mouth area):
- 입술 주변 랜드마크를 마스킹하여 training shortcuts 방지.
Condition Set
\[C=\{a,z_r,z_m,l\}\]- \(a\): 오디오 특징
- \(z_r\): 참조 이미지 특징
- \(z_m\): 마스킹된 이미지 특징
- \(l\): 랜드마크 특징
모든 condition을 포함하여 Conditional Denoising Process 모델링
네트워크 파라미터 ($\mathcal{M},E_A,E_L$)는 최적화 목표를 통해 공동 최적화
\[L := \mathbb{E}_{z, \epsilon \sim \mathcal{N}(0,1), C, t} \left[ \left\| \epsilon - \mathcal{M}(z_t, t, C) \right\|_2^2 \right].\]참조 이미지($x_r$)는 입 모양과 배경을, 마스킹된 이미지($x_m$)는 헤드 포즈를, 랜드마크($l$)는 얼굴 외형을 제어하여, 시간적으로 일관성 있고 아이덴티티를 유지하면서 새로운 아이덴티티에도 일반화 가능한 비디오 합성을 달성
4.2.4 Conditioning Mechanisms
Conditional Denoising Process을 효과적으로 모델링하기 위해 다양한 조건 C를 네트워크에 통합
- Base Network: UNet 기반 백본(M)
- Cross-Attention : **다중 모달 학습(multimodality learning) 강화
Visual condition
- 노이즈 맵 (\(z_T\))
- 마스킹된 참조 이미지 (\(z_m\))
- 참조 이미지 (\(z_r\))
연산 방식 : channel-wise concatenation → \(C_v=[z_T;z_m;z_r]∈\mathbb{R}^{h×w×9}\)
네트워크의 첫 번째 레이어에 입력
이미지-이미지 변환(image-to-image translation) 방식으로 출력 얼굴을 직접 안내
Latent condition
- 오디오 특징 (a)
- 랜드마크 특징 (l)
연산 방식 : $$ C_l=[a;l]∈\mathbb{R}^{D_A+D_L} $$
네트워크의 중간 Cross-Attention Layer에 입력 : Attention 메커니즘에서 Key와 Value 로 condition 들어감
Final condition
\[C=\{C_v,C_l\}\]- 모든 조건 정보를 네트워크 M에 효과적으로 통합
- 말하는 얼굴 합성 과정을 정확하게 안내
4.3 Higher-Resolution Talking Head Synthesis
DiffTalk을 사용하여 고해상도(High-Resolution) 말하는 얼굴 합성을 수행
추가적인 계산 비용을 최소화하면서도 Faithful Reconstruction Effects 달성
latent space and resolution setting (256×256×3)
- 다운샘플링 비율 (f): f=4
- 잠재 공간 크기: 64×64×3
high-resolution setting (512 × 512 × 3)
- 다운샘플링 비율 (f): f=8
- 이미지 인코더 (EI)와 디코더 (DI)를 조정
- 학습된 인코더를 고정(frozen) 상태로 유지
- 잠재 공간 크기: 64×64×3
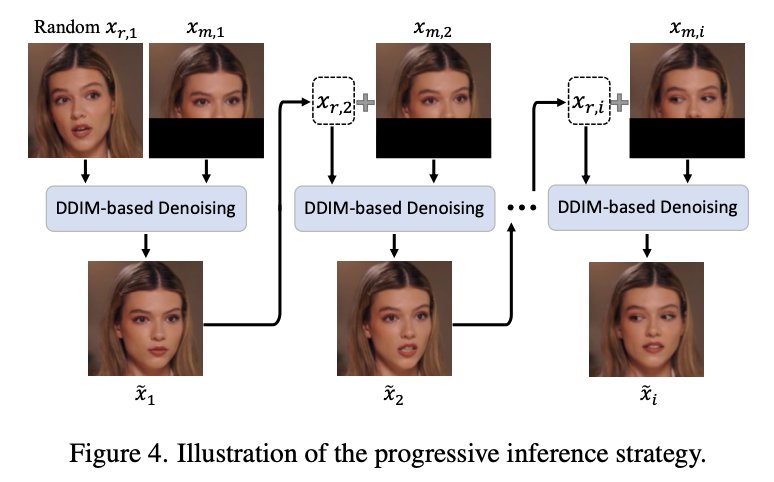
4.4 Progressive Inference
DDIM 기반 추론 (Denoising Diffusion Implicit Model)
Progressive Reference Strategy
- 초기 프레임 (\(x_{r,1}\)):
- 첫 번째 프레임은 타겟 아이덴티티의 임의 얼굴 이미지로 설정.
- 후속 프레임 (\(x_{r,i+1}\)):
- 이전에 합성된 얼굴 이미지 (\(\tilde{x}_i\))를 다음 프레임의 참조 이미지 (\(x_{r,i+1}\))로 사용.
인접 프레임 간 차이가 작기 때문에 shortcuts을 방지하기 위해 inference 에만 사용
in training
- 마스킹된 \(z_T\) 사용
- 입 주변 영역을 마스킹하고 무작위로 초기화하여 네트워크가 이 영역에 집중하도록 유도
Video Jitter Reduction
- 프레임 보간 기술 (Frame Interpolation) 사용.
- 비디오 프레임 간의 불연속성 감소.
- 더 부드럽고 일관된 비디오 출력 달성.
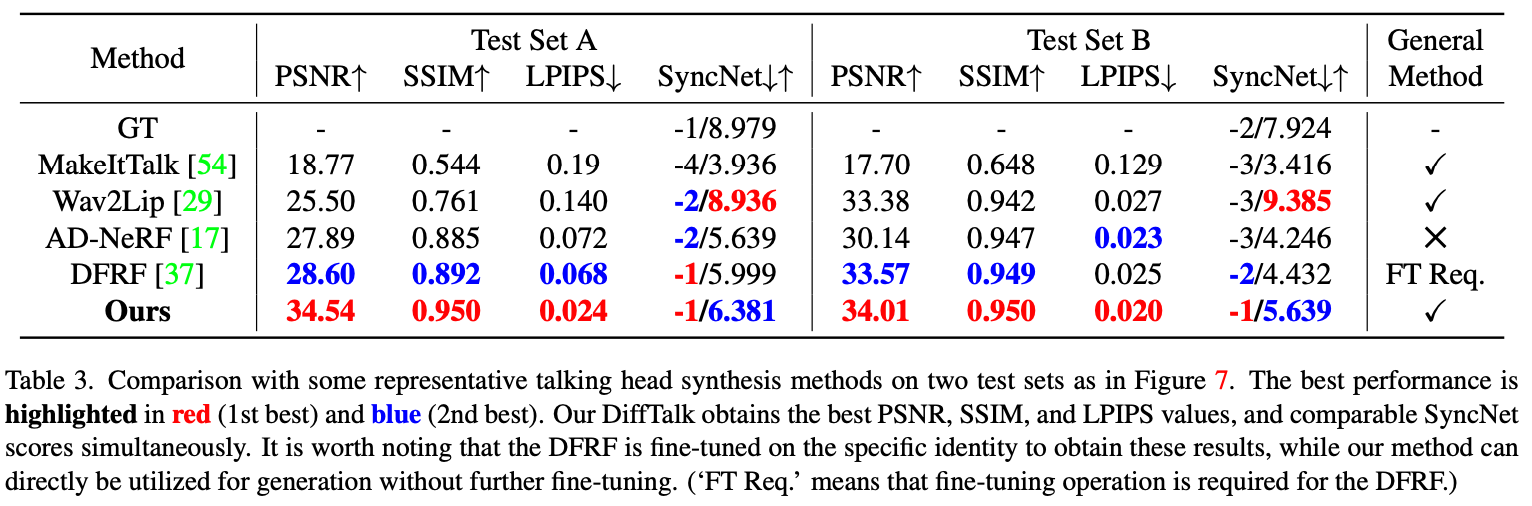
5.1 Experimental Settings
5.1.1 dataset
HDTF Dataset
- 16시간 분량의 말하는 비디오 포함
- 해상도: 720P 또는 1080P
- 300명 이상의 아이덴티티(identity) 포함
- 훈련 및 테스트 분할:
- 100개의 비디오를 랜덤하게 선택하여 총 100분의 훈련용 비디오 갤러리 생성
- 나머지 데이터는 테스트 세트로 사용
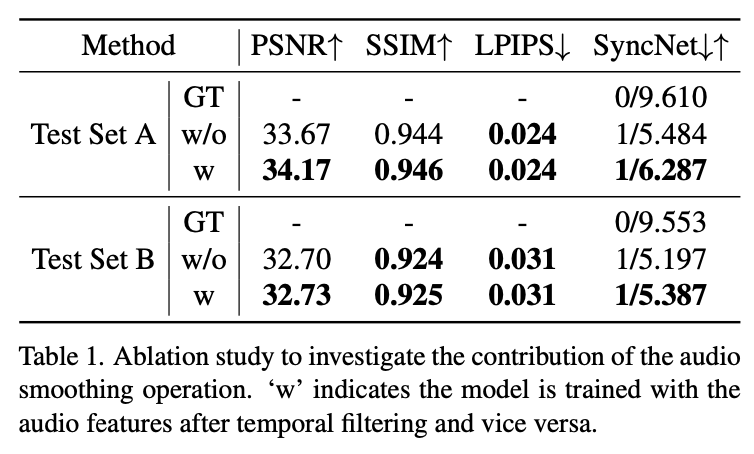
5.1.2 Metrics
- 이미지 품질 평가:
- PSNR (↑): 더 높을수록 좋음
- SSIM (↑): 더 높을수록 좋음
- LPIPS (↓): 더 낮을수록 좋음 (학습 기반 지각적 유사도 척도, 인간의 인식과 더 일치)
- 오디오-비주얼 동기화 평가:
- SyncNet Score
- Offset (↓): 더 낮을수록 좋음
- Confidence (↑): 더 높을수록 좋음
- SyncNet Score
5.1.3 Implementation Details
- 입력 이미지 크기:
- 기본 해상도: 256 × 256
- 고해상도: 512 × 512
- 다운샘플링 비율 (ff)
- 256 × 256 → f = 4 → 64 × 64 × 3
- 512 × 512 → f = 8 → 64 × 64 × 3
- 노이즈 제거 단계 (TT)
- 학습 및 추론: 200단계
- 특징 차원:
- \[D_A=D_L=64\]
- 학습 환경:
- 8개의 NVIDIA 3090 GPU 사용
- 총 15시간 학습 소요
5.2 Ablation Study

5.3 Method Comparison